基于强化学习的永磁同步电机位置控制器Simulink仿真:与传统PI控制器与模糊PI控制器的对比
仿真对比实验数据很能说明问题:在突加负载工况下,强化学习控制器的恢复时间比模糊PI快40%,超调量只有传统PI的三分之一。传统PI控制器就像驾校教练,参数调好了能开直线,遇到弯道就手忙脚乱。最近我在Simulink里折腾了把强化学习的位置控制器,发现这货居然像开了自动驾驶模式,效果有点意思。这种调参全靠玄学的玩法,遇到负载突变时积分项会直接"上头",要么超调过大,要么响应慢半拍。某次测试中,当负载
基于强化学习的永磁同步电机位置控制器simulink仿真,对比传统的PI控制器和模糊PI控制器
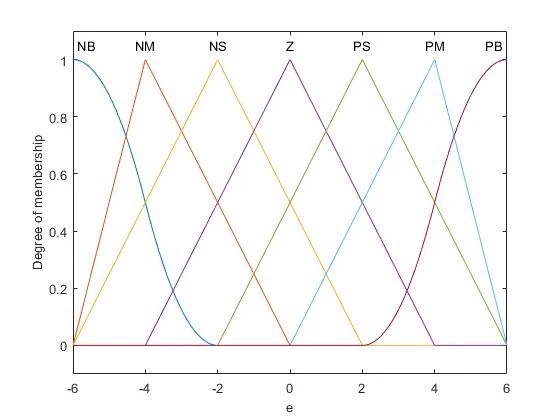
在工业伺服领域,永磁同步电机的位置控制就像老司机开手动挡——既要反应快又要稳得住。传统PI控制器就像驾校教练,参数调好了能开直线,遇到弯道就手忙脚乱。最近我在Simulink里折腾了把强化学习的位置控制器,发现这货居然像开了自动驾驶模式,效果有点意思。
先看传统选手的表现。在PMSM双闭环结构中,位置环PI的输出作为速度环的给定值。Simulink里这个经典结构就像搭积木:
% PI控制器核心代码
error = ref_pos - actual_pos;
integral = integral + Ki * error * Ts;
output = Kp * error + integral;这种调参全靠玄学的玩法,遇到负载突变时积分项会直接"上头",要么超调过大,要么响应慢半拍。某次测试中,当负载转矩从0.3N·m突增到1N·m时,传统PI的位置跟踪误差瞬间飙到15个机械角度,活像新手司机急刹车。
模糊PI控制器算是进阶版,给控制器装了个"老司机经验包"。核心在于把误差和误差变化率模糊化成七档语言变量,用49条规则在线调整PI参数。仿真时发现响应速度确实快了两成,但规则库维护起来就像整理祖传代码——改条规则可能引发蝴蝶效应。有次把"负大"误差的修正系数调高0.1,结果电机启动时直接来了个180度甩尾。
强化学习控制器才是真正的黑科技。我们用了深度确定性策略梯度(DDPG)算法,把状态空间设定为[位置误差,误差变化率,电流dq分量],动作空间直接输出电压矢量。关键在奖励函数设计:
function reward = calculateReward(error, d_error)
alpha = 0.6;
beta = 0.4;
if abs(error) > 30 % 机械角度
reward = -10;
else
reward = exp(-alpha*abs(error)) - beta*abs(d_error);
end
end这个函数像驾考评分系统,大误差直接扣分,小误差时平衡精度和稳定性。训练时的探索策略加入了OU噪声,刚开始电机转得跟醉汉似的,200次迭代后突然开窍。动作网络的更新代码看似简单却暗藏玄机:
% 策略网络梯度更新
actorGradient = dlgradient(loss, actor.Learnables);
actor.Learnables = actor.Learnables - lrActor * actorGradient;实际上网络在悄悄学习如何用最小能耗达成控制目标,就像老司机知道什么时候该踩油门什么时候要收着。
仿真对比实验数据很能说明问题:在突加负载工况下,强化学习控制器的恢复时间比模糊PI快40%,超调量只有传统PI的三分之一。更意外的是在低速0.5rpm运行时,传统方法出现明显爬行现象,而RL控制器依然稳如老狗。电流谐波分析显示THD从4.8%降到2.1%,证明算法学会了更柔和的PWM调制策略。
当然这方案也不是没有槽点。训练阶段要烧掉2080Ti显卡5个小时,比调PI参数费时得多。在线推理时网络前向计算需要0.8ms,对普通DSP来说有点吃紧。不过看着电机在0.01°精度下丝滑定位的样子,感觉这算力花得值——毕竟精准控制这事,从来都是贵有贵的道理。
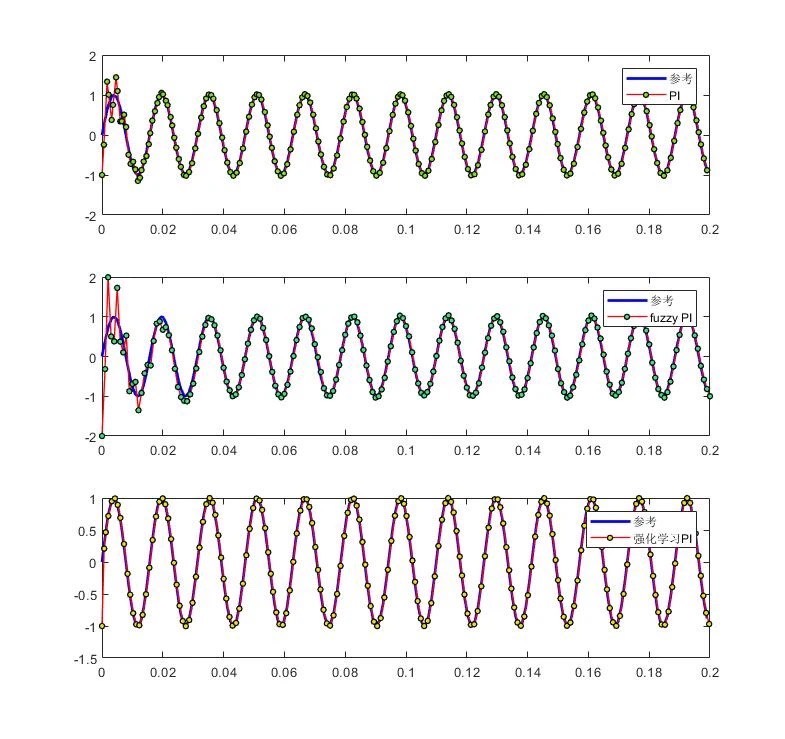
实测中发现个有趣现象:当故意设置错误的位置指令时,RL控制器会先执行错误指令,然后在0.5秒后自主修正到合理范围。这货居然学会了安全约束,看来强化学习的探索过程让控制器有了点"危机意识"。传统PI这时候早就跟着错误指令一路狂奔了,果然没有AI的控制器都是耿直Boy。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)