深度学习篇---Transformer交叉注意力机制
交叉注意力是Transformer模型中连接编码器和解码器的关键机制,允许解码器在生成每个词时动态关注输入序列的相关部分。其核心组件包括查询(解码器当前位置)、键值对(编码器输出),通过计算相似度权重实现信息筛选。该机制在机器翻译等任务中展现出灵活的对齐能力,可直观显示注意力权重分布。典型应用包括多模态任务处理,并衍生出多头、稀疏等多种变体。交叉注意力如同智能对焦系统,使模型能根据当前生成内容有选
Transformer交叉注意力机制详解
1. 什么是交叉注意力?
交叉注意力(Cross-Attention)是连接编码器(Encoder)和解码器(Decoder)的"桥梁",让解码器在生成每个词时,能够"关注"到输入序列中的相关部分。
生活类比:就像同声传译员,在说中文的同时,要时刻关注 speaker 的英文原话,确保翻译准确。交叉注意力就是让模型在生成每个词时,都能"回头看"原始输入。
2. 交叉注意力的核心思想
2.1 基本概念
-
查询(Query, Q):来自解码器当前生成位置
-
键(Key, K):来自编码器输出(输入序列的表示)
-
值(Value, V):来自编码器输出(输入序列的内容)
通俗理解:
-
Q是"我现在想说什么"
-
K是"输入中有哪些关键信息"
-
V是"这些关键信息的具体内容"
2.2 工作原理
解码器位置 → 生成查询 → 在编码器输出中检索 → 获取相关信息 → 生成下一个词
3. 交叉注意力的详细计算过程
3.1 数学公式
Attention(Q, K, V) = softmax(QK^T/√d_k) × V
其中:
-
Q ∈ ℝ^(目标长度 × d_k) # 解码器查询
-
K ∈ ℝ^(源长度 × d_k) # 编码器键
-
V ∈ ℝ^(源长度 × d_v) # 编码器值
3.2 分步理解
# 伪代码:交叉注意力计算过程
def cross_attention(decoder_query, encoder_keys, encoder_values):
# 1. 计算相似度:每个解码位置与所有编码位置的匹配程度
similarity = decoder_query @ encoder_keys.T # [目标长度, 源长度]
# 2. 缩放并归一化为注意力权重
attention_weights = softmax(similarity / sqrt(d_k)) # [目标长度, 源长度]
# 3. 加权求和:根据权重获取编码器信息
context = attention_weights @ encoder_values # [目标长度, d_v]
return context, attention_weights4. 实际工作示例
以英译中"I love China"为例:
第1步:生成"我"
解码器输入:<sos> 查询:<sos>的表示 相似度计算: - 与"I"的相似度:0.8 ← 重点关注 - 与"love"的相似度:0.1 - 与"China"的相似度:0.1 结果:主要从"I"获取信息 → 生成"我"
第2步:生成"爱"
解码器输入:<sos> 我 查询:"我"位置的表示 相似度计算: - 与"I"的相似度:0.2 - 与"love"的相似度:0.7 ← 重点关注 - 与"China"的相似度:0.1 结果:主要从"love"获取信息 → 生成"爱"
第3步:生成"中国"
解码器输入:<sos> 我爱 查询:"爱"位置的表示 相似度计算: - 与"I"的相似度:0.1 - 与"love"的相似度:0.2 - 与"China"的相似度:0.7 ← 重点关注 结果:主要从"China"获取信息 → 生成"中国"
5. Mermaid总结框图
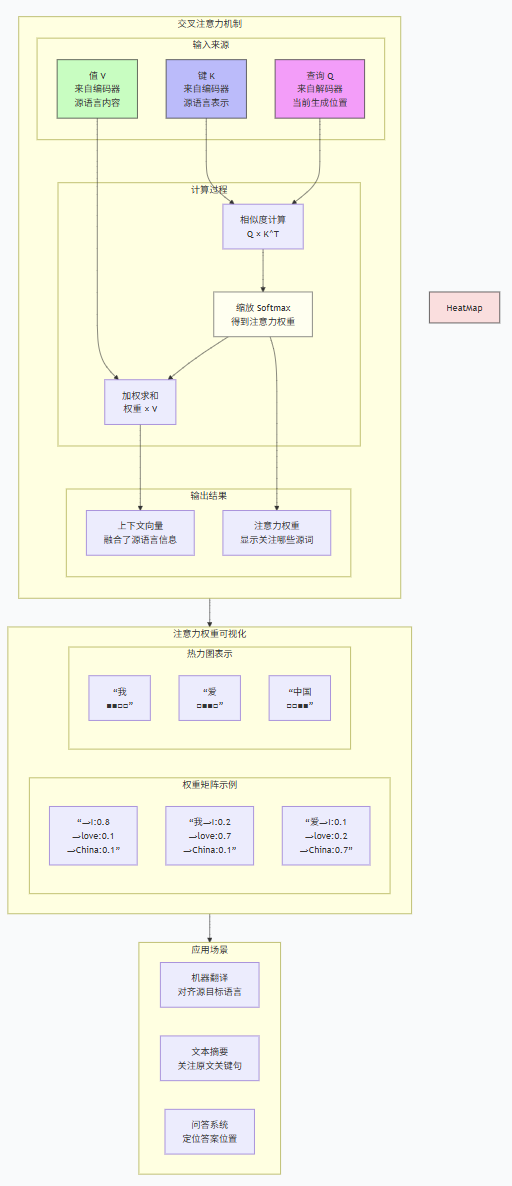
6. 交叉注意力的关键特性
| 特性 | 说明 | 重要性 |
|---|---|---|
| 不对称性 | Q和K/V来源不同 | 连接编码器和解码器 |
| 动态聚焦 | 每个解码步关注不同源位置 | 灵活对齐 |
| 可解释性 | 权重可展示对齐关系 | 理解模型行为 |
| 无位置限制 | 可以关注任意距离的源词 | 长距离依赖 |
7. 与其他注意力机制对比
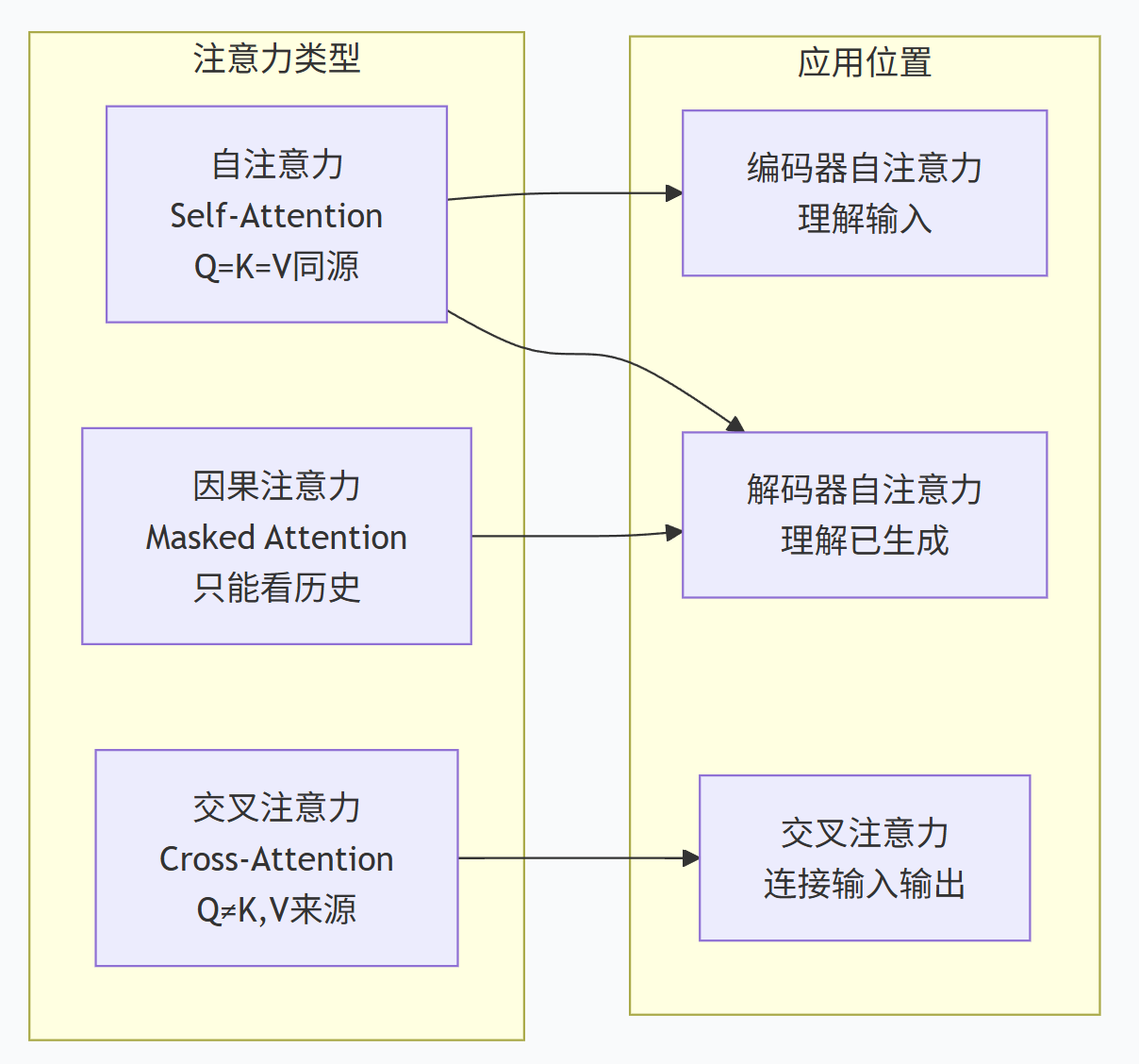
8. 实际应用中的交叉注意力
8.1 机器翻译中的对齐可视化
源语言: I love China
目标语言: 我 爱 中国
注意力权重热力图:
I love China
我 ■■ □ □
爱 □ ■■ □
中国 □ □ ■■
8.2 多模态应用
-
图文生成:文本解码器关注图像区域
-
语音识别:文本解码器关注音频特征
-
视频描述:语言解码器关注视频帧
9. 交叉注意力的变体
| 变体 | 特点 | 优势 |
|---|---|---|
| 多头交叉注意力 | 多个子空间并行 | 捕获不同类型的关系 |
| 稀疏交叉注意力 | 只关注部分源位置 | 减少计算量 |
| 分层交叉注意力 | 多尺度关注 | 处理长序列 |
10. 通俗理解总结
把交叉注意力想象成一个"智能对焦系统":
-
解码器 = 正在写作文的学生
-
编码器 = 参考资料书
-
查询(Q) = 学生当前想写的内容("接下来要写什么?")
-
键(K) = 参考书的目录("哪些章节相关?")
-
值(V) = 参考书的具体内容("具体信息是什么?")
-
注意力权重 = 学生看各章节的时长分配
整个过程:学生每写一句话,都会快速浏览参考书,找到最相关的部分,提取信息,然后写出下一句。写完一句,再看下一句需要什么信息,循环直到完成整篇作文。
这种机制让Transformer能够灵活地在输入和输出之间建立联系,是实现序列到序列任务的核心技术。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献122条内容
已为社区贡献122条内容

所有评论(0)