# Youtu-VL:通过统一视觉-语言监督释放视觉潜能
尽管视觉-语言模型(Vision-Language Models, VLMs)取得了显著进展,但当前架构在保留细粒度视觉信息方面常表现出局限性,导致粗粒度的多模态理解。我们将这一缺陷归因于现有 VLM 中固有的次优训练范式,该范式表现出文本主导的优化偏差,仅将视觉信号视为被动的条件输入而非监督目标。
Youtu-VL 团队 ∗ ^{*} ∗
摘要
尽管视觉-语言模型(Vision-Language Models, VLMs)取得了显著进展,但当前架构在保留细粒度视觉信息方面常表现出局限性,导致粗粒度的多模态理解。我们将这一缺陷归因于现有 VLM 中固有的次优训练范式,该范式表现出文本主导的优化偏差,仅将视觉信号视为被动的条件输入而非监督目标。为缓解此问题,我们提出了 Youtu-VL 框架,该框架利用视觉-语言统一自回归监督(Vision-Language Unified Autoregressive Supervision, VLUAS)范式,从根本上将优化目标从"视觉作为输入"转变为"视觉作为目标"。通过将视觉 token 直接整合到预测流中,Youtu-VL 对视觉细节和语言内容施加统一的自回归监督。此外,我们将此范式扩展至涵盖视觉中心任务,使标准 VLM 无需任务特定模块即可执行视觉中心任务。大量实证评估表明,Youtu-VL 在通用多模态任务和视觉中心任务上均取得具有竞争力的性能,为全面通用视觉智能体的开发奠定了坚实基础。
代码:https://github.com/TencentCloudADP/youtu-vl
模型:https://huggingface.co/collections/tencent/youtu
1 引言
视觉-语言模型(VLMs)通过将大语言模型(LLMs)的理解能力与预训练视觉编码器相结合,在多模态任务上取得了显著能力。通过将视觉特征与语言语义对齐,这些架构已成为从图像描述到视觉推理等通用应用的标准 [Bai et al., 2025, Wang et al., 2025]。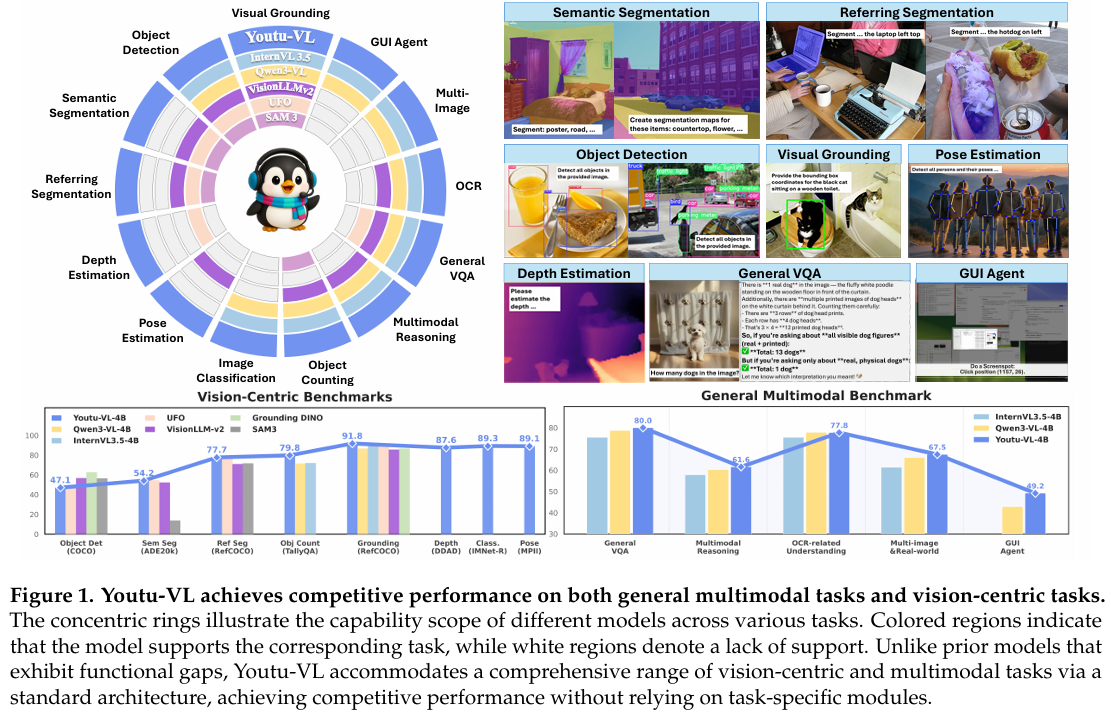
然而,当前 VLM 研究中存在一个根本性局限:细粒度视觉信息的保留。我们将此缺陷归因于现有训练范式中固有的文本主导优化偏差。在典型架构中,视觉信号仅被概念化为被动的条件输入,而优化过程完全由自回归文本生成目标驱动 [Liu et al., 2023, Assran et al., 2023]。因此,模型被隐式鼓励丢弃对粗粒度文本生成而言冗余的视觉细节,不可避免地造成信息瓶颈,阻碍密集感知能力。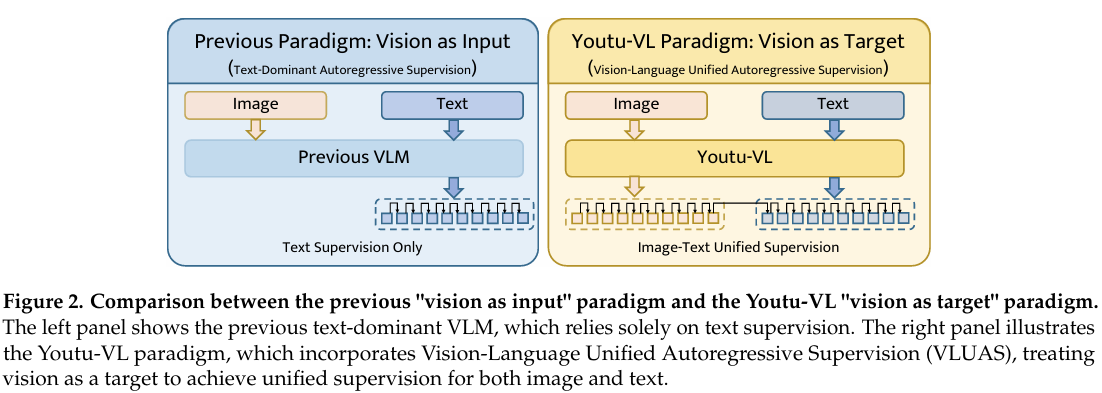
为解决上述优化瓶颈,我们提出了 Youtu-VL 框架,该框架基于视觉-语言统一自回归监督(VLUAS)范式构建。如图 2 所示,与主流的"视觉作为输入"策略不同,我们通过学习的视觉码本将文本词表扩展为统一的多模态词表 V unified \mathcal{V}_{\text{unified}} Vunified。该设计的核心是我们的协同视觉 Tokenizer,它融合高层语义概念与低层几何结构以生成离散编码,从而提供密集的语义视觉监督。这使模型能够将视觉信号视为监督目标而非被动条件。通过将这些视觉 token 整合到预测流中,Youtu-VL 对视觉细节和语言内容施加统一的自回归监督,确保保留通常被标准文本生成目标丢弃的细粒度信息。
此外,我们将此统一范式扩展至涵盖全面的视觉中心任务套件,采用标准架构而无需任务特定模块。我们将这些能力分为两个不同流:基于文本的预测和密集预测。对于对象检测和视觉定位等基于文本的预测任务,我们实现了具有绝对像素坐标的轴特定词表,使模型能够直接将精确边界框生成为文本 token,避免归一化伪影。相反,针对语义分割和深度估计等像素级任务,我们利用模型的原生 logits 表示。通过多任务自回归视觉监督,我们的方法能够直接从这些原始 logits 生成高质量密集预测,无需额外的任务特定头或嵌入。该设计统一了推理流程,使标准 VLM 能够在高层推理与低层密集感知之间无缝切换,无需结构修改。
我们的贡献总结如下:
• 视觉-语言统一自回归监督(VLUAS)。我们提出从纯文本监督到生成式统一的范式转变。通过将视觉 token 视为优化目标,我们缓解了文本主导偏差并强制保留细粒度视觉细节。
• 标准架构下的视觉中心预测。我们将图像和文本 token 视为等价的自回归状态,使 Youtu-VL 能够在标准 VLM 架构内执行视觉中心任务,包括密集视觉预测(如分割、深度)和基于文本的预测(如定位、检测),无需任务特定添加。
• 实证性能。大量评估表明,Youtu-VL 在通用多模态任务和视觉中心任务上均取得具有竞争力的性能,为通用视觉智能体建立了稳健基线。
2 架构与方法论
我们介绍 Youtu-VL,一个基于所提出的视觉-语言统一自回归监督(VLUAS)和标准架构下视觉中心预测的新框架。如图 3 左侧面板所示,Youtu-VL 包含三个核心组件:视觉编码器、用于将视觉特征映射到统一视觉-语言 token 空间的视觉-语言投影器,以及 LLM。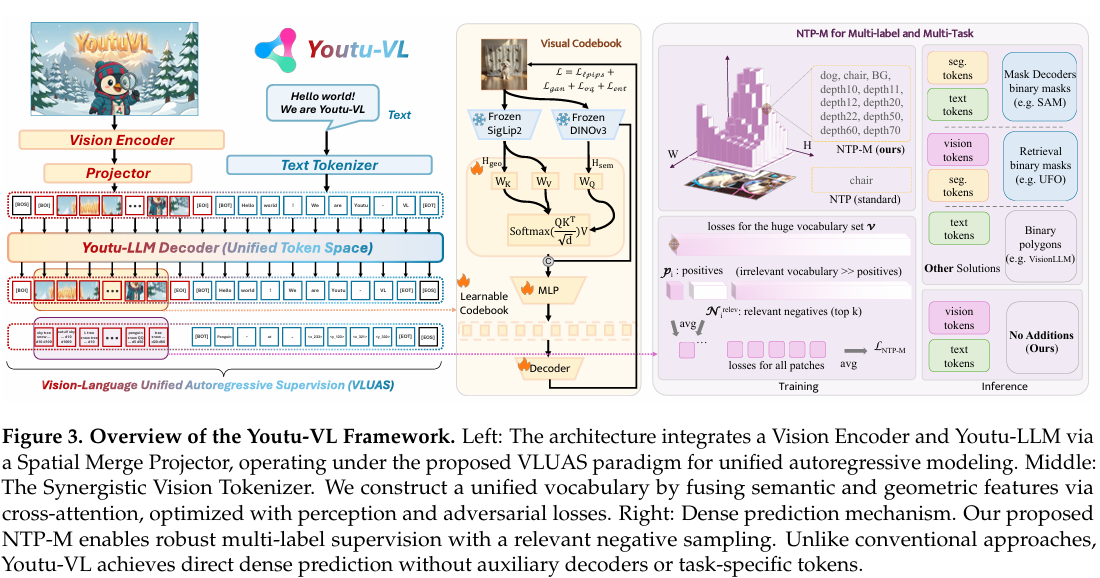
大语言模型(LLM)。Youtu-VL 中采用的 LLM 是基于 Youtu-LLM 架构自研的模型 [Lu et al., 2026]。在此基础上,我们引入 VLUAS 范式,通过专用的图像-token 词表扩展原始文本词表。为实现此目标,我们采用多阶段训练流程。在第 3 阶段,我们的视觉 Tokenizer 被训练以构建视觉码本,形成 V unified \mathcal{V}_{\text{unified}} Vunified的视觉部分(图 3 中部)。在第 4 阶段,我们直接对 LLM 的自回归输出应用所提出的多标签 NTP 目标,实现密集预测监督,无需引入辅助解码器或任务特定 token(图 3 右侧)。
视觉编码器。我们的视觉编码器基于 SigLIP-2 [Tschannen et al., 2025] 构建。具体而言,我们采用 siglip2-so400m-patch16-naflex 变体。该架构根据空间形状采用 2D 旋转位置编码(RoPE)[Su et al., 2023] 进行位置编码。它进一步采用窗口注意力以提高效率,每 8 层插入全局注意力。此外,它通过累积序列长度机制利用 FlashAttention [Dao et al., 2022] 处理批次内的变长序列。重要的是,我们的设计允许编码器以原始分辨率处理图像,为高分辨率输入提供灵活性,无需调整为固定尺度。
视觉-语言投影器。视觉-语言投影器采用空间合并(Spatial Merge)操作连接相邻的 2 × 2 2 \times 2 2×2patch 特征 [Bai et al., 2023]。这有效地将 token 数量减少至原始大小的四分之一(1/4),从而缩短后续 LLM 的输入序列长度。最后,两层多层感知机(MLP)将这些压缩特征投影到 LLM 的输入空间。
2.1 视觉-语言统一自回归监督范式
VLUAS 范式通过将传统文本词表扩展为统一的图像-文本词表( V unified \mathcal{V}_{\text{unified}} Vunified)来弥合模态差距。在此公式下,视觉信号被表示为 token 并以与语言相同的下一个 token 预测目标进行训练,从而实现统一的自回归建模接口并支持直接的 token 级密集监督。本节详细说明通过专用 tokenizer 构建此词表,随后阐述我们统一的自回归目标公式。
统一图像-文本词表的构建。为实现 VLUAS 范式,我们通过引入视觉 tokenizer 将常规文本词表扩展为统一的图像-文本词表( V unified \mathcal{V}_{\text{unified}} Vunified),该 tokenizer 通过向量量化将图像映射为离散索引序列。我们使用这些离散索引作为预测目标,将视觉学习转化为与语言建模相同的下一个 token 预测形式,并通过交叉熵实现直接的 token 级密集监督。同时,条件路径保持连续:输入图像由视觉编码器编码为连续嵌入,投影到 LLM 隐藏维度,并与文本嵌入连接作为上下文。这在上下文中保留了细粒度视觉线索,避免将量化误差传播到条件信号中。纯连续替代方案需要回归高维向量,偏离基于 token 的自回归接口,使监督与标准 LLM 训练不太对齐。因此,这种非对称设计结合了信息保留的连续条件与稳定的、基于词表的自回归监督。
对于视觉 tokenizer 表示,重要的是保留高层语义和精细空间结构。语义编码器往往空间粗糙,而像素级目标可能保留过多高频冗余并鼓励纹理捷径。我们通过设计协同视觉 tokenizer 来解决此问题,该 tokenizer 在离散化前形成密集的视觉-语言对齐特征。具体而言,我们利用两个具有互补属性的冻结基础编码器:SigLIP-2 [Tschannen et al., 2025] 提供丰富的语言对齐语义,而 DINOv3 [Siméoni et al., 2025] 通过自蒸馏提供边界一致的局部对应关系,有助于维持空间结构。尽管 DINOv3 也包含密集语义,但它并未显式与语言对齐;将其与 SigLIP-2 结合使我们能够将语言对齐的语义内容绑定到几何感知的空间布局。
具体而言,我们采用交叉注意力融合机制,在结构约束下探测语义特征。我们将特征图投影到共享流形以定义查询(Q)、键(K)和值(V)矩阵:
Q = H g e o W Q , K = H s e m W K , V = H s e m W V , \mathbf{Q}=\mathbf{H}_{\mathrm{geo}}\mathbf{W}_{Q},\quad\mathbf{K}=\mathbf{H}_{\mathrm{sem}}\mathbf{W}_{K},\quad\mathbf{V}=\mathbf{H}_{\mathrm{sem}}\mathbf{W}_{V}, Q=HgeoWQ,K=HsemWK,V=HsemWV,
其中 H g e o \mathbf{H}_{\mathrm{geo}} Hgeo和 H s e m \mathbf{H}_{\mathrm{sem}} Hsem分别表示来自结构(DINOv3)和语义(SigLIP-2)编码器的隐藏状态。融合的协同表示 Z s y n \mathbf{Z}_{\mathrm{syn}} Zsyn通过交叉注意力计算:
Z s y n = S o f t m a x ( Q K ⊤ d k ) V . \mathbf{Z}_{\mathrm{syn}}=\mathrm{Softmax}\left(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d_{k}}}\right)\mathbf{V}. Zsyn=Softmax(dkQK⊤)V.
在量化前,我们将 Z syn \mathbf{Z}_{\text{syn}} Zsyn与原始结构特征 H geo \mathbf{H}_{\text{geo}} Hgeo沿通道维度连接,通过 MLP 投影复合表示,并使用索引反向传播量化(IBQ)[Shi et al., 2025] 进行离散化。此过程将连续向量映射到可学习码本 C = { c k } k = 1 K \mathcal{C} = \{c_k\}_{k=1}^K C={ck}k=1K中的最近原型,配置码本大小为 K = 150 , 000 K = 150,000 K=150,000,嵌入维度为 D = 768 D = 768 D=768。
tokenizer 通过端到端优化以从这些离散编码重建输入图像。我们采用复合目标函数 L tok \mathcal{L}_{\text{tok}} Ltok平衡感知保真度与码本使用:
L t o k = λ p L l p i p s + λ g L g a n ⏟ P e r c e p t u a l & A d v e r s a r i a l F i d e l i t y + L v q + λ e L e n t ⏟ C o d e b o o k O p t i m i z a t i o n \mathcal{L}_{\mathrm{tok}}=\underbrace{\lambda_{p}\mathcal{L}_{\mathrm{lpips}}+\lambda_{g}\mathcal{L}_{\mathrm{gan}}}_{\mathrm{Perceptual~\&~Adversarial~Fidelity}}+\underbrace{\mathcal{L}_{\mathrm{vq}}+\lambda_{e}\mathcal{L}_{\mathrm{ent}}}_{\mathrm{Codebook~Optimization}} Ltok=Perceptual & Adversarial Fidelity λpLlpips+λgLgan+Codebook Optimization Lvq+λeLent
其中 L lpips \mathcal{L}_{\text{lpips}} Llpips通过感知相似性强制纹理真实性, L gan \mathcal{L}_{\text{gan}} Lgan表示对抗判别器损失。为防止码本崩溃,我们整合向量量化损失 L vq \mathcal{L}_{\text{vq}} Lvq以及熵正则化项 L ent \mathcal{L}_{\text{ent}} Lent。我们将损失权重设置为 λ p = 1 \lambda_p = 1 λp=1, λ g = 1 \lambda_g = 1 λg=1, λ e = 0.1 \lambda_e = 0.1 λe=0.1。我们策略中的关键设计选择是刻意排除标准像素级 ℓ 1 \ell_1 ℓ1重建损失。我们认为 ℓ 1 \ell_1 ℓ1最小化会产生"纹理偏差",鼓励模型将高频噪声记忆为捷径,从而绕过高层语义抽象。通过仅依赖感知和对抗约束,我们迫使码本编码结构语义而非纯粹的像素统计。实证上,此方法在我们的复合数据集上产生 97.74% 的码本利用率。学习的索引形成视觉词表 V img \mathcal{V}_{\text{img}} Vimg,当与文本词表合并时,为我们的 VLUAS 范式建立统一基础 V unified = V text ∪ V img \mathcal{V}_{\text{unified}} = \mathcal{V}_{\text{text}} \cup \mathcal{V}_{\text{img}} Vunified=Vtext∪Vimg。
视觉-语言统一自回归监督(VLUAS)范式。Youtu-VL 的核心贡献是从判别式"视觉作为输入"范式向生成式"视觉作为目标"范式的转变。我们将训练目标重新公式化为对视觉和语言序列的联合概率进行自回归建模。为最大化性能,我们对输入和目标采用非对称表示策略。对于输入上下文,我们利用 SigLIP-2 编码器提取的连续视觉嵌入。这些特征被线性投影到 LLM 维度并与文本嵌入连接,通过在输入阶段消除量化误差来保留最大信号保真度。
形式上,给定包含文本 token T = { t 1 , … , t N } T = \{t_1, \ldots, t_N\} T={t1,…,tN}和视觉 token V = { v 1 , … , v M } V = \{v_1, \ldots, v_M\} V={v1,…,vM}的多模态序列 S S S,模型优化给定上下文 s < i s_{<i} s<i的下一个 token s i s_i si的概率,无论模态如何。统一目标函数 L VLUAS \mathcal{L}_{\text{VLUAS}} LVLUAS是文本和视觉预测损失的加权和:
L V L U A S = L t e x t + λ L i m a g e \mathcal{L}_{\mathrm{VLUAS}}=\mathcal{L}_{\mathrm{text}}+\lambda\mathcal{L}_{\mathrm{image}} LVLUAS=Ltext+λLimage
其中 λ \lambda λ是平衡任务梯度的超参数(经验设置为 0.5)。各个损失分量使用标准交叉熵计算:
L text = − ∑ i ∈ I t log P ( t i ∣ s < i ; θ ) , L image = − ∑ j ∈ I v log P ( v j ∣ s < j ; θ ) \mathcal{L}_{\text{text}}=-\sum_{i\in\mathcal{I}_{t}}\log P(t_{i}\mid s_{<i};\theta),\quad\mathcal{L}_{\text{image}}=-\sum_{j\in\mathcal{I}_{v}}\log P(v_{j}\mid s_{<j};\theta) Ltext=−i∈It∑logP(ti∣s<i;θ),Limage=−j∈Iv∑logP(vj∣s<j;θ)
此处 I t \mathcal{I}_{t} It和 I v \mathcal{I}_{v} Iv分别表示扁平化序列中文本和图像 token 的索引。通过强制执行 L image \mathcal{L}_{\text{image}} Limage,Youtu-VL 被迫同时重建视觉细节和语言内容。这解决了文本主导的优化偏差,保留了判别方法中通常丢失的细粒度视觉信息。
2.2 标准 VLM 的视觉中心预测
基于文本预测的视觉中心任务。我们将视觉中心任务分为两种范式:文本预测和密集预测。文本预测范式涵盖图像分类、对象计数、视觉定位、对象检测、姿态估计和基于多边形的分割等任务。文本预测范式的核心是通过坐标预测精确定位对象。我们通过三种设计实现此目标:(1) 轴特定词表:我们通过为 X 轴和 Y 轴各引入 2048 个坐标(例如 ⟨ x 0 ⟩ \langle x_0\rangle ⟨x0⟩)来扩展 tokenizer 的词表。此设计显著减少了坐标表示所需的序列长度(无需 x & y 指示符、逗号和长数字)。它还有效缓解了多坐标场景中 X 和 Y 值之间的歧义。(2) 绝对像素坐标:模型直接在绝对像素坐标上操作,而非归一化相对坐标。此设计消除了训练和推理期间坐标重归一化的需要,从而防止模型尝试学习隐式缩放映射时可能引起的干扰。(3) 解析 token:为精确结果解析,一些解析 token 已集成到词表中(参见附录 A.1)。
基于此词表设计,我们将特定视觉任务公式化如下:(1) 视觉定位表示为预测定义边界框的四个坐标 token XYXY。(2) 对象检测通过在坐标序列前附加文本类别 token 来扩展定位公式。该框架支持灵活的查询模式,范围从单一和多目标类别到支持"检测全部"命令以应对开放世界场景。(3) 人体姿态估计被公式化为多个关键点坐标的顺序预测。(4) 基于多边形的分割可通过预测一系列点来勾勒对象边界实现(压缩在 20 个点内以避免过长情况)。(5) 对象计数:我们支持直接回归数值 token,或"先检测后计数"方法(见图 15)以实现可验证的准确性。
标准 VLM 的密集预测。我们的目标是使标准 VLM 能够执行主流视觉中心任务,从而调和通用 VLM 与这些关键但常被忽视的能力。显然,仅文本生成无法涵盖所有模态,特别是语义分割和深度估计等像素或 patch 级密集预测任务。传统方法通常诉诸于结合额外的任务特定解码器 [Rasheed et al., 2024, Wu et al., 2024, Liu et al., 2025] 和相应的任务嵌入 token [Tang et al., 2025]。然而,此类附加组件不可避免地碎片化统一架构并使训练和推理流程复杂化,从而损害实用性。受 token 激活图 [Li et al., 2025] 启发,我们认为标准 VLM 本质上是密集预测器,能够直接从输出视觉 token 生成密集预测,无需辅助模块。我们的推理方案依赖于两个核心机制:(1) 在统一词表内直接预测类别。(2) 获取对应预测类别 token 索引的视觉 token logits,通过 argmax 操作获得结果。
对于语义分割,类别是标准文本 token。对于深度估计,我们将深度范围离散化为 bins(例如 1–1000),支持线性量化用于多个封闭集,以及对数量化用于开放世界任务(例如深度任意场景)。注意我们不预测每个 bin 名称;我们对所有 bin 词表应用 argmax。相比之下,预测语义分割中的类别是必要的,因为通用文本词表太大而无法进行 argmax。为处理由多个 token 表示的类别(例如子词单元),我们通过计算与每个类别 k k k相关的原始 logits Z v \mathbf{Z}_v Zv的均值来聚合其对齐分数( S k \mathcal{S}_k Sk表示对应第 k k k个语义类别的 token 索引集)。这些聚合 logits 被重塑( R \mathcal{R} R)为空间网格,并通过双线性插值( I \mathcal{I} I)上采样以恢复像素级粒度。最后,通过在预测类别上取 argmax( A \mathcal{A} A)导出密集预测图 M \mathbf{M} M:
M = A ( I ( R ( Z ˉ ) ) ) , w h e r e Z ˉ k = 1 ∣ S k ∣ ∑ t ∈ S k Z v , t . \mathbf{M}=\mathcal{A}\Big(\mathcal{I}\Big(\mathcal{R}\Big(\bar{\mathbf{Z}}\Big)\Big)\Big),\quad\mathrm{where}\quad\bar{\mathbf{Z}}_{k}=\frac{1}{\big|\mathcal{S}_{k}\big|}\sum_{t\in\mathcal{S}_{k}}\mathbf{Z}_{v,t}\;. M=A(I(R(Zˉ))),whereZˉk= Sk 1t∈Sk∑Zv,t.
为获得高质量像素级输出,可在插值后可选地采用密集 CRF [Krähenbühl and Koltun, 2011] 作为后处理步骤。此外,可对聚合 logits Z ˉ k \bar{\mathbf{Z}}_k Zˉk应用带温度 τ \tau τ的 softmax 操作以调节分布锐度,从而控制 logits 对颜色值的相对贡献。此操作对语义分割是可选的,而深度估计不建议使用。提升性能的另一种有效策略是图像缩放,它利用模型的原生分辨率能力处理更精细细节。最后,掩码被转换为字符串并通过开放式语言接口附加到对话中,用于输入和输出。
用于多标签和多任务的自回归视觉损失。我们工作的核心贡献是视觉 token 的自回归监督。我们将下一个 token 预测(NTP)范式扩展到视觉 token,以促进图像和文本表示之间更紧密的对齐,确保稳健的密集预测性能,而非将监督仅限于文本 token。认识到单个图像 patch 通常封装多个语义标签和任务目标(见图 3),我们为视觉 token 采用多标签监督目标。我们称之为 NTP-M,是标准 NTP 针对多标签和多任务场景的变体。具体而言,我们从单标签过渡到多标签框架,通过为每个图像 patch 构建多热目标向量,其中对应所有相关对象、任务和潜在粒度的 token ID 被设为 1,而词表中其余索引被赋值为 0。与标准 NTP 不同(通过 Softmax 建模分类分布),我们独立地对词表中每个 token 的概率进行建模。因此,我们重新定义生成目标 p ( Y ∣ X v , X instruct ) p(\mathbf{Y}|\mathbf{X}_{v},\mathbf{X}_{\text{instruct}}) p(Y∣Xv,Xinstruct)为词表上独立伯努利试验的联合概率:
p ( Y ∣ X v , X i n s t r u c t ) = ∏ i = 1 L ∏ v = 1 ∣ V ∣ σ ( z i , v ) y i , v ⋅ ( 1 − σ ( z i , v ) ) ( 1 − y i , v ) , p(\mathbf{Y}|\mathbf{X}_{v},\mathbf{X}_{\mathrm{instruct}})=\prod_{i=1}^{L}\prod_{v=1}^{|\mathcal{V}|}\sigma(\mathbf{z}_{i,v})^{y_{i,v}}\cdot(1-\sigma(\mathbf{z}_{i,v}))^{(1-y_{i,v})}, p(Y∣Xv,Xinstruct)=i=1∏Lv=1∏∣V∣σ(zi,v)yi,v⋅(1−σ(zi,v))(1−yi,v),
其中 X v , X instruct \mathbf{X}_v, \mathbf{X}_{\text{instruct}} Xv,Xinstruct分别是视觉 token 输入和指令(prompt)输入。 L L L表示视觉 token 的序列长度, ∣ V ∣ |\mathcal{V}| ∣V∣是词表大小, σ ( z i , v ) \sigma(\mathbf{z}_{i,v}) σ(zi,v)表示 patch i i i处 token v v v的 Sigmoid 激活概率, y i , v ∈ { 0 , 1 } y_{i,v} \in \{0,1\} yi,v∈{0,1}指示对应目标的 ground truth 存在性。注意 X instruct \mathbf{X}_{\text{instruct}} Xinstruct可影响密集预测过程;例如,图像前的 prompt 指导特定相机的深度估计深度范围。
鉴于 VLM 固有的广泛词表大小,显著的类别不平衡对有效监督构成挑战。为解决此问题,我们实施稳健的多标签下一个 token 预测损失 L NTP-M \mathcal{L}_{\text{NTP-M}} LNTP-M,该损失替换朴素平均策略以确保稳定收敛。我们的核心见解在于独立的正负样本平均耦合相关负采样。具体而言,我们解耦正样本和负样本的处理。我们首先计算所有有效正样本的平均损失。对于负样本,我们根据预测概率 p p p(Eq. 7 中的 Sigmoid 后)对它们进行排序,仅计算 top-k 相关负样本的平均损失。此方法防止由大量无关、低响应负样本平均引起的梯度稀释。不同于标准在线难例挖掘 [Shrivastava et al., 2016](联合对正负样本排序),我们的方法防止正样本被难负样本的庞大数量掩盖或排除,从而提高收敛效率。此外,为适应不完整标注(例如具有语义标签但缺失深度信息的实例),我们应用有效性掩码将对应索引从平均过程中排除。我们正式定义正样本集和相关负样本集以反映排序和掩码逻辑。令 p i , j = σ ( z i , j ) p_{i,j} = \sigma(z_{i,j}) pi,j=σ(zi,j)为步骤 i i i处第 j j j个 token 的 Sigmoid 激活概率。令 M i \mathcal{M}_i Mi为当前任务的有效索引集(掩码掉缺失标注)。正索引集定义为 P i = { j ∈ M i ∣ y i , j = 1 } \mathcal{P}_i = \{j \in \mathcal{M}_i \mid y_{i,j} = 1\} Pi={j∈Mi∣yi,j=1}。对于负样本,候选集为 C i = { j ∈ M i ∣ y i , j = 0 } \mathcal{C}_i = \{j \in \mathcal{M}_i \mid y_{i,j} = 0\} Ci={j∈Mi∣yi,j=0}。我们将相关负样本集 N i h a r d \mathcal{N}_i^{\mathrm{hard}} Nihard定义为 C i \mathcal{C}_i Ci的大小为 k k k的子集,该子集最大化预测概率之和(即 top- k k k排序操作):
N i h a r d = arg max S ⊂ C i , ∣ S ∣ = k ∑ j ∈ S p i , j . \mathcal{N}_{i}^{\mathrm{hard}}=\underset{S\subset\mathcal{C}_{i},|S|=k}{\arg\max}\sum_{j\in S}p_{i,j}. Nihard=S⊂Ci,∣S∣=kargmaxj∈S∑pi,j.
最终损失 L N T P − M \mathcal{L}_{\mathrm{NTP-M}} LNTP−M是这些集合上独立平均的总和:
L N T P − M = ∑ i = 1 L [ − 1 ∣ P i ∣ ∑ j ∈ P i log ( p i , j ) − 1 k ∑ j ∈ N i h a r d log ( 1 − p i , j ) ] . \mathcal{L}_{\mathrm{NTP-M}}=\sum_{i=1}^{L}\left[-\frac{1}{|\mathcal{P}_{i}|}\sum_{j\in\mathcal{P}_{i}}\log(p_{i,j})-\frac{1}{k}\sum_{j\in\mathcal{N}_{i}^{\mathrm{hard}}}\log(1-p_{i,j})\right]. LNTP−M=i=1∑L −∣Pi∣1j∈Pi∑log(pi,j)−k1j∈Nihard∑log(1−pi,j) .
3 预训练
3.1 训练方案
Youtu-VL 的训练遵循渐进式多阶段训练方案。该流程结构化为四个连续阶段,从建立稳健的语言基础(阶段 1 和 2)演进到多模态基础预训练(阶段 3),最终达到多功能任务适应(阶段 4)。此训练方案的细节如图 4 所示。在阶段 3 和 4 期间,我们部署双流监督策略以实施全面的视觉监督。对于通用多模态数据,我们施加自回归视觉重建损失 L image \mathcal{L}_{\text{image}} Limage(在第 2.1 节中定义),迫使模型将视觉 token 作为内在生成目标与文本一起预测。作为补充,对于视觉中心数据,我们结合专用损失 L NTP-M \mathcal{L}_{\text{NTP-M}} LNTP-M(在第 2.2 节中详述),这对于促进细粒度密集感知能力至关重要。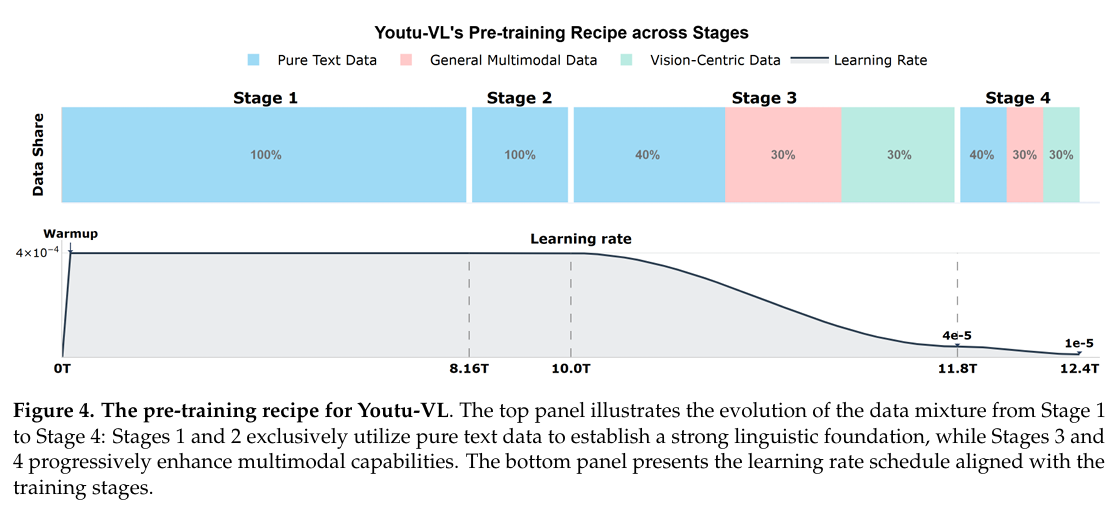
阶段 1 和 2:语言骨干预训练。Youtu-VL 语言骨干通过两个不同阶段进行训练:常识预训练(阶段 1)和 STEM 与编码中心预训练(阶段 2)。这些阶段共同涵盖约 10T tokens 的纯文本数据,使模型在通用推理、STEM 和编码任务上具备卓越能力。数据混合和训练方案的详细规格在 Youtu-LLM 技术报告 [Lu et al., 2026] 中提供。
阶段 3:多模态基础预训练。为使模型具备稳健的视觉感知和多模态理解能力,我们利用包含图像-标题对和视觉中心任务数据的综合多模态数据集。这种多样化混合促进广泛世界知识、跨模态上下文理解以及各种视觉感知任务的熟练掌握。在此阶段,Youtu-VL 的所有组件——包括 LLM 骨干、视觉编码器和投影器——均以端到端方式完全可训练。为保留并进一步增强骨干的语言能力,我们纳入 Youtu-LLM 通用中期训练阶段的高质量文本语料库。通过将此文本数据与多模态样本混合,模型在总计约 1.8T tokens 上进行训练,平衡视觉和语言能力。
阶段 4:多功能任务适应。此阶段使模型专业化,具备涵盖广泛任务的能力,包括通用 VQA、OCR、STEM、GUI、检测、分割、定位和姿态估计。整个模型在约 0.6T tokens 的多样化高质量多模态指令数据集上进行端到端训练,使其能够有效泛化到多样化用户指令。此外,我们纳入大量高质量合成短思维链(CoT)数据。此阶段赋予模型长上下文理解和生成能力,以及基础逻辑推理技能。
3.2 预训练数据
3.2.1 视觉中心数据
文本数据。第 2.2 节中描述的大多数视觉中心任务通过文本预测实现。大部分数据基于开源数据集构建,结合部分内部数据和合成数据。我们根据任务详细阐述数据细节。(1) 视觉定位:除利用广泛采用的开源定位数据集外,我们还从对象检测和场景图数据集中策划多样化的定位查询。此外,我们采用自动标注管道从大规模图像-文本对合成额外定位数据。(2) 对象检测:我们利用多个开源对象检测数据集,并基于边界框标注制定具有不同要求的检测任务,使模型能够识别广泛对象类别。此外,我们合成更密集、更多样化的数据集以进一步增强模型的检测能力。(3) 基于多边形的分割针对指代表达和实例任务。我们将点压缩在 20 个以内以实现高效训练并避免超出窗口大小。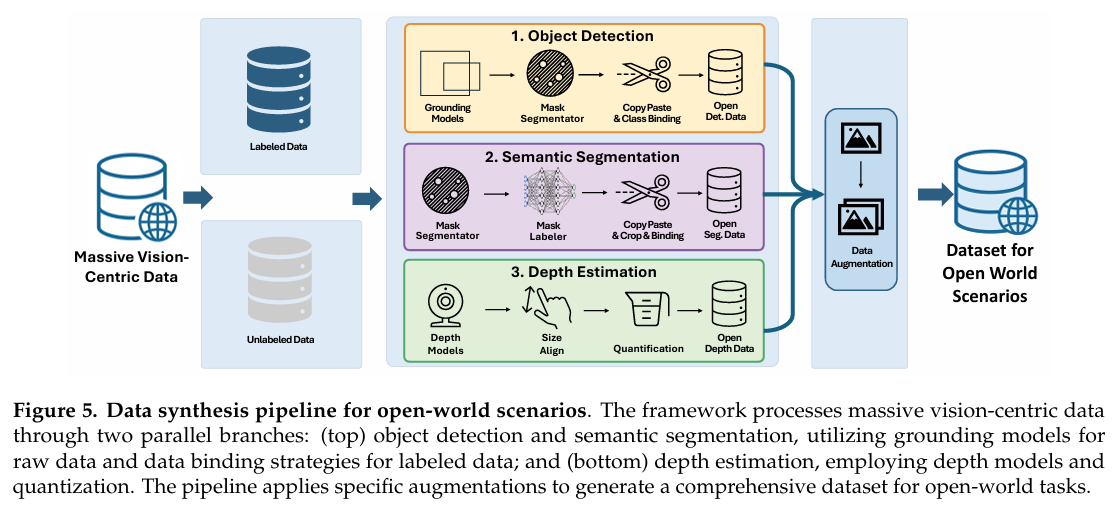
针对概念理解和关键点感知,数据包括:(1) 对象计数:除开源计数数据集外,我们通过从视觉定位和检测数据合成计数数据来扩充训练集。支持两种推理变体:直接计数和先检测后计数方式。(2) 图像分类:我们利用开源分类数据集建立模型的分类熟练度。这使模型不仅能识别常见对象和场景,还能识别细粒度生物分类概念。(3) 人体姿态估计:我们将姿态估计公式化为统一的关键点预测问题,在单次前向传递中直接回归图像中所有人的关节坐标。
密集标注数据。密集标注数据主要源自开源数据集和合成数据。我们根据特定密集预测任务详细阐述数据处理策略。(1) 语义分割:我们通过将数值掩码标签映射到文本描述来构建训练数据。在数据加载阶段,标签被转换为 token 索引,其中有效类别索引被分配正标签,而未标注或无效区域在损失计算期间被显式忽略。(2) 实例和指代表达分割:我们将二值分割与检测和定位任务集成以支持高质量场景。我们通过随机颜色边界框利用视觉提示,并分配前景()和背景()词表以实现高质量框提示分割。此外,我们应用多样化增强技术,包括填充、裁剪和调整大小,以增强模型鲁棒性。(3) 深度估计:我们实施线性量化管道将有效深度范围映射到离散 bins(1–1000)以用于已知相机,标签 0 用于忽略标签。提示在图像前处理以允许模型适应变化的相机参数,增强涉及颜色抖动和随机裁剪,对高分辨率数据使用原始值,对低分辨率源使用固定比例调整大小(例如 3x)。预测随后反量化为实际深度用于评估。
开放世界场景数据管道。开放场景数据集通过处理大规模视觉中心数据构建,分为两个主要分支以支持对象检测、分割和深度估计。对于对象检测和语义分割,管道处理原始和标注数据。原始数据通过定位模型和分割器处理,而标注数据经过数据绑定以处理单个、多个或类别集。此合成解决四个需求:指定正类别、混合正负类别(用于封闭集场景)以及生成密集场景。这些输入产生类别合并和类别采样输出。具体而言,"任意类别"场景采用复制粘贴策略,其中透明对象在随机调整大小和旋转后被密集放置在背景上。对于深度估计,管道类似地分割处理。原始数据通过深度模型传递以使用开源模型生成伪标签。标注数据经过调整大小和量化以模拟具有 2000 像素固定焦距的稳定相机参数。我们利用对数均匀量化,采用灵活的提示放置来定义 0.5m 至 100m 的有效深度范围;因此,具有不同焦距的输入图像表示相对深度并需要缩放。最后,两个分支的输出通过任务特定增强(检测、分割和深度)和裁剪二值分割传递,产生用于开放世界场景的最终数据集。
3.2.2 图像标题和知识数据
我们的数据获取管道始于大规模聚合开源图像-文本对。为确保此语料库的完整性和稳健基础,我们实施了严格的多阶段过滤协议。此初始阶段涉及通过 CLIP 分数进行严格的图像-文本对齐过滤 [Radford et al., 2021, Wei et al., 2025, Fang et al., 2023]、NSFW 内容剔除和分辨率约束。在修剪不可用链接和损坏数据后,此初步清理产生了约 5 万亿 tokens 的原始语料库。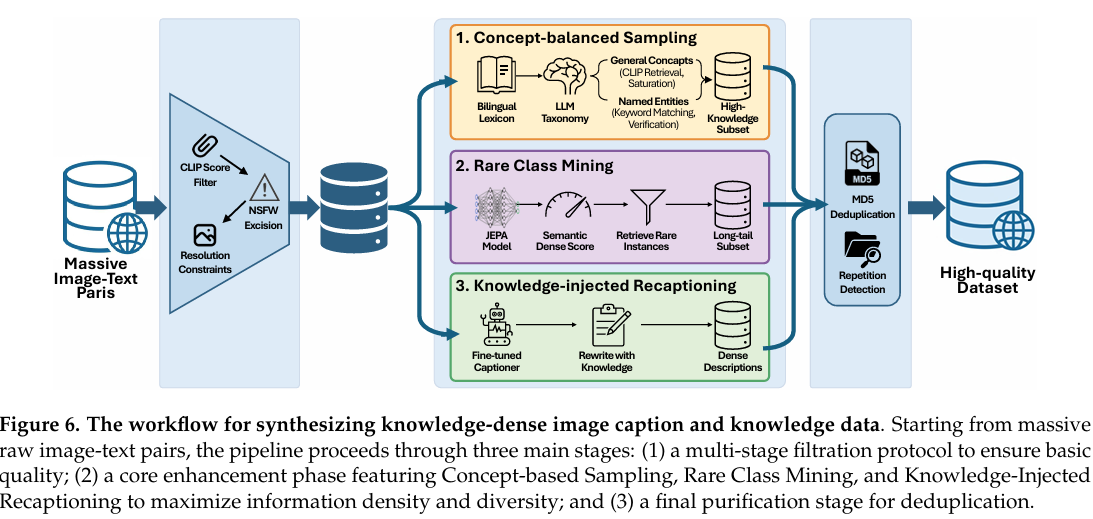
在此基础上,我们通过三管齐下的策略最大化信息密度和训练效率:基于概念的平衡采样、稀有类别挖掘和知识注入重标注。
• 基于概念的平衡采样。受 MetaCLIP [Chuang et al., 2025] 方法论启发,我们超越随机采样,采用严格的、基于本体的方法。我们策划了源自多个百科全书来源的全面双语词典(中文和英文)。LLMs 被用于将每个条目分类为通用概念(例如"足球"、“电影摄影”)或命名实体(例如特定电影标题、历史人物)。对于通用概念,我们采用 CLIP 分数检索挖掘训练数据,直到每个概念达到预定义的饱和阈值。对于命名实体,其中事实精确性至关重要,我们利用严格的关键词匹配和实体验证以确保正确关联。这种平衡采样策略使我们能够有效地从原本稀疏且嘈杂的原始分布中提取高知识密度数据子集。
• 通过 JEPA 分数进行稀有类别挖掘。基于概念的采样本质上偏向常见实体,使数据分布的显著长尾未被充分探索。为纠正此问题,我们利用基于 JEPA 的密度度量来识别和检索位于潜在空间稀疏区域的稀有实例。具体而言,我们利用最先进的 JEPA(联合嵌入预测架构)系列模型为每个数据点计算"语义密度分数",类似于 [Balestriero et al., 2025] 中讨论的方法。通过识别潜在空间中低密度区域的样本,我们基于自适应阈值选择性地保留稀有但语义独特的示例,确保模型暴露于多样化的视觉流形。
• 知识注入重标注。虽然大规模开源图像标题数据集推动了近期进展,但它们经常遭受简短性和噪声困扰。为提升模型的细粒度视觉理解,我们开发了专用的"知识注入标题器",通过微调多模态模型实现。此标题器被部署以重写数据集,将稀疏网络文本转化为密集、详细且视觉接地的描述。此过程不仅减少幻觉,还将文本模态精确对齐到视觉内容。
最后,策划的数据集经历净化阶段。我们应用 MD5 校验和去重以消除冗余,并利用重复检测启发式方法消除循环生成伪影。此管道的最终成果是一个干净、紧凑且高保真的数据集,包含约 1 万亿 tokens,作为我们视觉-语言对齐的基石。
3.2.3 光学字符识别(OCR)数据
为增强 OCR 和细粒度图表理解的熟练度,我们策划了专注于视觉感知和推理的高质量数据集。最初,我们整合现有开源人工标注数据集以建立基线能力。然而,我们识别出这些传统资源的显著局限性:(1) 简短性,其中响应通常过于简洁;(2) 单调性,以提示模式缺乏多样性为特征;(3) 中间步骤缺失,因为人工标注通常提供最终答案而无中间推理过程(即短思维链)。此缺失导致次优训练效率和对复杂、未见查询的有限泛化。因此,我们转向合成大规模详细数据集,该数据集构成我们训练语料库的核心。
我们的数据合成管道采用三管齐下的方法以确保高质量和多样性。首先,为利用大量未标注数据,我们聚合原始 PDF、学术图表和真实文档图像的集合。我们利用 LLM 从各种视角和难度级别生成多样化问题,随后由强大 VLM 生成详细、描述性答案,创建丰富的指令遵循对。其次,针对现有人工标注数据的缺陷,我们引入逻辑一致性精炼管道。LLM 评估现有 QA 对的逻辑连贯性;对于被认为不透明的样本,VLM 以显式逐步推理重新生成响应。此过程由闭环验证机制保护,其中 LLM 验证新推理路径是否与原始 ground truth 保持一致。最后,为进一步扩展训练数据,我们使用稳健渲染引擎从纯文本语料库构建大规模合成 OCR 数据集。此引擎应用随机排版增强并模拟真实世界采集条件——具体通过叠加复杂背景纹理(例如纸张颗粒、阴影)并应用物理失真(例如模糊、噪声、仿射变换和旋转)——以生成数百万干净、准确且视觉多样化的训练样本。
3.2.4 科学、技术、工程和数学(STEM)数据
STEM 数据集旨在增强基于图像的分析和推理能力。该数据集涵盖广泛的视觉密集型 STEM 场景,包括几何图表、图表和曲线图、物理插图、化学结构、工程示意图和考试风格问题图表。为构建能够支持复杂推理的数据集,我们实施了包含三个关键阶段的复杂策划管道:
• 多维质量过滤。我们通过聚合多样化 STEM 相关数据集启动此过程。为清除低质量样本,我们部署了利用 VLMs 和 LLMs 的评分系统。每个样本在三个关键维度上进行严格评估:视觉相关性、答案正确性和推理完整性。仅满足所有指标高阈值的数据被保留用于后续精炼阶段。
• 合成与一致性验证。认识到传统数据通常缺乏详细推理步骤,我们利用 VLM 根据图像和问题重新合成答案。为确保这些合成响应的保真度,我们采用双管验证策略。对于具有现有 ground truth (GT) 的样本,LLM 验证合成答案与原始答案之间的语义对齐。对于缺乏 ground truth 的合成数据集,我们实施验证协议。我们利用 LLM 生成原始问题的多个语义等价但句法不同的变体(即提示扰动)。随后要求 VLM 回答这些多样化查询。我们实施严格的一致性过滤器,仅保留那些模型在所有查询变体上展示推理不变性——在所有查询变体上产生一致答案——的样本。这确保生成的知识是稳定的。最后,我们使用我们的质量指标重新评估新详细答案与原始答案,保留更优候选者以最大化信息密度。
• 视觉接地问题扩展。单个问题通常无法穷尽复杂图像中嵌入的知识。为纠正此问题,我们微调专用的"问题预测 VLM",该模型将图像和答案作为输入以预测相应问题。这使我们能够为每个图像生成多样化、有意义的查询。这些增强对通过编辑距离启发式方法、基于 LLM 的去重和视觉相关性评分进行过滤。此外,我们通过利用 LLMs 从标题中提取知识实体并提示 VLM 基于这些点制定教育问题来重新利用图像标题数据。最后,为模拟真实世界使用场景(例如拍摄试卷照片),我们采用 OCR 管道中的渲染策略。文本问题被动态渲染到图像上,创建稳健数据集以模拟物理文档的视觉噪声和布局。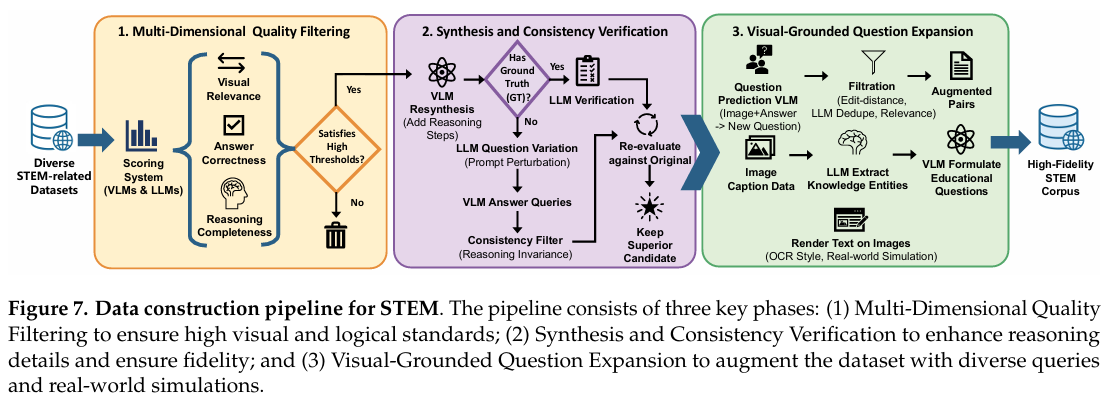
通过这些管道的协同作用,我们最终构建了高保真 STEM 语料库,其特征是严格的推理链、多样化查询视角和稳健的视觉接地,显著增强了模型在 STEM 领域的能力。
3.2.5 图形用户界面(GUI)数据
为使 Youtu-VL 具备自主 GUI 交互的智能体能力,我们使用双流数据策划管道进行持续预训练,该管道由单轮定位数据和长程交互轨迹组成。
• 细粒度感知与定位:为建立稳健的原子 UI 理解和操作能力,我们从各种开源数据集聚合单轮数据。我们实施严格的数据生产和过滤过程,利用集成 LLM 作为评判框架 [Lin et al., 2025] 以确保标签正确性。此高保真数据对于增强模型的细粒度能力至关重要,特别是在元素描述、密集标题和密集定位方面,从而实现对多样化用户界面的稳健理解。
• 顺序交互动态:为推进策略模型对环境动态和多步交互逻辑的推理,我们使用大规模沙盒系统合成跨平台轨迹,涵盖桌面、移动和 Web 环境 [Xie et al., 2024, Shi et al., 2025]。此合成管道旨在最大化任务多样性并模拟不同应用程序中的真实操作环境。在整个合成过程中,我们实施严格的隐私和访问控制协议,以确保沙盒中产生的轨迹不含个人身份信息和未授权内容访问。
• 奖励引导的混合验证:我们通过分层过滤策略对两个数据流实施严格质量控制。候选者根据我们集成评判框架 [Lin et al., 2025] 的分数进行排名和过滤:最高分轨迹经过严格人工标注以构建用于后训练的优质数据集,而其余验证数据用于持续预训练。
3.2.6 纯文本数据
为保留模型的基本语言能力,我们纳入 Youtu-LLM 使用的中期训练数据,涵盖 Web、百科全书、STEM 和编码等领域。数据获取和策划的全面细节可在 Youtu-LLM 技术报告 [Lu et al., 2026] 中找到。
3.3 预训练范式分析
标准 VLM 基准测试主要采用零样本设置。然而,预训练检查点通常缺乏指令对齐,导致格式不匹配,从而掩盖模型的内在能力。为将表示质量与指令遵循技能解耦,我们采用与近期基础 LLM 评估方法论一致的少样本评估协议 [DeepSeek-AI et al., 2025]。具体而言,我们利用上下文学习标准化输出格式,从而在不依赖显式指令调优的情况下公平评估基础模型的进展。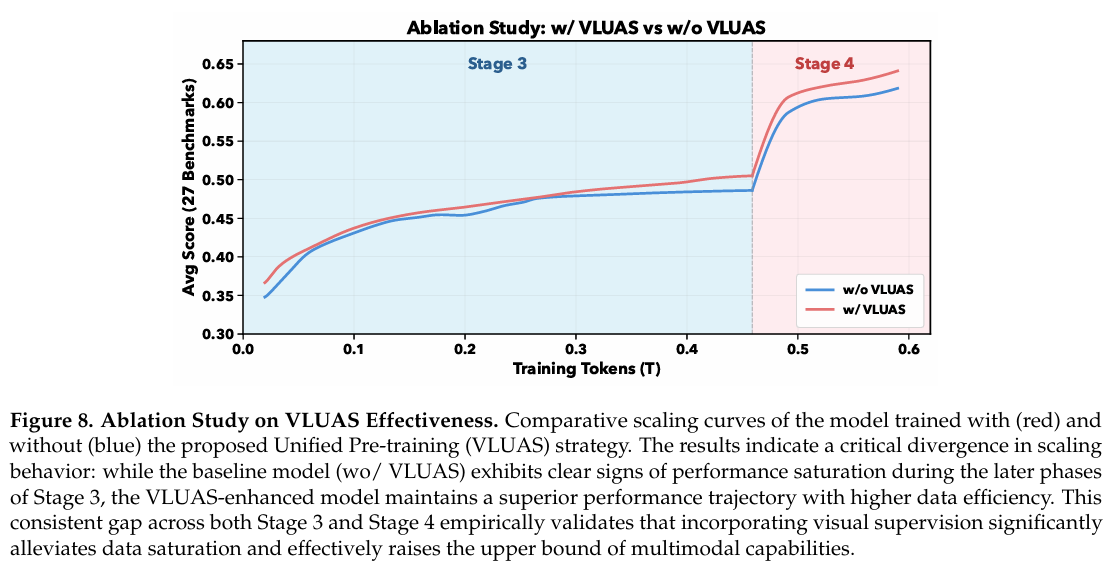
利用此严格协议,我们分析阶段 3 和 4 中多模态理解的扩展动态。如图 8 所示,27 个多模态基准测试的平均性能突显了我们的 VLUAS 范式与传统文本主导监督基线之间的明显分歧。文本主导模型在阶段 3 早期就表现出性能饱和迹象,指向当监督局限于语言模态时的根本瓶颈。相反,VLUAS 维持陡峭的学习轨迹,有效绕过此过早平台期。此优势延伸至阶段 4;即使在数据质量提高的情况下,VLUAS 仍展示出卓越的数据效率并持续扩大性能差距。这些实证结果证实,整合生成式视觉监督不仅作为辅助任务,而且从根本上提升了模型的能力上限。
3.4 数据扩展分析
为系统评估我们预训练的可扩展性和稳定性,我们进行了涵盖 2.4T tokens 的全面分析。如图 9a 所示,模型在统一训练量与多模态性能(27 个基准测试的平均值)之间表现出稳健、单调的正相关。训练轨迹跨越两个不同数据机制,阶段 3(多模态基础预训练)和阶段 4(多功能任务适应),我们的优化策略始终将增加的计算投资转化为切实的能力提升。在整个预训练生命周期中,涵盖阶段 3 中混合文本-视觉语料库的基础学习和阶段 4 中的高质量指令调优,平均基准分数展示持续上升趋势,从约 0.43 上升到最终收敛超过 0.74。此持续增长证实我们的预训练有效利用大规模数据,保持高样本效率,而未遇到多任务优化中常见的早期饱和或不稳定性。
通过评估评估误差( ϵ \epsilon ϵ)随训练计算量(GFLOPs)的扩展,我们量化模型性能轨迹的可预测性。如图 9b 的对数-对数图所示,我们的统一预训练过程严格遵循神经扩展定律,拟合幂律方程 L ( C ) ∝ C − α L(C) \propto C^{-\alpha} L(C)∝C−α。具体而言,阶段 3 机制展示陡峭的扩展指数 α ≈ 0.102 \alpha \approx 0.102 α≈0.102,表明通用文本语料库与多模态样本的整合促进快速信息吸收和初始阶段的高数据效率。过渡到阶段 4 后,模型进入精细化扩展机制, α ≈ 0.079 \alpha \approx 0.079 α≈0.079。虽然随着性能接近不可约误差下限,指数自然缓和,但对数尺度上的持续线性关系作为强有力的实证证据,表明我们的训练基础设施即使在复杂任务适应和长上下文 CoT 生成期间仍保持计算效率,有效将海量资源转化为可预测的模型改进。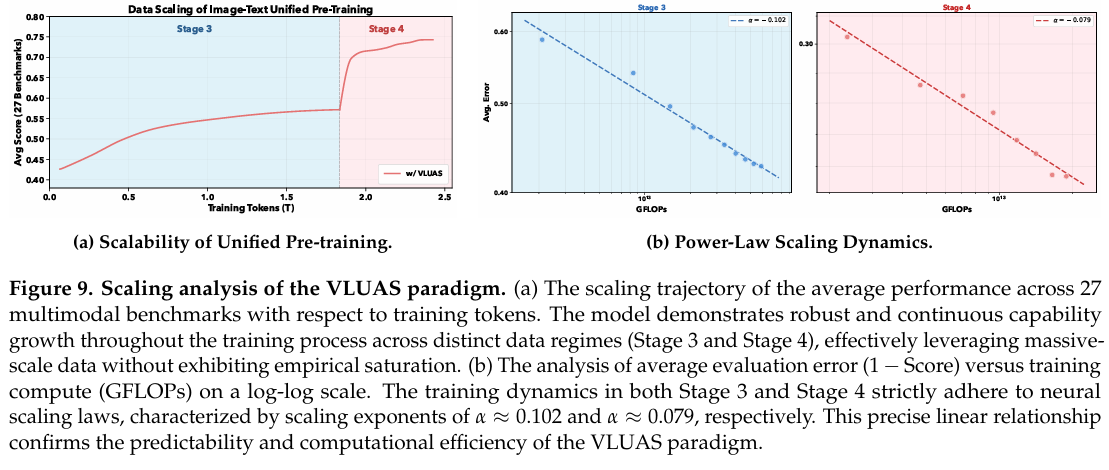
3.5 视觉表示分析
为评估视觉表示的质量,我们对 LLM 输出的视觉 token 的最后一层隐藏状态执行 PCA,并将其投影回原始图像的空间维度,如图 10 所示。对于缺乏视觉 token 监督的 VLM,我们观察到从 Qwen2.5-VL 到 Qwen3-VL 的清晰进展;后者展示更卓越的表示质量,对象之间具有更大区分度,这与其改进的模型性能呈正相关。值得注意的是,我们的 Youtu-VL-4B(无视觉监督)展示与 Qwen3-VL 相当的表示能力。然而,在整合视觉 token 监督后,Youtu-VL-4B 的视觉表示展示显著改进,具有清晰的语义结构和锐利的对象分离。此定性结果为我们的视觉监督提议的有效性和必要性提供了令人信服的证据,特别是在视觉表示方面。
4 后训练
4.1 监督微调
4.1.1 训练方案
监督微调旨在精炼模型理解复杂指令的能力、增强推理能力并与人类偏好对齐。在此阶段,我们将上下文窗口从初始的 16K tokens 扩展到 32K tokens。我们采用 AdamW [Loshchilov and Hutter] 优化器配合余弦学习率调度器。具体而言,我们设置 5% 的预热比例,学习率从峰值 2 × 10 − 5 2 \times 10^{-5} 2×10−5衰减到 2 × 10 − 6 2 \times 10^{-6} 2×10−6。
4.1.2 数据策划
我们致力于策划全面、高质量的 SFT 数据集,涵盖多样化的多模态任务谱系。为实现此目标,我们实施多源数据获取策略:
• 从预训练语料库中高质量挖掘。为从我们庞大的预训练语料库中提取高价值指令遵循数据,我们采用分层采样策略。我们首先利用 VLM 评估单个样本的质量和对齐度。为确保任务多样性,我们建立细粒度关键词分类法。通过对此分类法进行样本平衡并基于 VLM 分数进行过滤,我们从原始池中策划优质子集,有效最大化数据效率。
• 精炼开源数据。现有开源数据集通常受限于简单的"是/否"或单字答案,不足以训练稳健推理能力。我们将这些数据集仅视为图像和提示的来源,同时完全合成新的目标响应。通过采用严格的重写和扩展管道,我们提示强大 VLM 分析视觉细节并生成全面的段落级描述和推理步骤。此方法有效地将原始数据的信息密度"提升"一个数量级。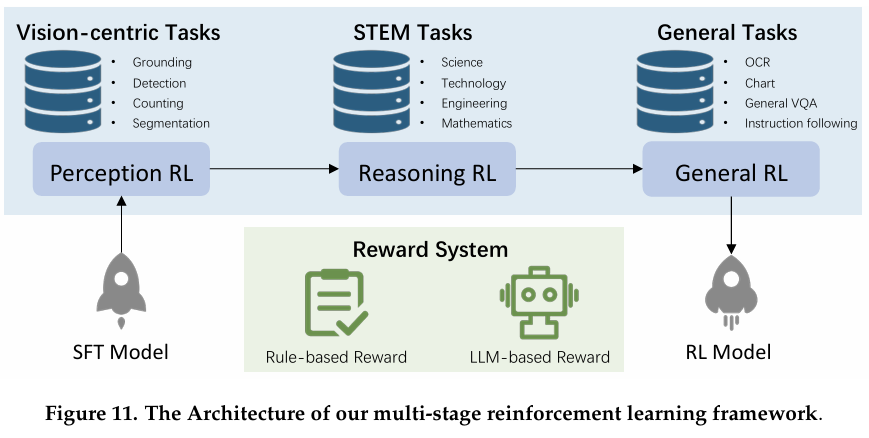
4.2 强化学习
为在监督微调阶段之外进一步释放模型潜力,我们采用多阶段强化学习框架。如图 11 所示,我们提出的框架遵循复杂的三阶段训练过程:
• 感知 RL。第一阶段致力于增强模型的细粒度视觉感知。在此阶段,我们专注于视觉中心任务,如视觉定位、对象检测、语义分割、对象计数等。通过利用针对这些任务定制的 RL 目标,我们的模型被优化以精确定位和解释图像内的结构元素。
• 推理 RL。第二阶段目标是增强模型的复杂推理能力。我们利用策划的 STEM(科学、技术、工程和数学)数据集,该数据集整合文本单模态和多模态数据。通过采用可验证奖励信号引导模型,我们有效弥合基础视觉识别与复杂问题解决之间的差距。
• 通用 RL。在基于可验证 STEM 任务的强化学习基础上,第三阶段将重点转向更广泛任务的泛化。通过整合多样化通用 VQA 挑战集,包括 OCR、图表理解、指令遵循等,我们进一步提升模型的泛化能力。
4.2.1 数据策划
为确保我们多阶段强化学习框架的稳定性和效率,我们实施严格的数据策划管道。我们的目标是构建多样化、高质量且最重要的是可验证的跨领域数据集,包括视觉中心任务、STEM、OCR、图表理解、通用 VQA 和复杂指令遵循。策划过程包括以下四个步骤:
• 任务分类。我们首先将从广泛开源多模态数据集收集的样本分类为以下领域:视觉中心任务、STEM、OCR、图表理解、通用 VQA 和复杂指令遵循。此分类使我们能够定制与每个任务要求对齐的领域特定奖励信号。
• 基于可验证性的过滤。为确保 RL 过程中奖励信号的精确性,我们进一步过滤掉难以轻松验证的样本。具体而言,我们首先将每个任务领域收集的样本分类为主观和客观类型。客观样本因提供确定性 ground-truth 标签而优先用于训练,便于自动化和高保真验证。此外,我们过滤掉本质上难以验证或易受随机猜测影响的样本,例如多项选择、真假和多问题提示。
• 质量保证。为保证用于训练的响应正确性,我们采用基于共识的验证机制。我们利用现有模型套件对候选数据执行交叉验证。仅当达成明确共识时才保留样本。
• 复杂度校准。最后,我们进行离线难度分级以优化学习课程。对于每个候选样本,我们使用我们最先进的 SFT 模型生成八个独立响应。所有响应均正确的样本被丢弃。
4.2.2 奖励系统
如表 1 总结,我们为不同任务设计任务特定奖励信号,以提供可靠优化目标。对于视觉中心任务(例如定位、检测、分割、计数),奖励通过标准指标(如 IoU 或 mAP)将结构化预测与确定性标注进行比较计算,产生高保真且完全可验证的反馈。在 STEM 领域,我们实施严格输出格式以促进自动答案提取并应用基于规则的验证。对于基于规则的验证失败的情况,我们额外执行与强大 LLM 验证器的一致性检查。对于 OCR 和图表理解,我们利用精确字符串匹配和编辑距离分别用于定位和解析任务。为解决更通用的 VQA 任务,我们使用 LLM 基于一致性检查对比参考答案和模型响应。最后,对于复杂指令遵循任务,我们采用具有详细评分标准和参考答案的 LLM 作为评判者以获得标量奖励。
除任务特定奖励外,遵循 Youtu-LLM [Lu et al., 2026],我们纳入两个辅助奖励以防止常见失败模式。(i) 语言一致性奖励通过惩罚响应中主导语言偏离预指定目标语言的情况来阻止代码切换和混合语言输出。(ii) 重复检测奖励通过惩罚具有过度 n-gram 重复的退化生成来缓解模型循环且无法终止的情况。
4.2.3 训练方案
训练配置。我们遵循 DAPO [Yu et al., 2025] 采用的设置。最大上下文长度设置为 32,768 tokens。在每个训练阶段,我们采样 6,144 个当前策略的 rollout。策略优化使用 1,536 的小批量大小执行,每个训练迭代进行 4 次梯度更新步骤。策略网络的学习率固定为 1 × 10 − 6 1 \times 10^{-6} 1×10−6。为平衡训练稳定性和策略探索,裁剪范围设置为 [0.20, 0.24],这有助于防止过于激进的策略更新,同时在训练期间鼓励充分探索。此外,为抑制过长生成,我们引入软过长惩罚机制。具体而言,我们分析模型输出长度的分布并相应设置过长阈值。遵循先前工作 [Qi et al., 2025],我们在训练期间移除 KL 惩罚项并采用 FP16 训练。实证上,这些设计选择导致更快收敛和更稳定的训练动态。
基于奖励方差的采样。在强化学习中直接应用标准采样策略通常导致训练不稳定。当优势值接近零时,相应策略梯度减小,降低有效梯度幅度并增加对噪声的敏感性。此问题因引入软过长惩罚而进一步放大,该惩罚为某些样本分配负奖励并导致无长度惩罚的零奖励样本在小批量更新中占主导地位。此外,与先前具有离散奖励(例如二进制 0/1 信号)的设置不同,我们的框架采用连续奖励值。此问题在视觉中心任务中尤为突出,其中基于奖励的采样启发式方法保留许多具有高度相似奖励的样本,导致奖励区分不足。为解决这些问题,我们提出基于方差的动态采样策略。具体而言,对于为提示 q q q生成的每个 rollout 组 O q = { o 1 , … , o G } O_q = \{o_1, \ldots, o_G\} Oq={o1,…,oG},我们计算相应奖励的方差并丢弃奖励方差低于预定义阈值的组。此外,我们要求 rollout 组中至少一个样本接收正奖励,这有助于避免当整体奖励信号非正时的误导性优化信号,并进一步提高训练稳定性。此策略有效移除奖励区分不足的样本组,提高样本质量并稳定策略优化。
一致性采样。先前工作已将训练后端与推理引擎之间的不匹配确定为影响强化学习有效性的关键因素。为缓解此问题,我们遵循 Youtu-LLM [Lu et al., 2026] 并采用一致性采样策略以提高训练稳定性。对于给定提示 q q q,KL 度量 K ( q ) K(q) K(q)用于测量训练策略与 rollout 策略之间的分歧。
K ( q ) = E a ∼ π r o l l o u t ( ⋅ ∣ q ) [ π θ ( a ∣ q ) π r o l l o u t ( a ∣ q ) − 1 − log π θ ( a ∣ q ) π r o l l o u t ( a ∣ q ) ] . K(q)=\mathbb{E}_{a\sim\pi_{\mathrm{rollout}}(\cdot|q)}\left[\frac{\pi_{\theta}(a|q)}{\pi_{\mathrm{rollout}}(a|q)}-1-\log\frac{\pi_{\theta}(a|q)}{\pi_{\mathrm{rollout}}(a|q)}\right]. K(q)=Ea∼πrollout(⋅∣q)[πrollout(a∣q)πθ(a∣q)−1−logπrollout(a∣q)πθ(a∣q)].
对于每个提示 q q q,仅当相应策略分歧满足 K ( q ) ≤ τ K K(q) \leq \tau_K K(q)≤τK时,为该提示生成的 rollout 组 O q = { o 1 , … , o G } O_q = \{o_1, \ldots, o_G\} Oq={o1,…,oG}才被允许用于训练。违反此条件的 rollout 组在采样阶段被直接过滤掉,确保模型仅在具有约束策略漂移的样本上进行优化。
基于上述采样策略,最终强化学习目标定义为:
J ( θ ) = E q ∼ D , { o i } i = 1 G ∼ π r o l l o u t ( ⋅ ∣ q ) [ 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ l o w , 1 + ϵ h i g h ) A ^ i , t ) ] \mathcal{J}(\theta)=\mathbb{E}_{q\sim\mathcal{D},\{o_{i}\}_{i=1}^{G}\sim\pi_{\mathrm{rollout}}(\cdot|q)}\left[\frac{1}{\sum_{i=1}^{G}\left|o_{i}\right|}\sum_{i=1}^{G}\sum_{t=1}^{\left|o_{i}\right|}\min\Big(r_{i,t}(\theta)\hat{A}_{i,t},\ \mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon_{\mathrm{low}},1+\epsilon_{\mathrm{high}}\big)\hat{A}_{i,t}\Big)\right] J(θ)=Eq∼D,{oi}i=1G∼πrollout(⋅∣q) ∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,t(θ)A^i,t, clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i,t)
s . t . max 1 ≤ i ≤ G R ( o i ) > 0 , K ( q ) ≤ τ K , V a r ( { R ( o i ) } i = 1 G ) > τ V . \begin{array}{l l}{\mathrm{s.t.}\operatorname*{max}_{1\leq i\leq G}R(o_{i})>0,\quad K(q)\leq\tau_{K},\quad\mathrm{Var}\Big(\big\{R(o_{i})\big\}_{i=1}^{G}\Big)>\tau_{V}.}\end{array} s.t.max1≤i≤GR(oi)>0,K(q)≤τK,Var({R(oi)}i=1G)>τV.
5 评估
我们对 Youtu-VL 在 30 个视觉中心和 45 个通用多模态基准测试套件上进行了广泛评估。据我们所知,这是首次尝试统一评估 VLM 在数十个不同任务上的表现,范围从定位、检测、分类、计数、分割、深度估计和姿态估计到视觉问答、OCR 和 GUI 操作。为解决现有框架 [Li et al., 2024, Duan et al., 2024, Zhang et al., 2024] 在处理此类多样性方面的局限性,我们扩展了 VLMEvalKit [Duan et al., 2024],整合了额外的视觉中心和纯文本评估任务,从而建立了全面统一的评估管道。如图 1 底部的两个条形图所示,我们展示了模型在各个维度上与其他模型的熟练度比较。具体针对通用多模态基准测试,我们仅使用三个模型均有结果的基准测试计算每个类别的平均分数。每个评估基准测试的详细实证结果在以下小节中提供。
5.1 视觉中心任务
现有基准测试在数据集间具有不一致的标签集定义。为解决此问题,我们在提示中包含基准测试名称以提供必要上下文。同时,我们支持手动指定标签集(例如用于语义分割)。鉴于完整标签集通常过大而无法适应提示上下文窗口,基准测试名称是主要类型。对于实际推理任务,用户可提供自定义标签集以识别目标对象或某些灵活提示,支持存在和不存在的类别。评估细节和提示在附录 A.1 中给出。评估结果在表 2 中给出,实验分析如下。
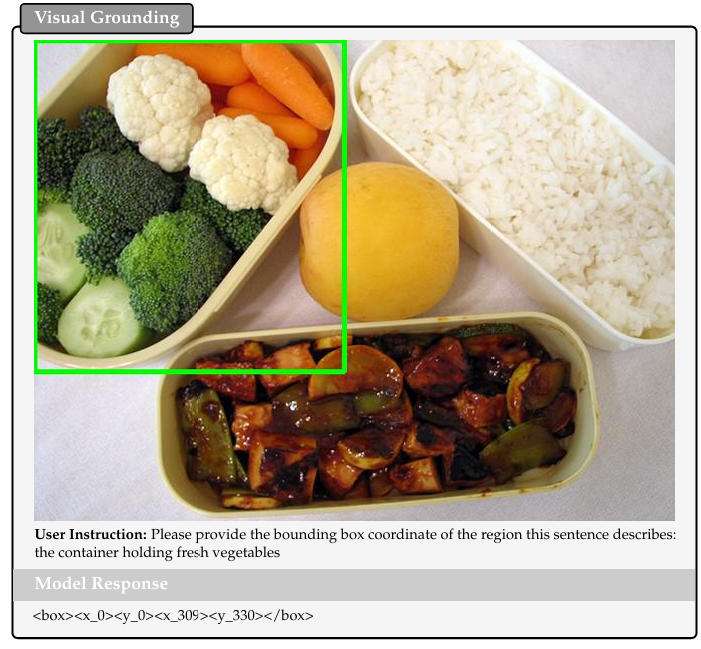
视觉定位。我们在标准 RefCOCO/+/g 基准测试 [Yu et al., 2016] 上评估 Youtu-VL 以评估其定位能力。Youtu-VL 展示卓越的定位性能,在所有 RefCOCO 拆分上达到 91.8% 的平均分数。相比之下,InternVL-3.5-4B 的平均结果为 89.4%,专有 Seed1.5-VL [Guo et al., 2025] 为 91.6%。这些结果证明 Youtu-VL 在视觉定位任务上的熟练度。
对象检测。对于对象检测,Youtu-VL 生成直接文本输出而无需额外头。此方法在 COCO [Lin et al., 2014] 上使用 2017 验证拆分产生具有竞争力的性能。具体而言,Youtu-VL 达到 47.1% mAP,而 GiT [Wang et al., 2024] 的结果为 46.7%。它还在性能上与 UFO [Tang et al., 2025](48.9% mAP)保持相当,尽管 UFO 是更大的、任务感知模型,受益于密集提议和并行解码。类似地,VisionLLM-v2 [Wu et al., 2024] 从其任务特定解码器中获益,达到 56.7% mAP。与这些方法相比,Youtu-VL 无需额外训练或推理修改即可实现具有竞争力的性能。
语义分割。对于语义分割,Youtu-VL 直接从视觉 token 的输出 logits 预测密集预测。此方法展示强大通用性,而其他通用 VLMs(如 Qwen3-VL 和 InternVL-3.5)不支持这些密集预测任务。在性能方面,Youtu-VL 在 ADE20k [Zhou et al., 2017] 数据集上实现显著改进,达到 54.2 mIoU,而 GiT 的结果为 47.8%。此外,Youtu-VL 证明与经典专家方法 Mask2Former [Cheng et al., 2022] 和基于 CLIP 的 VLMs [Lan et al., 2024, Qiu et al., 2025, Liu et al., 2024, Zhou et al., 2022] 相比具有竞争力的结果。Youtu-VL 在 COCOStuff [Caesar et al., 2018] 数据集上也展示强大性能,无需像 SAN [Xu et al., 2023] 那样进行微调(mIoU 52.5% 对 45.7%)。除定量分析外,分割还支持开放场景,例如指定某些类别和尽可能多的分割类别。这些能力不被经典专家和视觉中心 VLMs 支持。我们在附录 C 中对此进行了定性分析和可视化。
指代表达分割。在此任务中,Youtu-VL 采用定位后分割方式,基于特定文本描述生成精确分割掩码。具体而言,我们生成定位框并在图像上绘制,然后裁剪以分割前景语义。此操作不依赖任何额外解码器(如 SAM 或其他任务特定头),同时显著超越基于多边形的指代表达分割。此方法在可比模型中产生最先进性能。在 RefCOCO [Yu et al., 2016] 验证集上,Youtu-VL 达到 80.7% mIoU,而其他设置的结果分别为 80.0% [Tang et al., 2025]、76.6% [Wu et al., 2024]、80.5% [Liu et al., 2025] 和 79.3% [Ouyang et al., 2025]。我们的方法不依赖预测额外掩码嵌入 token 或额外头,简单而有效。这些结果证明通用模型无需依赖额外任务特定 token 或解码器即可实现像素级精度,同时获得高质量结果。
深度估计。此任务类似于语义分割,其中类别名称被量化 bins 的名称替换。Youtu-VL 直接从单目图像预测密集深度图。与大多数通用和视觉中心 VLMs(例如 Qwen3-VL [Bai et al., 2025]、GiT [Wang et al., 2024])不同,它们缺乏对此空间相关任务的支持,Youtu-VL 无缝集成此能力。在 NYUv2 [Silberman et al., 2012] 数据集上,Youtu-VL 达到$\delta_1 90.4 90.4%,略低于 8B 参数 UFO 模型( 90.4\delta_1 93.6 93.6%),因为未应用任务特定微调且参数较少。相比之下,另一种基于 VLM 的方法 DepthLLM-3B [Cai et al., 2025] 的性能为 86.8%,需要为每个点进行推理。相反,我们的模型无需任何额外推理即可内在获取深度信息。Youtu-VL 在 DDAD [Guizilini et al., 2020] 基准测试上展示强大性能, 93.6\delta_1$为 87.6%,而 DepthLLM-3B 的结果为 74.7%。我们的结果接近专家模型 UniDepth-v2 [Piccinelli et al., 2025](88.2%)。这确立 Youtu-VL 为能够理解 3D 信息以及 2D 语义任务的综合模型。
人体姿态估计。Youtu-VL 通过在单个生成框架内直接回归关键点坐标实现人体姿态估计,避免专家方法的任务特定头。在 MPII [Andriluka et al., 2014] 上,Youtu-VL 达到 89.1%(PCKh@0.5),遵循专家模型 ViTPose Xu et al. [2022](93.3%)的评估协议。此结果接近 LocLLM [Wang et al., 2024](特定关键点上 89.3%)。尽管性能相当,Youtu-VL 是多功能视觉-语言模型(VLM),无需显式姿态估计先验即可运行。详细评估信息可在附录 A.1 中找到。
图像分类。在图像分类任务中,Youtu-VL 被提示生成识别图像中主要对象类别的短语。在 ImageNet-ReaL [Beyer et al., 2020](具有修正 ground-truth 的 ImageNet-1k)上,Youtu-VL 达到 89.3% 的 Top-1 准确率。此性能接近领先专家模型的水平,证明模型在对象识别方面的效率。
对象计数。此任务通过直接输出对象数量而不提供任何选项进行评估。在 CountBench [Paiss et al., 2023] 中,Youtu-VL 达到 88.6% 的准确率,而 Qwen3-VL-4B 的结果为 78.4%(无选项的答案预测)。在简单对象计数场景(TallyQA-simple)[Acharya et al., 2019] 中,Youtu-VL 达到 85.1% 准确率,与通用模型 Omni-SMoLA(86.3%)表现相当。对于复杂计数任务(TallyQA-complex),Youtu-VL 获得 74.4% 的领先分数,而 PaliGemma [Beyer et al., 2024] 的性能为 72.3%。此结果接近专家模型 Omni-SMoLA [Wu et al., 2024](77.1%)。受益于定位数据的广泛训练,Youtu-VL 展示卓越的对象计数性能。
5.2 通用多模态任务
在本节中,我们系统评估 Youtu-VL 在多个维度上的表现,包括通用视觉问答(VQA)、多模态推理、真实世界和多图像理解、OCR 和文档理解、幻觉抑制以及文本中心任务。对于 Qwen3-VL 未官方报告的基准测试,我们额外使用其公开发布的检查点运行评估,以实现更全面的比较。总体而言,我们的模型在广泛多模态任务上持续优于或与同等规模的领先模型持平。
通用视觉问答。为评估 Youtu-VL 的通用 VQA 能力,我们在综合基准测试套件上进行广泛实验,包括 MMBench_V11(EN/CN)[Liu et al., 2023]、MMStar [Chen et al., 2024]、MME [Fu et al., 2023]、CVBench(2D/3D)[Zhu et al., 2025]、ScienceQA [Lu et al., 2022]、SEED-Bench 系列 [Li et al., 2023, 2024] 和 MMVet [Yu et al., 2024],如表 3 详述。在这些基准测试中,Youtu-VL 在需要联合感知和轻量推理的通用视觉理解任务上展示持续强大性能。在 MMBench 上,模型在英文拆分上达到 83.9 分,在中文拆分上达到 83.6 分,表明稳定的多语言视觉-语言对齐。在强调广泛视觉推理和跨多样化问题类型鲁棒性的 MMStar 和 MME 上,Youtu-VL 获得相对高分,反映视觉感知与知识接地的有效整合。此外,模型在 CVBench-2D 和 CVBench-3D 上提供令人印象深刻性能,表明处理结构化视觉表示和核心视觉相关推理的扎实能力。MMVet 上的性能相对较低,表明在需要更强组合推理和响应校准的更复杂指令式 VQA 场景上仍有改进空间。
多模态推理与数学。我们在广泛多模态推理基准测试上评估模型,包括 VLMs Are Blind [Rahmanzadehgervi et al., 2025]、VisuLogic [Xu et al., 2025]、MMMU 系列(MMMU [Yue et al., 2024]、MMMU-Pro [Yue et al., 2024]、CMMMU [Zhang et al., 2024])、MathVista [Lu et al., 2024]、MathVerse [Zhang et al., 2024] 和 LogicVista [Xiao et al., 2024]。这些基准测试共同评估图像接地逻辑、抽象推理、数学理解和知识密集型多模态问题解决。
如表 3 所示,Youtu-VL 在多个推理导向基准测试上取得强大结果。值得注意的是,它在 VisuLogic 上达到 25.7% 分数,在 VLMs Are Blind 上达到 88.9% 分数,展示稳健视觉推理能力。结合其在 LogicVista 上的竞争力表现,这些结果表明 Youtu-VL 在处理逻辑关系、基于规则的推理和图像依赖推理方面有效。在数学相关基准测试上,Youtu-VL 在 MathVerse 上达到 56.5% 分数,并在 MathVista 上保持稳定性能,展示强大的多模态数学推理能力。
在大规模学术基准测试(如 MMMU、MMMU-Pro 和 CMMMU)上,这些基准测试类似于多学科大学水平考试并强调长尾领域知识和长上下文语言推理,Youtu-VL 达到中高水平分数(例如 MMMU 上约 60 分)。虽然这些分数总体具有竞争力,但在最知识密集型和上下文繁重的任务上仍存在适度性能差距。这表明,除扎实的多模态感知和推理外,未来改进可聚焦于扩展专业领域覆盖范围并进一步加强长上下文推理稳定性。总体而言,当前结果表明 Youtu-VL 已提供先进可靠的多模态推理能力,特别是在需要真实图像接地推理、抽象逻辑判断和结构化视觉-符号推理的场景中。
幻觉。我们使用 HallusionBench [Guan et al., 2023]、POPE [Li et al., 2023] 和 CRPE [Wang et al., 2023, 2024] 评估幻觉抑制和指令对齐,这些基准测试专门设计用于探测对抗性图像-问题不一致性以及细粒度对象存在性和关系判断。如表 3 所示,Youtu-VL 展示显著降低的幻觉倾向。在 HallusionBench 上,该基准测试故意呈现问题与图像内容矛盾的场景,Youtu-VL 达到 59.1%。此改进在问题暗示图像中明显不存在对象的情况下尤为显著,表明 Youtu-VL 优先验证视觉证据而非依赖语言先验。在 CRPE e x i s t _{exist} exist和 CRPE r e l a t i o n _{relation} relation上,Youtu-VL 提供值得称赞的性能,残余错误主要源于本质上模糊的边界情况,例如微小对象或严重遮挡。总体而言,Youtu-VL 在保持竞争力指令遵循能力的同时,展示卓越的抗幻觉能力和更严格的图像接地对齐,在视觉证据不足或矛盾时倾向于谨慎响应。我们将此稳健性归因于有效视觉监督的整合,这迫使模型将其预测严格基于视觉信息。
OCR 相关理解与文档 QA。我们在 AI2D [Kembhavi et al., 2016]、InfoVQA [Mathew et al., 2021]、TextVQA [Singh et al., 2019]、DocVQA [Mathew et al., 2021]、ChartQA [Masry et al., 2022]、OCRBench [Liu et al., 2023]、SEEDBench2Plus [Li et al., 2024] 以及 CharXiv 描述和推理子集 [Wang et al., 2024] 上评估细粒度 OCR 能力和文档级问答。这些基准测试涵盖从密集文本识别到结构化文档分析和图表中心视觉-语言整合的任务谱系。
如表 3 所示,Youtu-VL 在 OCR 中心基准测试上提供强大性能,特别是在需要更高级语义理解和文本识别推理的设置中。具体而言,它在 CharXiv D Q _{DQ} DQ上达到约 79% 分数,在 CharXiv R Q _{RQ} RQ上达到约 44% 分数,与可比 4B 级系统相比在描述性和推理式图表理解上均提供数个百分点的明显增益。这些任务要求的不仅是基本文本提取;它们需要对科学图表和图形进行结构化解释,并对轴、图例、曲线和周围文本解释进行联合推理。定性检查进一步表明,Youtu-VL 倾向于以更全局一致的方式捕获文档布局和视觉-文本关系,通常产生既完整又逻辑组织的解释。
在广泛使用的 OCR 繁重型基准测试(如 TextVQA、DocVQA、ChartQA、OCRBench、SEEDBench2Plus、AI2D 和 InfoVQA)上,Youtu-VL 保持总体竞争力分数配置,在多样化数据源和任务格式上展示稳定性能。虽然在某些数据集上其分数略低于报告的最佳数字,但总体结果表明 Youtu-VL 已有效处理信息密集型视觉上下文,并在低级文本识别与高级文档和图表智能之间架起桥梁。
多图像与真实世界理解。我们在 BLINK [Fu et al., 2024]、RealWorldQA [XAI, 2024] 和 MMERealWorld(EN 和 CN)[Zhang et al., 2024] 上评估多图像推理和真实场景理解。如表 3 总结,Youtu-VL 在这些基准测试上提供竞争力性能。具体而言,Youtu-VL 在真实世界和多图像基准测试上展示强大性能。在 RealWorldQA 上,它达到 74.6 分数,表明在处理具有小对象、杂乱背景和复杂对象-场景交互的高分辨率照片方面的稳健能力。在 MMERealWorld 上,Youtu-VL 在英文和中文设置上均获得扎实分数,其中中文拆分上的相对较高分数尤为值得注意,因为模型主要在英文数据上训练。此跨语言稳健性表明底层视觉感知在很大程度上与语言无关,受益于有效视觉监督,这帮助模型聚焦细粒度细节同时保留全局场景上下文。在强调基础多图像匹配和比较的 BLINK 上,Youtu-VL 保持竞争力分数水平,表明它能以一致方式跨图像对齐和比较信息。总体而言,这些结果表明 Youtu-VL 提供强大可靠的现实世界视觉理解,同时保持扎实的多图像推理能力,剩余差距主要出现在更上下文繁重的对话设置中,而非核心视觉感知中。
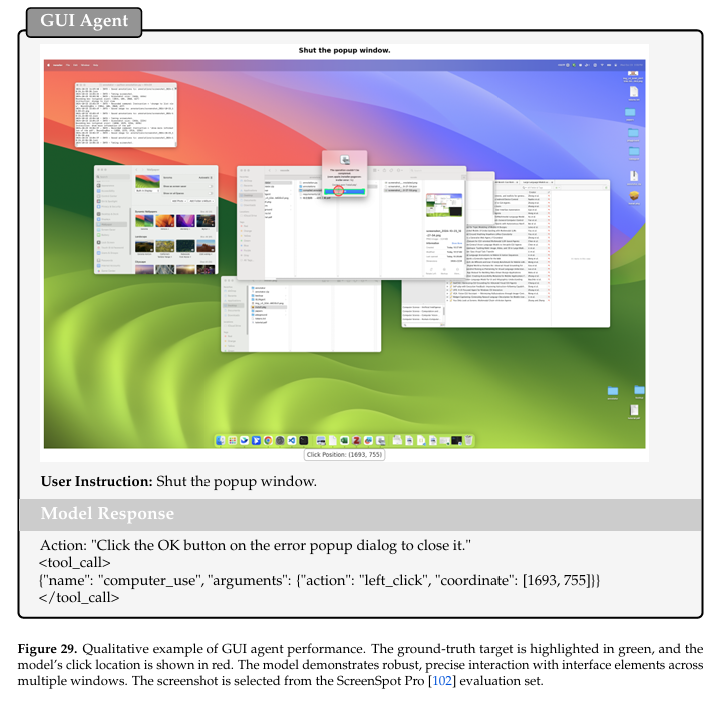
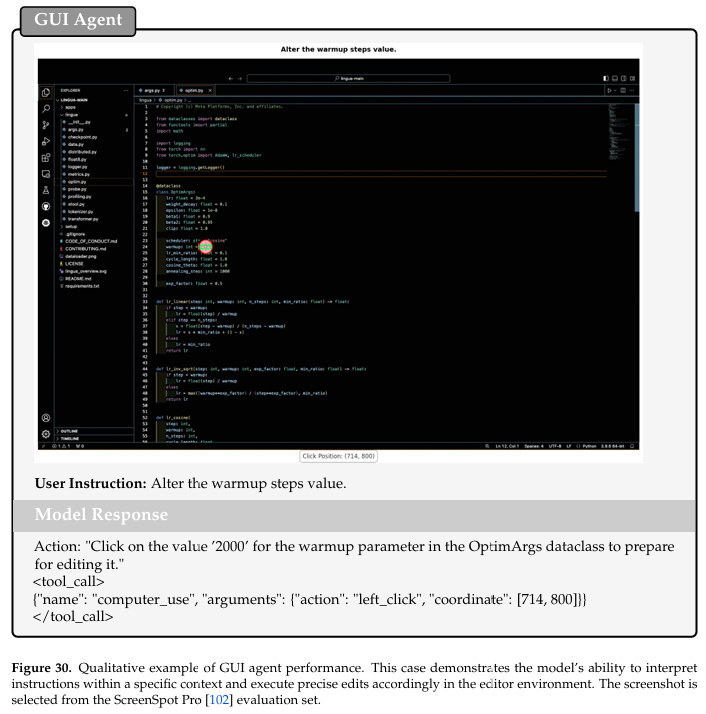
GUI 智能体。我们使用两个主要基准测试评估 Youtu-VL 的 GUI 智能体性能:ScreenSpot Pro [Li et al., 2025] 和 OSWorld [Xie et al., 2024]。ScreenSpot Pro 作为静态单轮定位基准测试,旨在评估模型的基础指令解析和精确坐标预测能力。其包含多样化操作系统和专用跨平台应用程序,确保对模型感知泛化的全面测量。相反,OSWorld 提供动态闭环交互的全面评估。通过利用具有真实软件安装的实时 Ubuntu 沙盒,OSWorld 要求智能体执行多轮推理并适应实时状态转换。此环境通过测试模型在功能操作系统内维持长程目标的能力,准确反映"计算机使用"能力。我们的实证结果证明 Youtu-VL 在两个基准测试上均达到最先进性能,特别是在 OSWorld 上,成功率达到 38.8。这些指标表明 Youtu-VL 具有优越的定位到动作映射,有效将视觉感知转化为有效系统序列,而不仅仅是识别 UI 元素。显著的性能改进凸显模型对"错误累积"的韧性——多轮任务中的常见失败模式,其中单个失误导致不可恢复状态。此外,这些结果证明 Youtu-VL 能够以更高效率和稳健性处理复杂真实计算机使用场景,优于基线模型。
文本中心任务。表 3 最后部分呈现 Youtu-VL 在纯文本基准测试上的评估结果。鉴于 Youtu-VL 的架构主要聚焦多模态能力——特别是视觉中心任务——与最先进模型相比存在明显性能差距。具体而言,在评估指令遵循能力的 IFEval [Zhou et al., 2023] 上,Youtu-VL 达到 76.9 分数,展示在遵守复杂约束方面的胜任能力,尽管未达到顶级语言模型的上限。在 MMLU-Redux [Gema et al., 2024] 上,模型达到 76.8 分数,表明通用知识和推理的稳健基础;然而,其在 GPQA-Diamond [Rein et al., 2023](39.8)上的性能凸显在处理专家级领域推理方面的剩余挑战。总之,虽然 Youtu-VL 为文本交互维持功能性基线,但在语言能力方面仍有显著提升空间,这作为 Youtu-VL 框架未来迭代的关键目标。
6 结论
讨论。在本工作中,我们提出了 Youtu-VL,一个从根本上重塑视觉-语言模型优化格局的框架。通过引入视觉-语言统一自回归监督(VLUAS)范式,我们有效缓解了传统架构中固有的文本主导优化偏差。从静态"视觉作为输入"依赖过渡到生成式"视觉作为目标"目标,Youtu-VL 激励模型同时预测细粒度视觉细节和高层语言语义,从而弥合粗粒度理解与密集感知之间的差距。至关重要的是,我们的结果证明此统一目标使标准 VLM 架构能够原生执行多样化视觉中心任务,无需依赖任务特定解码器或辅助头。这说明高保真感官感知可在单个通用 transformer 内端到端建模。我们的发现标志着 VLM 演化中的关键拐点:从单纯跨模态对齐迈向结构统一。我们认为真正多模态智能并非源于堆叠专家模块,而是源于感知与推理的协同整合。因此,Youtu-VL 不仅作为竞争性基线,更作为下一代通用视觉智能体的基础蓝图。
局限性。尽管 Youtu-VL 在各种基准测试上取得竞争力性能,但它面临某些系统性挑战。首先,当前视觉表示粒度仍是低分辨率输入上高精度任务的瓶颈。其次,模型在专业几何感知任务(例如深度和姿态估计)上的性能仍受其对传感器内禀参数的敏感性和训练分布多样性的限制,限制其在分布外环境中的零样本鲁棒性。此外,虽然 Youtu-VL 在通用感知方面表现出色,但其高级认知能力,特别是在复杂数学推理和密集知识检索方面,需要进一步优化。解决这些基础约束仍是 Youtu-VL 框架未来发展的关键目标。
附录
A 评估细节
A.1 视觉中心基准测试与提示
为确保更好的可复现性,我们提供了视觉中心任务基准测试的评估细节以及具体提示。所有结果均采用零样本方式测试,未使用少样本示例,也未启用思维模式(例如思维链)。
A.1.1 视觉定位
RefCOCO 系列 [59]。对于视觉定位,我们要求模型通过预测边界框直接定位查询对象。具体提示如下:
<image>
Question:
Please provide the bounding box coordinate of the region this sentence describes: the person bottom left
Answer: <box><x_155><y_154><x_221><y_206></box>
开放世界视觉定位。除特定基准测试外,Youtu-VL 还支持各种开放场景提示和目标。我们支持一些灵活提示和中文提示。{keyword} 表示需要定位的目标,通常为单词或短语。
Can you return the bounding box for "[keyword]" in this image?
Output the bounding box for "[keyword]" in this image.
Perform object grounding for "[keyword]" with bounding box.
Can you return the bounding box for {keyword} in this image?
Output the bounding box for {keyword} in this image.
Perform object grounding for {keyword} with bounding box.
Please provide the bounding box coordinate of the region this sentence describes:
{keyword}.
Please get the bounding box coordinate for the target: {keyword}.
Get bounding box for {keyword}.
Identify the bounding box for "[keyword]" in this image.
Locate and return the bounding box coordinates of {keyword}.
Find the bounding box around the object described as "[keyword]".
Provide the coordinates of the bounding box for {keyword}.
Show me the bounding box for the object labeled "[keyword]".
Draw the bounding box for {keyword} and provide its coordinates.
Extract the bounding box for "[keyword]" from the image.
Where is the bounding box for {keyword} located in this image?
Mark the bounding box surrounding {keyword} and return its position.
Return the coordinates of the bounding box that encloses {keyword}.
Give me the bounding box details for the item described as "[keyword]".
Please highlight the bounding box of {keyword} and share the coordinates.
Get the spatial bounding box for the object "[keyword]".
Locate {keyword} in the image and provide its bounding box.
Identify the region bounding box corresponding to {keyword}.
Provide bounding box information for the entity named "[keyword]".
Find and output the bounding box for {keyword} in this picture.
Output the spatial coordinates of the bounding box for {keyword}.
Can you specify the bounding box around {keyword} in the image?
Please return the bounding box of the object referred to as "[keyword]".
Find the object "[keyword]" and give me its bounding box coordinates.
A.1.2 目标检测
COCO val [61]。在 COCO 上评估时,我们提示模型使用 COCO 标签空间生成检测结果,事先不指定任何特定类别。对于通过朴素自回归输出格式生成的检测,我们将每个预测解析为对象类别和边界框。在计算 mAP 时,对于每个预测框,我们将其置信度分数设为框面积。由于我们的模型在更高分辨率图像上训练,我们的主要结果通过对每张 COCO 图像的多个放大版本(具体为 1×、2×、3× 和 4×)进行预测并聚合获得。在多个尺度上预测的边界框使用 IoU 阈值为 0.7 的非极大值抑制(NMS)进行合并。每张图像的具体提示如下:
<image>
Question:
Detect all objects in the provided image.
Answer: <ref>spoon</ref><box><x_87><y_103><x_929><y_934></box><ref>bowl</ref>
<box><x_85><y_1409><x_887><y_2094></box><box><x_84><y_97><x_2073><y_1466></box>
...<ref>dining table</ref><box><x_89><y_105><x_2069><y_2082></box>
开放世界目标检测。目标检测与视觉定位的区别在于:定位支持单个对象的定位,而检测支持单个类别的多个对象以及多个类别的多个对象。我们对给定类别执行检测,包括图像中可能存在或不存在的单个/多个类别的组合。{keyword} 是一系列类别,例如 “dog” 或 “dog, cat, person, tree”。具体提示如下,我们也支持其中文版本:
Please detect {keyword} in the image.
Please detect "{keyword}" in the image.
Please detect: {keyword}
Detect and highlight {keyword} in the picture.
Can you detect {keyword} in this image?
Can you detect "{keyword}"?
Detect objects from: {keyword}.
Detect all {keyword} visible in the photo.
Detect all "{keyword}" in the photo.
Detect all objects in these classes: {keyword}
Perform detection for "{keyword}"
Run object detection for {keyword} in this picture.
Apply detection: {keyword}.
Use image detection to locate {keyword}.
Carry out detection for all {keyword}.
Carry out detection for "{keyword}"
Perform detection for "{keyword}"
Apply detection: {keyword}.
Run detection for any {keyword} visible.
Execute detection for classes: {keyword}.
Detect {keyword} in this image.
Please perform detection on {keyword} shown.
Run detection algorithms to find {keyword}.
Detect any visible {keyword} in this photo.
Detect the presence of {keyword} in the image.
Find and detect {keyword} within the picture.
Detect all objects labeled as {keyword}.
Perform a detailed detection for {keyword}.
Detect {keyword} and outline them in the image.
Locate and detect "{keyword}" precisely.
Run a detection pass for {keyword} here.
若未输入类别关键词,我们也支持检测图像中的主要类别。此方法在某种程度上可称为"检测一切"。然而,可能存在遗漏不太显著类别的问题。我们将继续优化此能力以增强开放世界场景中的泛化能力。具体提示包括但不限于:
Detect all object categories present in this picture.
Run object detection and output all found objects.
Detect objects across the entire image area.
Please detect every object and report the results.
Run a full object detection to capture all items.
Detect all objects in the frame and list them.
Apply object detection and return all object labels.
Detect and annotate all objects you can see.
Identify all objects present and provide detection data.
Run object detection to find every object in view.
Detect all objects in the picture and summarize them.
Perform object detection over the entire image.
Identify all items in this image using object detection.
Detect all visible objects and provide their labels.
Run object detection to detect all objects shown.
Detect all objects within this image and list categories.
Please perform object detection and list all findings.
Detect all objects in this image without specifying extra constraints.
Detect all.
Detect it.
Detect all objects.
Run object detection.
Return all object categories found.
Detect all objects with locations.
Detect objects.
Show all detected objects.
Run object detection.
Return all detections.
Enumerate all objects detected.
Detect all object categories present.
Output all detected objects.
Perform detection.
Detect all objects shown.
A.1.3 图像分类
ImageNet-ReaL [68]。在评估过程中,我们指示模型输出描述图像中主要对象类别的单个单词或短语。如果预测与真实标签匹配,则计为正确。具体提示如下:
<image>
Question:
What is the category of the primary object in this image? Answer the question with a single word or phrase.
Answer: puck
A.1.4 目标计数
TallyQA [70] & CountBench [69]。对于计数评估,我们要求模型输出与查询对象数量对应的单一数值。仅当该数字与真实计数完全匹配时,预测才被视为正确。在评估时,输入图像被放大 2 倍或 2.5 倍。具体提示如下:
<image>
Question:
How many aum symbols are there in the image? Output the final answer as a single number.
Answer: 9
A.1.5 语义分割
ADE20K [63]。在 ADE20K 数据集(测试集)的测试中,我们采用开放词汇方法。提示采用格式"Segment: class1, class2, class3,…",其中类别名称均为表示各类别的小写英文术语。为协助模型单独查询每个类别而不拟合特定指令,我们为每张图像随机打乱类别名称顺序。考虑到 token 合并后 patch 尺寸经历显著下采样(降至 32),且考虑到此基准测试中图像的小分辨率,我们测试时将每张图像放大至原始分辨率的四倍。检测到的类别结果格式化为 <ref>class1</ref> <ref>class2</ref> <ref>class3</ref>,便于解析。像素级输出在末尾列为 <mask>RLE string</mask>,编号对应类别名称出现的顺序。“RLE string” 表示通过游程编码压缩的像素标签。1D 掩码字符串的长度与像素数量相同。用户需将其重塑为 2D 原始图像尺寸以供进一步使用。对于无背景评估,对 logits 应用温度为 0.2 的 softmax 和 DenseCRF [17] 以细化像素级预测。此操作应用于评估期间所有与语义分割相关的任务,在实际应用中为可选项。具体示例如下:
<image>
Question:
Segment: tree, towel, tank, armchair, refrigerator, countertop, blanket, railing, hood, bathtub, radiator, chandelier, canopy, arcade machine, trade name, case, wardrobe, oven, sidewalk, toilet, chair, wall, door, land, fireplace, windowpane, plant, waterfall, swimming pool, computer, animal, apparel, bannister, poster, flag, step, chest of drawers, box, book, light, tower, ceiling, bulletin board, palm, bicycle, barrel, earth, buffet, person, bus, stairs, stove, stool, basket, washer, rug, monitor, stairway, cushion, pot, minibike, awning, desk, grass, clock, runway, sea, bookcase, sky, food, hovel, seat, van, road, fountain, streetlight, coffee table, painting, ball, car, bed, cradle, airplane, kitchen island, house, ottoman, column, rock, blind, sconce, fan, escalator, lake, boat, booth, stage, sofa, base, swivel chair, mirror, pole, shower, conveyer belt, table, bench, tray, glass, lamp, dishwasher, crt screen, plaything, pool table, water, screen door, truck, bridge, pillow, building, ship, signboard, traffic light, microwave, screen, path, vase, mountain, pier, field, bottle, sculpture, floor, hill, river, sand, flower, sink, grandstand, shelf, dirt track, ashcan, skyscraper, counter, cabinet, television receiver, fence, bar, plate, tent, curtain, bag, without the background class.
Answer:
The target categories include <ref>tree</ref> <ref>sidewalk</ref> <ref>...</ref> <ref>pot</ref> <ref>signboard</ref>, numbered sequentially starting from 0, without the background class.<mask>RLE string</mask>
注意:我们使用"开放世界语义分割"中随机采样的提示评估 ADE20k 以展示提示灵活性,而其他基准测试为简化起见使用固定提示。
Cityscapes [106]。Cityscapes(验证集)的评估与 ADE20K 的输出格式一致;输入提示的唯一区别在于类别名称(同样打乱顺序)。区别在于分辨率乘以 2 而非 4。为减少计算量,我们对图像进行 2×2 非重叠裁剪进行测试。具体提示如下:
<image>
Question:
Segment: train, motorcycle, vegetation, person, wall, terrain, pole, sky, traffic
light, fence, bicycle, road, traffic sign, rider, building, truck, sidewalk, bus, car,
without the background class.
Answer:
The target categories include <ref>road</ref><ref>sidewalk</ref><ref>car</ref>, numbered
sequentially starting from 0.<mask>RLE string</mask>
Context59 [107]。Pascal context(验证集)基准测试遵循上述提示和输出协议,输入分辨率放大至原始大小的 $ 3 \times $。Context59 包含 59 个前景类别,不包括背景类别。为适应需要背景识别的场景,模型支持可选配置:从提示中省略短语"without the background class"。在此模式下,背景通道(由 $ \langle\mathrm{OTHERS}\rangle $ 表示)被集成到后处理流程中:logits 在 sigmoid 激活前缩放 0.25 倍,随后添加常量背景分数(0.5)以促进 argmax 操作。然而,对于 Context59 的标准评估,我们遵循默认的 softmax 细化(温度 0.2)和 DenseCRF,与其他语义分割任务的协议一致。代表性提示如下所示:
<image>
Question:
Segment: window, ceiling, dog, person, ground, keyboard, cloth, bus, bag, boat, sheep, wall, bicycle, snow, platform, grass, flower, computer, floor, truck, bottle, light, car, curtain, sign, bird, pottedplant, tree, cat, table, door, bed, food, train, sidewalk, bench, bedclothes, sofa, mountain, rock, water, building, aeroplane, plate, track, cabinet, horse, chair, cup, fence, road, tvmonitor, motorbike, sky, book, mouse, cow, wood, shelves, without the background class.
Answer:
The target categories include <ref>ground</ref><ref>grass</ref>...
<ref>rock</ref><ref>water</ref><ref>sky</ref>, numbered sequentially starting from 0.<mask>RLE string</mask>
VOC20。VOC20(即 PASCAL VOC)包含 20 个前景类别,无背景类别。测试分辨率倍数、提示格式和输出格式与 Context59 一致。具体示例如下:
<image>
Question:
Segment: train, sofa, sheep, horse, bird, cat, car, cow, boat, aeroplane, diningtable,
pottedplant, chair, dog, bottle, person, motorbike, bicycle, tvmonitor, bus, without the
background class.
Answer:
The target categories include <ref>car</ref><ref>boat</ref><ref>person</ref>
<ref>bus</ref>, numbered sequentially starting from 0.<mask>RLE string</mask>
COCOStuff [64]。COCOStuff 使用与 ADE20K 相同的测试协议,区别仅在于调整比例为 3。其余提示格式(包括标签打乱)和输出格式保持一致。具体示例如下:
<image>
Question:
Segment: wall-tile, ground-other, surfboard, moss, fire hydrant, towel, backpack, couch, floor-wood, mirror-stuff, rock, handbag, door-stuff, paper, salad, gravel, door, plant-other, hill, snowboard, eye glasses, snow, person, tennis racket, wall-concrete, playingfield, plastic, wall-wood, bird, banana, carrot, bed, sandwich, furniture-other, knife, rug, plate, vase, elephant, clouds, kite, tv, cell phone, fork, apple, straw, stone, frisbee, suitcase, fence, cake, clock, train, grass, wood, donut, curtain, cow, cloth, floor-other, toaster, tree, giraffe, sports ball, shelf, flower, building-other, potted plant, carpet, fruit, window-blind, spoon, railroad, pillow, traffic light, bush, desk-stuff, sheep, bear, railing, bottle, hat, blender, baseball glove, sea, sky-other, hair drier, microwave, parking meter, zebra, tent, mouse, skis, counter, desk, banner, tie, oven, branch, scissors, structural-other, dirt, keyboard, fog, cupboard, wall-panel, wall-brick, floor-stone, food-other, wall-other, dining table, napkin, stop sign, cat, net, mirror, leaves, bus, house, bowl, mud, stairs, truck, laptop, table, textile-other, clothes, sand, window, vegetable, pizza, floor-tile, wine, glass, waterdrops, river, road, floor-marble, cardboard, refrigerator, window-other, wall-stone, platform, cup, mountain, street sign, shoe, umbrella, car, book, chair, skyscraper, cabinet, skateboard, ceiling-other, blanket, toothbrush, bench, orange, light, hot dog, bridge, pavement, bicycle, solid-other, ceiling-tile, teddy bear, water-other, motorcycle, broccoli, horse, cage, mat, baseball bat, dog, roof, boat, metal, sink, hair brush, remote, toilet, airplane, without the background class.
Answer:
The target categories include <ref>rock</ref><ref>plant-other</ref>
<ref>bird</ref><ref>grass</ref><ref>bush</ref><ref>bear</ref><ref>dirt</ref>
<ref>water-other</ref>, numbered sequentially starting from 0.<mask>RLE string</mask>
开放世界语义分割。开放集分割与特定基准测试在输出内容和解释结果方面存在差异。开放集支持单个对象、多个对象和标签集合。若无背景改进,模型将输出 $ \langle\mathrm{OTHERS}\rangle $ 标签,激活 sigmoid + 阈值解释方法。具体而言,logits 除以 4 后通过 sigmoid,背景类别阈值默认为 0.5。开放集的对应准确率通常不高,固定阈值有时会导致背景类别不准确。我们可以通过检测后分割类型实现更精确的开放集分割结果。具体方法是先调用检测,然后在图像上绘制每个框,应用 1.2 的填充,调整大小,然后分割前景和背景。相比之下,直接输出语义分割结果更快但质量相对较低,尽管它可以额外支持 stuff 类别。直接语义分割的具体提示如下(也支持中文版本):
Please perform segmentation for the following classes: {keyword}.
Can you identify and segment these objects: {keyword}?
I'm looking for {keyword}. Please segment them in the image.
Segment the image based on these keywords: {keyword}.
Mark the regions corresponding to: {keyword} in the image.
Identify the boundaries of these objects: {keyword}.
Please label and segment the following categories: {keyword}.
Show me the segmentation mask for: {keyword}.
Create segmentation maps for these items: {keyword}.
Locate and segment the following objects: {keyword}.
Segment the image to highlight: {keyword}.
Distinguish and segment these classes: {keyword}.
Please provide segmentation for objects: {keyword}.
Identify and separate the following elements: {keyword}.
Generate segmentation for the specified classes: {keyword}.
Semantic segmentation for {keyword}.
Perform semantic segmentation for {keyword}.
Run semantic segmentation: {keyword}.
Segment: {keyword}.
Semantic segmentation: {keyword}.
Find {keyword} and segment.
Segment these: {keyword}.
Segment {keyword}.
Segment {keyword}.
Segment and label {keyword}.
Please segment {keyword}.
Could you please segment objects classified as: {keyword}?
Provide a detailed segmentation of the following: {keyword}.
Perform pixel-level segmentation for: {keyword}.
Mark and segment the specified classes: {keyword}.
Generate a segmented output focusing on: {keyword}.
Show segmentation results highlighting: {keyword}.
Can you segment and annotate the following keywords: {keyword}?
Provide segmentation masks specifically for: {keyword}.
Please segment any visible {keyword} in the image.
Produce a segmentation mask isolating {keyword}.
Segment and highlight the regions occupied by {keyword}.
Perform semantic segmentation targeting: {keyword}.
Segment and classify the following entities: {keyword}.
Mark the presence and segment the {keyword} in the image.
Generate masks that segment the {keyword} clearly.
Create a detailed segmentation for the objects: {keyword}.
Generate segmentation annotations for: {keyword}.
Provide a detailed semantic segmentation of the following categories: {keyword}.
Perform pixel-level semantic segmentation for: {keyword}.
Create precise semantic segmentation boundaries around these classes: {keyword}.
Generate a semantic segmentation output focusing on: {keyword}.
Segment {keyword} in the image.
Show semantic segmentation for {keyword}.
Find and segment {keyword}.
Please segment {keyword}.
Segment {keyword} categories.
Show {keyword} segmentation.
Classify and segment {keyword}.
Generate segmentation annotations for: {keyword}.
{keyword} indicates some category names such as "dog, cat, tree, soft". We also support "segment anything" type without specific keyword assignment. It is important to note that this model does not necessarily segment all elements in detail, but rather segments some significant main objects. Since background classes will also be output, sigmoid processing will be applied, with a background threshold of 0.5. The combined version of detection and semantic segmentation can address issues with inaccurate backgrounds. Suggested prompts include:
Please segment all objects present in the image.
I want to segment everything in the image.
Segment every object visible in the photo.
Segment all objects in this image.
Segment all visible elements in the photo.
Segment all objects in the image.
Identify and segment all items.
Segment everything visible.
Find and segment all objects.
Label all objects in the image.
Segment all elements.
Perform semantic segmentation for this image.
Do semantic segmentation for this image.
Segment all.
Conduct semantic segmentation for all.
Perform semantic segmentation for this image.
Do semantic segmentation for this image.
Segment all.
Segment this image.
Segment it.
Segment everything.
Segment all
Semantic segmentation for all.
Semantic segmentation.
Run semantic segmentation
Segment this image
Conduct semantic segmentation for all.
Apply semantic segmentation to the image.
Run semantic segmentation on this image.
Execute semantic segmentation for all objects.
Carry out semantic segmentation for everything.
Perform full semantic segmentation.
Complete semantic segmentation for all items.
A.1.6 指代表达分割
RefCOCO 系列 [59](多边形)。指代表达分割的基础版本使用多边形实现。此模式为简单版本,但未进行评估。
<image>
Question:
Can you segment 'bowl behind the others can only see par' in this image?
Answer:
The segmentation result is <ins><poly><x_468><y_3><x_471><y_46><x_473><y_83><x_521>
<y_107><x_581><y_117><x_640><y_106><x_640><y_105><x_640><y_1></poly></ins>.
这是基础指代表达分割提示。注意 <ins> 表示一个对象,一个对象可能有多个 <poly>,表示不同部分。
RefCOCO 系列 [59](定位后分割)。由于点数精度限制,我们推荐先使用定位再进行语义分割。具体而言,在定位输出原始图像上的边界框后,我们在图像上以随机颜色绘制框,并使用 1.2 的填充比例(额外 0.2)裁剪图像。然后将短边调整为 1280 进行语义分割以区分前景和背景类别(支持较低分辨率以加速)。与语义分割类似,DenseCRF 也用作后处理步骤(多边形不使用)。输出中的"RLE string"表示通过游程编码压缩的像素标签字符串格式。评估指标为 cIoU。基于多边形和语义分割的示例如下所示:
在测试中,我们实际使用定位提示,然后在图像上绘制框并进行 1.2 填充裁剪。将短边设置为 1280 后,执行以下语义分割命令,然后将分割结果填充回原始图像进行测试。
<image>
Question:
Can you segment "Segment the code" in this image?
Answer:
The segmentation result is <ins><poly><x_468><y_3><x_471><y_46><x_473><y_83><x_521>
<y_107><x_581><y_117><x_640><y_106><x_640><y_105><x_640><y_1></poly></ins>.
这是基础指代表达分割提示。注意 <ins> 表示一个对象,一个对象可能有多个 <poly>,表示不同部分。
<image>
Question:
Please provide the bounding box coordinate of the region this sentence describes: the person bottom left
Answer: <box><x_155><y_154><x_221><y_206></box>
<image>
Question:
Please provide the bounding box coordinate of the region this sentence describes: bowl behind the others can only see part Answer:
<box><x_54><y_0><x_361><y_141></box>
<cropped image> #Draw the box, padding, and resize.
Question:
Segment the core target.
Answer:
The results are 0 for <ref><BG></ref> and 1 for <ref><FG></ref>.<mask>RLE string</mask>
开放世界指代表达分割。指代表达分割和点是此任务的关键词,将激活模型为单个目标输出多边形分割结果。基于定位 + 语义分割的方法可参考定位的灵活提示。
Can you segment "{keyword}" via points?
Can you segment "{keyword}" in the manner of referring segmentation?
Referring segment for "{keyword}".
Referring segment for {keyword}.
Referring expression segmentation for {keyword}.' Can you segment {keyword} via points?
Can you segment {keyword} in the manner of referring segmentation?
Outline {keyword} via points.
Outline {keyword} via the polygon or points.
Segment {keyword} via points.
Outline "{keyword}" via points.
Use points to segment {keyword}.
Use points to segment "{keyword}".
Use point to segment {keyword}.
Use point to segment "{keyword}".
Please {keyword}.
Use points to segment "{keyword}".
Outline "{keyword}" via the polygon or points.
Segment "{keyword}" via points.
Perform referring segmentation for the keywords: {keyword}.
Perform referring segmentation for "{keyword}".
Please segment "{keyword}" in the image using polygon or points.
Could you outline "{keyword}" with points?
Draw the boundary of "{keyword}" via points.
Generate a referring segmentation mask for "{keyword}".
Segment {keyword} based on referring expression.
Segment "{keyword}" using points outlining.
Please perform referring expression segmentation for {keyword}.
Use polygon or points to segment "{keyword}".
Draw a polygon or points to segment "{keyword}" in the image.
Referring segmentation for the object "{keyword}".
Segment {keyword} in this picture by outlining with polygon or points.
Please extract the polygon or pointsal region corresponding to "{keyword}"
A.1.7 深度估计
NYUv2 [65]。深度估计测试有四个关键点:(1) 类别 ID 预设为 <custom_1> 到 <custom_1000>,无需预测类别名称,提高速度。(2) 不使用 DenseCRF,而是先放大两倍,然后进行 argmax,再调整回原始图像大小。argmax 前的适当调整可改善结果。(3) 真实深度需要反量化。对于 NYUv2,我们使用均匀线性量化,将 0 到 10 米的真实深度映射到 1 到 1000。无效深度设为 0 并在训练期间忽略。测试时,我们反量化为实际深度并排除无效深度。(4) 提示必须位于图像之前,以便模型学习潜在量化方法。输出格式为 argmax 和调整大小后对应像素大小的深度名称字符串。对于 NYUv2,由于图像相对较小,我们基于原始分辨率进行了三倍调整。示例如下:
Question:
Please estimate the depth of this image from the NYUv2 dataset.
<image>
Answer:
This is the <depth>.<mask>RLE string</mask>
Cityscapes [106]。Cityscapes 的测试标准与 NYUv2 相同。区别在于将 0-80 米的有效深度量化为 1-1000,且由于分辨率足够,未进行调整大小。此外,我们按照先前工作设置左右和底部对的无效区域。具体示例如下:
Question:
Please estimate the depth of this image from the Cityscapes dataset.
<image>
Answer:
This is the <depth>.<mask>RLE string</mask>
DDAD [66]。DDAD 的测试标准与 NYUv2 相同。区别在于将 0.05-120 米的有效深度量化为 1-1000,且由于分辨率足够,未进行调整大小。具体示例如下:
Question:
Please estimate the depth of this image from the DDAD dataset.
<image>
Answer:
This is the <depth>.<mask>RLE string</mask>
开放世界深度估计。开放世界场景中的深度估计默认使用对数均匀量化,将 0.5 到 100 米的真实深度映射到 1 到 1000。此范围外的值设为 0(IGNORE)。测试时,预测值需要反量化以获得真实深度;否则仅获得相对深度。此外,我们要求输入调整为 2000 像素的焦距以模拟默认焦距的相机。实际焦距的差异可能导致预测深度偏差,产生相对深度输出。与需要提前放置提示的特定数据集不同,我们的开放集支持图像前后放置提示。需要注意的是,此任务依赖大量训练数据,"任意深度"能力仍需改进。然而,我们已证明标准 VLM 模型可容纳几种不同的量化方法,内在构建空间深度感知而无需额外结构。我们推荐使用以下提示及其中文翻译版本:
Estimate the depth.
Estimate the depth in the default range.
Predict the depth map.
Estimate the depth map.
What the depth map?
Execute depth estimation.
Run depth estimation.
Generate a depth map.
Calculate the depth.
Provide depth estimation.
Perform depth prediction.
Create the depth map.
Get the depth map for the image.
Compute the depth information.
Estimate distance using depth.
Run a depth map generation.
Can you predict the depth map?
Show me the depth estimation.
Depth map prediction, please.
Extract depth from the image.
Apply depth estimation.
A.1.8 人体姿态估计
MPII [67]。我们在 MPII 验证集上使用标准 PCKh@0.5 指标评估模型。遵循 ViTPose [53] 的评估设置(在真实人物边界框裁剪的图像上报告结果),输入图像由真实边界框裁剪构建。由于我们的模型在单次前向传递中预测图像中多个人的姿态,我们采用后处理策略以实现一对一评估。具体而言,对于每张图像,我们计算真实实例的关键点中心,并选择关键点中心在空间上最接近它的预测姿态,丢弃所有其他预测。然后使用标准 PCKh 指标将所选预测与对应的真实姿态进行评估。
<image>
Question: Detect all persons and their poses from the image within the class set of MPII Human Pose Dataset. The output format should be a JSON-like string, containing person instances. Each person instance is enclosed in <person>...</person> tags. Within each person instance, provide the bounding box using <box>...</box> tags and their 16 keypoints using <kpt>...</kpt> tags. The bounding box is defined by <x_x1><y_y1><x_x2><y_y2> tags, and each keypoint is defined by <x_...><y_...><v_...> tags, where x, y are coordinates and v is visibility. The joints must follow the standard MPII ordering.
Answer: <person><box><x_457><y_187><x_548><y_315></box> <kpt><x_531><y_793><v_1.0></kpt>
<kpt><x_624><y_659><v_1.0></kpt>...<kpt><x_602><y_281><v_1.0></kpt> </person>
注:在结构化输出中,每个坐标和可见性值(例如 <x_*><y_*><v_*>)表示为专用特殊 token,并在训练期间直接学习。为简洁起见,上述示例仅显示部分关键点;实践中,模型按照 MPII 关节顺序预测每个检测人物的完整 16 个关键点集。
A.2 通用多模态基准测试
我们提供主文中报告的通用多模态基准测试的详细评估设置和提示。所有评估均使用基于 VLMEvalKit [34] 增强的 VLM 评估框架进行。具体而言,我们增强框架以解决原始精确匹配协议在某些多项选择题(MCQ)基准测试中的局限性。为提高评估准确性,我们集成了基于 LLM 的评判机制,利用大语言模型稳健地从模型生成的响应中提取和解析最终答案。
实现细节。为确保跨不同任务的最佳性能,我们根据基准测试要求定制视觉分辨率设置。对于大多数需要细粒度视觉细节的基准测试(例如 DocVQA [95]、MMMU [82]、MMBench [108]、RealWorldQA [100]),我们采用动态高分辨率策略。具体而言,我们将最小 patch 数量设置为 1,280(默认为 64),最大为 65,536 个 patch。对于对极端分辨率不太敏感或标准分辨率足够的基准测试(例如 MathVista [85]、OCRBench [109]、ScienceQA [75]、HallusionBench [88]),我们保留默认设置(min_num_patches=64)。
关于评估协议,特别是对于 MCQ 基准测试,我们采用混合评判策略以确保准确性。我们首先尝试使用精确匹配提取答案。如果提取失败或模型输出模糊,我们利用基于 LLM 的评判器解析响应。
提示细节。关于提示策略,我们根据任务性质对基准测试进行分类。对于需要复杂推理的基准测试(例如 MathVerse [86]、MMMU、VisuLogic [81])或真实世界分析(例如 RealWorldQA),我们选择性激活思维链(CoT)提示(例如"逐步思考")。对于幻觉和 OCR 任务,我们采用严格约束以确保输出简洁精确。详细配置如下。
VisuLogic [81]。对于此专注于复杂视觉逻辑推理的基准测试,我们使用专门提示,明确指示模型在提供最终答案前逐步推理。
<image>
{Question}
Solve the complex visual logical reasoning problem through step-by-step reasoning.Think about the reasoning process first and answer the question following this format:
Answer: \boxed{LETTER}
Think step-by-step.
MathVerse & MathVista & LogicVista [86, 85, 87]。为处理这些基准测试中的复杂推理,我们结合 CoT 策略以引出结构化的几何和数学推导。
<image>
{Question}
Think step-by-step.
MMMU(VAL & Pro_Standard)[83, 110]。对于大规模多学科理解基准测试,我们在选项后附加标准 CoT 指令以鼓励详细推理。
<image>
Hint: {Hint}
Question: {Question}
Options:
A. {OptionA}
B. {OptionB}
...
Please select the correct answer from the options above.
Think step-by-step.
MMMU(Pro_V)[83]。MMMU-Pro 的纯视觉协议。在此配置中,冗余文本提示被移除并替换为 CoT 指令以引出深度优先的视觉分析和逻辑推导。
<image>
Think step-by-step.
RealWorldQA [100]。尽管这是 VQA 任务,但我们发现空间和物理理解从推理中显著受益。因此,我们强制"逐步思考"指令。
<image>
{Question}
Think step-by-step.
MMBench & CV-Bench [71, 74]。对于通用感知和推理,我们使用 VLMEvalKit 提供的标准 CircularEval 策略,辅以逐步思考指令。
<image>
Hint: {Hint}
Question: {Question}
Options:
A. {OptionA}
...
Please select the correct answer from the options above.
Think step-by-step.
MME-RealWorld [101]。对于此基准测试,我们使用详细系统提示指导模型选择最佳选项,以特定后缀结束以诱导答案生成。
<image>
{Question}
{Options}
Select the best answer to the above multiple-choice question based on the image.
Respond with the letter (A, B, C, D, or E) of the correct option.
The best answer is:
HallusionBench & POPE [88, 89]。为严格测试幻觉,我们禁用 CoT 并强制"是/否"约束以防止模型生成回避性或冗长响应。
<image>
{Question} Please answer yes or no.
DocVQA、InfoVQA、TextVQA、ChartQA & AI2D [95, 93, 94, 96]。对于文档理解和 OCR 相关任务,我们附加约束以确保输出为短语或单个单词,便于准确指标计算。
<image>
{Question} Answer the question with a single word or phrase.
ScienceQA & SEEDBench [75, 76]。对于这些通用多项选择基准测试,我们使用直接答案提示而不使用 CoT 以评估模型的直接知识检索能力。
<image>
Hint: {Hint}
Question: {Question}
Choices:
A. {OptionA}
...
Answer the question with a single word or phrase.
OSWorld [25]。对于 OSWorld 基准测试,我们使用以下提示评估候选模型。
(系统提示和工具定义部分因篇幅限制略去,包含 computer_use 工具的完整 JSON Schema 定义,支持鼠标移动、点击、键盘输入、等待和任务终止等操作)
ScreenSpot Pro [102]。对于 ScreenSpot Pro 基准测试,我们使用以下提示评估候选模型。
(系统提示和工具定义部分因篇幅限制略去,仅支持 mouse_move 和 left_click 两种操作,要求输出精确坐标)
B 扩展实验与比较
视觉中心任务涵盖各种设置,全面比较具有挑战性。为实现表 2 之外的彻底评估,我们提供两个额外的补充表格——表 4 和表 5,分别专注于分割和定位。在这些表格中,我们系统地与五种代表性设置进行比较:(1) 视觉专家模型,(2) 基于 CLIP 的视觉-语言模型,(3) 视觉通用架构,(4) 具有任务特定添加的多模态 LLM,(5) 我们的标准多模态 LLM(不使用额外模块、头或任务嵌入)。我们的结果表明,尽管架构简单,我们的方法在不同设置下均实现具有竞争力或最先进的性能。这证明标准 MLLM 在配备适当监督和训练时,可作为高效通用预测器,结合强大性能、最小设计和广泛适用性。
B.1 与密集预测方法的比较
表 4 中的结果展示了我们提出的 Youtu-VL 在多个密集预测基准测试上的卓越性能,突显其作为稳健视觉-语言通用模型的能力,无需复杂架构添加。
在语义分割任务中,Youtu-VL 在所有五个数据集上均取得显著结果。值得注意的是,它在 ADE20K 上达到 54.2 mIoU,而视觉通用模型如 GiT [62] 为 47.8 mIoU,基于 CLIP 的方法如 SAN [47] 为 32.1 mIoU。关键的是,与通常无法执行这些任务的标准多模态 LLM(标记为"×")不同,Youtu-VL 展示了直接处理细粒度密集预测的独特能力。
在深度估计任务中,Youtu-VL 展示具有竞争力的结果。它在 NYUv2 上达到 90.4,而 DepthLLM [49] 的结果为 87.6。我们的方法仅需处理图像一次,而 DepthLLM 需要绘制每个点并多次推理。我们还像视觉专家模型 SwinMTL [51] 一样对模型进行微调,在 NYUv2 上达到 92.7 $ \delta_{1} $(SwinMTL 为 92.1)。虽然专家模型 UniDepthv2 [50] 在 NYUv2 上表现更高,但在 DDAD 上的性能非常接近(88.2 对 87.6),表明此通用模型有时能达到任务特定模型的高性能。
Youtu-VL 在指代表达分割任务中展示强大性能。在 RefCOCO val 上,Youtu-VL 达到 80.7 cIoU,而基线结果为 GLaMM [12] 的 79.5 和需要额外 SAM 解码器的 UniPixel [14] 的 80.5。此外,基于多边形预测的方法仅为 74.5。UFO [15] 达到 80.0 cIoU(Youtu-VL 为 80.7),但该方法需要额外的掩码 token 嵌入进行检索过程。与上述方法相比,我们的方法简单而高效,专为标准 VLM 设计,无需额外架构修改。
B.2 定位任务比较
表 5 中的结果表明,Youtu-VL 在定位任务上实现卓越性能,无需复杂架构添加。此成功归因于检测、计数和定位能力之间的协同作用,在标准 VLM 框架内建立领先性能。
在目标检测中,Youtu-VL 在 COCO 验证集上达到 47.1 mAP,凸显标准 VLM 处理密集定位任务的潜力。此外,从第 3 阶段开始仅在检测数据上进行 SFT 可将性能提升至 48.0 mAP,有效弥合与专业架构的差距。在视觉定位方面,Youtu-VL 在 RefCOCO 系列的所有拆分上均获得领先结果。同样,在计数任务中,模型在 CountBench、TallyQA-simple 和 TallyQA-complex 等基准测试上展示卓越性能。
C 案例研究



- 图 14:Objects365 数据集上的开放世界检测定性示例,展示"先检测后计数"方法

- 图 15:作者拍摄照片上的"先检测后计数"定性示例,草莓计数结果为 25


-
图 16-17:ADE20k 数据集上的语义分割定性示例

-
图 18-19:RefCOCO 数据集上的视觉定位定性示例

-
图 20:RefCOCO 数据集上的指代表达分割定性示例


- 图 21-22:NYUv2 数据集上的深度估计定性示例

- 图 23:MPII 人体姿态估计定性示例,展示多人姿态关键点检测






魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

所有评论(0)