即插即用还涨点!ICCV 2025 LEG:边缘-高斯-双注意力,非常涨点的三重增强轻量模块,显著提升视觉任务性能
遥感图像目标检测()任务常受到低空间分辨率、传感器噪声、运动模糊及不利光照等多重降质因素的困扰。这些因素削弱了目标的特征独特性,导致表示模糊和前景-背景分离困难。现有方法,特别是轻量化模型,在处理低质量目标时表现出局限性。为应对这些挑战,本文提出了一种名为的轻量级骨干网络,其核心是新颖的来锐化模糊或低对比度目标中易于丢失的关键边缘细节,并利用来抑制噪声、规整模糊的特征响应,从而在挑战性条件下增强前
遥感图像目标检测(RSOD)任务常受到低空间分辨率、传感器噪声、运动模糊及不利光照等多重降质因素的困扰。这些因素削弱了目标的特征独特性,导致表示模糊和前景-背景分离困难。现有方法,特别是轻量化模型,在处理低质量目标时表现出局限性。
为应对这些挑战,本文提出了一种名为LEGNet的轻量级骨干网络,其核心是新颖的边缘-高斯聚合(EGA)模块。该方法巧妙地将传统图像处理技术与现代深度学习相结合:EGA模块通过引入方向感知的Scharr滤波器来锐化模糊或低对比度目标中易于丢失的关键边缘细节,并利用基于高斯先验的特征精炼来抑制噪声、规整模糊的特征响应,从而在挑战性条件下增强前景的显著性。
本文的主要贡献在于:
1)提出了EGA模块,有效应对低质量遥感图像中的特征退化问题;
2)构建了基于EGA的轻量级网络LEGNet,在保持计算效率的同时,显著提升了对模糊、遮挡等挑战性目标的检测性能;
3)在DOTA、DIOR-R等五个主流遥感检测基准上验证了LEGNet的卓越性能,证明了其在资源受限场景下的实用价值。
01 论文基本信息

- 标题: LEGNet: A Lightweight Edge-Gaussian Network for Low-Quality Remote Sensing Image Object Detection
- 核心模块: LoG-Stem层、轻量级边缘-高斯(LEG)模块、边缘-高斯聚合(EGA)模块(包含边缘提取与高斯建模)
02 算法框架与核心模块
2.1 算法框架
LEGNet是一个四阶段的骨干网络架构。输入图像首先通过一个LoG-Stem层进行初步的边缘感知下采样。随后,特征图在四个阶段中被逐步处理。每个阶段由多个LEG Block堆叠而成,用于深度特征提炼。阶段之间通过下采样模块降低分辨率,最终生成1/4, 1/8, 1/16, 和1/32四种尺度的特征图,供后续的检测头使用。
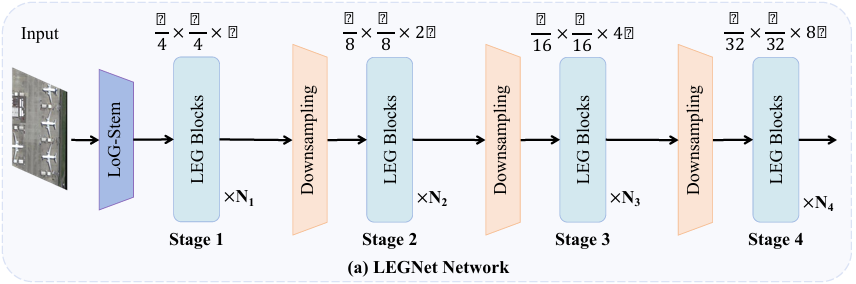
2.2 核心模块
模块一:LoG-Stem层
- 核心功能: 在网络初始阶段进行下采样,同时抑制噪声并增强对边缘等高频信息的捕捉能力,为后续网络提供更鲁棒的初始特征。
- 实现逻辑: 该模块首先使用一个7x7卷积提取初步特征,随后利用一个拉普拉斯-高斯(LoG)滤波器来锐化边缘。LoG算子的定义如下:
LoGk×kσ(x)=1πσ4(1−i2+j2σ2)e−i2+j22σ2 \text{LoG}_{k \times k}^{\sigma}(x) = \frac{1}{\pi\sigma^4} \left( 1 - \frac{i^2+j^2}{\sigma^2} \right) e^{-\frac{i^2+j^2}{2\sigma^2}} LoGk×kσ(x)=πσ41(1−σ2i2+j2)e−2σ2i2+j2
其中(i,j)是核内坐标,σ是高斯标准差。通过残差连接融合原始特征和LoG滤波后的特征,保留了图像细节。最后通过卷积层和下采样模块,生成1/4分辨率的特征图。 - 优势: 相比于标准的Stem层(如大步长卷积),LoG-Stem层利用经典的LoG算子,能够在网络早期就有效地从含噪、退化的遥感图像中提取关键的边缘结构,为检测低质量目标奠定了坚实基础。
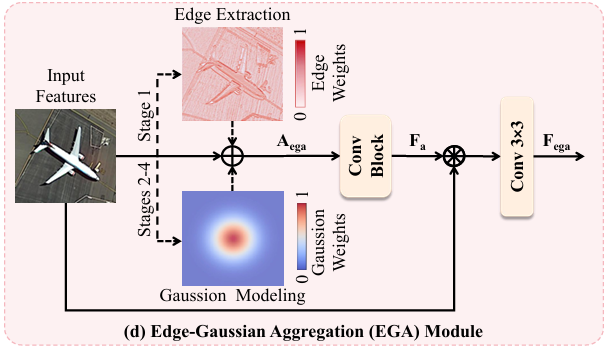
模块二:边缘-高斯聚合(EGA)模块
-
核心功能: 根据网络层深度的不同,自适应地采用边缘提取或高斯建模策略来优化特征图,旨在增强浅层网络的边缘细节并平滑深层网络的语义特征。
-
实现逻辑: EGA模块的设计如论文图2(d)所示,其行为取决于所在的阶段:
- 边缘提取 (Stage 1): 在浅层网络(第一阶段),利用固定的Scharr滤波器(一种改进的Sobel算子,具有更好的旋转不变性)提取水平和垂直方向的边缘梯度
A_edge,以保留和增强物体的轮廓信息。
Sx=[−303−10010−303],Sy=[−3−10−30003103] S_x = \begin{bmatrix} -3 & 0 & 3 \\ -10 & 0 & 10 \\ -3 & 0 & 3 \end{bmatrix}, \quad S_y = \begin{bmatrix} -3 & -10 & -3 \\ 0 & 0 & 0 \\ 3 & 10 & 3 \end{bmatrix} Sx= −3−10−30003103 ,Sy= −303−10010−303 - 高斯建模 (Stage 2-4): 在深层网络(第二至四阶段),边缘信息变得模糊,而物体特征趋向于高斯分布。此时,模块采用一个固定的5x5高斯核进行深度卷积操作
A_gauss,以平滑特征响应,抑制噪声,并强化核心特征区域。
无论是A_edge还是A_gauss,其输出A_ega都会与输入特征F_in相加,并通过一个卷积块(Conv Block)进行深度融合,最终生成优化后的特征F_ega。
- 边缘提取 (Stage 1): 在浅层网络(第一阶段),利用固定的Scharr滤波器(一种改进的Sobel算子,具有更好的旋转不变性)提取水平和垂直方向的边缘梯度
-
优势: EGA模块的核心创新在于将传统图像处理的先验知识(边缘检测和高斯平滑)作为一种即插即用的注意力机制融入深度网络。这种混合设计使得网络能够在不同阶段关注不同类型的特征:浅层关注结构,深层关注语义,从而在几乎不增加可学习参数的情况下,显著提升了对低质量目标的表征能力。
03 模块适用任务
- 核心应用场景: 本文方法主要针对遥感图像中的旋转目标检测任务,尤其在处理由传感器限制或成像条件不佳导致的低质量(如模糊、低对比度、部分遮挡)目标时表现突出。
- 方法论核心: 其最本质的思想是**“先验引导的特征增强”**。它不完全依赖数据驱动的学习,而是将经典的、被证明有效的图像处理算子(如LoG、Scharr、Gaussian)作为固定的“专家核”,嵌入到现代CNN架构中,以低成本的方式引导网络关注对特定任务(如边缘感知)至关重要的信息。
- 启发性拓展:
- 任务泛化: 该框架中的边缘与高斯先验对于其他需要精细结构信息或对噪声敏感的视觉任务(如遥感图像的语义分割、变化检测)同样具有应用潜力。
- 动态核选择: 目前EGA模块的策略是固定的(浅层用边缘,深层用高斯)。未来可以探索让网络根据输入特征动态地、自适应地选择或融合不同的“专家核”,使其更具灵活性。
04 实验结果与可视化分析
核心实验与结论
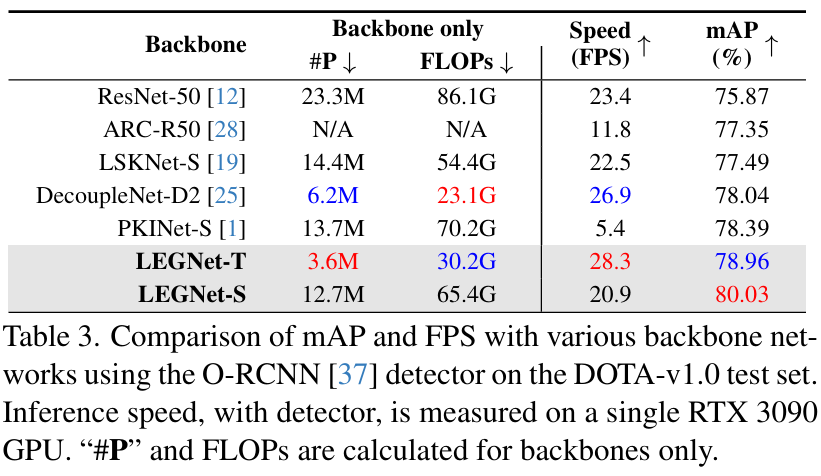
论文在表3中对不同骨干网络在DOTA-v1.0数据集上的性能、参数量、计算量和推理速度进行了综合比较,这一实验最能体现本文的核心贡献。
-
实验目的: 该实验旨在验证LEGNet作为骨干网络在遥感目标检测任务中,相较于其他SOTA(State-of-the-Art)骨干网络(如ResNet-50, LSKNet-S, PKINet-S等),能否在效率和精度之间取得更优的平衡。
-
关键结果:
- 精度: LEGNet-S取得了80.03% mAP的最高精度,超越了所有对比方法,包括之前性能领先的PKINet-S(78.39% mAP)。
- 效率: 轻量级版本的LEGNet-T仅用3.6M参数和30.2G FLOPs就达到了78.96% mAP,相比当时最高效的DecoupleNet-D2,参数量减少了41.9%,mAP反而提升了0.92%。
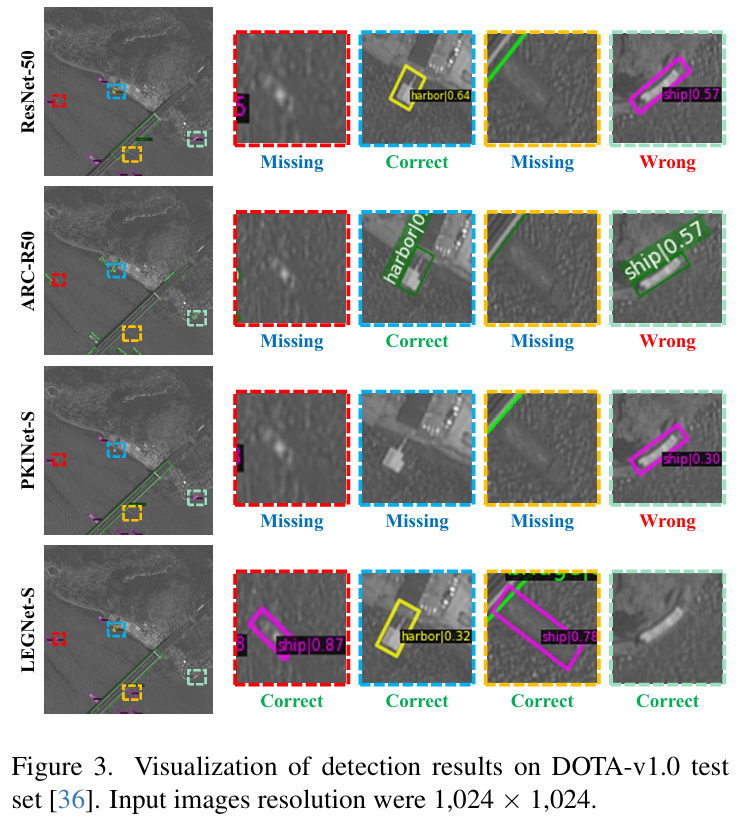
- 可视化分析: 如论文图3所示,在面对模糊、低质量的船舶目标时,ResNet-50、ARC-R50和PKINet-S均出现了漏检或错检,而LEGNet-S能够准确无误地检测出所有目标,证明了其在挑战性场景下的鲁棒性。
-
作者结论: 作者基于这些数据得出结论:LEGNet不仅在精度上设立了新的行业标杆(首次在DOTA-v1.0单尺度测试中突破80% mAP),且在模型轻量化和计算效率上展现出巨大优势。这证明了通过融合传统图像处理先验来增强低质量特征的策略是高效且实用的,使LEGNet非常适合部署在无人机、卫星等资源受限的边缘计算平台。
05 即插即用模块代码
LoG-Stem 层(LoGFilter + 下采样 + Gaussian + DRFD)
- 核心功能:在输入端进行边缘增强与抗噪下采样,输出鲁棒的 1/4 分辨率特征。
- 核心优势:用 LoG 与高斯先验引导早期特征,保住结构信息同时降低噪声,对低质量遥感图像更稳健。
- 核心代码(片段):
import math
import torch
import torch.nn as nn
from mmcv.cnn import build_norm_layer
class Conv_Extra(nn.Module):
def __init__(self, channel, norm_layer, act_layer):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(channel, 64, 1),
build_norm_layer(norm_layer, 64)[1],
act_layer(),
nn.Conv2d(64, 64, 3, stride=1, padding=1, dilation=1, bias=False),
build_norm_layer(norm_layer, 64)[1],
act_layer(),
nn.Conv2d(64, channel, 1),
build_norm_layer(norm_layer, channel)[1],
)
def forward(self, x): return self.block(x)
class Gaussian(nn.Module):
def __init__(self, dim, size, sigma, norm_layer, act_layer, feature_extra=True):
super().__init__()
self.feature_extra = feature_extra
kernel = self.gaussian_kernel(size, sigma)
kernel = nn.Parameter(data=kernel, requires_grad=False).clone()
self.gaussian = nn.Conv2d(dim, dim, kernel_size=size, stride=1, padding=int(size // 2), groups=dim, bias=False)
self.gaussian.weight.data = kernel.repeat(dim, 1, 1, 1)
self.norm = build_norm_layer(norm_layer, dim)[1]
self.act = act_layer()
if feature_extra: self.conv_extra = Conv_Extra(dim, norm_layer, act_layer)
def forward(self, x):
g = self.act(self.norm(self.gaussian(x)))
return self.conv_extra(x + g) if self.feature_extra else g
def gaussian_kernel(self, size, sigma):
return torch.FloatTensor([
[(1 / (2 * math.pi * sigma ** 2)) * math.exp(-(u ** 2 + v ** 2) / (2 * sigma ** 2))
for u in range(-size // 2 + 1, size // 2 + 1)]
for v in range(-size // 2 + 1, size // 2 + 1)
]).unsqueeze(0).unsqueeze(0)
class DRFD(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.conv = nn.Conv2d(dim, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim)
self.conv_c = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=2, padding=1, groups=dim * 2)
self.act_c = act_layer()
self.norm_c = build_norm_layer(norm_layer, dim * 2)[1]
self.max_m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.norm_m = build_norm_layer(norm_layer, dim * 2)[1]
self.fusion = nn.Conv2d(dim * 4, dim * 2, kernel_size=1, stride=1)
self.gaussian = Gaussian(dim * 2, 5, 0.5, norm_layer, act_layer, feature_extra=False)
self.norm_g = build_norm_layer(norm_layer, dim * 2)[1]
def forward(self, x):
x = self.conv(x)
x = self.norm_g(x + self.gaussian(x))
m = self.norm_m(self.max_m(x))
c = self.norm_c(self.act_c(self.conv_c(x)))
x = torch.cat([c, m], dim=1)
x = self.fusion(x)
return x
class LoGFilter(nn.Module):
def __init__(self, in_c, out_c, kernel_size, sigma, norm_layer, act_layer):
super().__init__()
self.conv_init = nn.Conv2d(in_c, out_c, kernel_size=7, stride=1, padding=3)
ax = torch.arange(-(kernel_size // 2), (kernel_size // 2) + 1, dtype=torch.float32)
xx, yy = torch.meshgrid(ax, ax)
kernel = (xx**2 + yy**2 - 2 * sigma**2) / (2 * math.pi * sigma**4) * torch.exp(-(xx**2 + yy**2) / (2 * sigma**2))
kernel = kernel - kernel.mean()
kernel = kernel / kernel.sum()
log_kernel = kernel.unsqueeze(0).unsqueeze(0)
self.LoG = nn.Conv2d(out_c, out_c, kernel_size=kernel_size, stride=1, padding=int(kernel_size // 2), groups=out_c, bias=False)
self.LoG.weight.data = log_kernel.repeat(out_c, 1, 1, 1)
self.act = act_layer()
self.norm1 = build_norm_layer(norm_layer, out_c)[1]
self.norm2 = build_norm_layer(norm_layer, out_c)[1]
def forward(self, x):
x = self.conv_init(x)
LoG = self.LoG(x)
LoG_edge = self.act(self.norm1(LoG))
x = self.norm2(x + LoG_edge)
return x
class Stem(nn.Module):
def __init__(self, in_chans, stem_dim, act_layer, norm_layer):
super().__init__()
out_c14 = int(stem_dim / 4)
out_c12 = int(stem_dim / 2)
self.Conv_D = nn.Sequential(
nn.Conv2d(out_c14, out_c12, kernel_size=3, stride=1, padding=1, groups=out_c14),
nn.Conv2d(out_c12, out_c12, kernel_size=3, stride=2, padding=1, groups=out_c12),
build_norm_layer(norm_layer, out_c12)[1],
)
self.LoG = LoGFilter(in_chans, out_c14, 7, 1.0, norm_layer, act_layer)
self.gaussian = Gaussian(out_c12, 9, 0.5, norm_layer, act_layer)
self.norm = build_norm_layer(norm_layer, out_c12)[1]
self.drfd = DRFD(out_c12, norm_layer, act_layer)
def forward(self, x):
x = self.LoG(x)
x = self.Conv_D(x)
x = self.norm(x + self.gaussian(x))
x = self.drfd(x)
return x
边缘-高斯聚合(EGA)单元(Scharr/Gaussian + LFEA)
- 核心功能:浅层用 Scharr 强化边缘,深层用 Gaussian 平滑语义,统一用 LFEA 做自适应通道注意力。
- 核心优势:在几乎不增加参数的情况下,融合结构与语义先验,显著增强低质量目标的可分性。
- 核心代码(片段):
import torch
import torch.nn as nn
from mmcv.cnn import build_norm_layer
class Conv_Extra(nn.Module):
def __init__(self, channel, norm_layer, act_layer):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(channel, 64, 1),
build_norm_layer(norm_layer, 64)[1],
act_layer(),
nn.Conv2d(64, 64, 3, stride=1, padding=1, dilation=1, bias=False),
build_norm_layer(norm_layer, 64)[1],
act_layer(),
nn.Conv2d(64, channel, 1),
build_norm_layer(norm_layer, channel)[1],
)
def forward(self, x): return self.block(x)
class Scharr(nn.Module):
def __init__(self, channel, norm_layer, act_layer):
super().__init__()
scharr_x = torch.tensor([[-3., 0., 3.], [-10., 0., 10.], [-3., 0., 3.]], dtype=torch.float32).unsqueeze(0).unsqueeze(0)
scharr_y = torch.tensor([[-3., -10., -3.], [0., 0., 0.], [3., 10., 3.]], dtype=torch.float32).unsqueeze(0).unsqueeze(0)
self.conv_x = nn.Conv2d(channel, channel, kernel_size=3, padding=1, groups=channel, bias=False)
self.conv_y = nn.Conv2d(channel, channel, kernel_size=3, padding=1, groups=channel, bias=False)
self.conv_x.weight.data = scharr_x.repeat(channel, 1, 1, 1)
self.conv_y.weight.data = scharr_y.repeat(channel, 1, 1, 1)
self.norm = build_norm_layer(norm_layer, channel)[1]
self.act = act_layer()
self.conv_extra = Conv_Extra(channel, norm_layer, act_layer)
def forward(self, x):
edges_x = self.conv_x(x)
edges_y = self.conv_y(x)
scharr_edge = torch.sqrt(edges_x ** 2 + edges_y ** 2)
scharr_edge = self.act(self.norm(scharr_edge))
out = self.conv_extra(x + scharr_edge)
return out
class Gaussian(nn.Module):
def __init__(self, dim, size, sigma, norm_layer, act_layer, feature_extra=True):
super().__init__()
self.feature_extra = feature_extra
kernel = self.gaussian_kernel(size, sigma)
kernel = nn.Parameter(data=kernel, requires_grad=False).clone()
self.gaussian = nn.Conv2d(dim, dim, kernel_size=size, stride=1, padding=int(size // 2), groups=dim, bias=False)
self.gaussian.weight.data = kernel.repeat(dim, 1, 1, 1)
self.norm = build_norm_layer(norm_layer, dim)[1]
self.act = act_layer()
if feature_extra: self.conv_extra = Conv_Extra(dim, norm_layer, act_layer)
def forward(self, x):
g = self.act(self.norm(self.gaussian(x)))
return self.conv_extra(x + g) if self.feature_extra else g
def gaussian_kernel(self, size, sigma):
return torch.FloatTensor([
[(1 / (2 * math.pi * sigma ** 2)) * math.exp(-(u ** 2 + v ** 2) / (2 * sigma ** 2))
for u in range(-size // 2 + 1, size // 2 + 1)]
for v in range(-size // 2 + 1, size // 2 + 1)
]).unsqueeze(0).unsqueeze(0)
class LFEA(nn.Module):
def __init__(self, channel, norm_layer, act_layer):
super().__init__()
self.conv2d = nn.Sequential(
nn.Conv2d(channel, channel, 3, stride=1, padding=1, dilation=1, bias=False),
build_norm_layer(norm_layer, channel)[1],
act_layer()
)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1d = nn.Conv1d(1, 1, kernel_size=3, padding=1, bias=False)
self.sigmoid = nn.Sigmoid()
self.norm = build_norm_layer(norm_layer, channel)[1]
def forward(self, c, att):
att = c * att + c
att = self.conv2d(att)
wei = self.avg_pool(att)
wei = self.conv1d(wei.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
wei = self.sigmoid(wei)
x = self.norm(c + att * wei)
return x
轻量级边缘-高斯(LEG)块(EGA + MLP 残差,Stage 选择)
- 核心功能:将 EGA 的输出做 MLP 精炼并残差连接,按阶段选择 Scharr 或 Gaussian,实现可堆叠的轻量化特征提炼单元。
- 核心优势:结构与语义的先验融合通过轻量 MLP 与 DropPath 提升表达但控制计算量,适合作为通用骨干积木。
- 核心代码(片段):
import torch
import torch.nn as nn
from timm.models.layers import DropPath
from mmcv.cnn import build_norm_layer
class LFE_Module(nn.Module):
def __init__(self, dim, stage, mlp_ratio, drop_path, act_layer, norm_layer):
super().__init__()
self.stage = stage
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
build_norm_layer(norm_layer, mlp_hidden_dim)[1],
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
)
self.LFEA = LFEA(dim, norm_layer, act_layer)
if stage == 0:
self.Scharr_edge = Scharr(dim, norm_layer, act_layer)
else:
self.gaussian = Gaussian(dim, 5, 1.0, norm_layer, act_layer)
self.norm = build_norm_layer(norm_layer, dim)[1]
def forward(self, x):
att = self.Scharr_edge(x) if self.stage == 0 else self.gaussian(x)
x_att = self.LFEA(x, att)
x = x + self.norm(self.drop_path(self.mlp(x_att)))
return x
class BasicStage(nn.Module):
def __init__(self, dim, stage, depth, mlp_ratio, drop_path, norm_layer, act_layer):
super().__init__()
self.blocks = nn.Sequential(*[
LFE_Module(dim=dim, stage=stage, mlp_ratio=mlp_ratio, drop_path=drop_path[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
def forward(self, x): return self.blocks(x)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)