机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
本文针对第二十届全国大学生智能汽车竞赛智能视觉组任务,从红色立方体定位、15类物品分类和手写数字识别三个关键技术点展开分析。在定位方面比较了垂直/斜向下YOLO检测、水平视觉定位及传感器融合三种方案;分类任务建议通过eIQ训练模型,强调数据集规模的重要性;数字识别提出整体100分类和分数字+角度识别的两种思路,后者虽逻辑复杂但准确率更高。文章指出各方案需结合队伍技术实力选择,并提醒注意数据增强和硬
系列文章目录
机器视觉:智能车大赛视觉组技术文档——OpenArt结合OpenMV实现色块检测
机器视觉:智能车大赛视觉组技术文档——用 YOLO3 Nano 实现目标检测并部署到 OpenART
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
文章目录
前言
第二十届全国大学生智能汽车竞赛智能视觉组有着较复杂的机器视觉处理与运动控制任务。此前,我们已围绕色块检测、YOLO3 Nano目标检测、eIQ训练分类模型等基础技术展开了初步探讨,这些技术为视觉模块的搭建提供了核心支撑。但结合本届比赛的具体规则——需完成红色立方体定位、15类工程师周边物品分类及0-99手写数字奇偶性判断,且需适配NXP微控制器与指定图像处理模块,单一技术方案难以满足所有场景需求。本文将基于比赛实际约束,深入分析视觉模块的多种实现思路,为参赛队伍提供更具针对性的技术参考。
一、定位红色箱子思路
思路一:openart垂直向下/斜向下看定位(yolo目标检测)
这个是从去年的视觉组比赛传承下来的思路,优点是用于目标检测的openart和用于识别分类的openart放在一起,不需要做太多的映射和微调,基本可以实现目标检测的art定位到中心的时候,分类的art也定位到差不多的地方。示意图如下: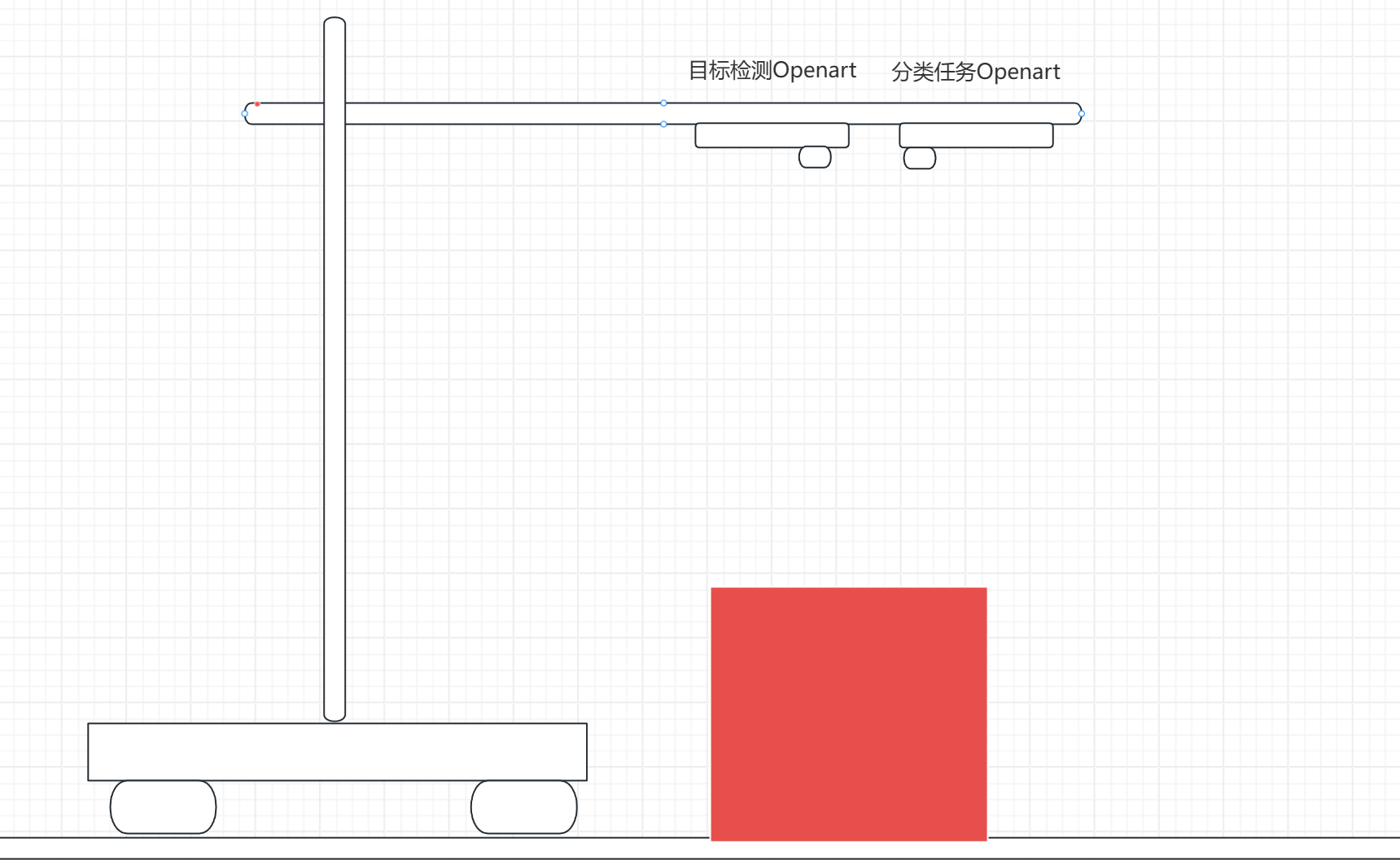
这样的话openart直接返回箱子中心与openart镜头中心的误差给主控进行定位矫正既可,可能由于两个art的位置偏差需要进行中心点的偏移处理
优点:实现简单,只需要处理少量的位置偏移不需要进行映射。
缺点:特征性相对思路二没有那么强,有可能会出现误判的情况。由于openart的性能与yolo模型的限制,整体性能较低,只能跑到15帧
思路二:openart水平向前看定位(yolo目标检测 / 色块检测)
这个是根据今年的视觉组定制的思路,也是逐飞官方给出的思路,将openart放在支撑杆上水平向前看,定位art,将红色块大小数据映射为距离的数据,可以使用yolo3 nano模型也可以使用色块检测,示意图如下: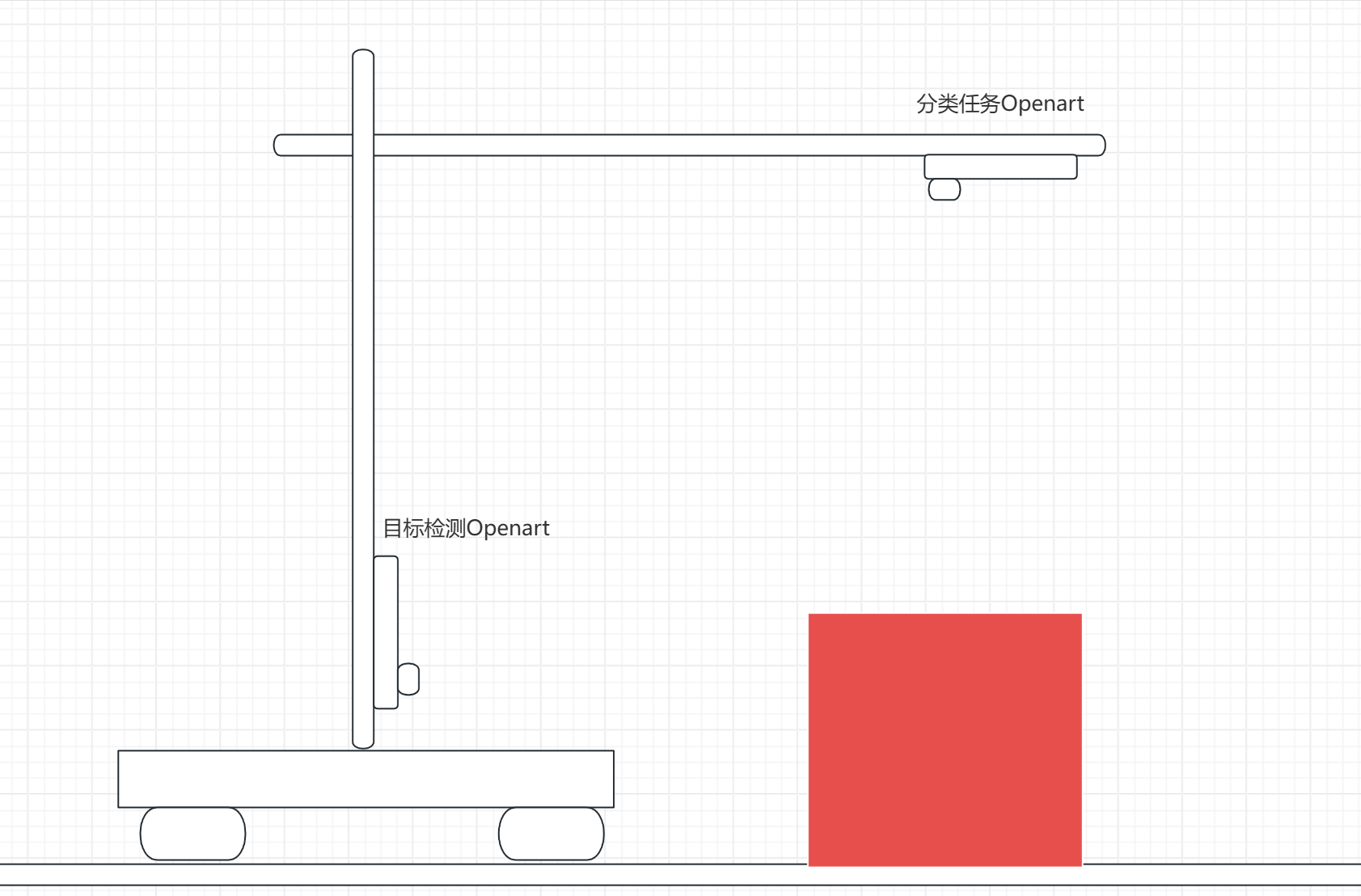
这样的话openart返回箱子中心与检测到的ROI大小给主控进行定位矫正既可。
优点:鲁班性较强,由于箱子的侧面是固定的红色图案,与背景差异明显,所以无论是色块检测还是yolo模型目标检测,都有非常强的鲁班性。并且色块检测的帧率会远超yolo模型,进一步提高性能。并且对于左右便宜的定位非常清晰。
缺点:设置较为复杂,需要处理箱子大小到距离的映射。需要考虑背景中其他的箱子对于定位的影响(设置最小色块阈值)
思路三:传感器融合辅助视觉决策
利用TOF或者超声波传感器辅助箱子前后距离以及左右偏移的矫正,可以大幅度提高定位的精确度。
例如:
1、根据TOF返回的距离参数直接调整距离箱子的前后位置大小。
2、根据返回的距离参数是否有调整左右偏移(可以考虑安装多个TOF)例如左边两个TOF有数据 右边TOF没数据则说明箱子偏左。
二、15类工程师周边物品分类
思路一:eIQ训练15分类模型
其实这个都差不多,特别是在模型选择方面,选取eIQ官方的模型和自己搭模型在准确率上的提高其实是不多的,更多的提升应该是在数据集方面(我们15分类是拍了2-3w张数据集),需要大量的数据集堆砌出一个比较好的分类效果。
具体的训练思路已经在上一篇博客讲过了,可以参考下:
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
但是真实情况下如何训练,还是得靠自己慢慢积累经验。
三、0-99手写数字奇偶性判断
思路一:eIQ训练100分类模型
这个就是跟刚才15分类的思路一样了,都是最简单的实现思路,自行准备手写数据集然后拍照片,练模型
优点:实现思路简单,不需要考虑太多逻辑层面的问题就是做数据集练模型
缺点:这个方法实测下来是效果不是特别好(也可能是我数据集或者训练方法的问题),毕竟0-99分类难免会出现误识别的情况,很难训练出效果完美的分类模型。
思路二:十位数字和个位数字分开识别,同样用eIQ训练模型
这个思路也是逐飞官方给出的思路。是从目标检测阶段就训练单个手写数字的目标检测模型,然后再提取ROI的时候提取单个数字的ROI,进而进行分类任务
分类任务不只是对0-9数字进行十分类,还需要考虑数字的正向方向(因为规则里面说到箱子的摆放方向是不固定的,有可能出现角度倾斜0-360度的情况),[0,1,8]这三个数字通常是不考虑正反的,只用分成两类就可以(0度与90度),而剩下的所有数字都需要考虑(0,90,180,270)四种情况,所以按逻辑来说是得进行38分类或者更少的分类(0度的6和180度的9可以归为一类 同理180度的6也可以与0度的9归为一类 90度与270度也是对应的)。
根据识别的结果,即需要参考数字的识别结果,也需要考虑其朝向得到正确的箱子是如何摆的,应该把哪一个数字作为十位数,应该把哪一个数字作为个位数,是否需要考虑6和9倒置之后识别错的情况。
优点:分类数相对较少,并且由于分类中含有角度因素,所以分类的特征性很强,识别准确率会提高非常多,对数据集规模的要求也相对较低。不需要花大量的时间拍99分类数据集
缺点:实现逻辑复杂,需要结合目标检测进行调整。需要花一定的时间梳理逻辑。并且由于角度不固定,当箱子倾斜角为45、135、235、325时候很有可能在提取ROI的时候提取过多边缘区域导致另外一位数字的图像也被纳入ROI导致识别错误
总结
参赛队伍在选择方案时,需充分结合自身技术储备与硬件条件,并且可以对思路进行不同的调整。
例如:上述讲到十位数字和个位数字分开识别的时候,可以结合软件进行以下方案消除0-45度之间的角度误差
视觉端:定位的时候通过矩形检测传回箱子的倾斜角度
软件端:根据倾斜角度调整车正对箱子而非侧45度面对
这样的方案按逻辑来说是可以完美解决另外一位数字的图像也被纳入ROI的问题。但是对软件以及视觉都有更高的要求。所以各位还是自行选择
同时,无论选择哪种思路,都应重视数据增强、抗干扰处理和硬件适配,避免因细节问题导致罚时。
希望本文的思路分析能为参赛队伍提供有益参考,在之后的每一届智能车比赛中取得佳绩

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)