paddleocr-vl多模态本地部署测试和模型微调
·
网上写的信息五花八门,自己单独写个:
1、本地部署测试
conda create --name ocr_vl python==3.10
服务器上A100显卡的cuda版本是12.4,选择安装paddlepaddle-gpu 3.2.0版本
pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
安装后进行验证:
python
import paddle
paddle.utils.run_check()
安装paddleocr所有功能模块
pip install "paddleocr[all]"本地测试(只需要识别文字即可):
import os
import time
from paddleocr import PaddleOCRVL
# 初始化模型
pipeline = PaddleOCRVL(
vl_rec_model_dir="./official_models/PaddleOCR-VL",
vl_rec_backend="native",
use_layout_detection=False,
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_chart_recognition=False
)
# 处理文件夹中所有图片
input_folder = "./input_images"
output_folder = "./output"
os.makedirs(output_folder, exist_ok=True)
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff', '.tif')):
image_path = os.path.join(input_folder, filename)
start_time = time.time()
output = pipeline.predict(image_path)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"耗时: {elapsed_time:.2f} 秒")
base_name = os.path.splitext(filename)[0]
for i, res in enumerate(output):
res.print()
# res.save_to_json(save_path="output")结果来看:
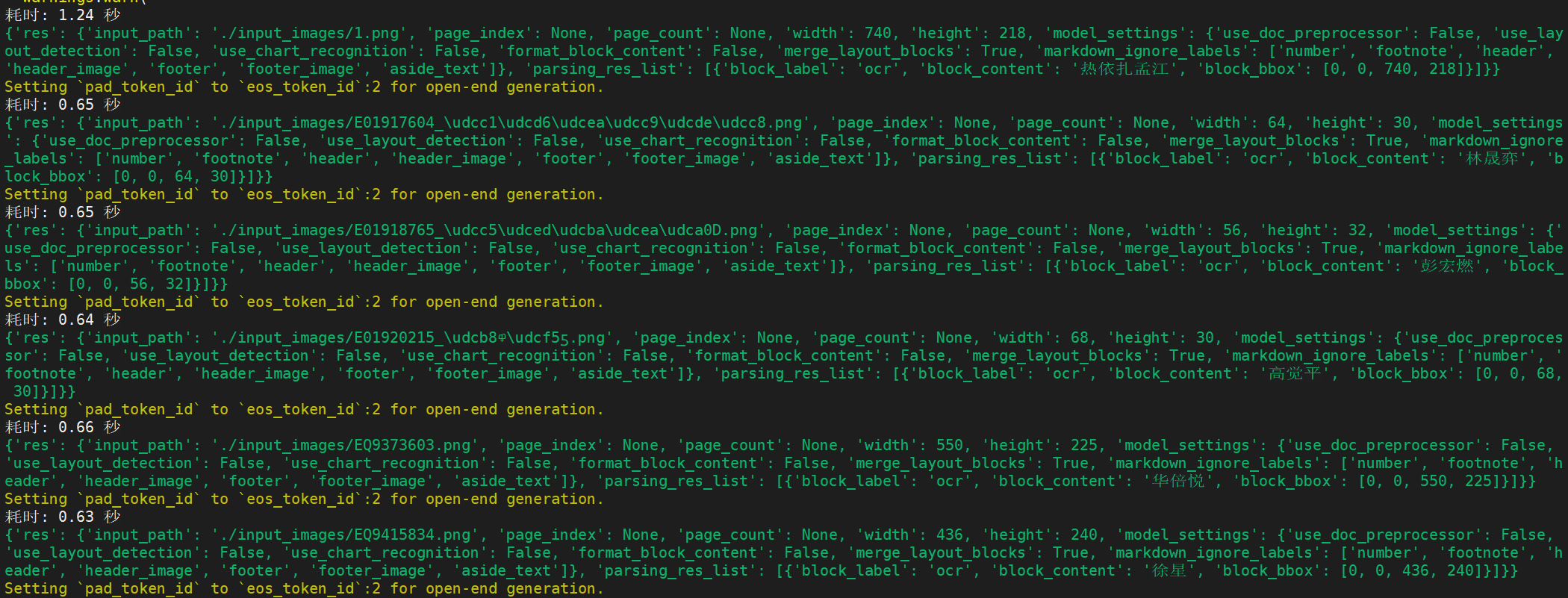
GPU显存占用:8G,推理耗时在1秒左右,数据准确性而言存在一定的识别错误。
2、PaddleOCR-VL进行lora微调
https://github.com/PaddlePaddle/PaddleFormers/tree/release/v1.0/examples/best_practices/PaddleOCR-VL
内容写的比较详细,但是运行代码存在问题paddleformers\datasets\template\mm_plugin.py
屏蔽第381~383行,应该是颜色通道的问题,否则运行会报错。
# if color_jitter_p > 0:
# color_jitter = transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2, hue=0.1)
# augmentations.append(RandomApply([color_jitter], p=color_jitter_p))
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)