阿里云 大模型高级工程师 ACP 认证 通关 02
扩展答疑机器人的知识范围。
·
扩展答疑机器人的知识范围
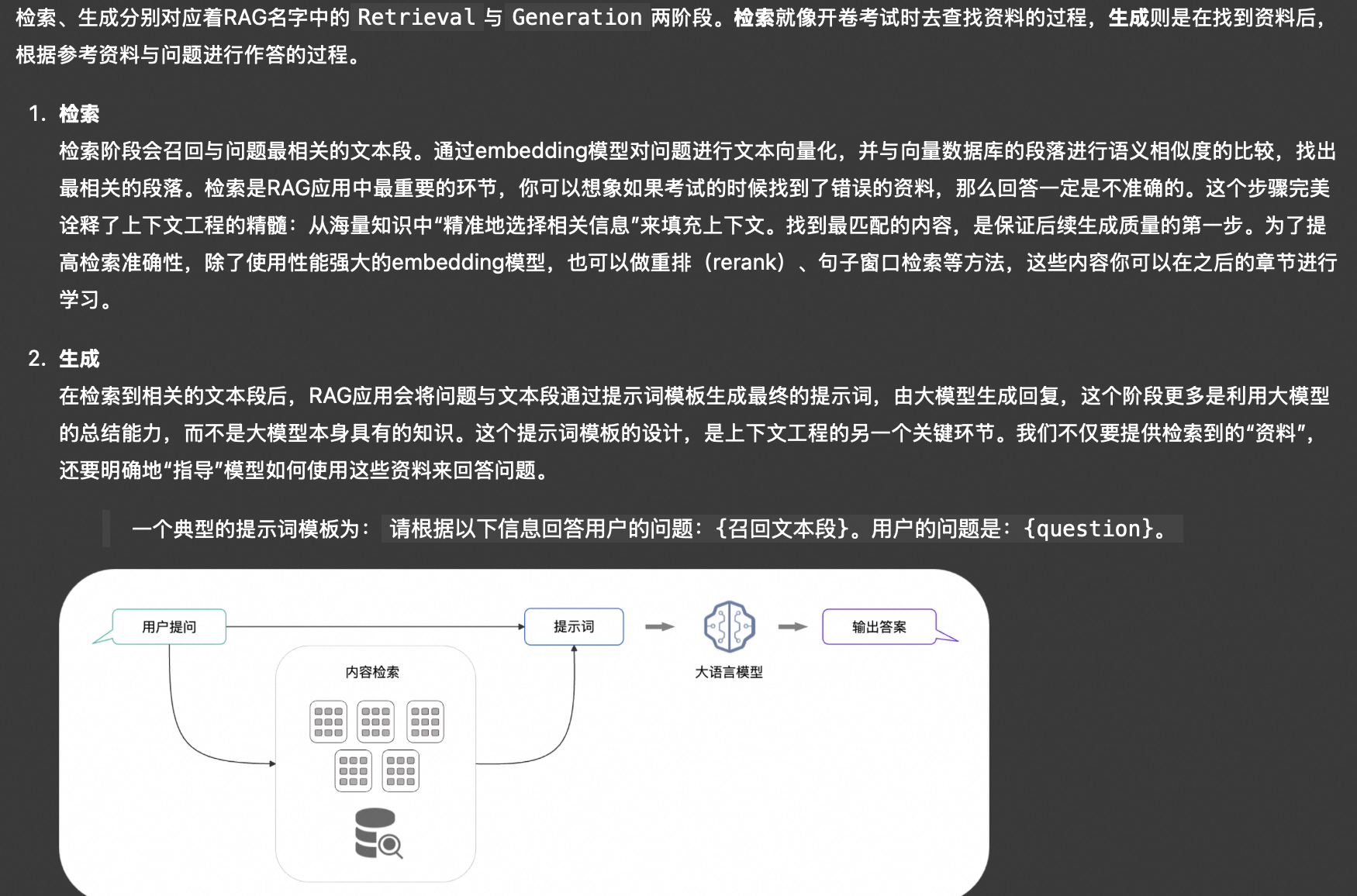
RAG的工作原理:
RAG应用通常包含建立索引与检索生成两部分。
建立索引

问题:主流向量数据库有哪些,各自优缺点。
检索生成
问题:主流embedding模型有哪些?
加载key:
> from config.load_key import load_key import os
>
> load_key()
> # 生产环境中请勿将 API Key 输出到日志中,避免泄露 print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')
创建RAG应用
> 导入依赖
> from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels from llama_index.core
> import SimpleDirectoryReader,VectorStoreIndex from
> llama_index.llms.openai_like import OpenAILike
>
> 这两行代码是用于消除 WARNING 警告信息,避免干扰阅读学习,生产环境中建议根据需要来设置日志级别 import logging logging.basicConfig(level=logging.ERROR)
>
> print("正在解析文件...")
> # LlamaIndex提供了SimpleDirectoryReader方法,可以直接将指定文件夹中的文件加载为document对象,对应着解析过程
> documents = SimpleDirectoryReader('./docs').load_data()
>
> print("正在创建索引...")
> # from_documents方法包含切片与建立索引步骤 index = VectorStoreIndex.from_documents(
> documents,
> # 指定embedding 模型
> embed_model=DashScopeEmbedding(
> # 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hw
> model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
> )) print("正在创建提问引擎...") query_engine = index.as_query_engine(
> # 设置为流式输出
> streaming=True,
> # 此处使用qwen-plus-0919模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5u
> llm=OpenAILike(
> model="qwen-plus",
> api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
> api_key=os.getenv("DASHSCOPE_API_KEY"),
> is_chat_model=True
> )) print("正在生成回复...") streaming_response = query_engine.query('内容开发工程师岗位用到的内容创作工具有哪些') print("回答是:")
> # 采用流式输出 streaming_response.print_response_stream()
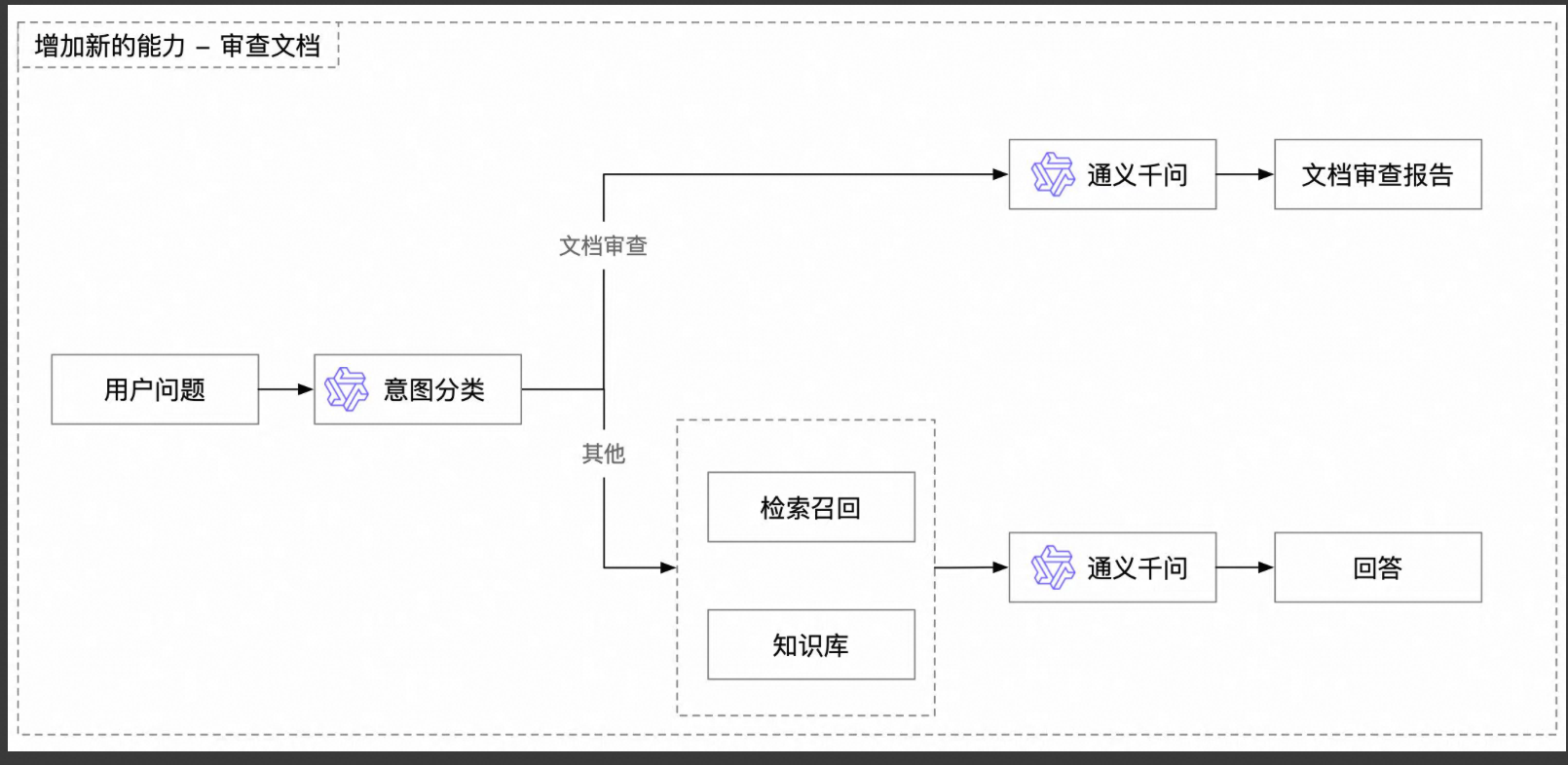
这个意图分类需要一个模型去做,然后走分支流程,类似于Agent概念。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)