ODTrack:用于视觉跟踪的在线密集时间令牌学习
本文提出了一种新颖的视觉跟踪方法ODTrack,通过在线密集时间令牌学习实现高效视频级跟踪。不同于传统基于稀疏图像对匹配的跟踪方法,ODTrack将目标跟踪重新定义为令牌序列传播任务,利用视频流建模来捕捉目标的时空轨迹关系。该方法通过两种时间令牌传播注意力机制,将目标的判别性特征压缩为令牌序列,作为未来帧推理的提示,从而避免了复杂的在线更新策略。实验表明,ODTrack在七个主流跟踪基准上达到了S
ODTrack:用于视觉跟踪的在线密集时间令牌学习
ODTrack: Online Dense Temporal Token Learning for Visual Tracking
作者: Yaozong Zheng, Bineng Zhong, Qihua Liang, Zhiyi Mo, Shengping Zhang, Xianxian Li
发表期刊: AAAI2024
论文地址: http://arxiv.org/abs/2401.01686
摘要
连续视频帧之间的在线上下文推理与关联对于视觉跟踪中的实例感知至关重要。然而,目前大多数性能领先的跟踪器仍坚持通过离线模式,依赖于参考帧与搜索帧之间稀疏的时间关系。因此,它们只能在每个图像对内进行独立交互,并建立有限的时间相关性。为了缓解上述问题,我们提出了一种简单、灵活且有效的视频级跟踪流水线,命名为 ODTrack。它通过在线令牌传播的方式,密集地关联视频帧的上下文关系。ODTrack 接收任意长度的视频帧以捕捉实例的时空轨迹关系,并将目标的判别性特征(定位信息)压缩进一个令牌序列中,从而实现帧与帧之间的关联。这一新方案带来了以下优势:1) 提纯后的令牌序列可以作为下一视频帧推理的提示,从而利用过去的信息来引导未来的推理;2) 通过令牌序列的迭代传播,有效地避免了复杂的在线更新策略,从而使我们能够实现更高效的模型表示和计算。ODTrack 在七个基准测试中达到了新的 SOTA 性能,同时保持实时运行速度。代码和模型已在 https://github.com/GXNU-ZhongLab/ODTrack 发布。
引言
视觉跟踪旨在通过使用任意目标查询,在视频序列中唯一地识别并跟踪一个物体。在视觉世界中,物体很少孤立存在,而是处于更大且动态的上下文中。因此,视觉感知是一个复杂的过程,涉及对物体周围环境的解释和理解。在这种情况下,赋予模型进行在线上下文推理和建立关联的能力,是视觉跟踪领域的一项挑战。尽管存在这一挑战,当前大量的跟踪方法仍忽视了这一问题,而是依赖于离线图像对匹配来定位当前帧中的实例。如图 1(a) 所示,这些离线方法(Bertinetto et al. 2016; Li et al. 2019; Chen et al. 2021; Yan et al. 2021a; Ye et al. 2022; Cui et al. 2022)通常遵循一个三阶段过程:(i) 通过对两个视频帧(即参考帧和搜索帧)进行采样来提取特征;(ii) 通过匹配/融合模块将初始目标信息从参考帧传播到搜索帧;(iii) 利用边界框预测头输出定位结果。大多数跟踪器在这种范式下表现良好,但仍存在以下缺陷:(1) 采样帧是稀疏的(即仅使用一个参考帧和一个搜索帧)。虽然视觉跟踪本质上包含丰富的时域数据,但这种简单的采样策略不足以准确表示物体的运动状态,给跟踪器理解动态视频内容带来了重大挑战;(2) 目标信息是离线匹配的且局限于图像对级别,阻碍了视频帧间目标的关联。传统的特征匹配/融合方法(Chen et al. 2020; Zhang et al. 2020; Guo et al. 2021; Xie et al. 2022)侧重于物体的外观相似性,而未考虑跟踪实例依赖于连续跨帧关联的特性。为了将时域信息融入模型,一些方法通常设计在线更新技术,例如更新模板(Yan et al. 2021a; Cui et al. 2022)和更新模型参数(Bhat et al. 2019)。尽管取得了成功,这些方法仍然依赖于稀疏的采样帧(即参考帧、搜索帧和更新帧),并且没有有效探索信息如何在搜索帧之间进行在线传播。这启发我们思考:我们的视觉跟踪算法能否在视频流上下文中密集地关联并感知物体?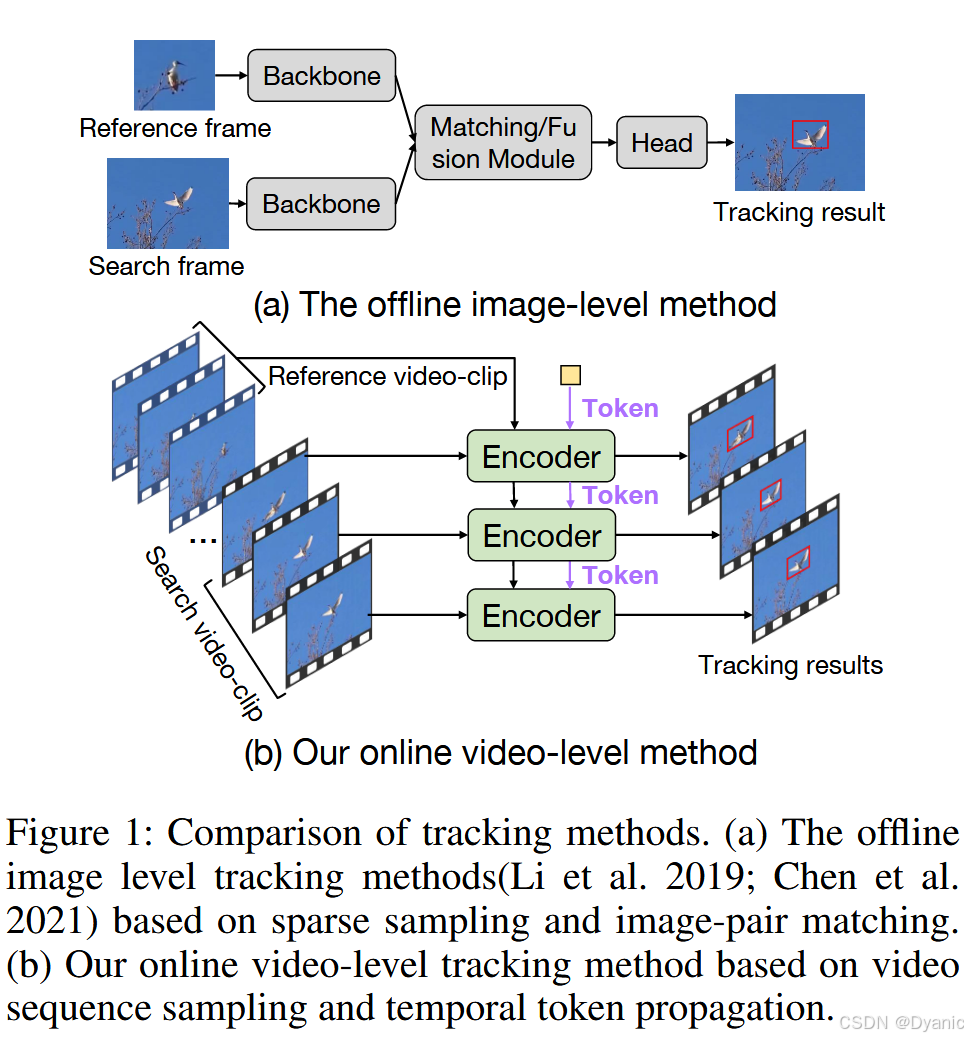
答案是肯定的。与依赖于稀疏采样帧的离线图像对匹配的传统方法不同,本文提出了 ODTrack,这是一种利用视频流建模的新型视频级视觉跟踪框架。具体而言,我们将目标跟踪重新表述为一种令牌序列传播(token sequence propagation)任务,以自回归的方式密集地关联跨视频帧的上下文关系,如图 1(b) 所示。为了克服传统图像对采样策略的局限性并探索丰富的时域依赖关系,我们将模型的输入从图像对扩展到视频流级别。在这种新的输入范式下,我们设计了两种简单而有效的时间令牌传播注意力机制,通过在线令牌传播的方式捕捉目标实例的时空轨迹关系,从而允许处理任意长度的视频级输入。值得注意的是,我们将每个视频序列视为一个连续的句子,使我们能够采用语言建模来实现对视频内容的全面上下文理解。这种新颖的方法使我们的跟踪器与传统方法(Yan et al. 2021a; Ye et al. 2022; Cui et al. 2022)有了显著区别,并大大增强了其理解目标实例时空轨迹的能力。这项工作的主要贡献如下。
- 我们提出了一种名为 ODTrack 的新型视频级跟踪流水线。与现有基于稀疏时域建模的跟踪方法相比,我们采用令牌序列传播范式来密集关联跨视频帧的上下文关系。
- 我们引入了两种时间令牌传播注意力机制,将目标的判别性特征压缩进一个令牌序列中。该令牌序列作为提示(prompt)引导未来帧的推理,从而避免了复杂的在线更新策略。
- 我们的方法在七个视觉跟踪基准测试中取得了新的当前最佳(SOTA)跟踪结果,包括 LaSOT、TrackingNet、GOT10K、LaSOText、VOT2020、TNL2K 和 OTB100。
相关工作
传统跟踪框架。当前主流的跟踪器(Bertinetto et al. 2016; Li et al. 2019; Chen et al. 2021; Ye et al. 2022)由孪生跟踪范式主导,该范式通过图像对匹配实现跟踪。为了提高跟踪器的准确性和鲁棒性,研究者提出了几种不同的方法,例如预测头网络(Li et al. 2018; Chen et al. 2020; Zhang et al. 2020)、互相关模块(Han et al. 2021; Liao et al. 2020; Chen et al. 2021)、强大的骨干网络(Chen et al. 2022; Cui et al. 2022)以及注意力机制(Guo et al. 2021; Yu et al. 2020)。近年来,Transformer(Vaswani et al. 2017)的引入使得跟踪器(Yan et al. 2021a; Xie et al. 2022; Cui et al. 2022; Ye et al. 2022)能够探索更强大且更深层的特征交互,从而在跟踪算法的发展中取得了重大进展。然而,这些方法大多是基于离线模式和稀疏图像对策略设计的。在这种设计范式下,跟踪器难以在时间维度上准确理解物体的运动状态,且只能求助于传统的孪生相似性进行外观建模。与这些方法不同,我们将目标跟踪重新表述为一项令牌序列传播任务,旨在扩展孪生跟踪器,以自回归的方式高效利用目标的时域信息。
视觉跟踪中的时域建模。多目标跟踪算法(Meinhardt et al. 2022; Zeng et al. 2022)通常涉及视频中单个物体的识别和关联,因此研究轨迹信息是一种通用的做法。然而,在单目标跟踪算法中,探索利用时空轨迹信息的研究相对有限。为了在孪生框架内探索时域线索,研究者精心设计了几种在线更新方法。UpdateNet(Zhang et al. 2019)引入了一种自适应更新策略,利用自定义网络融合累积的模板,并为视觉跟踪生成加权的更新模板特征。基于判别相关滤波(DCF)的跟踪器(Danelljan et al. 2019; Bhat et al. 2019; Danelljan, Gool, and Timofte 2020)擅长使用复杂的优化技术在线更新模型参数,从而提高跟踪器的鲁棒性。STMTrack(Fu et al. 2021)和 TrDiMP(Wang et al. 2021a)采用注意力机制,沿时间维度有效提取上下文信息。STARK(Yan et al. 2021a)和 Mixformer(Cui et al. 2022)专门设计了用于更新模板帧的目标质量分支,有助于改善跟踪结果。
最近,从不同角度对时间上下文进行建模的研究正逐渐增多。TCTrack(Cao et al. 2022)引入了一种在线时间自适应卷积和一种自适应时间 Transformer,在包含特征提取和相似度图细化的两个层级上聚合时间上下文。VideoTrack(Xie et al. 2023)设计了一种基于视频 Transformer 的新型跟踪器,并使用简单的前馈网络来编码时间依赖关系。ARTrack(Xing et al. 2023)提出了一种新的时间自回归跟踪器,能够渐进地估计物体的坐标序列。尽管如此,上述跟踪算法仍受以下局限性的困扰:(1) 优化过程复杂,涉及专用损失函数的设计(Bhat et al. 2019)、多阶段训练策略(Yan et al. 2021a)以及人工更新规则(Yan et al. 2021a);(2) 尽管它们在一定程度上探索了时域信息,但未能研究时域线索如何在搜索帧之间传播。在这项工作中,我们从令牌传播的角度引入了一种新的密集上下文传播机制,为规避复杂的优化过程和训练策略提供了一种解决方案。此外,我们提出了一种名为 ODTrack 的新基准方法,专注于通过传播目标的运动/轨迹信息来释放时域建模的潜力。
方法
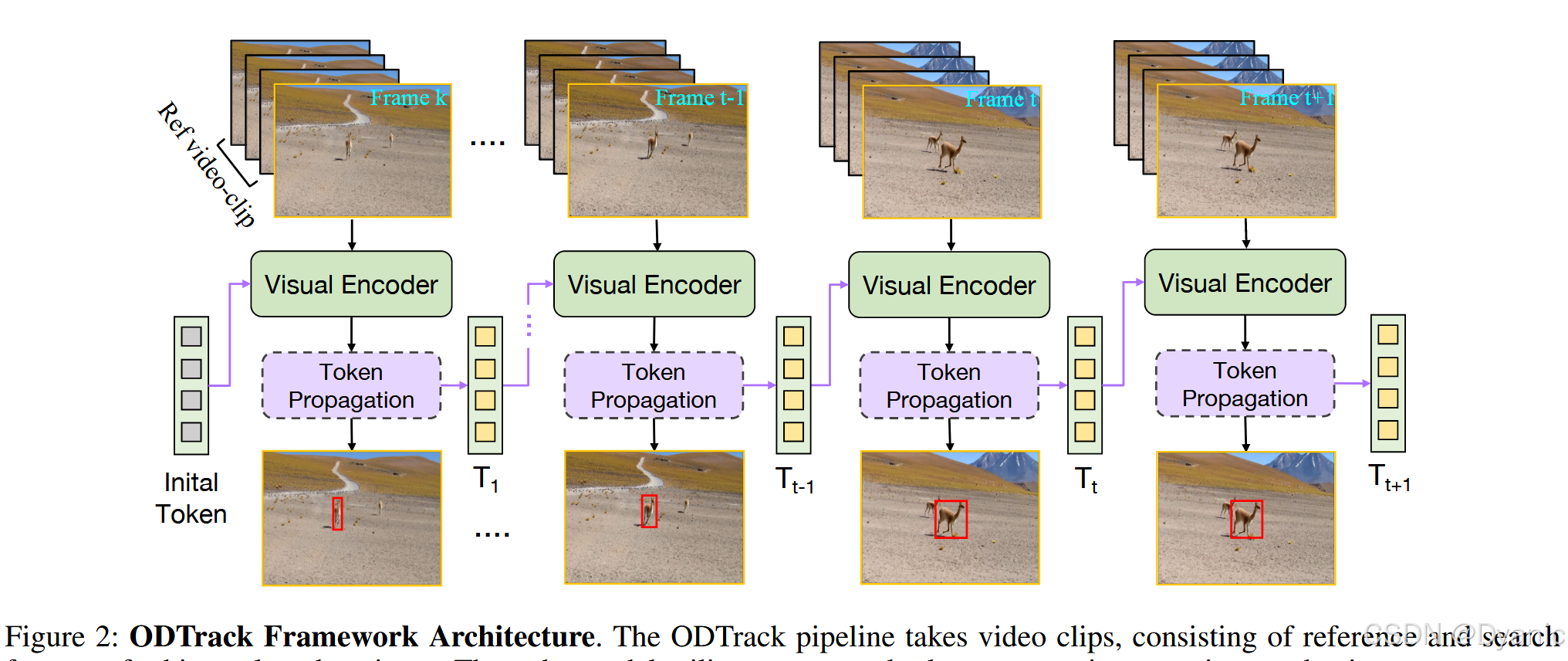
我们介绍了 ODTrack,这是一种新的视频级框架,它采用令牌序列传播进行视觉跟踪,如图 2 所示。本节首先描述视频级视觉目标跟踪的概念,随后介绍时间令牌传播注意力机制,以及它们是如何在新的设计范式下进行训练的。
问题阐述
为了全面理解我们的 ODTrack 框架,有必要首先回顾一下以前主流的图像对匹配跟踪方法(Bertinetto et al. 2016; Chen et al. 2021; Ye et al. 2022)。给定一对视频帧,即一个参考帧 R∈R3×Hr×WrR \in \mathbb{R}^{3 \times H_r \times W_r}R∈R3×Hr×Wr 和一个搜索帧 S∈R3×Hs×WsS \in \mathbb{R}^{3 \times H_s \times W_s}S∈R3×Hs×Ws,主流视觉跟踪器 Ψ\PsiΨ 被公式化为 B←Ψ:{R,S}B \leftarrow \Psi : \{R, S\}B←Ψ:{R,S},其中 BBB 表示当前搜索帧的预测框坐标。如果 Ψ\PsiΨ 是一个传统的卷积孪生跟踪器(Li et al. 2019; Chen et al. 2020, 2021),它经历三个阶段,即特征提取、特征融合和边界框预测。而如果 Ψ\PsiΨ 是一个 Transformer 跟踪器(Ye et al. 2022; Cui et al. 2022; Chen et al. 2022),它仅由一个骨干网络和一个预测头网络组成,其中骨干网络集成了特征提取和融合的过程。具体而言,Transformer 跟踪器接收一系列非重叠的图像块(每个图像块的分辨率为 p×pp \times pp×p)作为输入。这意味着一个 2D 参考-搜索图像对需要通过一个块嵌入层来生成多个 1D 图像令牌序列 {fr∈RD×Nr,fs∈RD×Ns}\{f_r \in \mathbb{R}^{D \times N_r}, f_s \in \mathbb{R}^{D \times N_s}\}{fr∈RD×Nr,fs∈RD×Ns},其中 DDD 是令牌维度,Nr=HrWr/p2N_r = H_r W_r / p^2Nr=HrWr/p2,Ns=HsWs/p2N_s = H_s W_s / p^2Ns=HsWs/p2。这些 1D 图像令牌随后被拼接并加载到一个 LLL 层的 Transformer 编码器中进行特征提取和关系建模。每个 Transformer 层 δ\deltaδ 包含一个多头注意力和一个多层感知机。在这里,我们将第 lll 个 Transformer 层的前向过程公式化如下:
frsl=δl(frsl−1),l=1,2,...,L(1) f_{rs}^l = \delta^l(f_{rs}^{l-1}), \quad l = 1, 2, ..., L \quad \tag{1} frsl=δl(frsl−1),l=1,2,...,L(1)
其中 frsl−1f_{rs}^{l-1}frsl−1 表示从第 (l−1)(l-1)(l−1) 个 Transformer 层生成的参考-搜索图像对的拼接令牌序列,而 frslf_{rs}^lfrsl 表示由当前第 lll 个 Transformer 层生成的令牌序列。
通过采用上述建模方法,我们可以构建一个简洁优雅的跟踪器来实现逐帧跟踪。然而,这种建模方法有一个明显的缺点。创建的跟踪器仅专注于帧内目标匹配,缺乏建立跨视频流跟踪物体所需的帧间关联的能力。因此,这种局限性阻碍了视频级跟踪算法的研究。
在这项工作中,我们旨在缓解这一挑战,并为视频级跟踪算法提出一种新的设计范式。首先,为了进行时域建模,我们将跟踪框架的输入从图像对级别扩展到视频级别。然后,我们引入了一种新的时间令牌/提示 TTT,旨在传播视频序列中目标实例的外观、时空位置和轨迹信息。形式上,我们将视频级跟踪公式化如下:
B←Ψ:{R1,R2,...,Rk,S1,S2,...,Sn,T}(2) B \leftarrow \Psi : \{R_1, R_2, ..., R_k, S_1, S_2, ..., S_n, T\} \quad \tag{2} B←Ψ:{R1,R2,...,Rk,S1,S2,...,Sn,T}(2)
其中 {R1,R2,...,Rk}\{R_1, R_2, ..., R_k\}{R1,R2,...,Rk} 表示长度为 kkk 的参考帧,{S1,S2,...,Sn}\{S_1, S_2, ..., S_n\}{S1,S2,...,Sn} 表示长度为 nnn 的搜索帧。我们的视频级跟踪框架接收任意长度的视频片段,以建模目标对象的时空轨迹关系。我们在下一节中更详细地描述提出的核心模块。
视频级跟踪流水线
图 2 给出了我们 ODTrack 框架的概述。在本节中,我们的重点在于构建一个视频级跟踪流水线。理论上,我们将整个视频建模为一个连续的序列,并以自回归的方式逐帧解码目标的定位。首先,我们提出了一种新颖的视频序列采样策略,专为满足视频级模型的输入要求而设计。随后,为了捕捉视频序列中目标实例的时空轨迹信息,我们引入了两种简单而有效的时间令牌传播注意力机制。
视频序列采样策略
大多数现有的跟踪器(Yan et al. 2021a; Cui et al. 2022; Ye et al. 2022)通常在短时间间隔内采样图像对,例如 50、100 或 200 帧间隔。然而,这种采样方法构成了潜在的限制,因为这些跟踪器无法捕捉被跟踪对象的长期运动变化,从而限制了跟踪算法在长期场景中的鲁棒性。为了从长期视频序列中获得目标实例更丰富的时空轨迹信息,我们偏离了传统的短期图像对采样方法,提出了一种新的视频序列采样策略。具体而言,我们建立了一个更大的采样间隔,并在此间隔内随机抽取多个视频帧,以形成任意长度的视频片段 {R1,R2,...,Rk,S1,S2,...,Sn}\{R_1, R_2, ..., R_k, S_1, S_2, ..., S_n\}{R1,R2,...,Rk,S1,S2,...,Sn}。虽然这种采样方法看起来很简单,但它使我们能够近似整个视频序列的内容。这对于视频级建模至关重要。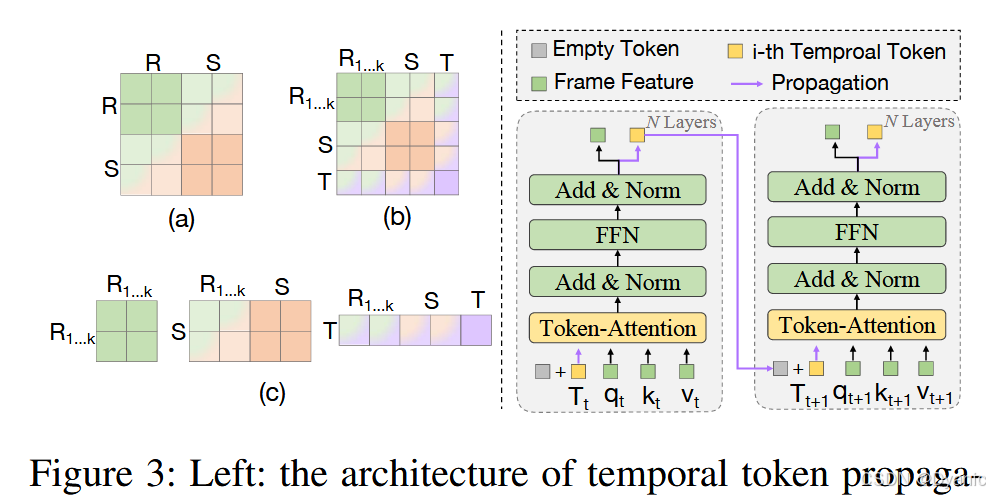
时间令牌传播注意力机制
我们没有采用复杂的视频 Transformer(Xie et al. 2023)作为编码视频内容的基础框架,而是从一个新的角度进行设计,利用一个简单的 2D Transformer 架构,即 2D ViT(Dosovitskiy et al. 2021)。为了构建一个优雅的实例级帧间相关机制,必须扩展原始的 2D 注意力操作以提取和整合视频级特征。在我们的方法中,我们基于压缩-传播的概念设计了两种时间令牌注意力机制,即拼接令牌注意力机制(concatenated token attention mechanism)**和**分离令牌注意力机制(separated token attention mechanism),如图 3(左)所示。核心设计涉及向注意力操作中注入额外信息,例如更多的视频序列内容和时间令牌向量,使它们能够提取目标实例更丰富的时空轨迹信息。在图 3(a) 中,原始注意力操作通常使用图像对作为输入,其关系建模过程可以表示为 f=Attn([R,S])f = \text{Attn}([R, S])f=Attn([R,S])。在这种范式下,跟踪器只能在每个图像对内进行独立交互,建立有限的时间相关性。在图 3(b) 中,提出的拼接令牌注意力机制将输入扩展到上述视频序列,实现了跨帧时空关系的密集建模。受通过拼接形成的语言的上下文性质的启发,我们将拼接操作应用于建立视频序列的上下文。其公式可以表示为:
ft=Attn([R1,R2,...,Rk,St,Tt])=∑s′′t′′Vs′′t′′⋅exp⟨qst,ks′′t′′⟩∑s′t′exp⟨qst,ks′t′⟩(3) f_t = \text{Attn}([R_1, R_2, ..., R_k, S_t, T_t]) = \sum_{s''t''} V_{s''t''} \cdot \frac{\exp \langle q_{st}, k_{s''t''} \rangle}{\sum_{s't'} \exp \langle q_{st}, k_{s't'} \rangle} \quad \tag{3} ft=Attn([R1,R2,...,Rk,St,Tt])=s′′t′′∑Vs′′t′′⋅∑s′t′exp⟨qst,ks′t′⟩exp⟨qst,ks′′t′′⟩(3)
其中 TtT_tTt 是第 ttt 个视频帧的时间令牌序列。[⋅⋅⋅,⋅⋅⋅][\cdot \cdot \cdot , \cdot \cdot \cdot ][⋅⋅⋅,⋅⋅⋅] 表示令牌之间的拼接。qst,kstq_{st}, k_{st}qst,kst 和 vstv_{st}vst 是拼接特征令牌的时空线性投影。值得注意的是,我们为每个视频帧引入了一个时间令牌,目的是存储采样视频序列的目标轨迹信息。换句话说,我们将目标当前的时空轨迹信息压缩成一个令牌向量,该向量用于传播到随后的视频帧。一旦时间令牌提取了目标信息,我们便以自回归的方式将令牌向量从第 ttt 帧传播到第 (t+1)(t+1)(t+1) 帧,如图 3(右)所示。首先,第 ttt 个时间令牌 TtT_tTt 被添加到第 (t+1)(t+1)(t+1) 个空令牌 TemptyT_{empty}Tempty 中,导致第 (t+1)(t+1)(t+1) 帧的内容令牌 Tt+1T_{t+1}Tt+1 更新,然后将其作为输入传播到后续帧。形式上,传播过程为:
Tt+1=Tt+Tempty T_{t+1} = T_t + T_{empty} Tt+1=Tt+Tempty
ft+1=Attn([R1,R2,...,Rk,St+1,Tt+1])(4) f_{t+1} = \text{Attn}([R_1, R_2, ..., R_k, S_{t+1}, T_{t+1}]) \quad \tag{4} ft+1=Attn([R1,R2,...,Rk,St+1,Tt+1])(4)
在这种新的设计范式下,我们可以采用时间令牌作为推断下一帧的提示,利用过去的信息来指导未来的推断。此外,我们的模型通过在线令牌传播隐式地传播目标实例的外观、定位和轨迹信息。这显著提高了视频级框架的跟踪性能。另一方面,如图 3© 所示,提出的分离令牌注意力机制将注意力操作分解为三个子过程:参考帧之间的自信息聚合、参考帧与搜索帧之间的交叉信息聚合,以及时间令牌与视频序列之间的交叉信息聚合。这种分解在一定程度上提高了模型的计算效率,而令牌传播则与上述过程保持一致。
关于在线更新的讨论。大多数以前的跟踪算法结合在线更新方法来训练时空跟踪模型,例如添加额外的分数质量分支(Yan et al. 2021a)或 IoU 预测分支(Danelljan et al. 2019)。它们通常需要复杂的优化过程和更新决策规则。与这些方法不同,我们通过利用令牌序列的在线迭代传播来避免复杂的在线更新策略,从而使我们能够实现更高效的模型表示和计算。
预测头和损失函数
对于预测头网络的设计,我们采用传统的分类头和边界框回归头来实现所需结果。用于预测的分类得分图 R1×Hsp×Wsp\mathbb{R}^{1 \times \frac{H_s}{p} \times \frac{W_s}{p}}R1×pHs×pWs、边界框尺寸 R2×Hsp×Wsp\mathbb{R}^{2 \times \frac{H_s}{p} \times \frac{W_s}{p}}R2×pHs×pWs 和偏移尺寸 R2×Hsp×Wsp\mathbb{R}^{2 \times \frac{H_s}{p} \times \frac{W_s}{p}}R2×pHs×pWs 分别通过三个子卷积网络获得。我们采用焦点损失(Focal Loss)(Lin et al. 2017)作为分类损失 LclsL_{cls}Lcls,并将 L1 损失和 GIoU 损失(Rezatofighi et al. 2019)作为回归损失。总损失 LLL 可以公式化为:
L=Lcls+λ1L1+λ2LGIoU(5) L = L_{cls} + \lambda_1 L_1 + \lambda_2 L_{GIoU} \quad \tag{5} L=Lcls+λ1L1+λ2LGIoU(5)
其中 λ1=5\lambda_1 = 5λ1=5 和 λ2=2\lambda_2 = 2λ2=2 是正则化参数。由于我们使用视频片段进行建模,任务损失是针对每个视频帧独立计算的,最终损失是搜索帧长度上的平均值。
实验
实施细节
训练。我们使用 ViT-Base (Dosovitskiy et al. 2021) 模型作为视觉编码器,其参数使用 MAE (He et al. 2022) 预训练参数进行初始化。训练数据包括 LaSOT (Fan et al. 2019)、GOT-10k (Huang, Zhao, and Huang 2021)、TrackingNet (Müller et al. 2018) 和 COCO (Lin et al. 2014)。在输入数据方面,我们采用包含三个 192 × 192 像素参考帧和两个 384 × 384 像素搜索帧的视频序列作为模型输入。我们采用 AdamW 优化网络参数,骨干网络的初始学习率为 1 × 10⁻⁵,其余部分为 1 × 10⁻⁴,并将权重衰减设置为 10⁻⁴。我们将训练轮次设置为 300 个 epoch。在每个 epoch 中随机采样 60,000 个图像对。学习率在 240 个 epoch 后下降 10 倍。模型在拥有两块 80GB Tesla A100 GPU 的服务器上运行,批次大小(batch size)设置为 8。
推理。为了与训练设置保持一致,我们在推理阶段将三个等间隔的参考帧合并到我们的跟踪器中。同时,搜索帧和时间令牌向量按帧输入。此外,我们对模型参数、FLOPs 和推理速度进行了对比实验,如表 1 所示。所提出的 ODTrack 在 2080Ti 上进行了测试,运行速度为 32 fps。
与 SOTA 的比较
GOT10K。GOT10K 是一个包含 10,000 多个视频序列的大规模跟踪数据集。GOT10K 基准测试提出了一项协议,即跟踪器仅使用其训练集进行训练。我们遵循该协议训练我们的框架。如表 2 所示,所提出的方法优于以往的跟踪器,并且与之前表现最佳的跟踪器 ARTrack(75.5% AO)相比,表现出极具竞争力的性能(77.0% AO)。这些结果表明,ODTrack 的优势之一来自于视频级采样策略,该策略旨在释放视频级建模框架的潜力。
LaSOT。LaSOT 是一个大规模长期跟踪基准,包含 1120 个训练序列和 280 个测试序列。如表 2 所示,与大多数其他跟踪算法相比,我们的 ODTrack-B 取得了新的当前最佳(state-of-the-art)结果。例如,与最新的 ARTrack 相比,我们的方法在 AUC、PNorm 和 P 分数方面分别取得了 0.6%、1.5% 和 1.5% 的增益。此外,图 4 显示了属性评估的结果,证明了我们的跟踪器在多个挑战属性上优于其他跟踪方法。这些结果表明,令牌传播机制有助于模型学习目标实例的轨迹信息,并大大改善了长期跟踪场景中的目标定位。
TrackingNet。TrackingNet 是一个大规模短期数据集,提供了一个包含 511 个视频序列的测试集。如表 2 报告,与高性能跟踪器 SeqTrack 相比,我们的方法在成功率(success)、归一化精确度(normalized precision)和精确度(precision)得分方面表现良好,分别超过了 1.2%、1.3% 和 1.3%。这证明了我们的 ODTrack 具有强大的泛化能力。
LaSOText。LaSOText 是 LaSOT 的扩展版本,包含 150 个长期视频序列。如表 2 报告,我们的方法取得了良好的跟踪结果,优于大多数对比跟踪器。例如,我们的跟踪器获得了 52.4% 的 AUC、63.9% 的 PNorm 得分和 60.1% 的 P 得分,分别优于 ARTrack 0.5%、1.9% 和 1.6%。这些结果符合我们的预期,即视频级建模在复杂场景下具有更稳定的目标定位能力。
VOT2020。VOT2020 (Kristan, Leonardis, and et.al 2020) 包含 60 个具有挑战性的序列,并使用二值分割掩码作为地面真值(groundtruth)。我们使用 Alpha-Refine (Yan et al. 2021b) 作为 ODTrack 的后处理网络来预测分割掩码。如表 3 所示,我们的 ODTrack-B 和 -L 在掩码评估中分别以 58.1% 和 60.5% 的 EAO 取得了最佳结果。
TNL2K 和 OTB100。我们在 TNL2K (Wang et al. 2021b) 和 OTB100 (Wu, Lim, and Yang 2015) 基准上评估了我们的跟踪器。它们分别包含 700 个和 100 个视频序列。表 5 中的这些结果表明,ODTrack-B 和 -L 在 TNL2K 和 OTB100 基准上均达到了最佳性能,证明了时间令牌传播注意力机制的有效性。
消融实验
令牌传播的重要性。为了研究等式 (4) 中令牌传播的效果,我们在表 4(a) 中进行了是否传播时间令牌的实验。w/o Token 表示采用视频级采样策略但不进行令牌传播的实验。从第二行和第三行可以观察到,缺乏令牌传播机制会导致 AUC 分数下降 1.2%。这一结果表明,令牌传播在跨帧目标关联中起着至关重要的作用。
不同的令牌传播方法。我们在表 4(a) 中进行了实验,以验证视频级跟踪框架中提出的两种令牌传播方法的有效性。可以观察到,分离式(separate)和拼接式(concatenation)方法都取得了显著的性能提升,其中拼接式方法的结果略好。这证明了两种注意力机制的有效性。
搜索视频片段的长度。如表 4(b) 所示,我们消融了搜索视频序列长度对跟踪性能的影响。当视频片段的长度从 2 增加到 3 时,AUC 指标提高了 0.3%。然而,序列长度的持续增加并没有带来性能的提升,这表明过长的搜索视频片段会给模型带来学习负担。因此,我们应该选择合适的搜索视频片段长度。
采样范围。为了验证采样范围对算法性能的影响,我们在表 4© 中对视频帧的采样范围进行了实验。当采样范围从 200 扩大到 1200 时,AUC 指标性能有明显提升,表明视频级框架可以从更大的采样范围中学习目标轨迹信息。
可视化与局限性
可视化。为了直观展示所提方法的有效性,尤其是在包含相似干扰物的复杂场景中,我们在 LaSOT 数据集上可视化了 ODTrack 和三种先进跟踪器的跟踪结果。如图 5 所示,由于能够密集传播目标的轨迹信息,我们的跟踪器在这些序列上远超最新的跟踪器 SeqTrack。此外,我们可视化了时间令牌注意力操作的注意力图,如图 6 所示。我们可以观察到,时间令牌持续传播并关注物体的运动轨迹信息,这有助于我们的跟踪器准确地定位目标实例。
局限性。这项工作将整个视频建模为一个序列,并以自回归的方式逐帧解码实例的定位。尽管取得了显著成果,但由于 GPU 资源的限制,我们的视频级建模方法是一种全局近似,我们目前仍无法以低成本的方式构建该框架。一个有前景的解决方案将涉及改进 Transformer 的计算复杂度和轻量化建模。
结论
在这项工作中,我们提出了 ODTrack,一种用于视觉目标跟踪的新型视频级框架。我们将视觉跟踪重新表述为一个令牌传播任务,以自回归的方式密集地关联跨视频帧的上下文关系。此外,我们提出了一种视频序列采样策略和两种时间令牌传播注意力机制,使得所提出的框架能够简化视频级时空建模,并避免复杂的在线更新策略。大量实验表明,我们的 ODTrack 在七个跟踪基准测试中取得了显著的成果。我们希望这项工作能为视频级跟踪建模的进一步研究提供启发。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)