python DataFrame数据分组统计groupby()函数
print(df)df1 = df.groupby(‘class’).sum()# 分组统计求和print(df1)1.2 二级分类_分组求和给groupby()传入一个列表,列表中的元素为分类字段,从左到右分类级别增大。(一级分类、二级分类…)data = [[‘a’, ‘A’, ‘1等’, 109], [‘b’, ‘B’, ‘1等’, 112], [‘c’, ‘A’, ‘1等’, 125],
[‘i’, ‘C’, 117], [‘j’, ‘C’, 128]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
columns = [‘name’, ‘class’, ‘num’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“=================================================”)
df1 = df.groupby(‘class’).sum() # 分组统计求和
print(df1)

给groupby()传入一个列表,列表中的元素为分类字段,从左到右分类级别增大。(一级分类、二级分类…)
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109], [‘b’, ‘B’, ‘1等’, 112], [‘c’, ‘A’, ‘1等’, 125], [‘d’, ‘B’, ‘2等’, 120],
[‘e’, ‘B’, ‘1等’, 126], [‘f’, ‘B’, ‘2等’, 133], [‘g’, ‘A’, ‘2等’, 124], [‘h’, ‘B’, ‘1等’, 134],
[‘i’, ‘A’, ‘2等’, 117], [‘j’, ‘A’, ‘2等’, 128], [‘h’, ‘A’, ‘1等’, 130], [‘i’, ‘B’, ‘2等’, 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“=================================================”)
df1 = df.groupby([‘class_1’, ‘class_2’]).sum() # 分组统计求和
print(df1)

1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算)
其中,df.groupby(‘class_1’)得到一个DataFrameGroupBy对象,对该对象可以使用列名进行索引,以对指定的列进行统计。
如:df.groupby(‘class_1’)[‘num’].sum()
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109], [‘b’, ‘B’, ‘1等’, 112], [‘c’, ‘A’, ‘1等’, 125], [‘d’, ‘B’, ‘2等’, 120],
[‘e’, ‘B’, ‘1等’, 126], [‘f’, ‘B’, ‘2等’, 133], [‘g’, ‘A’, ‘2等’, 124], [‘h’, ‘B’, ‘1等’, 134],
[‘i’, ‘A’, ‘2等’, 117], [‘j’, ‘A’, ‘2等’, 128], [‘h’, ‘A’, ‘1等’, 130], [‘i’, ‘B’, ‘2等’, 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“=================================================”)
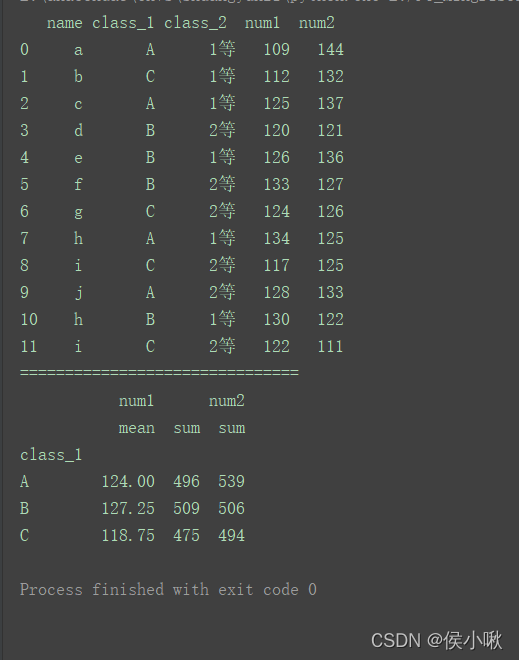
df1 = df.groupby(‘class_1’)[‘num’].sum()
print(df1)
代码运行结果同上。
===================================================================================
2.1 对一级分类的DataFrameGroupBy对象进行遍历
for name, group in DataFrameGroupBy_object
其中,name指分类的类名,group指该类的所有数据。
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109], [‘b’, ‘C’, ‘1等’, 112], [‘c’, ‘A’, ‘1等’, 125], [‘d’, ‘B’, ‘2等’, 120],
[‘e’, ‘B’, ‘1等’, 126], [‘f’, ‘B’, ‘2等’, 133], [‘g’, ‘C’, ‘2等’, 124], [‘h’, ‘A’, ‘1等’, 134],
[‘i’, ‘C’, ‘2等’, 117], [‘j’, ‘A’, ‘2等’, 128], [‘h’, ‘B’, ‘1等’, 130], [‘i’, ‘C’, ‘2等’, 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“===============================”)
获取目标数据。
df1 = df[[‘name’, ‘class_1’, ‘num’]]
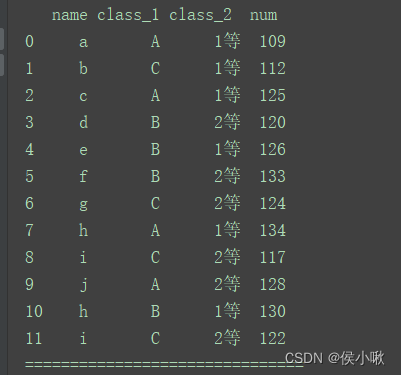
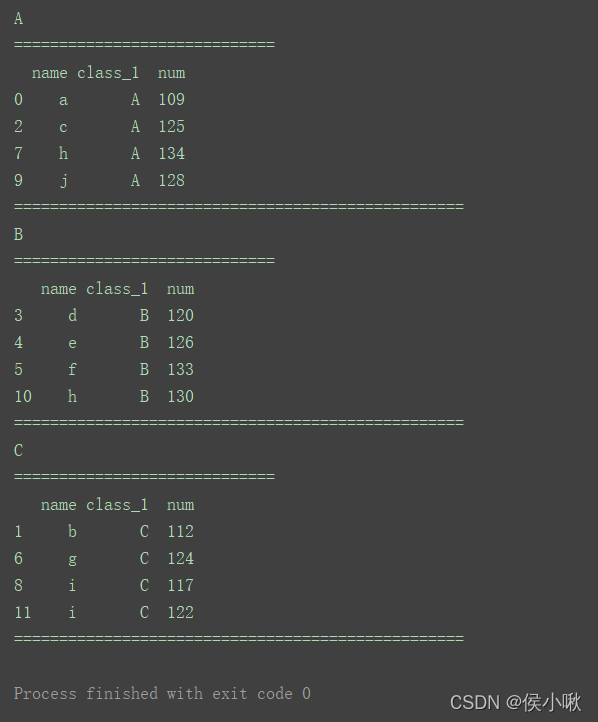
for name, group in df1.groupby(‘class_1’):
print(name)
print(“=============================”)
print(group)
print(“==================================================”)
2.2 对二级分类的DataFrameGroupBy对象进行遍历
对二级分类的DataFrameGroupBy对象进行遍历,
以for (key1, key2), group in df.groupby([‘class_1’, ‘class_2’]) 为例
不同于一级分类的是, (key1, key2)是一个由多级类别组成的元组,而group表示该多级分类类别下的数据。
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109], [‘b’, ‘C’, ‘1等’, 112], [‘c’, ‘A’, ‘1等’, 125], [‘d’, ‘B’, ‘2等’, 120],
[‘e’, ‘B’, ‘1等’, 126], [‘f’, ‘B’, ‘2等’, 133], [‘g’, ‘C’, ‘2等’, 124], [‘h’, ‘A’, ‘1等’, 134],
[‘i’, ‘C’, ‘2等’, 117], [‘j’, ‘A’, ‘2等’, 128], [‘h’, ‘B’, ‘1等’, 130], [‘i’, ‘C’, ‘2等’, 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num’]
df = pd.DataFrame(data=data, index=index, columns=columns)
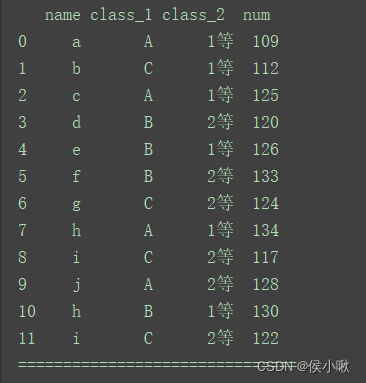
print(df)
print(“===============================”)
for (key1, key2), group in df.groupby([‘class_1’, ‘class_2’]):
print(key1, key2)
print(“=============================”)
print(group)
print(“==================================================”)
程序运行结果如下:
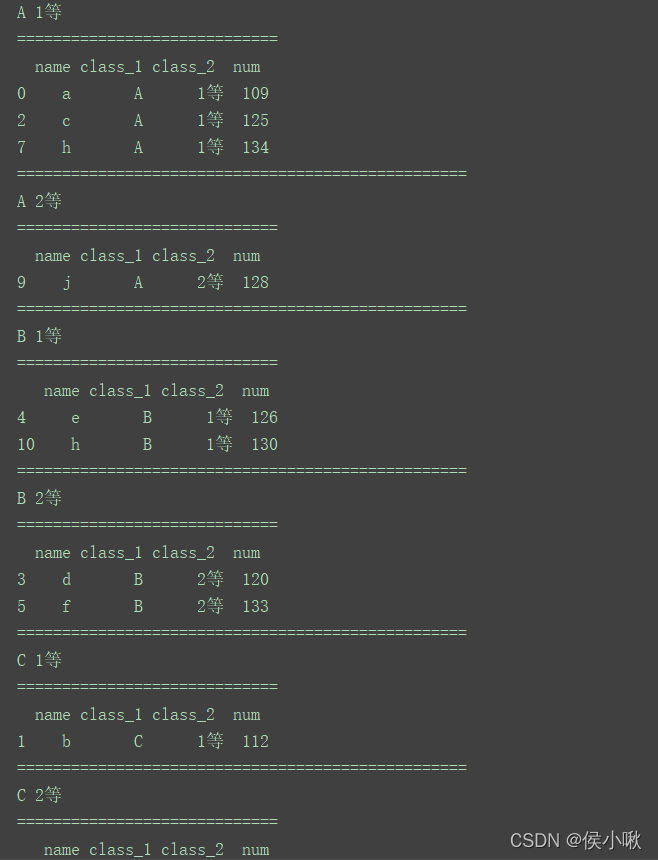
(部分)
=================================================================================
使用groupby()函数和agg()函数 实现 分组聚合操作运算。
以 分组求均值、求和 为例
给agg()传入一个列表
df1.groupby([‘class_1’, ‘class_2’]).agg([‘mean’, ‘sum’])
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109, 144], [‘b’, ‘C’, ‘1等’, 112, 132], [‘c’, ‘A’, ‘1等’, 125, 137], [‘d’, ‘B’, ‘2等’, 120, 121],
[‘e’, ‘B’, ‘1等’, 126, 136], [‘f’, ‘B’, ‘2等’, 133, 127], [‘g’, ‘C’, ‘2等’, 124, 126], [‘h’, ‘A’, ‘1等’, 134, 125],
[‘i’, ‘C’, ‘2等’, 117, 125], [‘j’, ‘A’, ‘2等’, 128, 133], [‘h’, ‘B’, ‘1等’, 130, 122], [‘i’, ‘C’, ‘2等’, 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num1’, ‘num2’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“===============================”)
df1 = df[[‘class_1’, ‘class_2’, ‘num1’, ‘num2’]]
print(df1.groupby([‘class_1’, ‘class_2’]).agg([‘mean’, ‘sum’]))
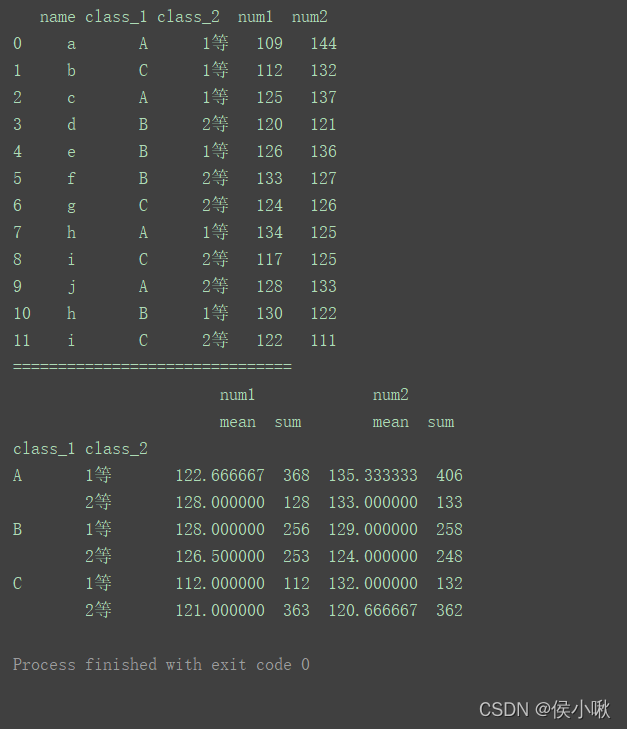
给agg()方法传入一个字典
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109, 144], [‘b’, ‘C’, ‘1等’, 112, 132], [‘c’, ‘A’, ‘1等’, 125, 137], [‘d’, ‘B’, ‘2等’, 120, 121],
[‘e’, ‘B’, ‘1等’, 126, 136], [‘f’, ‘B’, ‘2等’, 133, 127], [‘g’, ‘C’, ‘2等’, 124, 126], [‘h’, ‘A’, ‘1等’, 134, 125],
[‘i’, ‘C’, ‘2等’, 117, 125], [‘j’, ‘A’, ‘2等’, 128, 133], [‘h’, ‘B’, ‘1等’, 130, 122], [‘i’, ‘C’, ‘2等’, 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num1’, ‘num2’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“===============================”)
df1 = df[[‘class_1’, ‘num1’, ‘num2’]]
print(df1.groupby(‘class_1’).agg({‘num1’: [‘mean’, ‘sum’], ‘num2’: [‘sum’]}))
也可以自定义一个函数(以名为max1为例)传入agg()中。
import pandas as pd
data = [[‘a’, ‘A’, ‘1等’, 109, 144], [‘b’, ‘C’, ‘1等’, 112, 132], [‘c’, ‘A’, ‘1等’, 125, 137], [‘d’, ‘B’, ‘2等’, 120, 121],
[‘e’, ‘B’, ‘1等’, 126, 136], [‘f’, ‘B’, ‘2等’, 133, 127], [‘g’, ‘C’, ‘2等’, 124, 126], [‘h’, ‘A’, ‘1等’, 134, 125],
[‘i’, ‘C’, ‘2等’, 117, 125], [‘j’, ‘A’, ‘2等’, 128, 133], [‘h’, ‘B’, ‘1等’, 130, 122], [‘i’, ‘C’, ‘2等’, 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = [‘name’, ‘class_1’, ‘class_2’, ‘num1’, ‘num2’]
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)