【完整源码+数据集+部署教程】 楼梯区域分割系统源码&数据集分享 [yolov8-seg-FocalModulation&yolov8-seg-GFPN等50+全套改进创新点发刊_一键训练教程_We
【完整源码+数据集+部署教程】 楼梯区域分割系统源码&数据集分享[yolov8-seg-FocalModulation&yolov8-seg-GFPN等50+全套改进创新点发刊_一键训练教程_We
背景意义
随着城市化进程的加快,楼梯作为重要的建筑元素,广泛应用于公共场所、住宅及商业建筑中。楼梯不仅是人们日常出行的重要通道,也是建筑设计中不可或缺的组成部分。然而,楼梯区域的识别与分割在计算机视觉领域仍然面临诸多挑战,尤其是在复杂环境下的准确性和实时性问题。因此,开发一种高效的楼梯区域分割系统具有重要的理论价值和实际意义。
近年来,深度学习技术的迅猛发展为图像分割任务提供了新的解决方案。其中,YOLO(You Only Look Once)系列模型因其出色的实时检测能力和较高的准确性,成为了目标检测领域的热门选择。YOLOv8作为该系列的最新版本,进一步提升了模型的性能,尤其在小目标检测和复杂背景下的表现。基于YOLOv8的楼梯区域分割系统,能够有效地处理楼梯的多样性和复杂性,为建筑智能化和安全监测提供技术支持。
本研究将基于一个包含1500张图像的楼梯数据集进行模型训练与验证。该数据集涵盖了五个类别:草地、地面、坡道、道路和楼梯,具有较强的代表性和多样性。通过对这些类别的实例分割,能够更好地理解楼梯在不同环境中的表现及其与周围环境的关系。这不仅有助于提升楼梯区域的自动识别能力,还能为后续的智能导航、建筑安全监测及无障碍设计提供数据支持。
在实际应用中,楼梯区域的准确分割对于提升建筑物的安全性和可达性至关重要。尤其是在公共场所,楼梯往往是人流密集的区域,任何对楼梯的误判都可能导致安全隐患。因此,基于改进YOLOv8的楼梯区域分割系统,不仅可以提高楼梯的识别精度,还能为智能监控系统提供实时数据,进而提升公共安全管理的效率。
此外,随着智能家居和智慧城市的兴起,楼梯区域的智能化管理逐渐成为研究热点。通过本研究所开发的分割系统,可以为楼梯的智能化改造提供技术基础。例如,在无障碍设计中,系统能够实时监测楼梯的使用情况,并根据人流量进行动态调整,优化楼梯的使用效率和安全性。同时,该系统还可以与其他智能设备进行联动,实现更为复杂的场景感知与响应。
综上所述,基于改进YOLOv8的楼梯区域分割系统的研究,不仅具有重要的学术价值,也为实际应用提供了广阔的前景。通过深入探索楼梯区域的分割技术,我们可以为建筑设计、城市规划及智能监控等领域提供创新的解决方案,推动相关技术的进步与发展。
图片效果
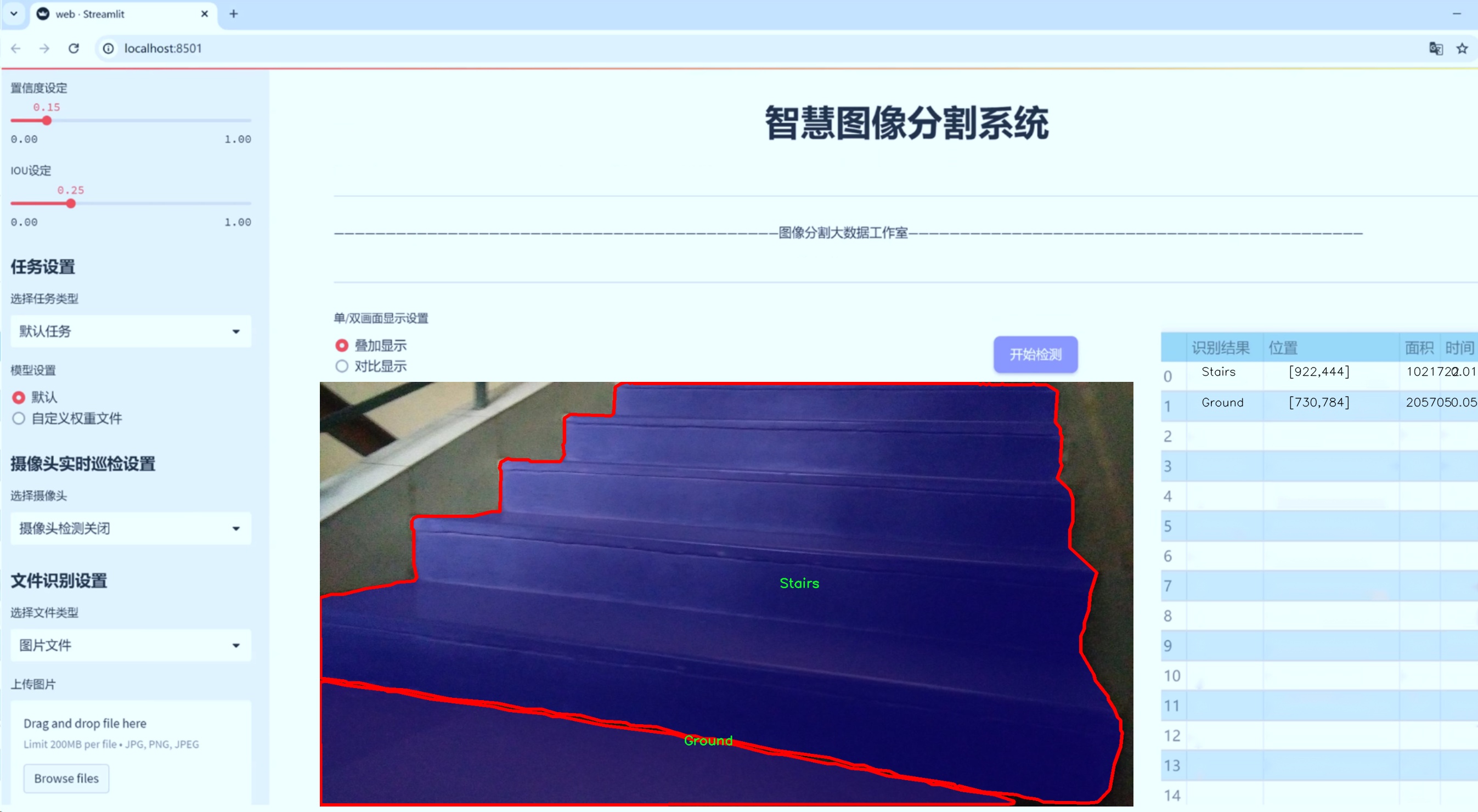
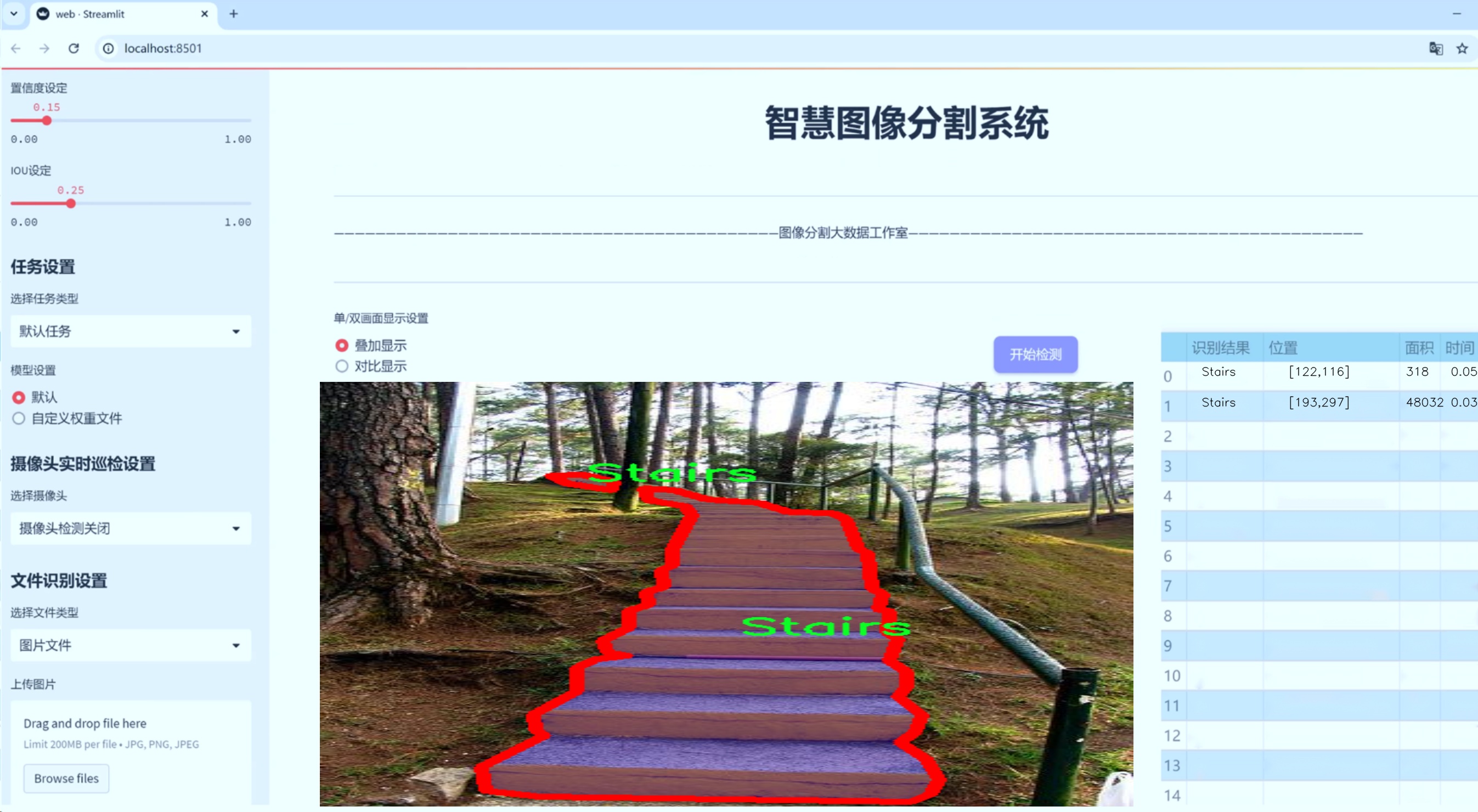
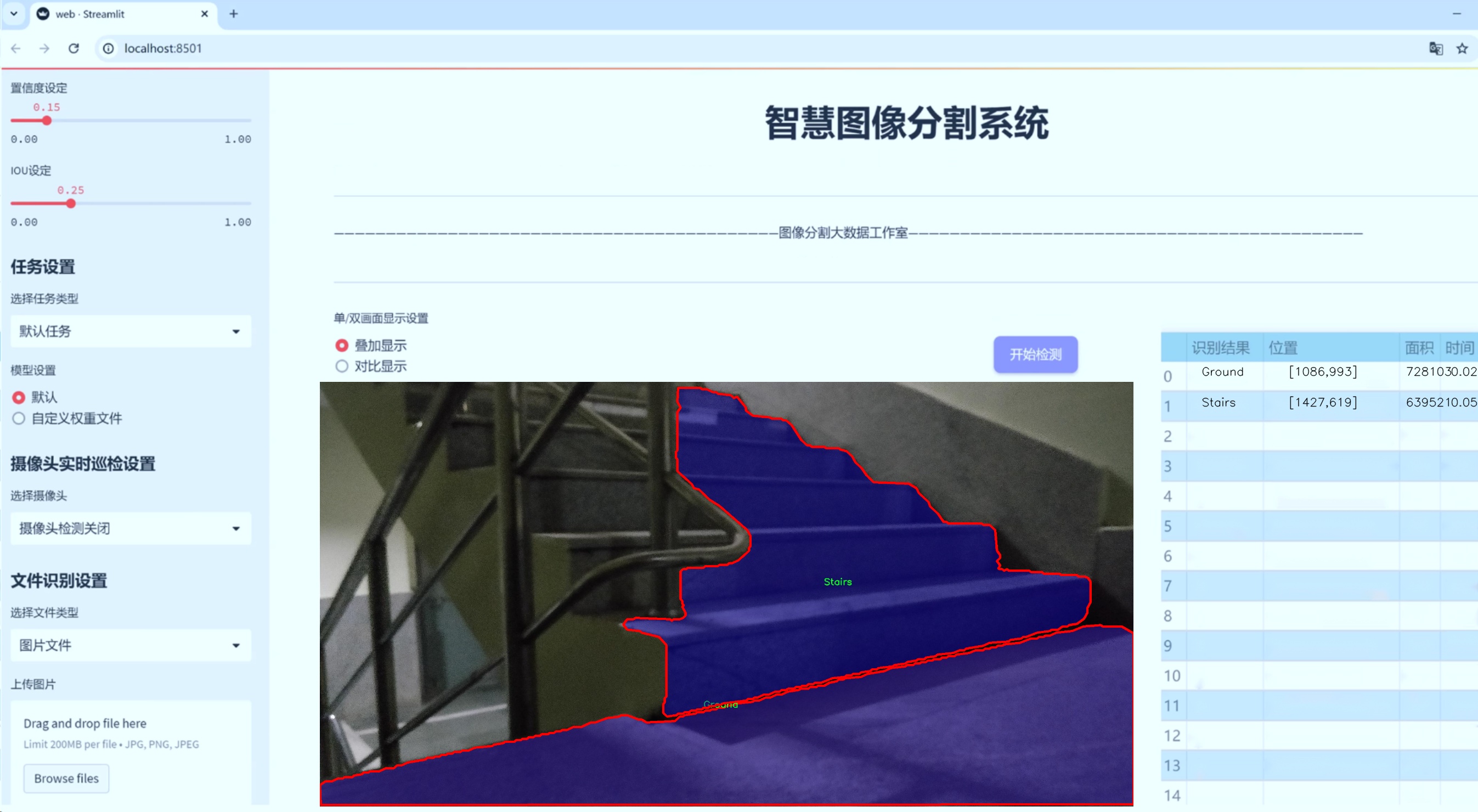
数据集信息
在本研究中,我们使用了名为“Stairs”的数据集,以改进YOLOv8-seg模型在楼梯区域分割任务中的表现。该数据集专门设计用于训练和评估模型在复杂环境中对楼梯及其周边区域的识别能力。数据集包含五个类别,分别为“Grass”(草地)、“Ground”(地面)、“Ramp”(坡道)、“Road”(道路)和“Stairs”(楼梯),这些类别的选择旨在覆盖楼梯周围常见的环境特征,从而为模型提供丰富的上下文信息。
数据集的构建经过精心设计,确保每个类别的样本数量和多样性,以增强模型的泛化能力。首先,草地和地面作为楼梯周围的基础环境,提供了重要的背景信息。草地通常出现在户外场景中,而地面则可以是各种材质的平坦表面,这两者的多样性有助于模型在不同环境下的适应性。坡道作为连接不同高度的过渡区域,能够帮助模型学习到楼梯与周围环境的关系,尤其是在复杂的场景中,坡道的存在往往会影响楼梯的可见性和可达性。
此外,道路类别的引入则进一步丰富了数据集的应用场景,尤其是在城市环境中,楼梯往往与道路相连,模型需要能够有效地区分这些区域,以实现准确的分割。最后,楼梯类别本身是数据集的核心,包含了多种类型的楼梯设计和结构,确保模型能够识别出不同形状、材质和角度的楼梯。
在数据集的构建过程中,所有图像均经过标注,确保每个类别的区域都被准确地划分。这一过程不仅提高了数据集的质量,也为后续的模型训练提供了可靠的基础。为了增强模型的鲁棒性,数据集还包括了不同光照条件、天气状况和视角下的图像,确保模型在实际应用中能够应对各种挑战。
通过使用“Stairs”数据集,我们期望改进YOLOv8-seg模型在楼梯区域分割任务中的性能。该数据集的多样性和丰富性将为模型提供充分的训练数据,使其能够在复杂环境中准确识别和分割楼梯区域。这不仅有助于提升模型的精度,也为后续的实际应用提供了坚实的基础。我们相信,经过充分训练的模型将在楼梯识别和分割领域取得显著进展,为智能交通、建筑设计以及无障碍设施等领域的应用提供强有力的支持。




核心代码
```python
import time
import pandas as pd
from ultralytics import YOLO
from ultralytics.utils import select_device, check_requirements
def benchmark(model='yolov8n.pt', imgsz=160, device='cpu', verbose=False):
"""
对YOLO模型进行基准测试,评估不同格式的速度和准确性。
参数:
model (str): 模型文件的路径,默认为'yolov8n.pt'。
imgsz (int): 测试时使用的图像大小,默认为160。
device (str): 运行基准测试的设备,默认为'cpu'。
verbose (bool): 如果为True,将显示详细的错误信息,默认为False。
返回:
df (pandas.DataFrame): 包含每种格式的基准测试结果的DataFrame,包括文件大小、指标和推理时间。
"""
pd.options.display.max_columns = 10 # 设置显示的最大列数
device = select_device(device, verbose=False) # 选择设备
model = YOLO(model) # 加载YOLO模型
results = [] # 存储结果
start_time = time.time() # 记录开始时间
# 遍历不同的导出格式
for i, (name, format, suffix, cpu, gpu) in export_formats().iterrows():
emoji, filename = '❌', None # 默认导出状态为失败
try:
# 检查设备支持情况
if 'cpu' in device.type:
assert cpu, 'CPU不支持此推理'
if 'cuda' in device.type:
assert gpu, 'GPU不支持此推理'
# 导出模型
if format == '-':
filename = model.ckpt_path or model.cfg # PyTorch格式
else:
filename = model.export(imgsz=imgsz, format=format, device=device, verbose=False)
exported_model = YOLO(filename) # 加载导出的模型
assert suffix in str(filename), '导出失败'
emoji = '✅' # 导出成功
# 进行推理
exported_model.predict('assets/bus.jpg', imgsz=imgsz, device=device)
# 验证模型
results_dict = exported_model.val(data='coco8.yaml', batch=1, imgsz=imgsz, device=device)
metric, speed = results_dict.results_dict['mAP'], results_dict.speed['inference']
results.append([name, emoji, round(file_size(filename), 1), round(metric, 4), round(speed, 2)])
except Exception as e:
if verbose:
print(f'基准测试失败: {name}: {e}')
results.append([name, emoji, None, None, None]) # 记录失败信息
# 打印结果
df = pd.DataFrame(results, columns=['格式', '状态', '大小 (MB)', '指标', '推理时间 (ms/im)'])
print(df) # 输出结果
return df # 返回结果DataFrame
代码分析与注释
-
导入必要的库:
time:用于记录时间。pandas:用于数据处理和结果展示。YOLO:从ultralytics库中导入YOLO模型。select_device:选择运行设备(CPU或GPU)。
-
benchmark函数:- 该函数用于对YOLO模型进行基准测试,评估不同格式的速度和准确性。
- 参数包括模型路径、图像大小、设备类型和详细输出标志。
-
结果存储与时间记录:
- 使用
results列表存储每种格式的测试结果。 - 记录基准测试开始的时间。
- 使用
-
遍历导出格式:
- 使用
export_formats()获取支持的导出格式。 - 对每种格式进行模型导出和推理测试。
- 使用
-
模型导出与推理:
- 检查当前设备是否支持推理。
- 根据格式导出模型并进行推理。
- 验证模型的准确性并记录结果。
-
异常处理:
- 捕获可能的异常并记录失败信息,若
verbose为True则输出详细错误信息。
- 捕获可能的异常并记录失败信息,若
-
结果输出:
- 使用
pandas.DataFrame格式化结果并打印。
- 使用
这个函数的核心功能是评估YOLO模型在不同格式下的性能,包括导出、推理和准确性验证,最终返回一个包含所有测试结果的DataFrame。```
这个文件是Ultralytics YOLO项目中的一个基准测试模块,主要用于评估YOLO模型在不同格式下的速度和准确性。文件中包含了两个主要的类和多个函数,分别用于基准测试和模型性能分析。
首先,文件的开头部分是一些文档字符串,介绍了如何使用这个模块。用户可以通过导入ProfileModels和benchmark函数来进行模型的基准测试。提供了多种模型格式的支持,包括PyTorch、ONNX、TensorRT等。
接下来是benchmark函数,它的主要功能是对指定的YOLO模型进行基准测试。函数接受多个参数,包括模型路径、数据集、图像大小、是否使用半精度和整数量化等。函数内部首先选择设备(CPU或GPU),然后加载模型。接着,函数遍历支持的导出格式,尝试将模型导出为不同格式,并对每种格式进行推理和验证。最后,函数会将结果以DataFrame的形式返回,并记录基准测试的日志。
ProfileModels类则用于对不同模型进行性能分析。它的构造函数接受模型路径、定时运行次数、预热运行次数、最小运行时间、图像大小等参数。profile方法会收集指定路径下的模型文件,并对每个模型进行TensorRT和ONNX格式的性能分析。该方法还会生成一个表格,显示每个模型的性能指标,包括推理时间、参数数量和FLOPs等。
文件中还定义了一些辅助函数,例如get_files用于获取模型文件,get_onnx_model_info用于提取ONNX模型的信息,iterative_sigma_clipping用于对运行时间进行迭代的sigma剪切,以去除异常值,profile_tensorrt_model和profile_onnx_model分别用于分析TensorRT和ONNX模型的性能。
最后,generate_table_row和generate_results_dict函数用于生成表格行和结果字典,方便输出模型的性能数据。print_table函数则负责格式化并打印出模型的比较表。
总的来说,这个文件提供了一套完整的工具,用于评估和比较YOLO模型在不同格式下的性能,帮助用户选择最适合其需求的模型格式。
```python
import numpy as np
import torch
def box_iou(box1, box2, eps=1e-7):
"""
计算两个边界框的交并比(IoU)。
参数:
box1 (torch.Tensor): 形状为 (N, 4) 的张量,表示 N 个边界框。
box2 (torch.Tensor): 形状为 (M, 4) 的张量,表示 M 个边界框。
eps (float, optional): 避免除以零的小值,默认为 1e-7。
返回:
(torch.Tensor): 形状为 (N, M) 的张量,包含 box1 和 box2 中每对边界框的 IoU 值。
"""
# 计算交集区域
(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp_(0).prod(2)
# 计算每个框的面积
area1 = (a2 - a1).prod(2)
area2 = (b2 - b1).prod(2)
# 计算 IoU
return inter / (area1 + area2 - inter + eps)
def bbox_iou(box1, box2, xywh=True, eps=1e-7):
"""
计算边界框 box1 (1, 4) 与 box2 (n, 4) 的交并比(IoU)。
参数:
box1 (torch.Tensor): 形状为 (1, 4) 的张量,表示单个边界框。
box2 (torch.Tensor): 形状为 (n, 4) 的张量,表示 n 个边界框。
xywh (bool, optional): 如果为 True,输入框为 (x, y, w, h) 格式;如果为 False,输入框为 (x1, y1, x2, y2) 格式。默认为 True。
eps (float, optional): 避免除以零的小值,默认为 1e-7。
返回:
(torch.Tensor): IoU 值。
"""
# 将 (x, y, w, h) 转换为 (x1, y1, x2, y2) 格式
if xywh:
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1 / 2, x1 + w1 / 2, y1 - h1 / 2, y1 + h1 / 2
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2 / 2, x2 + w2 / 2, y2 - h2 / 2, y2 + h2 / 2
else:
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
# 计算交集区域
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)
# 计算并集区域
union = (b1_x2 - b1_x1).prod() + (b2_x2 - b2_x1).prod() - inter + eps
# 计算 IoU
return inter / union
def compute_ap(recall, precision):
"""
计算给定召回率和精确率曲线的平均精度(AP)。
参数:
recall (list): 召回率曲线。
precision (list): 精确率曲线。
返回:
(float): 平均精度。
"""
# 在开头和结尾添加哨兵值
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([1.0], precision, [0.0]))
# 计算精确率包络线
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# 计算曲线下面积
ap = np.trapz(mpre, mrec) # 使用梯形法则积分
return ap
代码说明:
- box_iou:计算两个边界框之间的交并比(IoU),返回一个形状为 (N, M) 的张量,表示每对边界框的 IoU 值。
- bbox_iou:计算单个边界框与多个边界框之间的 IoU,支持 (x, y, w, h) 和 (x1, y1, x2, y2) 两种格式。
- compute_ap:计算给定的召回率和精确率曲线的平均精度(AP),通过插值和积分来计算曲线下面积。```
这个程序文件ultralytics/utils/metrics.py是用于计算和评估模型性能的各种指标,特别是在目标检测和分类任务中。文件中包含多个函数和类,主要用于计算交并比(IoU)、平均精度(AP)、混淆矩阵等指标。
首先,文件中定义了一些用于计算交并比的函数,包括 bbox_ioa、box_iou 和 bbox_iou。这些函数能够处理不同格式的边界框(bounding boxes),并计算它们之间的重叠程度。bbox_ioa 计算的是 box1 在 box2 上的交集比率,而 box_iou 则计算两个边界框之间的标准 IoU。bbox_iou 函数则支持多种 IoU 计算方式,包括普通 IoU、广义 IoU(GIoU)、距离 IoU(DIoU)等。
接下来,文件中还定义了一些用于计算和更新混淆矩阵的类,例如 ConfusionMatrix。这个类用于在目标检测和分类任务中跟踪预测结果和真实标签之间的关系。它能够处理分类预测和检测结果,并根据 IoU 阈值更新混淆矩阵。混淆矩阵的可视化功能也被实现,能够生成热图并保存到指定目录。
此外,文件中还有多个用于计算精度、召回率和平均精度的类,如 Metric、DetMetrics、SegmentMetrics 和 PoseMetrics。这些类提供了多种方法来计算和更新模型的性能指标,包括每个类别的平均精度、F1 分数等。它们还可以生成 PR 曲线和其他可视化图表,以便于分析模型的性能。
文件的最后部分定义了 ClassifyMetrics 类,用于计算分类任务的准确率,包括 top-1 和 top-5 准确率。这个类同样提供了计算和更新模型性能的功能,并能够返回相关的性能指标。
总的来说,这个文件提供了一整套用于评估目标检测和分类模型性能的工具,涵盖了从基本的 IoU 计算到复杂的混淆矩阵和性能指标计算的各个方面,适用于深度学习模型的训练和评估过程。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)