ICML 2025 | 中科院 & 清华提出 KAN-AD:重构 KAN 架构,傅里叶级数赋能时间序列异常检测-研梦非凡
"大道至简"比"叠积木"更有效!KAN-AD用傅里叶级数给KAN换个"发动机",在精度、效率、鲁棒性上实现了全面突破
【来源:卷毛的时序日记微信公众号】
在云服务监控、工业制造等领域,时间序列异常检测就像"安全卫士",能及时发现数据中的异常波动,避免重大故障。但传统方法总爱"钻牛角尖"——要么过度关注局部小波动导致误判,要么模型复杂到跑不动。
今天要给大家介绍的ICML 2025最新研究《KAN-AD: Time Series Anomaly Detection with Kolmogorov–Arnold Networks》,直接用三大创新点解决了这些痛点,一起来看看吧!
论文信息
题目:KAN-AD: Time Series Anomaly Detection with Kolmogorov–Arnold Networks
基于柯尔莫哥洛夫 - 阿诺德网络的时间序列异常检测方法KAN-AD
作者:Quan Zhou、Changhua Pei、Fei Sun、Jing Han、Zhengwei Gao、Haiming Zhang、Gaogang Xie、Dan Pei、Jianhui Li
为什么传统方法总掉链子?
先看个扎心的例子:当时间序列里混入局部峰值或下降时(比如服务器突发流量波动),像TimesNet这样的主流模型就容易"走火入魔"——把这些正常小波动当成异常,真正的异常反而漏检了。
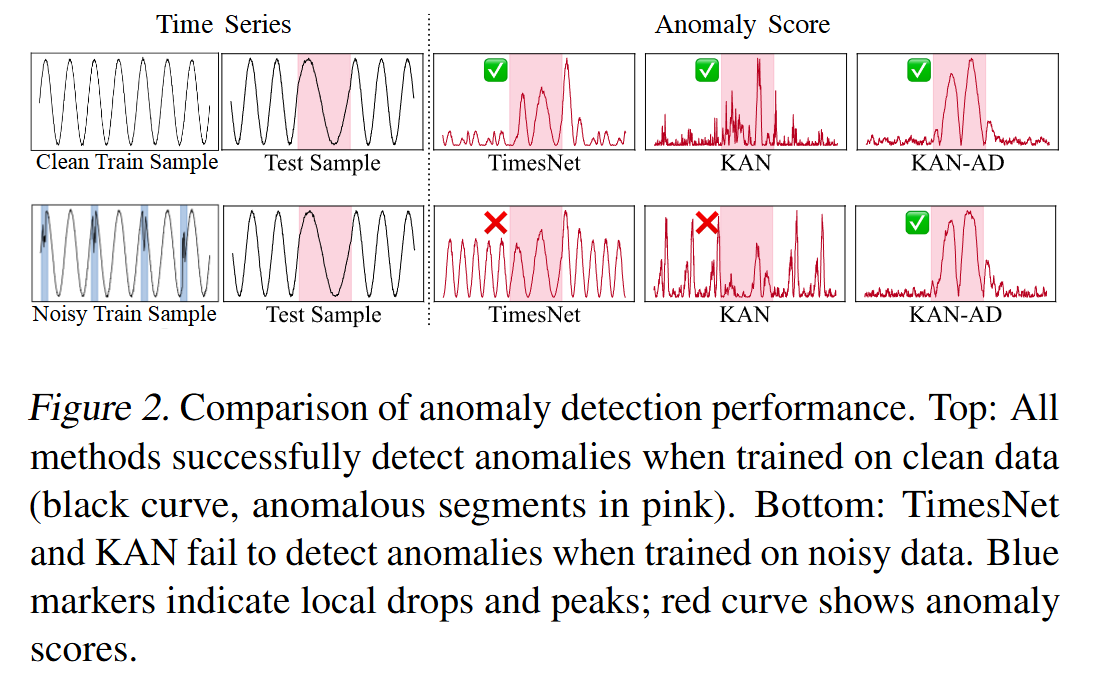
问题出在哪?作者指出:正常数据比异常数据更平滑,但传统预测模型非要"死磕"每一个细节,结果把噪声当成了规律。基于VAE的方法虽然想通过降维避免这个问题,却又容易"偷懒"导致欠拟合。
KAN-AD:给KAN换个"发动机"
受柯尔莫哥洛夫-阿诺德定理启发(任何复杂函数都能拆成简单单变量函数的组合),研究团队对KAN网络进行了三大改造:
- 用傅里叶级数替代B样条:傅里叶的正弦余弦波天生擅长捕捉周期性,还能过滤局部噪声
- 加个"放大镜"看细节:用替代索引函数弥补傅里叶高频信息的缺失
- 消除趋势干扰:通过差分运算让模型更专注于核心模式
一目了然的工作流程
KAN-AD的运作分三步,看完你就懂了:
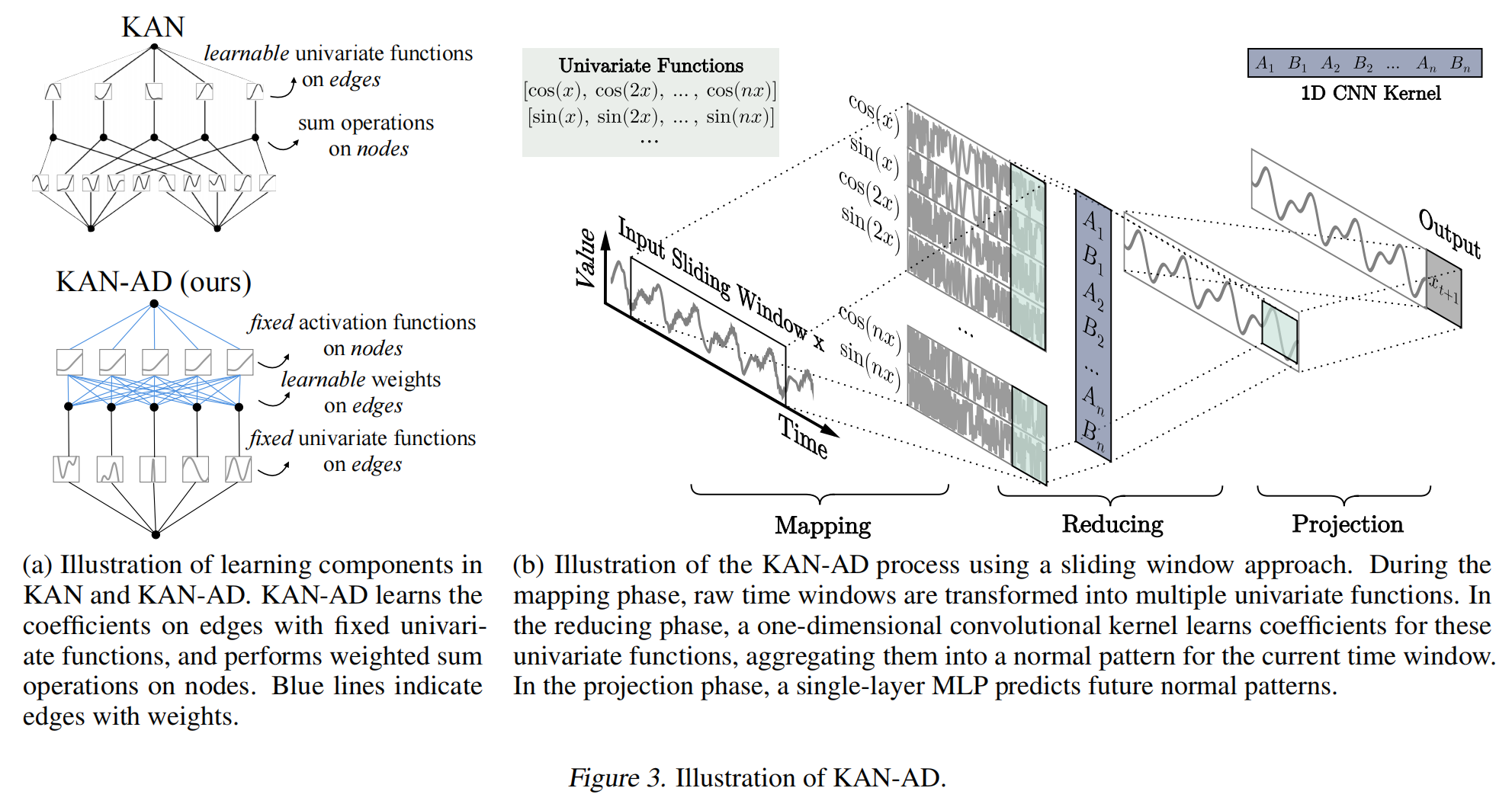
第一步:映射阶段——数据变变变
把原始时间窗口数据,通过三类函数转换成新特征:
- 原始时间序列
- 傅里叶级数(正弦+余弦波)
- 周期增强函数(专门捕捉细微周期)
就像给数据拍了"多角度照片",确保关键特征一个都跑不掉。
第二步:归约阶段——浓缩精华
用堆叠的1D卷积层对特征进行"提纯",通过残差连接防止信息丢失,最后输出正常模式的近似值。这一步就像用滤镜把照片的关键元素凸显出来。
第三步:投影阶段——预测见分晓
用简单的线性层预测下一个时间点的数值,通过比较预测值和实际值判断是否异常。
实战成绩:赢麻了!
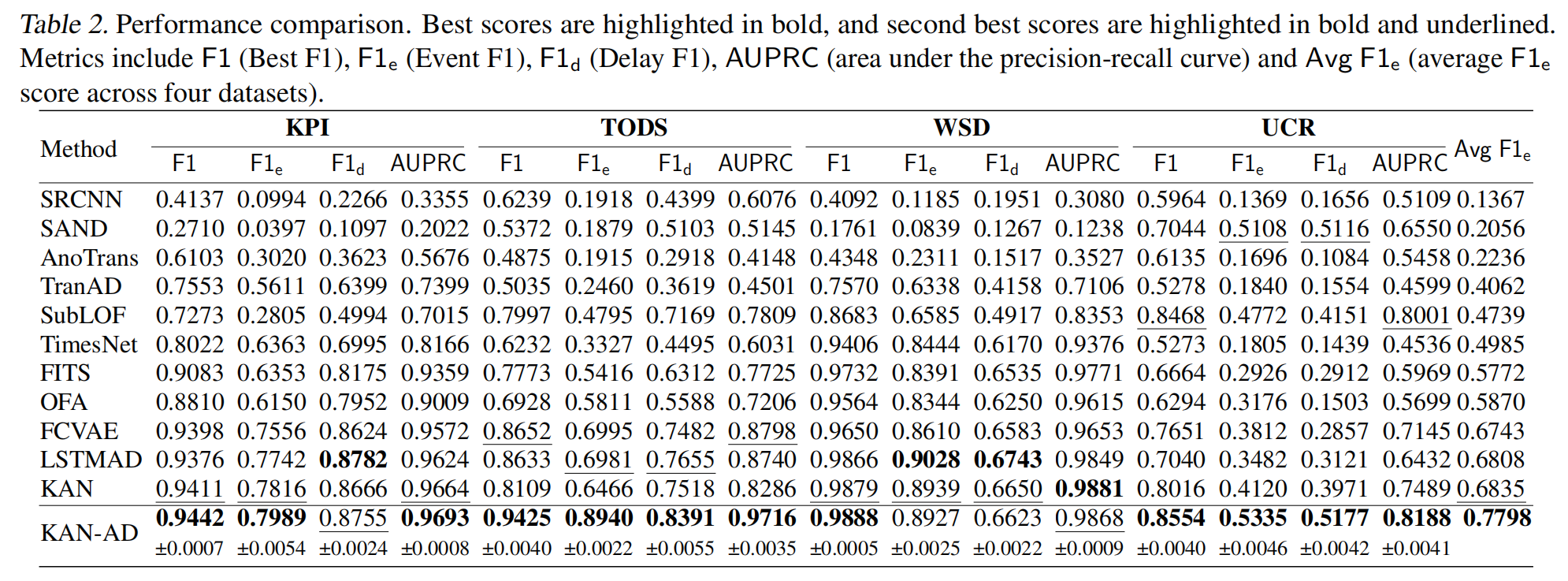
在KPI、TODS、WSD、UCR四个公开数据集上,KAN-AD把十种SOTA方法按在地上摩擦:
精度碾压
- 平均Event F1分数提升15%,在TODS数据集甚至反超27%
- 对长异常段(如UCR中300+点的异常)检测更稳定
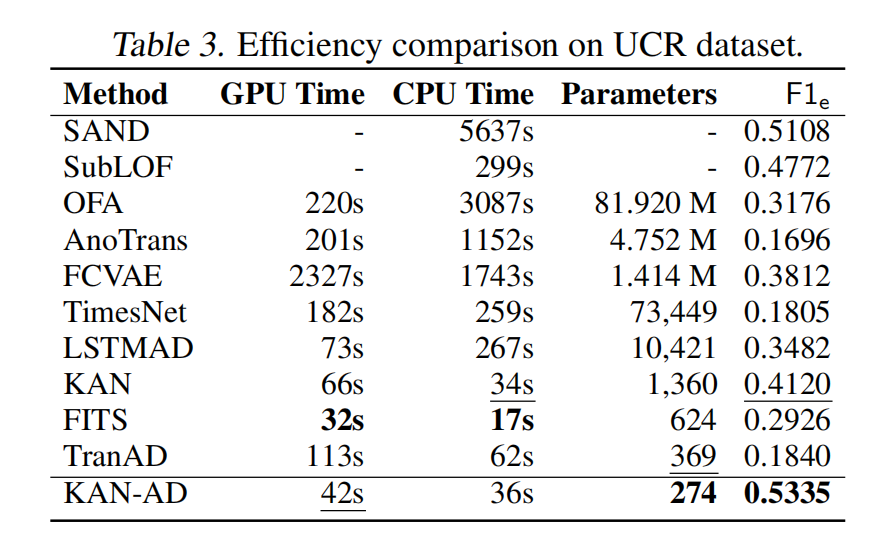
效率感人
- 仅需274个参数!比参数最少的TranAD还少25%
- 推理速度比原始KAN快50%,手机都能跑
鲁棒性拉满
当训练数据中异常比例增加时,LSTMAD等方法性能暴跌,而KAN-AD稳如老狗:
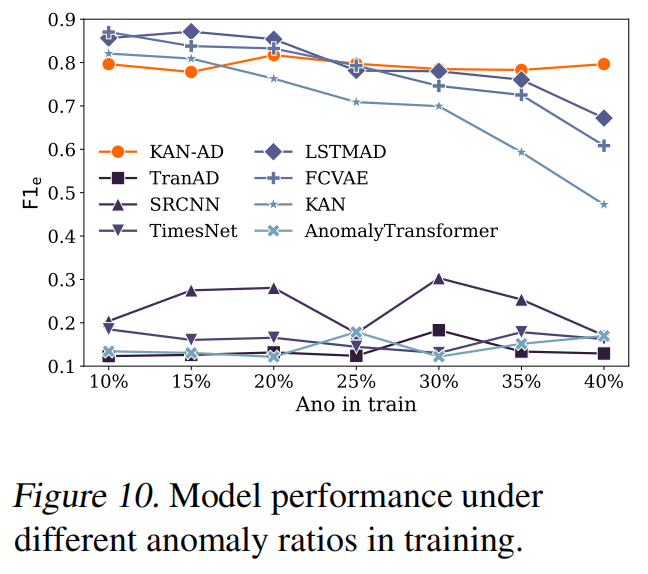
ablation study告诉你哪个模块最关键
作者做了一组"拆零件"实验,证明每个创新都不是多余的:
- 常数项消除模块:对KPI、TODS这类波动大的数据集,能提升5-8%的F1分数
- 傅里叶级数完胜:比泰勒级数、切比雪夫多项式更适合异常检测
- 多特征组合才是王道:傅里叶+周期函数的组合效果远超单一特征

不止单变量!多变量场景同样能打
把KAN-AD稍作改造(每个特征单独处理),在SMD、MSL等多变量数据集上,平均Best F1达到0.9076,参数还不到其他方法的十分之一!
写在最后
KAN-AD的成功证明:有时候"大道至简"比"叠积木"更有效。用傅里叶级数给KAN换个"发动机",居然在精度、效率、鲁棒性上全面突破。
如果你正在做异常检测相关研究,或者需要处理工业传感器、服务器监控等时间序列数据,这个方法绝对值得一试。代码已经开源(https://github.com/CSTCloudOps/KAN-AD),快去亲手试试吧!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)