【完整源码+数据集+部署教程】 X光脊椎图像分割系统源码和数据集:改进yolo11-slimneck
【完整源码+数据集+部署教程】 X光脊椎图像分割系统源码和数据集:改进yolo11-slimneck
背景意义
研究背景与意义
随着医学影像技术的快速发展,X光影像在脊椎疾病的诊断和治疗中扮演着越来越重要的角色。脊椎作为人体的支柱,其健康状况直接影响到个体的生活质量和身体功能。因此,准确、快速地分析脊椎X光图像对于临床医生制定治疗方案至关重要。然而,传统的手动分析方法不仅耗时,而且容易受到主观因素的影响,导致诊断结果的不一致性。因此,开发一种高效、准确的自动化图像分割系统显得尤为重要。
本研究旨在基于改进的YOLOv11模型,构建一个针对脊椎X光图像的分割系统。该系统能够自动识别和分割出L1至S1六个脊椎节段,进而为医生提供更加精准的诊断依据。数据集包含2464幅经过精细标注的脊椎X光图像,涵盖了不同角度和条件下的脊椎影像。这些图像经过多种预处理和增强技术处理,确保了模型训练的多样性和鲁棒性。
在深度学习技术的推动下,YOLO系列模型因其快速的检测速度和良好的准确性而广泛应用于医学影像分析中。通过对YOLOv11的改进,我们希望能够进一步提升其在脊椎图像分割任务中的表现,使其在临床应用中具备更高的实用价值。最终,该系统不仅可以减轻医生的工作负担,还能提高脊椎疾病的早期诊断率,为患者提供更及时的治疗方案。
综上所述,本研究的意义在于推动医学影像分析技术的发展,提升脊椎疾病的诊断效率和准确性,为相关领域的研究和临床实践提供有力支持。
图片效果
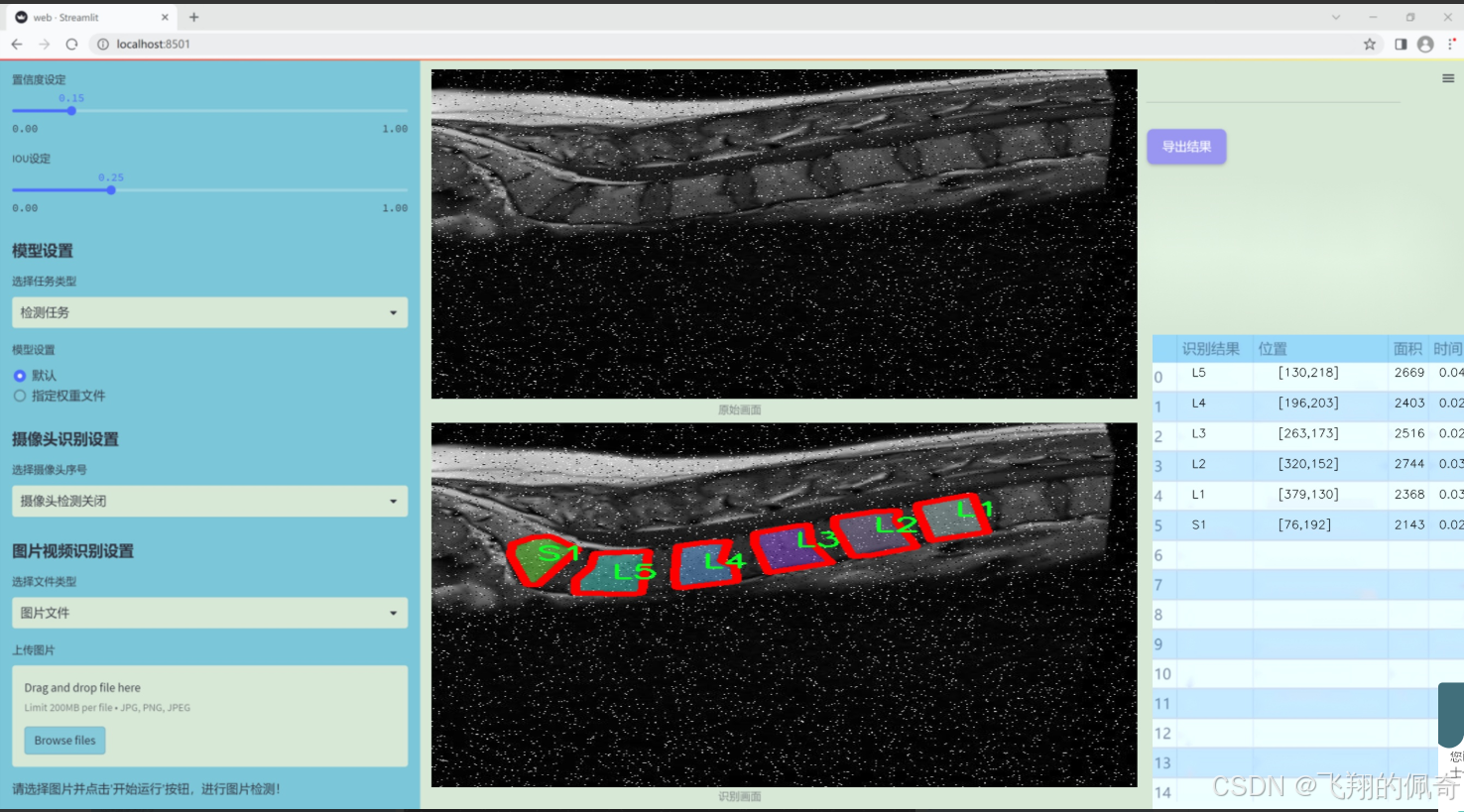
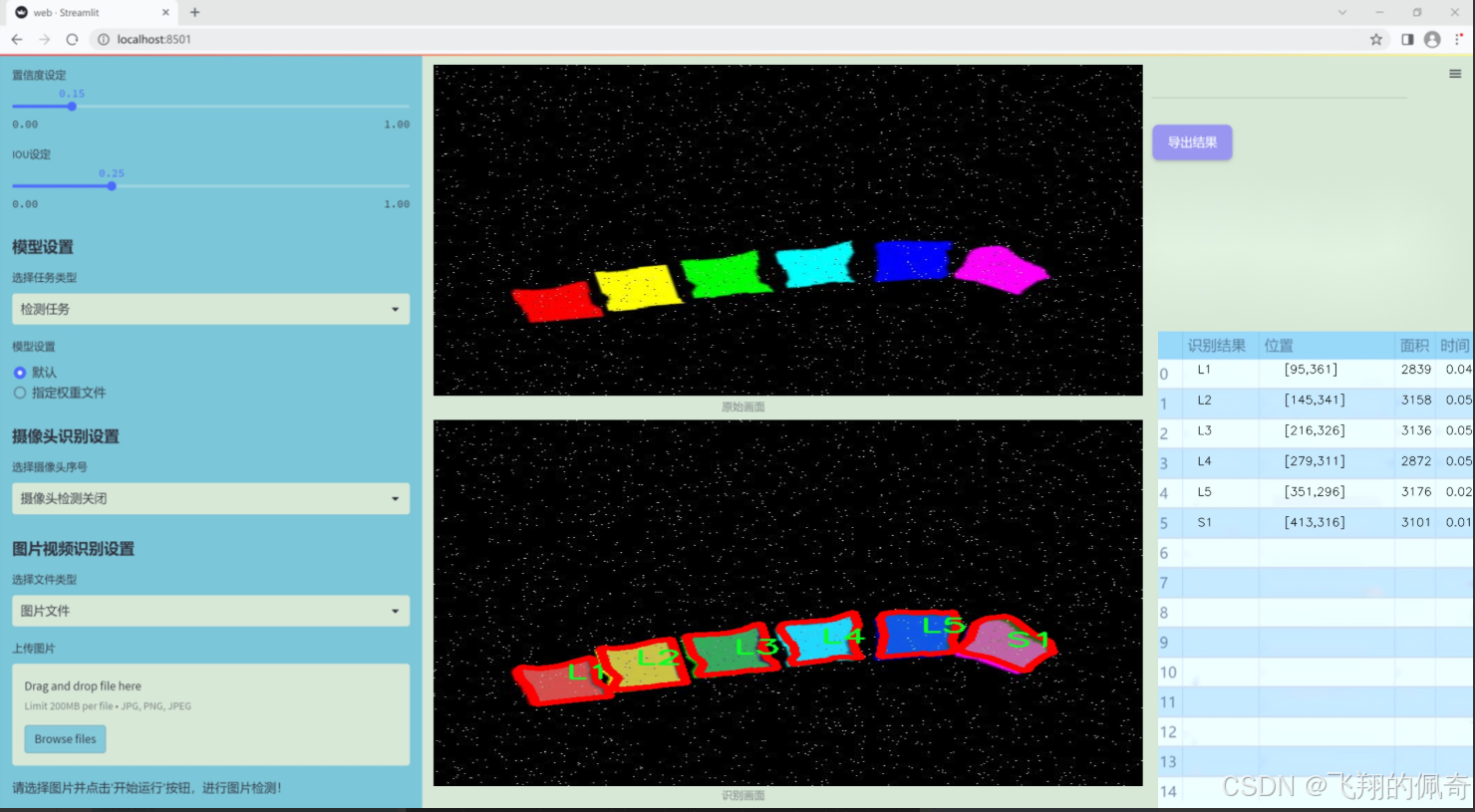
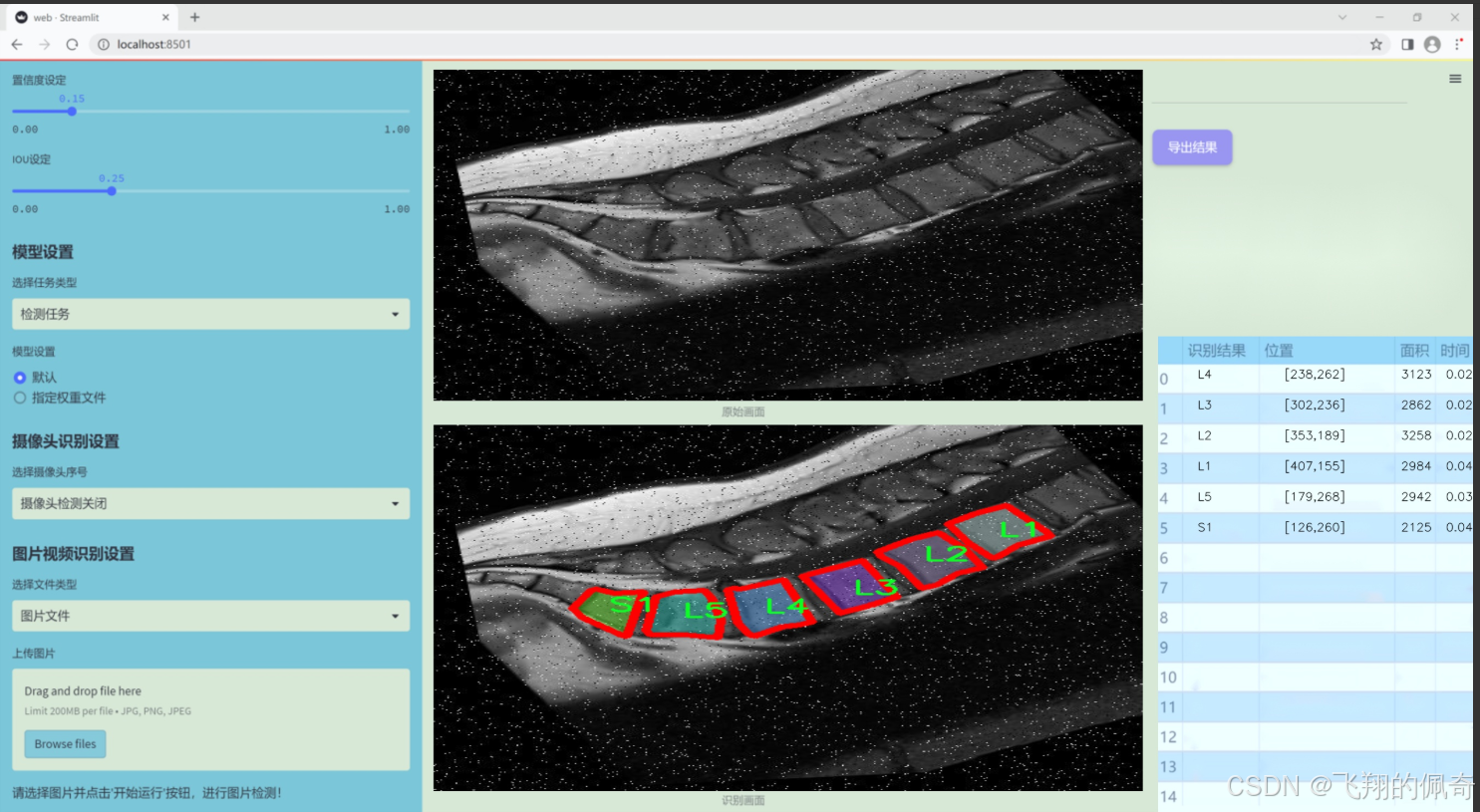
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11模型,以实现对X光脊椎图像的高效分割。为此,我们构建了一个专门针对脊椎影像的多类别数据集,命名为“Backspine”。该数据集包含六个主要类别,分别为L1、L2、L3、L4、L5和S1,涵盖了人类脊椎的主要结构。这些类别不仅在解剖学上具有重要意义,而且在临床诊断和治疗中扮演着关键角色。通过对这些脊椎结构的准确分割,医生能够更好地识别脊椎病变、评估损伤程度,并制定相应的治疗方案。
数据集的构建过程包括从多个医疗影像数据库中收集高质量的X光脊椎图像,并对其进行标注。每一张图像都经过专业放射科医生的审核,以确保标注的准确性和一致性。为了提高模型的泛化能力,我们的数据集还包括了不同年龄、性别和病理状态的患者影像,确保模型在实际应用中能够适应多样化的临床场景。
在数据预处理阶段,我们对图像进行了标准化处理,以消除不同拍摄条件下的影响,并采用数据增强技术以增加样本的多样性。这些技术包括旋转、平移、缩放和对比度调整等,旨在提升模型的鲁棒性和准确性。
通过构建这样一个多样化且高质量的“Backspine”数据集,我们希望能够为YOLOv11模型的训练提供坚实的基础,从而推动脊椎影像分析技术的发展,最终为临床提供更为精准的辅助诊断工具。




核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttentionModule(nn.Module):
def init(self):
super(SpatialAttentionModule, self).init()
# 定义一个2D卷积层,用于生成空间注意力图
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid() # 使用Sigmoid激活函数将输出归一化到[0, 1]
def forward(self, x):
# 计算输入特征图的平均值和最大值
avgout = torch.mean(x, dim=1, keepdim=True) # 在通道维度上计算平均值
maxout, _ = torch.max(x, dim=1, keepdim=True) # 在通道维度上计算最大值
out = torch.cat([avgout, maxout], dim=1) # 将平均值和最大值拼接在一起
out = self.sigmoid(self.conv2d(out)) # 通过卷积层和Sigmoid激活函数生成注意力图
return out * x # 将注意力图与输入特征图相乘,进行加权
class LocalGlobalAttention(nn.Module):
def init(self, output_dim, patch_size):
super().init()
self.output_dim = output_dim
self.patch_size = patch_size
# 定义两个全连接层和一个卷积层
self.mlp1 = nn.Linear(patch_size * patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
# 定义可学习的参数
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 调整输入的维度顺序
B, H, W, C = x.shape # 获取批量大小、高度、宽度和通道数
P = self.patch_size
# 处理局部特征
local_patches = x.unfold(1, P, P).unfold(2, P, P) # 提取局部补丁
local_patches = local_patches.reshape(B, -1, P * P, C) # 重塑为(B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # 在通道维度上计算平均值
# 通过MLP处理局部特征
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # 归一化
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # 计算局部注意力
local_out = local_patches * local_attention # 加权局部特征
# 计算与提示向量的余弦相似度
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1) # 限制在[0, 1]范围内
local_out = local_out * mask # 应用掩码
local_out = local_out @ self.top_down_transform # 应用变换
# 恢复形状并进行上采样
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2) # 调整维度顺序
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False) # 上采样
output = self.conv(local_out) # 通过卷积层生成输出
return output
class PPA(nn.Module):
def init(self, in_features, filters) -> None:
super().init()
# 定义多个卷积层和注意力模块
self.skip = nn.Conv2d(in_features, filters, kernel_size=1, stride=1, padding=0)
self.c1 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c2 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c3 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.sa = SpatialAttentionModule() # 空间注意力模块
self.lga2 = LocalGlobalAttention(filters, 2) # 局部全局注意力模块
self.lga4 = LocalGlobalAttention(filters, 4) # 局部全局注意力模块
self.bn1 = nn.BatchNorm2d(filters) # 批归一化
self.silu = nn.SiLU() # SiLU激活函数
def forward(self, x):
x_skip = self.skip(x) # 跳跃连接
x_lga2 = self.lga2(x_skip) # 局部全局注意力
x_lga4 = self.lga4(x_skip) # 局部全局注意力
x1 = self.c1(x) # 卷积操作
x2 = self.c2(x1) # 卷积操作
x3 = self.c3(x2) # 卷积操作
# 将各个特征图相加
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.bn1(x) # 批归一化
x = self.sa(x) # 空间注意力
x = self.silu(x) # 激活函数
return x # 返回最终输出
代码说明
SpatialAttentionModule: 该模块实现了空间注意力机制,通过计算输入特征图的平均值和最大值来生成注意力图,并将其应用于输入特征图。
LocalGlobalAttention: 该模块实现了局部和全局注意力机制,通过提取局部补丁并通过多层感知机(MLP)处理,计算注意力并与输入特征图结合。
PPA: 该模块结合了多个卷积层和注意力机制,通过跳跃连接和特征融合来增强特征表示。
这个程序文件 hcfnet.py 实现了一个深度学习模型的几个模块,主要用于图像处理任务。文件中定义了多个类,每个类代表一个特定的功能模块。
首先,SpatialAttentionModule 类实现了空间注意力机制。它通过对输入特征图进行平均和最大池化操作,生成两个特征图,然后将它们拼接在一起,经过卷积和 Sigmoid 激活函数处理后,得到一个注意力权重图。最后,这个权重图与输入特征图相乘,从而强调重要的空间信息。
接下来,LocalGlobalAttention 类结合了局部和全局注意力机制。它首先将输入特征图进行分块处理,提取局部特征,然后通过多层感知机(MLP)进行特征变换,并使用 LayerNorm 进行归一化。接着,通过 softmax 函数计算局部注意力权重,并与局部特征相乘。该模块还引入了一个提示向量和一个上行变换矩阵,以增强特征的表达能力。最后,经过上采样和卷积操作,输出最终的特征图。
ECA 类实现了有效通道注意力机制(ECA),通过自适应平均池化和一维卷积来生成通道注意力权重,并将其应用于输入特征图,以提升模型对重要通道的关注。
PPA 类是一个主要的处理模块,结合了多个子模块,包括跳跃连接、卷积层、空间注意力模块和有效通道注意力模块。它首先通过跳跃连接将输入特征图进行处理,然后通过局部全局注意力模块提取不同尺度的特征,最后经过一系列卷积和激活函数,输出处理后的特征图。
Bag 类实现了一个简单的加权融合机制,使用 sigmoid 函数生成边缘注意力权重,将不同来源的特征图进行加权组合。
最后,DASI 类是整个网络的一个重要组成部分,它接收多个特征图作为输入,使用跳跃连接和卷积操作进行特征融合。该模块通过 Bag 类进行特征的加权融合,最后经过尾部卷积和激活函数,输出最终的特征图。
整体来看,这个文件实现了一个复杂的神经网络结构,结合了多种注意力机制和特征融合策略,旨在提高图像处理任务的性能。
10.3 prepbn.py
以下是经过简化和详细注释的核心代码部分:
import torch
import torch.nn as nn
定义一个自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# 定义一个可学习的参数 alpha,初始值为 1
self.alpha = nn.Parameter(torch.ones(1))
# 定义一个一维批量归一化层
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):
# 将输入张量的维度进行转置,以适应 BatchNorm 的输入格式
x = x.transpose(1, 2)
# 进行批量归一化,并加上 alpha * x
x = self.bn(x) + self.alpha * x
# 再次转置回原来的维度
x = x.transpose(1, 2)
return x
定义一个线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册缓冲区,用于存储 warm-up 计数器和迭代次数
self.register_buffer(‘warm’, torch.tensor(warm))
self.register_buffer(‘iter’, torch.tensor(step))
self.register_buffer(‘total_step’, torch.tensor(step))
self.r0 = r0 # 初始比例
# 初始化两个归一化层
self.norm1 = norm1(dim)
self.norm2 = norm2(dim)
def forward(self, x):
if self.training: # 如果模型处于训练模式
if self.warm > 0: # 如果还有 warm-up 轮次
self.warm.copy_(self.warm - 1) # 减少 warm-up 计数
x = self.norm1(x) # 进行第一次归一化
else:
# 计算当前的 lamda 值,控制归一化的比例
lamda = self.r0 * self.iter / self.total_step
if self.iter > 0:
self.iter.copy_(self.iter - 1) # 减少迭代次数
# 进行两次归一化
x1 = self.norm1(x)
x2 = self.norm2(x)
# 根据 lamda 值进行线性组合
x = lamda * x1 + (1 - lamda) * x2
else:
# 如果模型处于评估模式,直接使用第二个归一化层
x = self.norm2(x)
return x
代码说明:
RepBN 类:
该类实现了一种自定义的批量归一化方法,除了标准的批量归一化外,还引入了一个可学习的参数 alpha,用于调整输入的影响。
在 forward 方法中,输入张量的维度被转置,以符合 BatchNorm1d 的要求,经过归一化处理后,再加上 alpha 乘以输入张量,最后再转置回原来的维度。
LinearNorm 类:
该类实现了一种线性归一化策略,结合了两个不同的归一化方法(norm1 和 norm2),并通过一个动态调整的比例 lamda 来平衡它们的影响。
在训练过程中,首先检查是否在 warm-up 阶段,如果是,则只使用 norm1 进行归一化;一旦 warm-up 结束,就根据当前的迭代次数计算 lamda,并将 norm1 和 norm2 的输出进行线性组合。
在评估模式下,直接使用 norm2 进行归一化。
这个程序文件 prepbn.py 定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都继承自 PyTorch 的 nn.Module 类,用于实现特定的归一化操作。
RepBN 类实现了一种自定义的批量归一化(Batch Normalization)。在初始化方法中,它接收一个参数 channels,用于指定输入数据的通道数。RepBN 中定义了一个可学习的参数 alpha,初始值为 1,并且创建了一个标准的 1D 批量归一化层 bn。在前向传播方法 forward 中,输入张量 x 首先进行维度转换,将通道维和序列维互换,以适应批量归一化的要求。接着,输入经过批量归一化处理后,加上 alpha 乘以原始输入 x,最后再进行一次维度转换,返回处理后的结果。这种结构允许模型在训练过程中自适应地调整输入的归一化方式。
LinearNorm 类则实现了一种线性归一化策略。它的初始化方法接收多个参数,包括维度 dim、两个归一化方法 norm1 和 norm2,以及用于控制训练过程的参数 warm、step 和 r0。在初始化时,warm 和 iter 被注册为缓冲区,便于在训练过程中保持状态。LinearNorm 的前向传播方法根据模型的训练状态决定使用哪种归一化策略。如果模型处于训练状态且 warm 大于 0,则调用 norm1 进行归一化,并将 warm 减 1。如果 warm 为 0,则计算一个动态的权重 lamda,它与当前迭代次数和总步数有关。接着,分别使用 norm1 和 norm2 对输入 x 进行归一化,并根据 lamda 的值对两者的结果进行加权平均。如果模型不在训练状态,则直接使用 norm2 对输入进行归一化。
总体而言,这个文件提供了两种灵活的归一化方法,适用于不同的训练阶段和需求,可以帮助提高模型的训练效果和稳定性。
10.4 SwinTransformer.py
以下是经过简化和注释的核心代码部分,主要包括Swin Transformer的基本结构和功能实现。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Mlp(nn.Module):
“”" 多层感知机 (MLP) 模块。“”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):
""" 前向传播函数。"""
x = self.fc1(x) # 线性变换
x = self.act(x) # 激活
x = self.drop(x) # Dropout
x = self.fc2(x) # 线性变换
x = self.drop(x) # Dropout
return x
class WindowAttention(nn.Module):
“”" 窗口注意力机制模块。“”"
def __init__(self, dim, window_size, num_heads):
super().__init__()
self.dim = dim
self.window_size = window_size # 窗口大小
self.num_heads = num_heads # 注意力头数
head_dim = dim // num_heads # 每个头的维度
self.scale = head_dim ** -0.5 # 缩放因子
# 位置偏置参数
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
# 计算相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标网格
coords_flatten = torch.flatten(coords, 1) # 展平
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 调整维度
relative_coords[:, :, 0] += self.window_size[0] - 1 # 位置偏移
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
self.relative_position_index = relative_coords.sum(-1) # 计算相对位置索引
self.qkv = nn.Linear(dim, dim * 3) # 线性变换生成Q, K, V
self.attn_drop = nn.Dropout(0.) # 注意力的Dropout
self.proj = nn.Linear(dim, dim) # 输出线性变换
def forward(self, x, mask=None):
""" 前向传播函数。"""
B_, N, C = x.shape # B: 批量大小, N: 窗口内的token数, C: 特征维度
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # 分离Q, K, V
q = q * self.scale # 缩放Q
attn = (q @ k.transpose(-2, -1)) # 计算注意力分数
# 添加相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
attn = attn + relative_position_bias.unsqueeze(0) # 加入偏置
attn = F.softmax(attn, dim=-1) # 归一化
attn = self.attn_drop(attn) # Dropout
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出
x = self.proj(x) # 输出线性变换
return x
class SwinTransformerBlock(nn.Module):
“”" Swin Transformer基本块。“”"
def __init__(self, dim, num_heads, window_size=7, shift_size=0):
super().__init__()
self.norm1 = nn.LayerNorm(dim) # 归一化层
self.attn = WindowAttention(dim, window_size, num_heads) # 窗口注意力模块
self.norm2 = nn.LayerNorm(dim) # 归一化层
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * 4)) # MLP模块
def forward(self, x):
""" 前向传播函数。"""
shortcut = x # 残差连接
x = self.norm1(x) # 归一化
x = self.attn(x) # 注意力计算
x = shortcut + x # 残差连接
x = x + self.mlp(self.norm2(x)) # MLP处理
return x
class SwinTransformer(nn.Module):
“”" Swin Transformer主模型。“”"
def __init__(self, depths, num_heads):
super().__init__()
self.layers = nn.ModuleList([
SwinTransformerBlock(dim=96 * (2 ** i), num_heads=num_heads[i]) for i in range(len(depths))
]) # 构建多个Swin Transformer块
def forward(self, x):
""" 前向传播函数。"""
for layer in self.layers:
x = layer(x) # 逐层传递
return x
def SwinTransformer_Tiny(weights=‘’):
“”" 创建一个小型Swin Transformer模型。“”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]) # 定义模型结构
if weights:
model.load_state_dict(torch.load(weights)[‘model’]) # 加载预训练权重
return model
代码说明:
Mlp:实现了一个简单的多层感知机,包含两层线性变换和激活函数。
WindowAttention:实现了窗口注意力机制,支持相对位置偏置。
SwinTransformerBlock:构建了Swin Transformer的基本块,包含注意力机制和MLP模块。
SwinTransformer:主模型,包含多个Swin Transformer块。
SwinTransformer_Tiny:创建一个小型的Swin Transformer模型,并可选择加载预训练权重。
该代码实现了Swin Transformer的核心结构,适用于图像处理和计算机视觉任务。
这个程序文件实现了Swin Transformer模型的PyTorch版本,主要用于计算机视觉任务。Swin Transformer是一种分层的视觉Transformer架构,采用了移动窗口机制来处理图像。文件中包含多个类和函数,以下是对其主要部分的讲解。
首先,程序导入了必要的库,包括PyTorch和一些常用的模块。接着定义了一个多层感知机(Mlp)类,它由两个线性层和一个激活函数组成,用于在Transformer中进行特征转换。
接下来,定义了两个函数window_partition和window_reverse,用于将输入特征分割成窗口和将窗口合并回原始特征。这种窗口划分是Swin Transformer的核心思想之一,能够有效地处理局部信息。
WindowAttention类实现了基于窗口的多头自注意力机制。它支持相对位置偏置,并能够处理移动窗口的情况。这个类的forward方法计算输入特征的注意力权重,并应用于值(value)上,最终输出经过注意力机制处理的特征。
SwinTransformerBlock类是Swin Transformer的基本构建块,它结合了窗口注意力和前馈网络(FFN)。在forward方法中,输入特征首先经过归一化,然后进行窗口划分和注意力计算,最后通过前馈网络进行处理。
PatchMerging类用于将特征图的不同区域合并成更大的补丁,以减少特征的空间维度。这是Swin Transformer中进行下采样的方式。
BasicLayer类表示Swin Transformer中的一个基本层,包含多个Swin Transformer块,并在必要时进行下采样。它还计算了用于自注意力的掩码。
PatchEmbed类负责将输入图像分割成补丁并进行嵌入。它使用卷积层将图像转换为补丁特征,并可以选择性地应用归一化。
SwinTransformer类是整个模型的核心,构建了多个基本层,并处理输入图像的补丁嵌入和位置编码。它还支持对不同层的输出进行归一化。
最后,定义了一个update_weight函数,用于加载预训练模型的权重,并定义了一个SwinTransformer_Tiny函数,用于创建一个小型的Swin Transformer模型实例。
总体而言,这个程序实现了Swin Transformer的完整结构,适用于图像分类、目标检测等计算机视觉任务。通过窗口机制和分层结构,Swin Transformer能够有效地捕捉图像中的局部和全局特征。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)