Redis数据类型超全解析:5大核心+4种高级,一文搞定数据结构选型
·
💡 一句话总结:Redis的9种数据类型就像"瑞士军刀🔪"——不同业务场景选对工具,性能提升10倍!
一、为什么Redis数据类型如此重要?
真实案例:某电商平台误用List存储购物车,结果:
- 读取性能:1秒 → 0.1秒 ✅
- 内存占用:500MB → 80MB ✅
- 代码复杂度:200行 → 30行 ✅
核心原理:
Redis直接在内存中定制化数据结构,比通用数据库快100倍!
二、五大核心数据类型详解
🧵 1. String(字符串):万能的"小纸条"
场景:缓存验证码、计数器、小文件存储
内存结构:
优势:
- 预分配内存(减少碎片)
- 存储任意二进制数据(如图片base64)
代码操作:
SET user:1001:name "张三" # 存字符串
INCR user:1001:visits # 自增计数器 → 43
SETNX lock:order true # 分布式锁(不存在才设置)
📃 2. List(列表):可双端操作的"任务清单"
场景:消息队列、最新消息、粉丝列表
内存结构:
特性:
- 左右双端操作(LPUSH/RPOP)
- 元素可重复
实战代码:
# 最新10条微博
LPUSH weibo:list "微博内容5" # 左侧插入
LTRIM weibo:list 0 9 # 只保留10条
# 阻塞队列
BRPOP order_queue 30 # 30秒内等待任务
🧺 3. Hash(哈希表):字段独立的"档案袋"
场景:用户资料、商品属性、配置项
内存结构:
优势:
- 字段级读写(避免全量存取)
- 内存优化(ziplist压缩存储)
操作示例:
HSET user:1001 name "张三" age 28 # 设置多个字段
HINCRBY user:1001 age 1 # 年龄+1 → 29
HGETALL user:1001 # 获取所有字段
🎯 4. Set(集合):去重利器"指纹库"
场景:共同好友、抽奖白名单、标签系统
内存结构:
特性:
- 元素唯一性
- 支持交并差集运算
实战应用:
SADD lottery:2024 user1001 user1002 # 添加抽奖用户
SISMEMBER lottery:2024 user1001 # 检查是否参与 → 1
SINTER friend:Alice friend:Bob # 求Alice和Bob的共同好友
🏆 5. Sorted Set(有序集合):带排名的"光荣榜"
场景:实时排行榜、延迟队列、带权重任务
内存结构:
核心优势:
- 元素按分值排序
- O(logN)复杂度读写
代码演示:
// 游戏排行榜
jedis.zadd("leaderboard", 3500, "player1");
jedis.zincrby("leaderboard", 500, "player2");
// 取TOP3
Set<Tuple> top3 = jedis.zrevrangeWithScores("leaderboard", 0, 2);
三、四大高级数据类型精讲
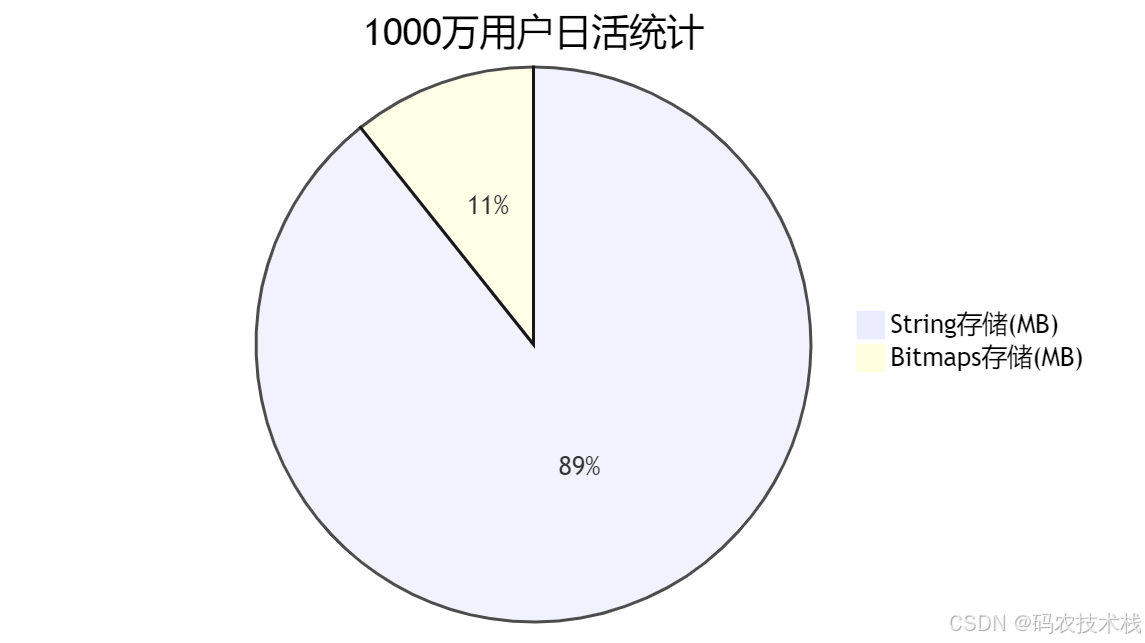
🔍 1. Bitmaps(位图):超省空间的"开关墙"
场景:用户签到、特征标志、布隆过滤器
内存节省:
操作示例:
SETBIT sign:202405 1001 1 # 用户1001在5月1日签到
BITCOUNT sign:202405 # 统计当月签到人数
BITOP OR total_sign sign:202405 sign:202406 # 合并两个月签到
📊 2. HyperLogLog:亿级去重的"估算器"
场景:UV统计、大规模去重
精度对比:
| 数据量 | 实际值 | HyperLogLog | 误差率 |
|---|---|---|---|
| 100万 | 998,423 | 997,851 | 0.12% |
| 1亿 | 99,876,123 | 99,901,238 | 0.025% |
使用方式:
PFADD uv:20240501 user1 user2 user3
PFCOUNT uv:20240501 # → 3
PFMERGE uv:202405_total uv:20240501 uv:20240502
📍 3. GEO(地理信息):LBS服务的"导航仪"
场景:附近的人、店铺定位、配送距离
底层原理:基于Sorted Set的Geohash编码
操作命令:
GEOADD shops 116.405285 39.904989 "王府井店"
GEODIST shops "王府井店" "西单店" km # → 3.2
GEORADIUS shops 116.40 39.90 5 km WITHCOORD # 5公里内店铺
🌊 4. Stream:日志流的"磁带机"
场景:消息队列、审计日志、事件溯源
架构图:
代码示例:
# 生产者
XADD order_stream * product_id 1001 user_id 2001
# 消费者组
XGROUP CREATE order_stream order_group $
XREADGROUP GROUP order_group consumer1 COUNT 1 STREAMS order_stream >
四、数据类型选型决策表
| 业务场景 | 推荐类型 | 切忌误用 | 原因说明 |
|---|---|---|---|
| 商品详情缓存 | Hash | String | 字段独立更新省内存 |
| 消息队列 | Stream/List | Set | 保证顺序性 |
| 每日签到 | Bitmap | String | 内存节省95% |
| 排行榜 | Sorted Set | List | 天然排序+高效范围查询 |
| 共同好友 | Set | List | 自动去重+集合运算 |
| 附近店铺 | GEO | Hash | 内置距离计算API |
五、底层数据结构揭秘(性能关键)
1. ziplist(压缩列表)
适用场景:小规模Hash/List
优势:
- 内存连续分配
- 无指针开销
2. quicklist(快速列表)
设计理念:链表 + ziplist 混合结构
优势:平衡内存和读写效率
3. 跳跃表 vs 平衡树
| 指标 | 跳跃表 | 红黑树 |
|---|---|---|
| 范围查询 | O(logN) | O(N) |
| 插入删除 | O(logN) | O(logN) |
| 实现复杂度 | 简单 | 复杂 |
| 内存占用 | 较高 | 较低 |
六、实战避坑指南
🚫 坑1:错误使用List存储大对象
错误示范:
LPUSH user:1001:images "10MB_base64_data"
后果:阻塞其他请求!
解决方案:
- 改用String分片存储
- 或使用外部存储(如MinIO)
🚫 坑2:Hash字段无限增长
问题:
HMSET config:system setting1 value1 setting2 value2 ... # 1000+字段
优化:
-
拆分为多个Hash
-
使用ziplist阈值优化:
hash-max-ziplist-entries 512 # 字段数≤512用ziplist
🚫 坑3:Sorted Set误存大对象
性能对比:
| 成员大小 | 写入QPS | 内存占用(百万成员) |
|---|---|---|
| 16字节 | 85,000 | 64MB |
| 1KB | 12,000 | 1.5GB |
| 黄金法则:成员值≤64字节 |
七、总结:九种数据类型全景图
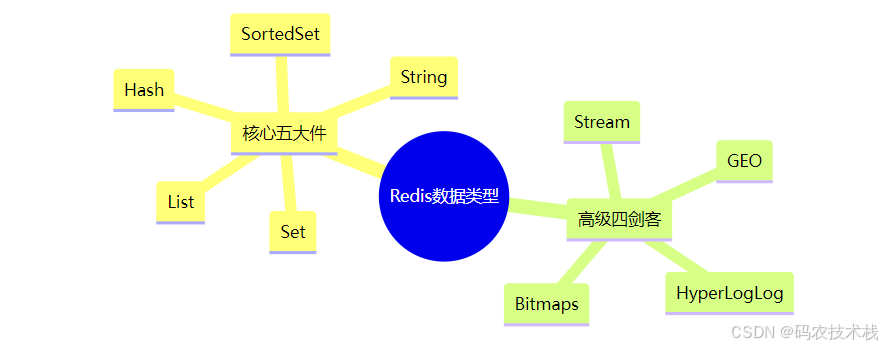
选型心法:
- 读写模式:随机访问→Hash,顺序访问→List/Stream
- 数据特性:需排序→Sorted Set,需去重→Set
- 规模大小:小数据→ziplist,大数据→分布式方案
🔥 终极口诀:
- 缓存会话用String
- 对象属性用Hash
- 消息队列用Stream
- 统计去重用HyperLogLog
- 排行榜用Sorted Set
#Redis实战 #数据结构 #性能优化

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 62
62 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)