知识图谱入门学习之路(三)----图算法PageRank
进入到图算法很多人最先接触的算法就是PageRank,PageRank是谷歌最开始创造并应用的,当初主要是为了用来评估构成网络中的每一个节点的重要性。在正式结束PageRank算法之前,我们先了解下有网络图(The web graph)。网络图的特征就是:有向图,存在强连通区。在网络图中,网页作为图中的节点,超链接作为图中的边。In(V)={w| w can re...
进入到图算法很多人最先接触的算法就是PageRank,PageRank是谷歌最开始创造并应用的,当初主要是为了用来评估构成网络中的每一个节点的重要性。
在正式介绍PageRank算法之前,我们先了解下网络图(The web graph)。网络图的特征就是:有向图,存在强连通区。在网络图中,网页作为图中的节点,超链接作为图中的边。
In(V)={w| w can reach V}
Out(V)={w| V can reach w}
 对于上图来说
对于上图来说
In(A)={A,B,C,E,G}
Out(A)={A,B,C,D,F}
在有向图中有2中类型,每一种图都可以通过这2种类型进行表示:
1. 强连接 :在有向图中,每个节点可以到达图中的任意一个节点。

In(A)=Out(A)={A,B,C,D,E}
2.有向无环图(DAG:directed acydic graph):图中不存在环,也就是如果从A可以到达B,那么B不能到达A。

强连通分量(strongly connected component)是节点S的集合,具备下面2个特征:
1.在S中的每一对节点都可以互相连通彼此;
2.在这种特性下,S是最大的集合,没有别的集合能够把S包含进去。
每一个节点都是一个SCC

在上述图中强连通分量:{A,B,C,G},{D},{E},{F}
定理:在每一个有向图中,在强连通分量上是一个有向无环图。

对于上图:
In(A)={A,B,C,D,E}
Out(A)={A,B,D,E,F,G,H}
上图就是一个巨大的强连通分量,不会存在第二个SCC。
在进行详细介绍PageRank的时候,先来思考下如下问题:
当一个页面有很多超链接的时候,是进来的链接重要还是出去的链接重要?显而易见,是进来的链接重要,那么问题又来了,进来的每一个链接的重要性都是一样的,还是说有所不同,如果不同怎么去衡量。在这里我们采用从更可信的地方出来的链接会更重要。同时网页的重要打分评估也是一个循环递归问题。
PageRank采用流式模型:
重要页面的投票会具有更高的权重。
如果页面的权重为
,有
条出边,那么每一个链接有拥有
票。
页面的重要性
是该页面所有进链投票总和。对节点j 定义
如下所示:
其中
代表节点
的出度
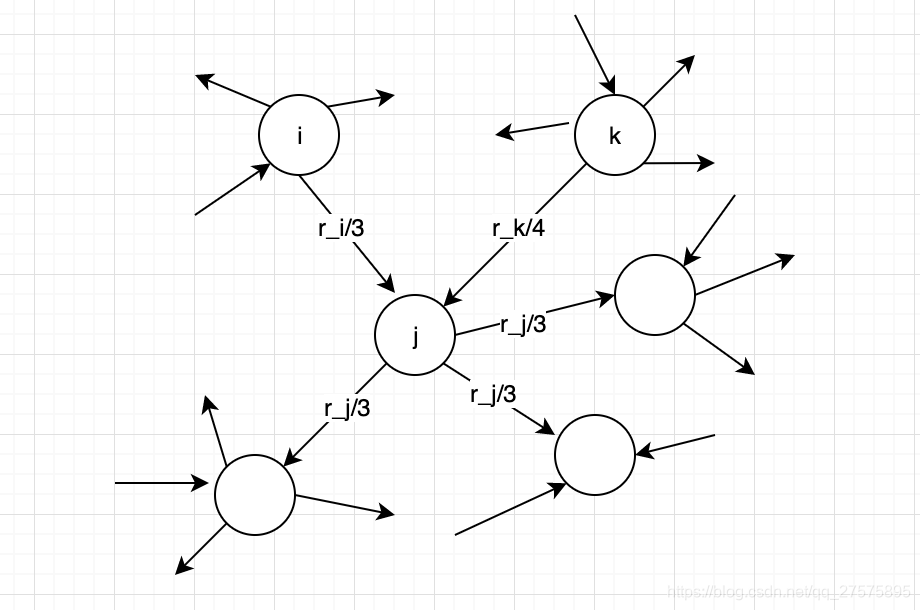
如上图,我们可知
矩阵表达:
设M为随机邻接矩阵,页面 有
条出边,当
就有
,其中M的每列和为1
秩向量:对于页面
的每一个进来的页面
有:
,也可以写作
在PageRank中采用了随机游走。
想象上网过程中的随机游走,
1.在任意时刻t,在页面进行浏览;
2.在时刻,从页面
均匀随机的往外走;
3.直到到了页面链接到了
,也就是遍历完;
4.不断地重复上述过程。
采用P(t)来表示在时间t,页面被访问到的概率,用P(t)来表示每个页面的概率分布情况。那么到了
时刻怎么去判断浏览到哪了,通过根据链接均匀随机的进行游走,
,假设当随机游走到达了如下状态
那么可知在随机游走中P(t)是平稳分布的。我们的秩向量r也满足
,同时r在随机游走中也满足平稳分布。
PageRank算法步骤如下:
1.给每个节点一个初始的PR(Page Rank)值;
2.对每一个节点进行计算:
式中
代表节点i的出度
直到
其中一般是能容忍的精度,到最后会逐渐收敛于某个值
3.重复迭代
举例如下:
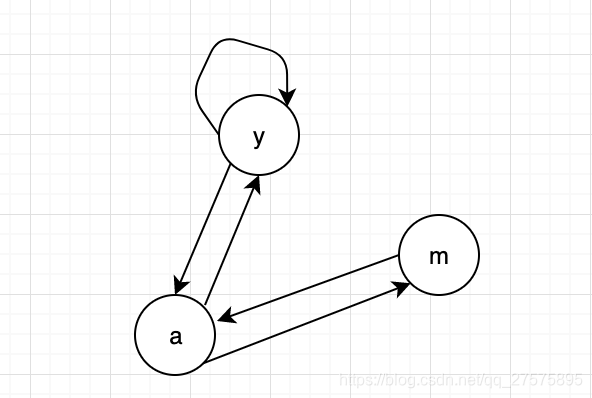
如上图 :
| y | a | m | |
| y | 1/2 | 1/2 | 0 |
| a | 1/2 | 0 | 1 |
| m | 0 | 1/2 | 0 |
下面计算PageRank过程
首先 赋予初始PR值:PR(y)=PR(a)=PR(m)=1/3
第一次迭代:
第二次迭代:
第三次迭代:
通过不断迭代直至收敛到
PR(y)=6/15
PR(a)=6/15
PR(m)=3/15
上面介绍完PageRank的计算过程,下面有三个问题需要思考:第一,是否具有覆盖性;第二,覆盖的值是否是我们想要的;第三,结果分值是合理的吗。
通过实践会发现PageRank在实际中存在如下两个问题:
1.有些页面是死胡同,只有进去的链接,它自身没有对外的链接,这样的页面会导致重要性泄露;
2.蛛网陷阱(所有的出链都是在一个group中)最终会吸收所有的重要性。
举例蛛网陷阱:
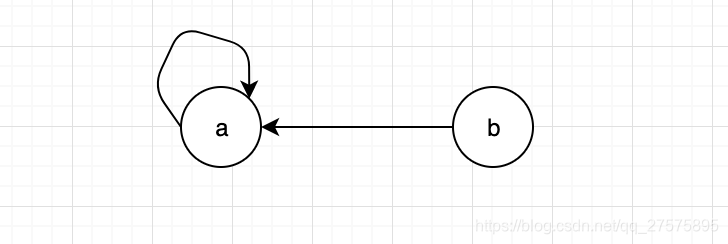
如上图所示:
| iteration | 0 | 1 | 2 | 3 |
| 1/2 | 1 | 1 | 1 | |
| 1/2 | 0 | 0 | 0 |
谷歌对于蛛网陷阱的解决方法就是:在每一个步,随机浏览有2中选择
1.在可能性为,随机跟一个链接出去
2.在可能性为,调到一个随机页面;通常
的取值在0.8到0.9之间。
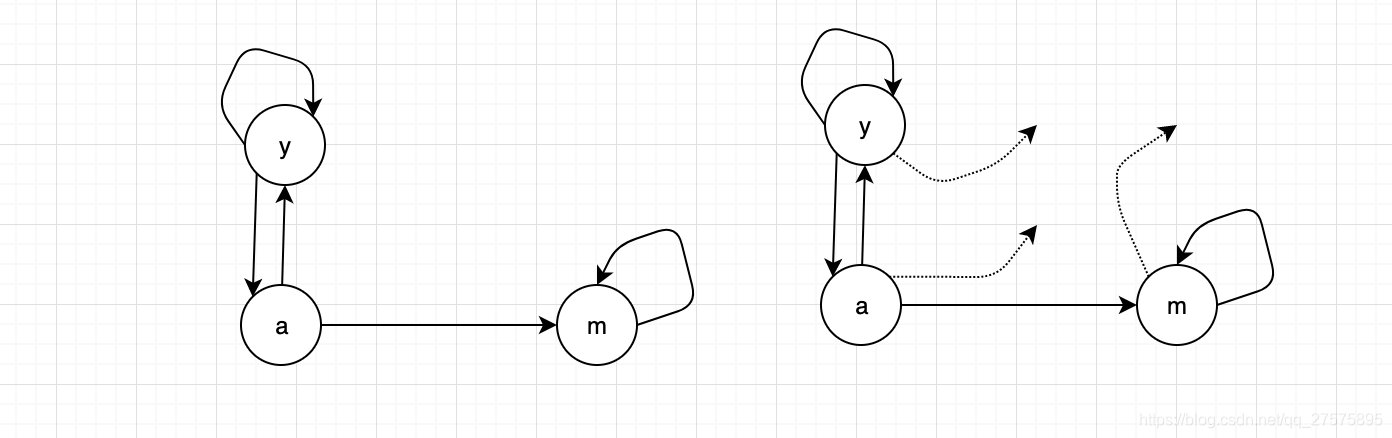
关于死胡同解决方法为:teleport
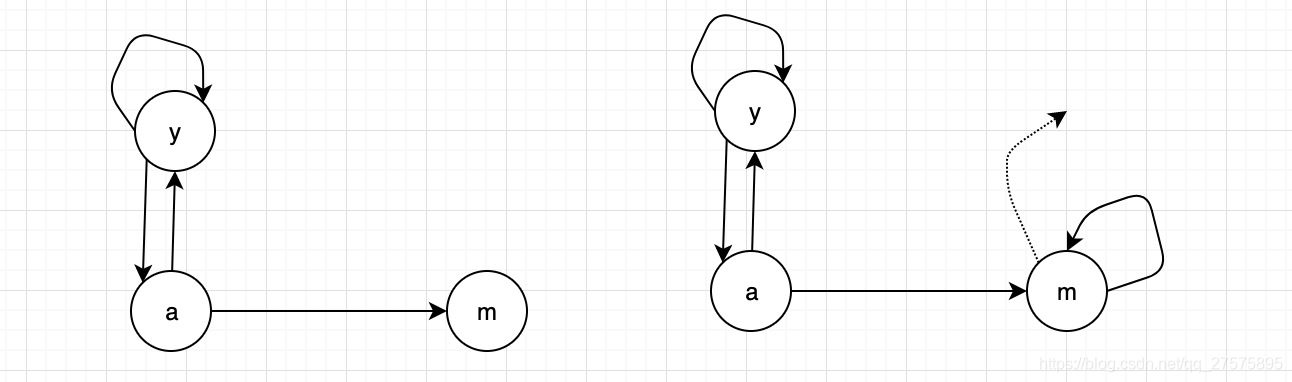
| y | a | m | |
| y | 1/2 | 1/2 | 0 |
| a | 1/2 | 0 | 0 |
| m | 0 | 1/2 | 0 |
变成
| y | a | m | |
| y | 1/2 | 1/2 | 1/3 |
| a | 1/2 | 0 | 1/3 |
| m | 0 | 1/2 | 1/3 |
最终的PageRank公式为:
好了,关于PageRank的介绍先说这么多,后续再聊!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)