NeurIPS2025 |TransferTraj:“双迁移”仅需预训练一次,搞定轨迹预测 + 恢复 + 时间估计!
来自NeurIPS2025,最新前沿时序技术,文章提出了一个TransferTraj 模型,首次实现 “双迁移”,同时解决轨迹模型的区域迁移与任务迁移问题,无需为每个场景单独训练。
本篇论文来自NeurIPS2025,最新前沿时序技术,文章提出了一个TransferTraj 模型,首次实现 “双迁移”,同时解决轨迹模型的区域迁移与任务迁移问题,无需为每个场景单独训练。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,最新126篇NeurIPS2025前沿时序合集(更新中)小时已经整理好了,在宫🀄蚝“时序大模型”发送“资料”添加回复“NeurIPS2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:TransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
论文作者:Tonglong Wei,Yan Lin,Zeyu Zhou,Haomin Wen,Jilin Hu,Shengnan Guo,Youfang Lin,Gao Cong,Huaiyu Wan

研究背景
车辆 GPS 轨迹数据为智能交通系统的下游任务(如轨迹预测、轨迹恢复、行程时间估计)提供关键支撑,但现有轨迹学习模型存在两大核心问题:
-
区域迁移性差:不同区域的空间特征(地理尺度、POI 分布、路网结构)差异显著,导致车辆移动模式(转弯、加速、方向)不同,传统标准化方法(归一化、网格离散化)难以适配跨区域场景,模型无法直接复用。
-
任务迁移性弱:不同任务的输入输出结构与学习目标差异大(如轨迹预测关注时序关联,行程时间估计关注起终点 - 时间关联),现有嵌入类方法需为每个任务额外训练预测模块,增加计算与存储成本。
因此提出了TransferTraj 模型,以解决上述问题。
模型框架
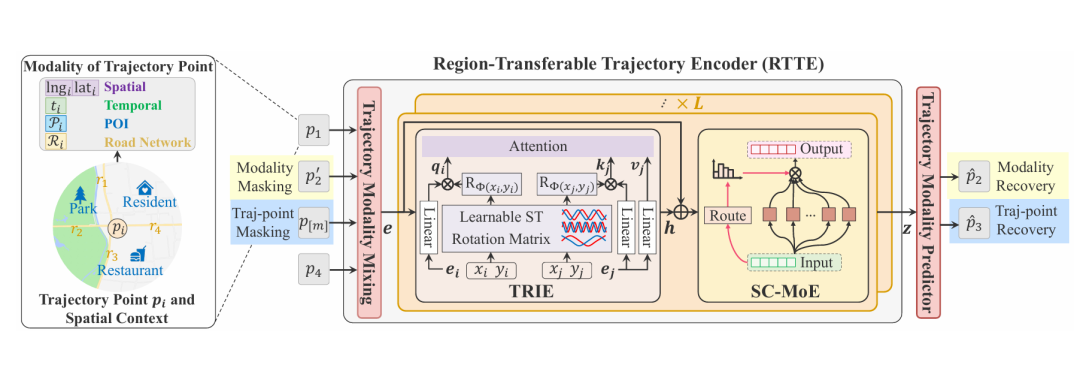
TransferTraj 通过两大核心组件实现区域与任务双迁移性
(一)区域迁移轨迹编码器(RTTE):解决区域迁移问题
RTTE 整合轨迹的四大模态(空间、时间、POI、路网),并通过两个关键模块适配跨区域空间差异:
轨迹模态融合(Trajectory Modality Mixing)
-
空间模态:计算轨迹点相对于起始点的相对坐标(而非绝对坐标),避免区域尺度偏差,再通过线性层编码为嵌入向量。
-
时间模态:将时间戳拆分为 “星期 / 小时 / 分钟 / 相对起始时间”,通过可学习傅里叶编码层转换为嵌入向量。
-
POI 与路网模态:利用预训练文本嵌入模型编码 POI(名称、类型)与路网(名称、长度)的语义信息,通过均值池化与线性层统一维度。
-
最终通过 Transformer 与均值池化融合四大模态,得到轨迹点的统一嵌入向量。
轨迹相对信息提取(TRIE):灵感源自 RoFormer,引入可学习时空旋转矩阵,将轨迹点的相对空间关系(如两点间距离)编码到注意力机制的 Query/Key 中,避免模型依赖特定区域的绝对空间特征,同时利用三角函数的连续性适配更长轨迹。
空间上下文混合专家(SC-MoE)
-
基于 “相似局部空间上下文对应相似移动模式” 的观察,设计多专家网络
-
每个专家网络(共 C 个)通过 MLP 学习特定空间上下文下的移动模式(如高密度 POI 区域的 “走走停停”、高速路网的 “匀速直线”)。
-
门控网络(带噪声 Top-K 机制)根据轨迹点的局部上下文(POI + 路网密度)动态选择适配的专家,实现跨区域移动模式的共享与区分。
轨迹模态预测器:通过线性层预测轨迹点的空间(相对坐标反推经纬度)与时间模态,采用 MSE 损失监督训练,确保模态融合的有效性。
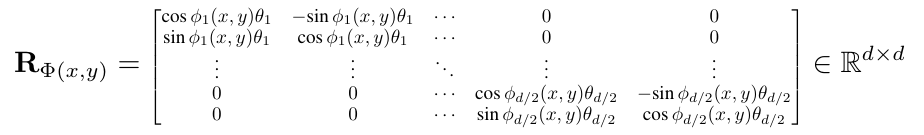
(二)任务迁移输入输出方案:解决任务迁移问题
将所有生成式任务的输入输出结构统一为 “掩码 - 恢复” 范式,无需重新训练即可适配不同任务
模态掩码与恢复:对轨迹点的单一模态(如空间、时间)掩码,模型在输出端恢复该模态(如掩码时间模态用于行程时间估计)。
轨迹点掩码与恢复:用特殊 token掩码连续子轨迹点,模型在输出端恢复完整轨迹(如掩码未来点用于轨迹预测)。
预训练机制:预训练阶段随机组合两种掩码方式(子轨迹点全掩码 + 剩余点随机模态掩码),通过重建损失优化模型,使预训练后的模型可直接迁移至下游任务。
实验数据
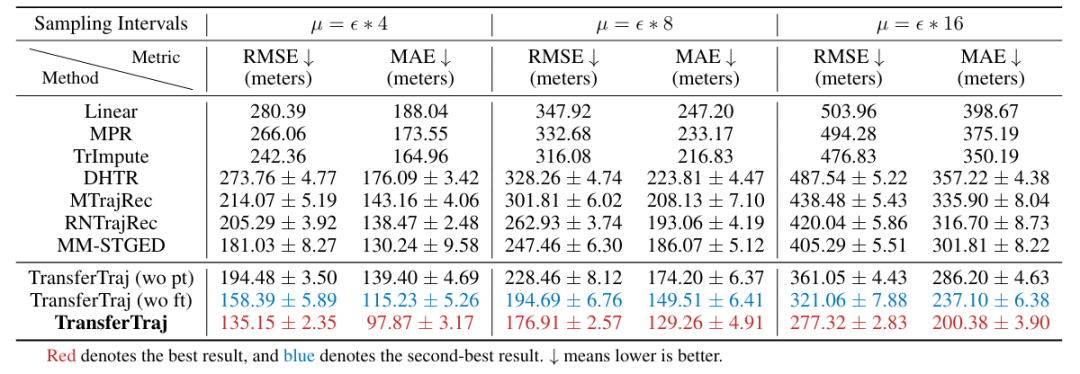
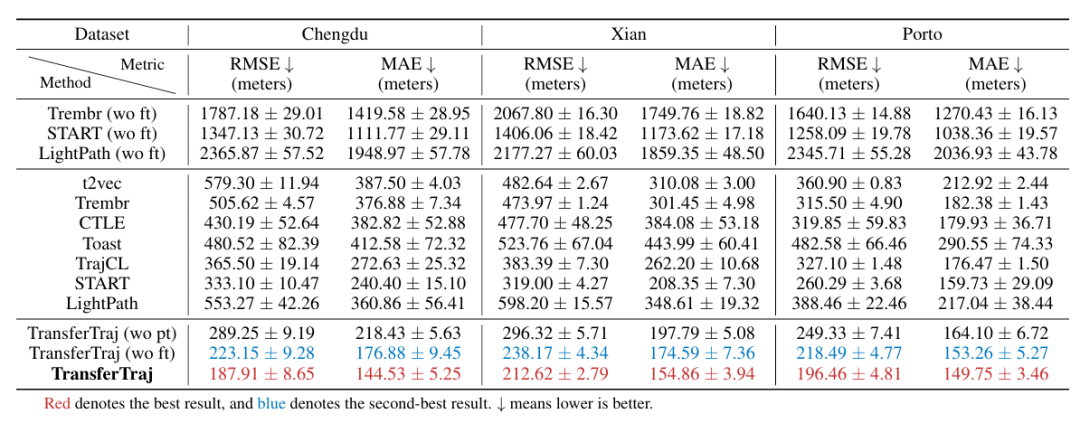
数据集:三个真实车辆轨迹数据集(成都、西安、波尔图),涵盖不同地理尺度、POI / 路网密度与采样间隔
对比基线
-
轨迹预测:t2vec、Trembr、START、LightPath 等 7 种方法。
-
轨迹恢复:Linear、TrImpute、MM-STGED 等 7 种方法。
-
行程时间估计:RNE、TEMP、DOT 等 8 种方法。
评估指标
-
轨迹预测 / 恢复:RMSE(米)、MAE(米)。
-
行程时间估计:RMSE(分钟)、MAE(分钟)、MAPE(%)。
迁移场景:任务迁移、零样本区域迁移(无目标区域数据)、少样本区域迁移(仅 5k 目标区域数据)。
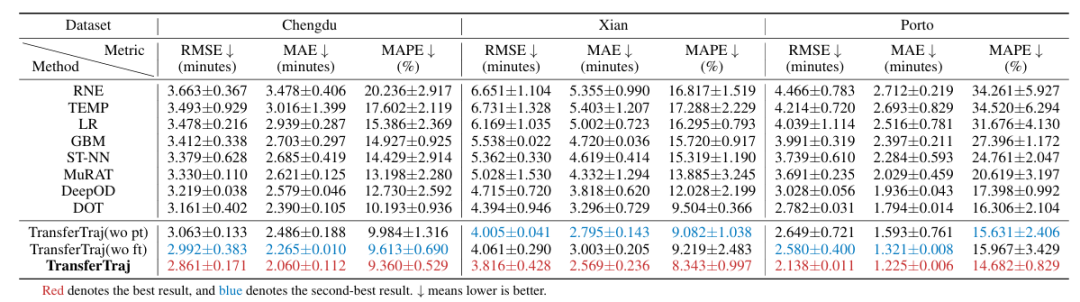
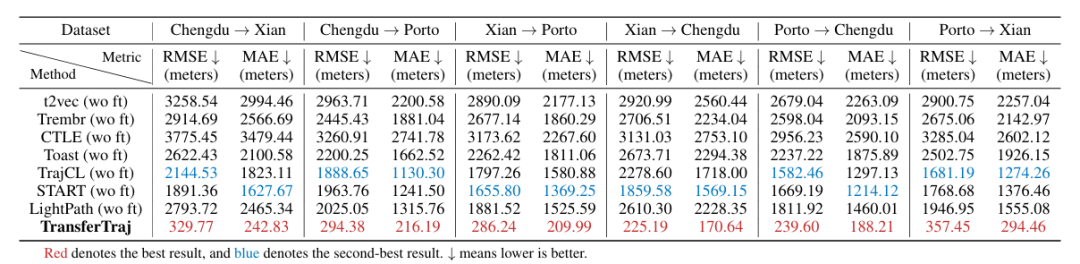
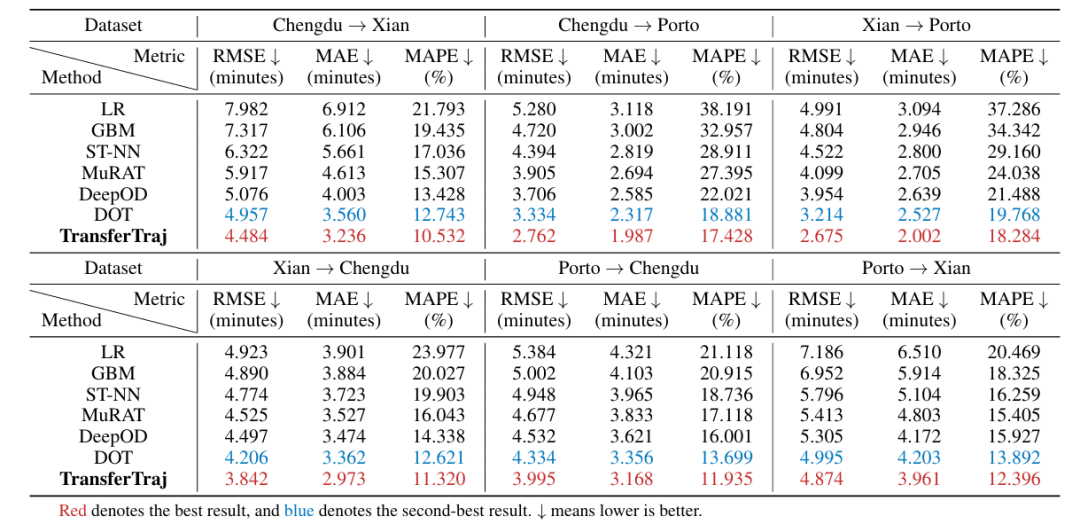
主要研究结果
(1)任务迁移性:预训练即可超越 SOTA
仅预训练(TransferTraj (wo ft))在三大任务上较 SOTA 基线提升显著:
-
轨迹预测:较 START 提升 20.18%。
-
轨迹恢复:较 MM-STGED 提升 17.87%。
-
行程时间估计:较 DOT 提升 7.94%。
进一步微调后(TransferTraj)性能再提升 8.62%-13.59%,且无需修改模型结构
(2)区域迁移性:零样本 / 少样本场景优势显著
-
零样本迁移:在轨迹预测任务中,较 SOTA(START)平均提升 83.70%;行程时间估计任务中较 DOT 提升 10.88%。
-
少样本迁移:轨迹预测任务较 SOTA 提升 33.68%,轨迹恢复提升 18.08%,行程时间估计提升 13.07%。
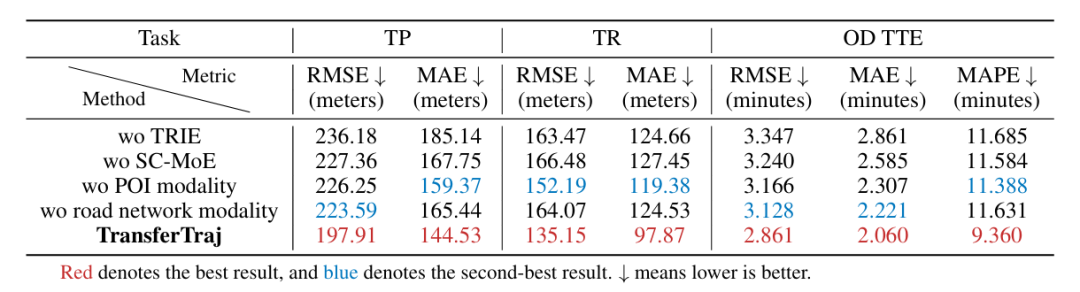
(3)消融实验:关键模块不可或缺
-
移除 TRIE:轨迹预测 RMSE 上升 20.8%,验证相对空间信息的重要性。
-
移除 SC-MoE:行程时间估计 MAPE 上升 23.8%,证明多专家网络对移动模式捕捉的有效性。
-
移除 POI / 路网模态:性能均有下降,验证语义上下文对跨区域适配的作用。
(4)效率优势
TransferTraj 模型大小(3.64-3.83MB)远小于 START(15.03-17.81MB)、LightPath(12.51-13.90MB),训练 / 测试时间仅为 SOTA 方法的 1/3-1/10,且预训练后无需重复训练。
小小总结
文章首次实现 “双迁移”,同时解决轨迹模型的区域迁移与任务迁移问题,无需为每个场景单独训练;创新 RTTE 模块,通过多模态融合、TRIE 相对信息提取、SC-MoE 上下文适配,有效处理区域空间差异;统一任务范式,用 “掩码 - 恢复” 统一任务输入输出,结合预训练实现 “一次训练、多任务复用”,显著降低计算与存储成本。
关注小时,持续学习前沿时序技术!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 37
37 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)