【linux】多线程(二)线程控制pthread_create,pthread_join,pthread_exit,pthread_cancel,pthread_self
一、pthread线程库二、线程创建pthread_create三、线程等待pthread_join四、零碎知识全局变量可重入函数五、线程终止pthread_exit,pthread_cancel获取线程的tid,pthread_self六、线程函数传递对象c++11中的多线程七、线程的管理八、如何理解pthread_join中的参数是二级指针retval九、如何理解线程的独立栈
小编个人主页详情<—请点击
小编个人gitee代码仓库<—请点击
linux系列专栏<—请点击
倘若命中无此运,孤身亦可登昆仑,送给屏幕面前的读者朋友们和小编自己!

目录
前言
【linux】多线程(一)线程概念——书接上文 详情请点击<——,本文会在上文的基础上进行讲解,所以对上文不了解的读者友友请点击前方的蓝字链接进行学习
本文由小编为大家介绍——【linux】多线程(二)线程控制
一、pthread线程库
- 内核中有没有很明确的线程的概念呢?没有,因为linux对于线程的设计理念就是采用“进程”(内核数据结构PCB)模拟线程,所以在linux中将线程叫做轻量级进程,所以内核中并没有线程的概念,内核中只有轻量级进程的概念
- 由于内核中只有轻量级进程的概念,所以内核中不会直接给我提供线程的系统调用,只会给我提供轻量级进程的系统调用,诸如clone等

- 观察上图的clone,参数很多也很难理解并且难以使用,这个clone是linux操作系统提供的用于维护轻量级进程的系统调用,那么这个clone系统调用对于用户来讲是否友好?不友好,因为用户根本不关心轻量级进程的相关的诸如clone等系统调用,并且这些系统调用的使用以及学习成本较高,用户关心的是线程,即对于用户来讲,需要的是线程的接口
- 所以linux的开发者就为用户在应用层编写了一个pthread线程库,注意这个pthread线程库的底层是封装了轻量级进程的系统调用,pthread线程库为用户提供线程的接口
- 几乎所有linux平台都是默认自带这个pthread线程库的,在linux中编写多线程代码,需要使用pthread这个第三方库
- 那么这个pthread线程库在哪里呢?其实是在/lib64/libpthread.so.0这个路径下

- 既然是在pthread是在应用层的第三方库,那么使用pthread线程库的使用就要被加载到内存,并且一般来讲第三方库都是动态库,并且pthread这个动态库被放在了系统路径下/lib64中,g++进行查找动态库的时候会去/lib64这个路径下查找,所以也就势必要使用选项-l告诉g++,让g++知道去/lib64这个路径下去找哪一个动态库,这个动态库的名称是去掉头去掉结尾,所以这个动态库的名称是pthread,所以在makefile中对使用了第三方库pthread的文件进行编译需要添加-lpthread选项,这里选项中的 l 可以省略,即-pthread也可以
mythread:mythread.cc
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:clean
clean:
rm -f mythead
线程控制分为线程创建,线程等待,线程终止,下面小编将依次进行讲解
二、线程创建pthread_create
-
那么前面讲了这么多,现在我们还没有真正见过线程呢,下面小编就来带领大家见一下线程,创建线程要使用pthread_create这个接口

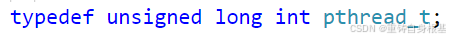
-
pthread_create的第一个参数是输出型参数,即thread是一个pthread_t*类型的,如上本质上pthread_t这个类型是一个长整数,thread是用于获取创建的线程的id,即线程tid类似于进程的pid,pthread_create的第二个参数attr是一个const pthread_attr_t *类型的,作用是为线程设置属性,这里我们不需要给线程设置属性,所以默认我们不关心第二个参数attr,即传入nullptr即可
-
pthread_create的第三个参数start_routine是线程函数,即一个函数指针类型void *(*) (void *)类型的,用于传入我们要让线程执行的函数,因为我们创建线程的目的就是让线程执行函数任务,第四个参数是arg类型是void*,用于给线程执行的函数传参,这里我们暂时不关心设置为nullptr即可
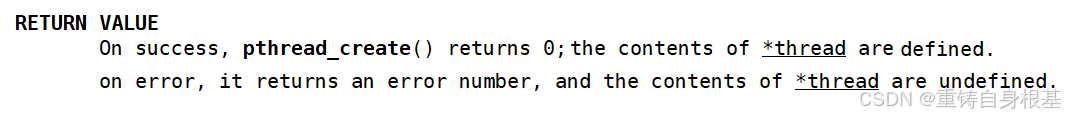
-
并且我们看一下pthread_create的返回值,如果创建新线程成功,那么返回0,并且新线程的tid被定义,如果创建新线程失败,那么返回错误码,并且新线程的tid没有被定义,这里有一个值得思考的点,为什么创建新线程失败,并没有设置错误码errno呢?
-
因为一个进程中可能有多个线程,而错误码errno是一个全局变量只有一个,所以并不能支持所有的新线程设置错误码,所以干脆新线程如果出错了都不设置错误码了,而是直接返回错误码即可,这样就保证了每一个线程都可以有自己的错误码
-
那么接下来小编先让main函数对应的主线程创建一个新线程,新线程执行threadRoutine函数,即死循环打印pid,同时主线程创建完成之后也死循环打印pid
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
while(true)
{
cout << "new thread, pid: " << getpid() << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, nullptr);
while(true)
{
cout << "main thread, pid: " << getpid() << endl;
sleep(1);
}
return 0;
}
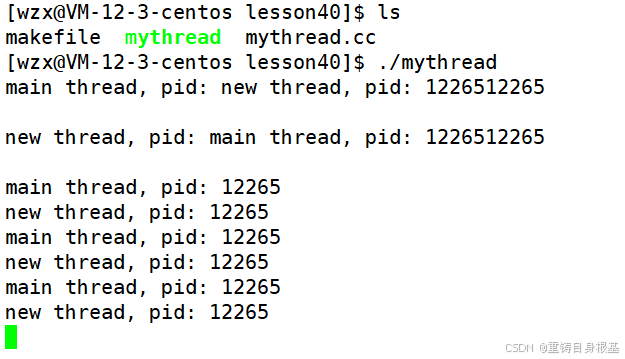
运行结果如下
- 如上,我们确实观察到了有两个执行流在进行死循环打印,我们知道一个执行流只能执行一个死循环,而此时进程中却执行了两个死循环,即另一个执行流一定是我们创建出来的新线程执行的死循环打印
- 我们也可以看出,如果多个线程(主线程和新线程)同时访问显示器资源(访问同一个资源)的时候会出现打印诸如前两行打印语句错乱的情况,因为线程同时访问的资源是共享资源,访问的资源不是临界资源,所以后续我们还会对线程增加同步与互斥机制来保护资源
- 我们还可以看出,主线程和新线程打印的pid是同一个pid,所以主线程和新线程是同属于一个进程的两个分支
- 使用ps -aL可以查看系统中的全部的轻量级进程,其中-aL选项中的a是all全部的意思,L是轻量级进程的意思,所以当左侧进程运行起来之后,我们使用ps -aL查看系统中全部的轻量级进程
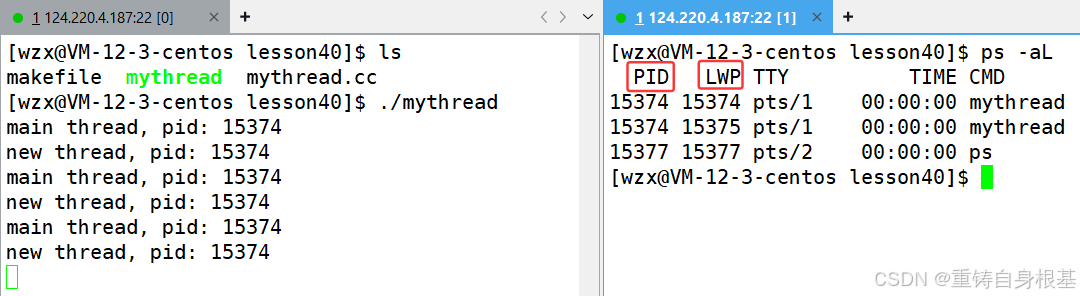
- 我们可以看到系统中有两个mythread轻量级进程,前两列一个是PID,一个是LWP,关于这两个进程的PID相同我们可以理解,但是什么是LWP呢?其实LWP是light weight process即轻量级进程的意思,关于这个LWP,主线程的LWP是与PID相同的,新线程的LWP是与PID不相同的,所以因此在线程被调度的时候CPU就可以区分出哪一个是新线程,哪一个是主线程,当主线程的时间片到了之后,就将PID对应的全部的线程都进行切换,那么这个LWP是否是线程的ID(线程的ID也就是tid)呢?
- 其实不是,这个LWP是给内核看的,用于在内核层面标识轻量级进程,而线程的ID是在用户层面,给用户看的,其实就是pthread_create的第一个参数输出型参数所对应的值,下面小编获取一下给大家看一下,并且这个tid更准确来讲就是虚拟地址,如何理解小编后面会进行讲解
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
while(true)
{
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, nullptr);
while(true)
{
printf("new thread tid: %p\n", tid);
sleep(1);
}
return 0;
}
运行结果如下
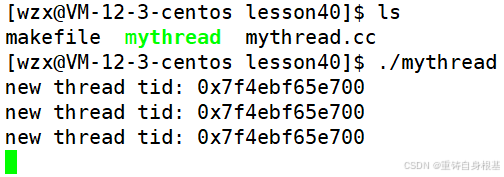
- 接下来小编带领大家学习一下pthread_create的第四个参数arg,之前小编讲解这个类型为void*的arg是给pthread_create中的第三个参数类型为void *(*) (void *)对应的函数传参的,即线程创建成功,新线程回调线程函数的时候,需要传参,这个第四个参数arg就是给线程函数传参的
- 我们知道void*作为函数的参数可以接收任意类型的指针,void*作为函数参数可以返回任意类型的指针,那么也就意味着我可以给这个函数传入字符串喽,注意这个字符串需要强转为void*类型用于传参,所以下面小编给这个函数传入一个名称字符串,如果要使用这个字符串,那么应该将其强转回const char*类型,并且让其进行打印,由线程执行这个函数
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
while(true)
{
cout << name << ", new thread, pid: " << getpid() << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
while(true)
{
cout << "main thread, pid: " << getpid() << endl;
sleep(2);
}
return 0;
}
运行结果如下
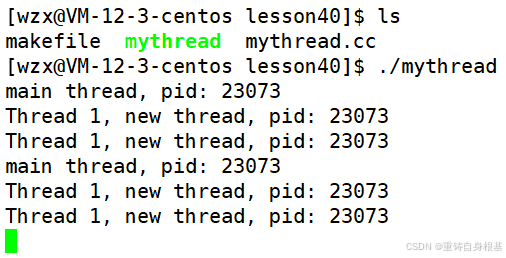
三、线程等待pthread_join
- 通过上面的讲解我们已经可以进行线程的创建了,可是我们猜想一下线程创建出来,新线程执行完了线程函数,那么新线程执行完了任务之后,需不需要被等待呢?
- 需要,因为新线程的底层是内核数据结构PCB,PCB也是资源,如果不等待新线程,那么就会造成内存泄漏,那么等待新线程有什么意义呢?
- (1)回收新线程,防止内存泄漏(2)如果需要的话,获取新线程执行任务的返回值,确认新线程是否执行完任务

- pthread_join的作用是等待一个新线程,根据新线程的tid,这个等待工作一定是主线程来做的,那么第一个参数传入新线程的tid即可,第二个参数我们先不关心,先设置为nullptr即可
- 那么接下来小编就尝试让主线程等待新线程,新线程5s之后退出死循环,而主线程创建完成新线程之后就执行pthread_join等待新线程退出
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
pthread_join(tid, nullptr);
cout << "main thread quit..." << endl;
return 0;
}
运行结果如下
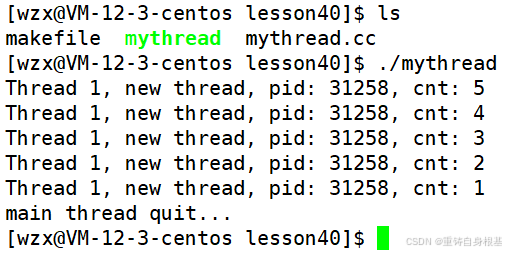
- 我们可以看出,主线程使用pthread_join等待新线程的时候,默认是阻塞式等待新线程
- 接下来我们学习一下pthread_join的第二个参数retval的作用,其实是用于接收获取线程函数的返回值,咋一看,咦,还是个二级指针,有点意思,那么这究竟是什么门道,我们先使用一下,使用完成之后再进行讲解原理
- 那么线程函数就可以返回0表示任务执行成功,返回除了0以外的数字表示错误码用于反馈给主线程,主线程就可以使用pthread_join的第二个参数retval进行接收
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
return (void*)2;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (int)retval << endl;
return 0;
}
运行结果如下

- 这是g++你这是要何故?为什么不给我编译过?其实这也是正常现象因为我们在线程函数中针对类型为int的返回值2将其强制类型转换为void*,int是4个字节,void*是几个字节呢?void*是一个指针,不同平台指针的大小不同

- 而在linux平台上,是妥妥的64位机器,即指针的大小是8个字节,下面我们来验证一下
#include <iostream>
using namespace std;
int main()
{
cout << sizeof(void*) << endl;
return 0;
}
运行结果如下

- 在64位机器上,指针的大小是8个字节,那么对于线程函数的返回值(void*)2,是4个字节的int类型强制类型转换8个字节的void*类型,会发生整型提升,g++允许整型提升,但是我们在主线程中将(int)retval,即将类型为void*的retval强制类型转换为int,即此时8个字节的void*强制类型转换为4个字节的int
- 那么这时候就会发生数据截断,即可能会发生数据丢失,那么g++编译器会进行检查,g++编译器不允许这种事情发生,所以就会直接报错,那么我们进行平滑的转换不就好了,不能转换为4个字节的int,那我转换为8个字节的long long int长整数不就好了,此时也就不会发生数据截断,那么此时编译器也就不会报错了
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
return (void*)2;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下
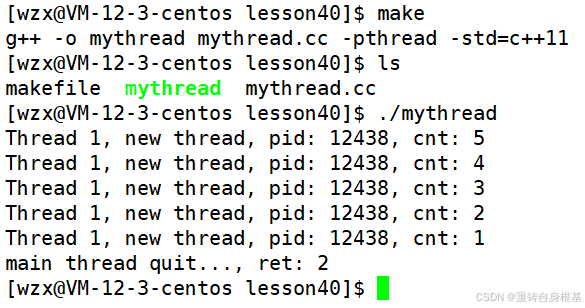
- 此时主线程就可以获取到新线程的返回值了,这个返回值为0可以表示执行任务成功,返回值为非0可以表示出错,具体的数字表示错误码,将其进行转换即代表错误的原因,可是之前我们学过进程退出的三种状态,即(1)进程异常(2)进程退出,结果正确(3)进程退出,结果错误
- 可是这里我们使用pthread_join获取到的仅仅是一个0或者退出码,那么如果新线程出现异常了呢?难道我们就不关心了吗?下面小编让新线程出现一下除零错误的异常,观察一下现象
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 3;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
int a = 10;
a /= 0;
return (void*)2;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下
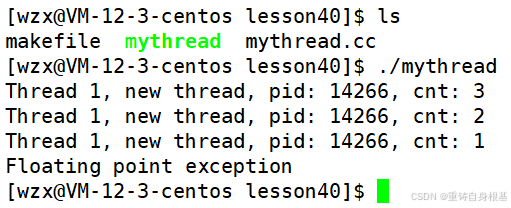
- 此时甚至主线程的打印语句还没有执行,整个进程因为新线程的异常终止了其实这也是正常的现象,那么我们思考一下,新线程和主线程是整个进程的执行分支,新线程和主线程代表着整个进程,那么新线程或者主线程出现异常,那么就代表着进程出现了异常,所以自然的,此时无论是新线程还是主线程都会收到异常信号终止退出,进而整个进程异常退出,所以对于主线程来讲,根本没有必要关心新线程的是否出现异常,因为一旦新线程出现异常,那么此时我主线程也一并被干掉了,异常以整个进程为整体,这个进程可能是子进程,由这个进程的父进程关心异常即可
四、零碎知识
全局变量
- 如果在代码中有一个全局变量,那么这个全局变量能否被主线程以及新线程所共享呢?下面小编定义一个全局变量g_val,由主线程对全局变量进行修改,观察新线程的打印结果
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
int g_val = 100;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
while(true)
{
printf("new thread, g_val: %d, &g_val: %p\n", g_val, &g_val);
sleep(1);
}
return (void*)0;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
while(true)
{
printf("main thread, g_val: %d, &g_val: %p\n", g_val, &g_val);
g_val++;
sleep(2);
}
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下
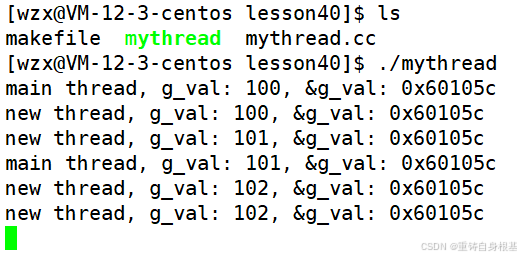
- 此时全局变量g_val无论是主线程还是新线程看到的全局变量的地址都相同,并且当线程的任意一方对这个全局变量进行了修改,其它线程都可以看到并访问修改后的结果
- 那么如果此时小编定义的不是全局变量,而是一个全局缓冲区呢?那么也就意味着此时多个线程之前可以看到同一块缓冲区,恰恰这块缓冲区就在进程的地址空间上,线程也可以访问进程的地址空间,那么此时一个线程向缓冲区内写入数据,另一个线程从缓冲区中读取数据,那么线程之间就可以进行通信了
- 所以线程相对于进程来讲,一个进程内的各个线程之间进行通信成本较低,所以我们通常研究较多的是多线程,研究较少的是多进程,所以针对并发性上有研究价值的更多的是多线程的并发性
可重入函数
- 那么定义一个打印的函数,这个函数是否可以被主线程以及新线程同时执行呢?
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void show(const string& name)
{
cout << name << "say# " << "hello thread" << endl;
}
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
while(true)
{
show("new thread");
sleep(1);
}
return (void*)0;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
while(true)
{
show("main thread");
sleep(2);
}
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下

- 此时主线程和新线程都可以执行这个show函数,即一个函数被多个执行流同时执行,并且不出现错误,那么我们称这个函数叫做可重入函数
五、线程终止pthread_exit,pthread_cancel
- 经过如上的讲解我们已经可以对一个线程进行线程的创建,线程的等待,接下来就是线程的终止,如何终止线程呢?其实有三种方式
- 第一种方式是新线程正常return,这个小编在之前已经演示过了,所以小编就不再进行演示了

- 第二种方式是pthread_exit,我们其参数是线程函数的返回值,那么我们为了更明显的进行演示,所以小编返回7,但是为了类型匹配pthread_exit的参数所以仍然需要进行强制类型转换(void*)7,所以我们在想要进行终止的线程中调用pthread_exit即可,那么小编演示终止新线程
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 3;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
pthread_exit((void*)7);
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
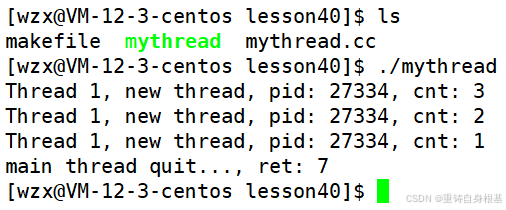
运行结果如下
此时新线程就被终止了,并且主线程获取到了新线程的返回值为7
- 小编小编,我感觉这个pthread_exit的使用方式有点类似于exit啊,是不是exit也可以终止单个线程呢?那么接下来小编为大家演示一下,小编让新线程调用exit观察现象即可
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 3;
while(true)
{
cout << name << ", new thread, pid: " << getpid() << ", cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
exit(0);
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下
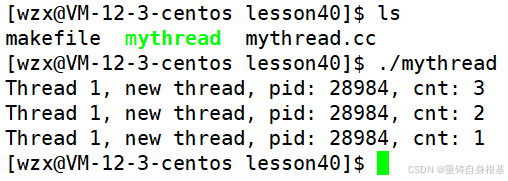
- 很不幸exit虽然将新线程终止了,可是遭殃的是整个进程,即在单个线程的任意位置调用了exit,那么都会立即终止整个进程,这并不是我们想要,我们想要的是终止单个线程,而不是终止整个进程,所以exit不适用于终止线程

- pthread_cancel同样也是一种终止单个线程的方法,但是pthread_cancel并不常用,pthread_cancel的参数是传入要取消的线程的tid即可去掉指定线程
- 那么我们在主线程创建出新线程后,新线程执行死循环打印的线程函数,在主线程中,当新线程运行2秒后,在主线程中使用pthread_cancel取消新线程,观察新线程能否被取消,并且在主线程中观察新线程的退出码
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* threadRoutine(void* args)
{
const char* name = static_cast<const char*>(args);
while(true)
{
cout << name << ", new thread, pid: " << getpid() << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, (void*)"Thread 1");
sleep(2);
pthread_cancel(tid);
void* retval;
pthread_join(tid, &retval);
cout << "main thread quit..., ret: " << (long long int)retval << endl;
return 0;
}
运行结果如下
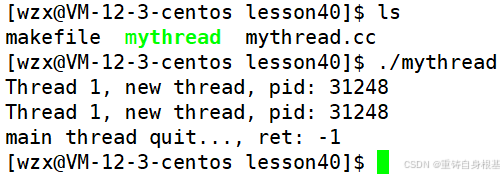
新线程虽然执行的是死循环的线程函数,但是2秒过后,只要主线程中调用的pthread_cancel对新线程进行了取消,那么新线程无论在做什么都会被立即去掉,进而终止新线程,一旦新线程被终止,主线程自热而然就可以等待成功新线程,获取新线程的退出码为-1
并且这个-1实际上是一个专门用于线程被pthread_cancel取消后返回的宏定义即PTHREAD_CANCELED,即(void*)-1

获取线程的tid,pthread_self
- 其实线程的pid不仅仅是在主线程创建新线程的时候主线程可以获取,对于新线程来讲,新线程自己也可以获取自己的线程tid,那么这就要使用到pthread_self了

- pthread_self可以获取当前线程的tid,不需要传参,但是pthread_self的返回值pthread_t是一个10进制的数字,我们知道线程的tid本质上是一个地址,即16进制的数字,所以我们编写一个转换为16进制的函数,而指针天然就是16进制数,那么利用snprintf将pthread_t转换为16进制的指针地址%p并且进行打印到字符数组中即可,那么主线程和新线程分别打印新线程的tid即可,对照是否相同
#include <iostream>
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <string>
#include <stdlib.h>
using namespace std;
string ToHex(pthread_t tid)
{
char hex[64];
snprintf(hex, sizeof(hex), "%p", tid);
return hex;
}
void* threadRoutine(void* args)
{
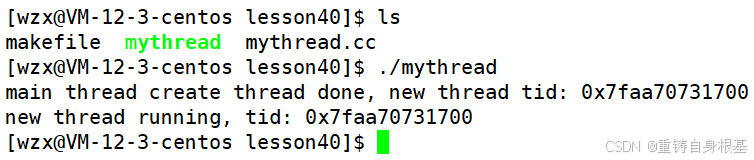
cout << "new thread running, tid: " << ToHex(pthread_self()) << endl;
return (void*)0;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, nullptr);
cout << "main thread create thread done, new thread tid: " << ToHex(tid) << endl;
pthread_join(tid, nullptr);
return 0;
}
运行结果如下
果然,主线程以及新线程打印的tid相同,所以pthread_self可以获取当前线程的tid
六、线程函数传递对象
- 其实当我们第一眼看到pthread_create的第三个参数,即线程函数start_routine的类型void*(*)(void*)的时候,我们就应该意识到,这个线程函数的参数以及返回值难道仅仅可以接收或者返回字符串或者整数吗?大胆一点其它类型难道不可以吗?
- c++中的对象亦可以进行接收或者返回,所以我们就可以将线程执行的任务封装成一个class类,并且将任务的结果以及线程函数的退出码同样也封装成一个类,那么以在堆上进行申请的方式进行传参以及释放即可,下面就是一个任务类Request用于传递任务,以及一个结果类Response用于返回任务结果
- 那么小编就让线程函数执行累加任务,从start累加到end并将结果放到结果类中的result中返回,并且对于任务类Request以及结果类Response的申请都是从堆上申请,那么Request任务类仅需要传递给线程函数对应的指针即可,线程函数使用完任务类Request之后为了防止内存泄漏要进行delete,同时线程函数中也应该在堆上申请一个结果类Response返回结果,主线程中拿到Response的结果后也应该进行delete防止内存泄漏
#include <iostream>
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
using namespace std;
class Request
{
public:
Request(int start, int end, string threadname)
:start_(start), end_(end), threadname_(threadname)
{}
public:
int start_;
int end_;
string threadname_;
};
class Response
{
public:
Response(int result, int exitcode)
:result_(result), exitcode_(exitcode)
{}
public:
int result_;
int exitcode_;
};
void* sumCount(void* args)
{
Request* rq = static_cast<Request*>(args);
Response* rsp = new Response(0, 0);
for(int i = rq->start_; i <= rq->end_; i++)
{
rsp->result_ += i;
}
delete rq;
return (void*)rsp;
}
int main()
{
pthread_t tid;
Request* rq = new Request(1, 100, "thread 1");
pthread_create(&tid, nullptr, sumCount, (void*)rq);
void* ret;
pthread_join(tid, &ret);
Response* rsp = static_cast<Response*>(ret);
cout << "result: " << rsp->result_ << ", exitcode: " << rsp->exitcode_ << endl;
delete rsp;
return 0;
}
运行结果如下

c++11中的多线程
- 其实在c++11中也支持了多线程,c++11支持的多线程的底层是对pthread线程库进行的封装,而pthread线程库的底层是对linux轻量级进程的系统调用诸如clone等进行的封装
- 那么下面小编就来简单演示一下c++11中的多线程,首先需要包头文件#include <thread>,那么接下来就如同类实例化一样使用类thread实例化对象即可,同样的也需要传入线程函数,线程函数的参数以及返回值较为自由可以根据实际的需求设置,当创建出来的新线程执行完线程函数之后,主线程也需要等待新线程,那么调用成员函数join即可等待新线程
#include <iostream>
#include <unistd.h>
#include <thread>
using namespace std;
void threadRoutine()
{
int cnt = 5;
while(true)
{
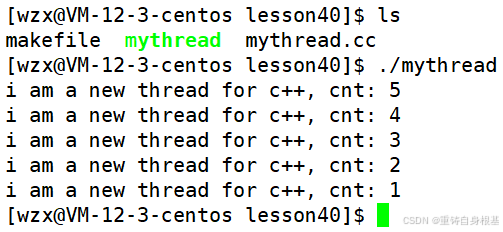
cout << "i am a new thread for c++, cnt: " << cnt << endl;
sleep(1);
cnt--;
if(cnt == 0)
break;
}
}
int main()
{
thread t(threadRoutine);
t.join();
return 0;
}
运行结果如下
- 从上面来看当我们掌握了原生线程库,即pthread线程库之后,对于c++中的线程库的学习成本大大降低,因为c++中的线程库底层还是封装的pthead线程库,同样的如果是在实际的工作中,小编建议读者友友们使用语言的线程库,例如c++的线程库,因为c++的线程库具有可移植性,即同一份代码不光光在linux上可以跑,在windows上也可以跑,因为c++针对不同的平台封装了适配对应平台上的线程函数的接口
- 但是对于使用了pthead线程库的代码来讲,仅仅只能在linux平台上可以跑,在其它平台上无法跑,因为不同的平台对于线程的具体实现方案不同,例如linux上是使用的“进程”内核数据结构PCB模拟的线程,而windows上却是定义了线程对应的描述对象,所以也势必造成了线程相关的接口不同,所以仅仅使用pthread线程库的线程代码不具有可移植性,在实际工作中涉及到多线程的编码的时候,建议使用具有可移植性的语言(c++)层面的多线程的接口
七、线程的管理
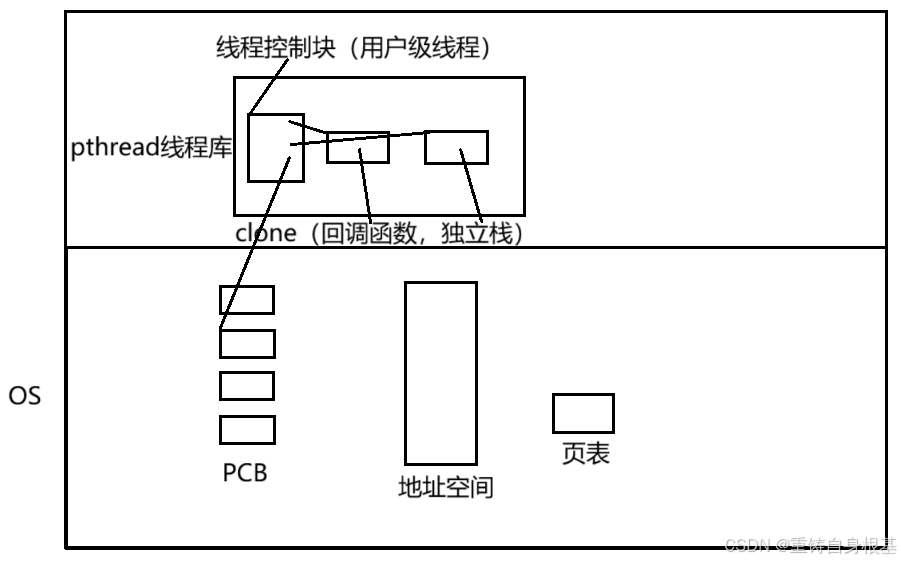
- 首先看上图,在操作系统中有一个进程,进程中有很多的执行流,即主线程以及新线程

- pthead线程库底层是封装的诸如clone等linux的轻量级进程的结构,clone需要的参数如上,我们关心前两个参数,第一个参数fn是一个函数指针,即回调函数用于给轻量级进程调用,第二个是一个给轻量级进程使用的独立栈,那么由于pthread线程库的底层是封装的clone,所以pthread线程库势必要给clone提供回调函数以及独立栈
- pthead线程库(原生线程库)是第三方库,即共享库,共享库使用的时候要动态加载到内存,如果用户要使用pthread线程库,那么这个pthread线程库要不要加载到内存?pthread线程库要加载到内存,然后经过页表映射到地址空间的共享区位置,所以说pthread线程库也是占有空间的呦!
- 所以pthread线程库可以为底层封装的用于创建轻量级进程的系统调用clone提供回调函数以及独立栈,那么系统中可能不仅仅是我这一个用户在使用pthread线程库创建线程,有可能有很多个用户在使用pthread线程库创建线程,那么系统中注定有很多线程,那么线程库要不要管理这些线程?
- 要,如何管理?先描述再组织,所以在pthread线程库中会为每一个线程创建线程控制块tcb,这个线程控制块中描述了线程的诸多属性,例如线程对应的执行流的位置,回调函数,独立栈等内容,然后此时就可以将线程描述起来了,最后使用例如数组将线程组织起来即可完成对线程的管理,从此以后对线程的管理就变成了对特定的数据结构的增删查改
- 由此可见linux的操作系统并不给我们维护线程的概念,linux操作系统中拥有的仅仅是一个轻量级进程,线程概念是pthread线程库给我们用户维护的,所以说线程要维护线程的概念对应的属性,而系统有多个线程,即有多个线程概念对应的属性的集合,所以pthread才会管理用户级线程,pthread线程库虽然要维护用户线程的概念,但是不用维护线程的执行流,因为线程的执行流就是轻量级进程(pcb),用户线程的调度运行基于轻量级进程(线程的执行流)实现的
八、如何理解pthread_join中的参数是二级指针retval
- 之前小编讲过pthread_join的第二个参数retval是用于获取类型为void*(*)(void*)的线程函数的返回值,明明线程函数的返回值是一个void*的一级指针,那么想要获取这个一级指针,直接使用一个一级指针拷贝不就好了,为什么还要大费周章的使用二级指针呢?
- 原因很简单,因为pthread线程库是线程的管理者,线程属性中有线程函数,那么线程函数的返回值我pthread线程库也应该知道,即线程函数的返回值被存储到了pthread线程库的一个区域中,此时这个区域中存储的是一个void*的一级指针,那么如果其它人想要获取这个区域的一级指针只能采用二级指针来进行获取
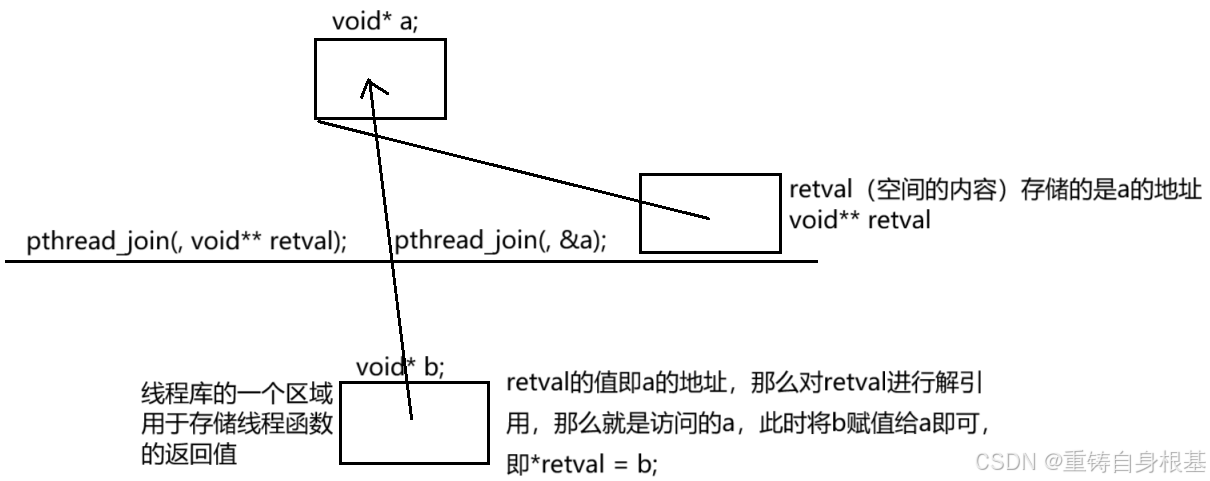
- 原理如上,用于想要使用pthread_join获取线程函数的返回值,那么用于就要定义一个void*的一个指针a,接下来调用pthread_join将a进行取地址,那么对一级指针进行取地址,那么拿到的就是二级指针,即一级指针的地址,传参给pthread_join之后,我们知道函数的形参进行传参,形参要创建临时变量,所以此时临时变量类型为void**的二级指针retval就被创建出来了
- 所以此时二级指针retval中存储的就是&a,即一级指针的地址,线程函数有一个类型为void*的返回值,我们知道因为pthread线程库是线程的管理者,线程属性中有线程函数,那么线程函数的返回值我pthread线程库也应该知道,即线程函数的返回值被存储到了pthread线程库的一个区域中,这个区域就是void* b
- 那么pthread_join可是要获取线程函数的返回值啊,那么它只能从pthread线程库的这个void* b区域中进行获取,那么retval的值即a的地址,那么对retval进行解引用,那么就是访问的a,此时将b赋值给a即可,即*retval = b,所以此时用户就可以拿到线程函数的返回值了
- 其实我们观察本质,无非就是想要将一级指针a的内容覆盖为一级指针b的内容,由于函数传参如果传参了一级指针,那么就会在函数的形参形成一级指针的拷贝,那么修改这个形参的一级指针的拷贝不会影响函数外面的一级指针a的内容,如果想要修改函数外的一级指针a的内容,那么就要拿到一级指针a的地址,即二级地址,拿着二级地址访问一级指针a的内容进行修改
九、如何理解线程的独立栈
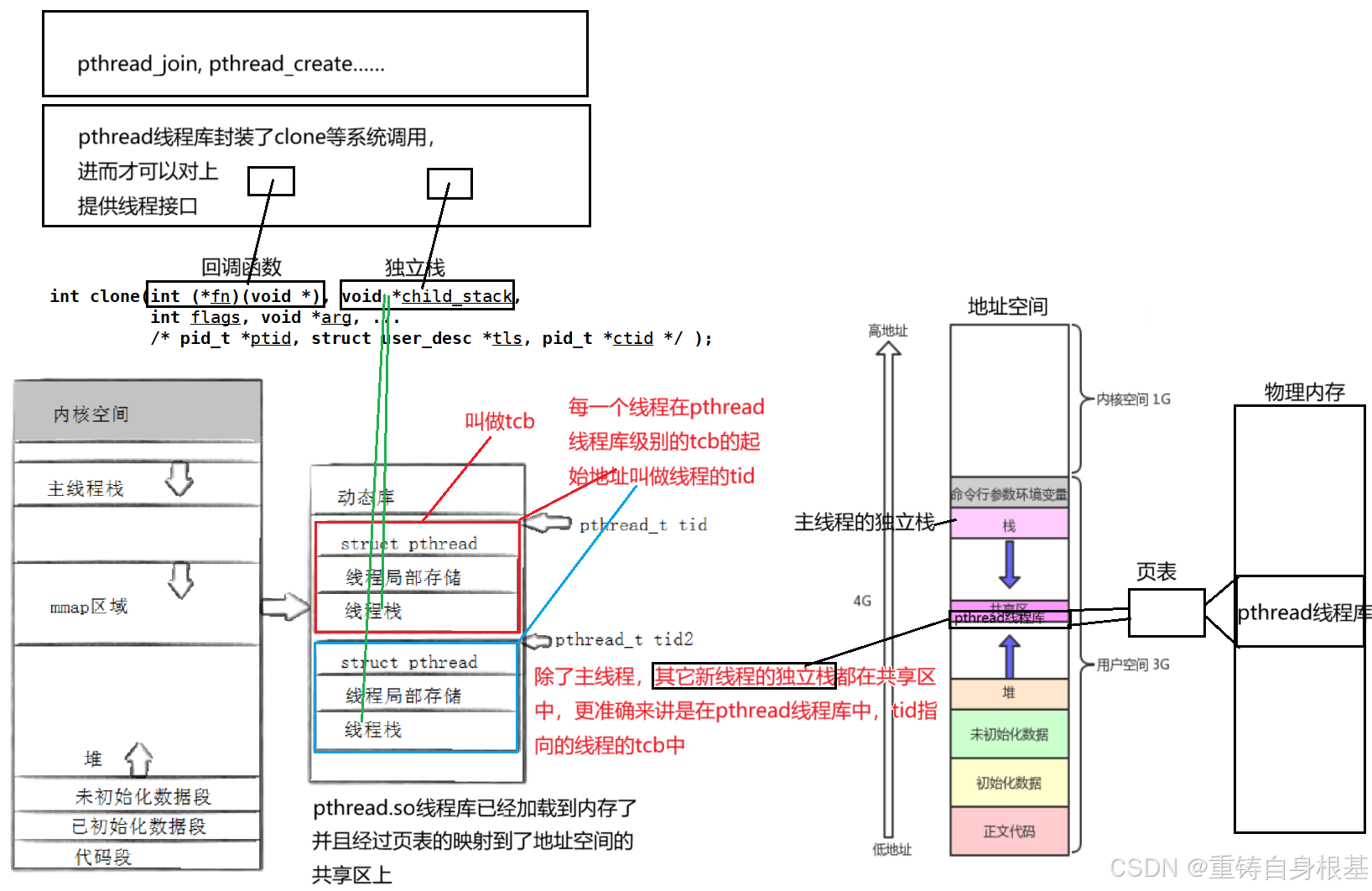
- 我们知道pthread线程库的底层实际上是封装了clone等系统调用,并且clone需要的回调函数,独立栈等都描述在pthread线程库中,进而pthread才可以向上提供线程的函数,例如pthread_join,pthread_create等
- pthread线程库是一个动态库,如果用户想要进行多线程编程,那么就要使用到pthread线程库,此时pthread线程库就要加载到物理内存,经过页表映射到进程地址空间上的共享区区域上
- pthread线程库中为每一个线程都创建了独属于每一个线程的tcb,即线程控制块,其中包含线程的相关属性,例如线程对应的执行流的位置,回调函数,独立栈等,其中每一个线程在线程库级别的tcb的起始地址叫做线程的tid,那么诸如线程的函数想要对线程进行操作,那么只需要拿着线程的tid找到线程控制块tcb就可以进行访问并且操作
- 之前我们将线程都要有自己的独立栈,那么如何理解呢?线程分为主线程以及新线程,主线程的栈帧是存在于地址空间的栈上的,当进行函数调用的时候会在栈上创建栈帧,在栈上创建临时变量,当调用函数完成之后会返回调用函数的位置向后继续执行
- 而新线程也需要栈帧,并且不能和主线程的栈帧冲突,新线程需要栈帧的原因是新线程也要进行函数调用,既然要进行函数调用,那么就需要栈来加载临时变量等,并且在函数调用中也可能又调用了函数,那么栈帧的存在还可以保证不同函数的临时变量互相之前不产生影响
- 而pthread线程库已经加载到了物理内存中,并且经过页表映射到了进程地址空间上,所以pthread线程库就会占用空间呦,恰恰pthread线程库又对线程进行了描述,所以就会为每一个新线程创建独属于新线程的独立栈,供新线程进行一系列的诸如函数调用,创建临时变量等使用
- 所以我们说线程中,除了主线程的独立栈是在地址空间的栈上,新线程的独立栈都是在共享区,更准确的来讲是在共享区的pthread线程库中,线程的tid指向的tcb中的一部分空间
总结
以上就是今天的博客内容啦,希望对读者朋友们有帮助
水滴石穿,坚持就是胜利,读者朋友们可以点个关注
点赞收藏加关注,找到小编不迷路!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)