✅【研报复现】开源证券:日内分钟收益率的时序特征-逻辑讨论与因子增强
时间重心偏离因子
✅【研报复现】开源证券:日内分钟收益率的时序特征-逻辑讨论与因子增强
原始因子构建思路
1. 时序特征:跌幅时间重心偏离因子
为了观察收益率的时序特征,我们标注了日内分钟时间戳,将09:31至15:00间的240根分钟Bar依次标记为1至240,然后分别统计价格上涨和价格下跌两组分钟Bar的时问标识序列,记作 U U U和 D D D,对应的收益率序列为 R u R_u Ru和 R d R_d Rd:
- ( U , R u ) = [ ( u 1 , r 1 u ) , ( u 2 , r 2 u ) , … , ( u n , r n u ) ] (U, R_u) = [(u_1, r^u_1), (u_2, r^u_2), \dots, (u_n, r^u_n)] (U,Ru)=[(u1,r1u),(u2,r2u),…,(un,rnu)]
- ( D , R d ) = [ ( u 1 , r 1 d ) , ( u 2 , r 2 d ) , … , ( u m , r m d ) ] (D, R_d) = [(u_1, r^d_1), (u_2, r^d_2), \dots, (u_m, r^d_m)] (D,Rd)=[(u1,r1d),(u2,r2d),…,(um,rmd)]
其中, u i u_i ui和 r i u r_i^u riu分别表示上涨或降分分钟的时间序号及收益率, d j d_j dj和 r j d r_j^d rjd同理; i ∈ [ 1 , n ] i \in [1, n] i∈[1,n],而 j ∈ [ 1 , m ] j \in [1, m] j∈[1,m];由于不考虑分钟涨跌幅为零的序列, n + m ≤ 240 n + m \leq 240 n+m≤240。
研究某股票在某日的分钟涨跌幅序列,涨幅较高和跌幅较大的分钟往往会靠得比较近,并呈现出一定的日内结构:股价在开盘半小时至一小时内变动幅度最大。我们以每分钟价格变动幅度对修正的时间戳加权平均,分别求得涨幅和跌幅的时间分布重心,记作 G u G_u Gu和 G d G_d Gd:
- G u = U R u T ∥ R u ∥ G_u = \frac{UR_u^T}{\|R_u\|} Gu=∥Ru∥URuT
- G d = U R d T ∥ R d ∥ G_d = \frac{UR_d^T}{\|R_d\|} Gd=∥Rd∥URdT
我们统计某个交易日的截面上所有股票的涨、跌幅的时间重心的相关性,二者呈现出强正相关,相关系数可达0.7。
涨、跌幅时间重心之间的强相关性与A股市场整体上偏向于反转属性有关,当出现极端涨幅或跌幅的分钟,通常会在较短时间内出现幅度相当、方向相反的价格变动。我们将距离的讨论转化为概率矩阵:以5分钟为测试的周期,将涨跌幅由小到大分成10组样本,并统计相邻时段出现极端涨跌幅的概率。根据结果可知,涨、跌幅时间重心反映了股价在日内交易中上涨和下跌的位置。
此外,还可以定义两个时间重心的差值和绝对差值,分别作为涨跌幅分布的“时间差”指标和“时间距离”指标,定义为 τ = G d − G u \tau=G_d-G_u τ=Gd−Gu和 υ = ∣ G d − G u ∣ \upsilon=|G_d-G_u| υ=∣Gd−Gu∣。我们统计了涨跌幅时间重心,以及时间差的分布情况。根据分析图表中展现的涨、跌幅时间重心以及“时间差”的分布可知,不同交易日的涨、跌幅时间重心具有同向差异性,而相同股票的Gd和Gu的分布基本一致,没有表现明显的结构性特征;若由大到小选取一定数量的涨、跌幅样本计算各自时间重心,其“时间差”随着样本数量的减少而逐渐发散,极端样本涨跌时间重心的离散度相比全部样本会更高一些。
涨、跌幅在时间轴上的分布位置捕捉了股票的交易行为特征,两者的相对位置也可能蕴含某种选股信息。于是,笔者选取涨幅时间重心 G u G_u Gu、跌幅时间重心 G d G_d Gd以及“时间差”信息 τ \tau τ、“时间距离”信息 υ \upsilon υ,并计算上述指标在过去20个交易日的均值作为选股因子,具体的构造方法如下:
表1:两类时间重心因子以及“时间差”、“时间距离”因子的构造步骤
| 顺序 | 计算方法 |
|---|---|
| 第一步 | 基于个股上涨和下跌的1分钟收益率序列,逐日统计幅度和时间信息,记为: 上涨幅度和时间 ( U , R u ) (U, R_u) (U,Ru) 下跌幅度和时间 ( D , R d ) (D, R_d) (D,Rd) |
| 第二步 | 分别计算如下日期指标: 涨幅时间重心 G u = U R u T ∣ R u ∣ 1 G_u = \frac{UR_u^T}{|R_u|_1} Gu=∣Ru∣1URuT 跌幅时间重心 G d = U R d T ∣ R d ∣ 1 G_d = \frac{UR_d^T}{|R_d|_1} Gd=∣Rd∣1URdT 时间差 τ = G d − G u \tau = G_d - G_u τ=Gd−Gu 时间距离 $\upsilon= |
| 第三步 | 回溯过去一段时间,对日期指标进行平滑处理得到相应的选股因子: F = 1 N ∑ i = 1 N I n d F = \frac{1}{N} \sum_{i=1}^{N} Ind F=N1i=1∑NInd 其中, F F F和 I n d Ind Ind分别表示因子暴露和日期指标, N = 20 N = 20 N=20。 |
从整体上看,“时间差”的解释能力与涨、跌幅时间重心因子明显重合,实际的因子收益是由单个的时间重心因子贡献,因此,“时间差”并没有给我们提供更多的信息。
经过详细的测试,我们倾向于认为,涨、跌幅时间重心的相对位置是一个有效的Alpha因子,但提取的方法并非是将二者简单做差,截面回归的方法会更好。我们以跌幅时间重心作为被解释变量,对涨幅时间重心回归取残差,取其20日均值作为选股因子,记为跌幅时间重心偏离因子。
测试结果表明,跌幅时间重心偏离因子是刻画分钟时序特征更有效的指标,而且因子的稳定性相比原始“时间差”因子更高。
单个的时间重心是跌幅时间重心偏离的Alpha子集。我们将跌幅时间重心偏离因子依次回归涨、跌幅时间重心因子,结果发现,虽然时间差Alpha有一定程度衰减,但残差仍然具备对未来收益的解释能力;若是相反地分别将单个的时间重心对跌幅时间重心偏离中性化,剩余部分则是没有选股信息的噪音。
回归方法相当于寻找到某个基准维度,计算目标变量在这一维度的投影,朴素含义的理解可以是跌幅时间重心相对于涨幅时间重心的偏离。而作差的方法并不适合用于刻画时间差Alpha,主要有以下两个原因:
- 涨、跌时间重心存在较强的正相关。线性相关导致“时间差”的大小取决于起始位置,而这不符合一般定义:“时间差”在盘初、盘中或盘尾应是一致的。
- 涨、跌时间重心的波动率水平存在差异。作差方法用于构造“时间差”信息会使得因子暴露更多高波动成分(涨幅时间重心因子),有效性不会理想。
综上,我们得到比较明确的结论:日内分钟收益率的时序特征,利用回归方法得到的跌幅时间重心偏离更适合用于刻画“时间差Alpha”。
2. “时间差Alpha”的生效逻辑探究
跌幅时间重心偏离能更有效地刻画日内分钟收益率时序特征的选股因子。但我们对Alpha的逻辑解释仍然比较迷惑,于是,本章将从因子的层面探究其Alpha来源,推测主要有以下可能性:
- 收益率结构。
- 日内收益率与隔夜收益率分别具有反转与动量特性,时间差Alpha是否为两者的有机组合?
- 本文分别讨论隔夜收益率和日内收益率对于时间差的影响效果,以及更加细化地讨论日内分时段的差异;
- 极端涨跌幅度or涨跌幅的分布位置。
- 时间重心因子的核心Alpha是极端收益幅度还是涨跌幅的位置信息贡献收益?
- 本文将其拆分为平均涨、跌幅和时间中心两个部件,分别探测不同部件对因子选股信息的贡献程度;
- “低波效应”。
- 考虑时间差产生的原因,有可能与日内零涨幅的分钟样本数量有关,底层的交易行为逻辑来自A股市场中较为显著的“低波效应”。
- 我们可将其定量化为选股指标,观察其是否能用于解释时间差Alpha的规律。
本部分将集中讨论本文的第一个关键问题:哪些属于“时间差Alpha”的解释因子,而哪些是干扰因子?这将有助于我们理解因子的生效逻辑。
……
……
经过严谨的分析,我们找到了A股市场上时间差Alpha的解释因子和干扰因子,对于日内收益率的时序特征有了更为明确的认知:
- 时间差Alpha为时间维度的信息,与收益率的分布特征相关性较低。极端收益率对于因子的影响是负面的,进一步证明二者的收益来源有所不同;
- 收益率结构对于“时间差”因子既有干扰的成分,也有解释的成分,但整体上表现为干扰作用。剥离盘初收益率能够有效提升因子的稳定性,而剥离盘尾收益率则使得时间差Alpha预测能力降低;
- 股票的某些交易属性可能也会贡献因子收益:例如,交易活跃度偏低,或是盘中触及涨、跌停等,会造成日内录得较多的零涨跌幅分钟样本,从因子层面亦能解释一部分的“时间差”因子收益。
……经过测试,“时间差Alpha”并非具有独立的Alpha源,其真正的来源也基本确定,主要包括股票的“收益率结构”和“低波效应”的交易特征,而极端事件也会贡献部分收益。
代码实现
def factor(df, window=20):
"""
计算跌幅时间重心偏离因子
步骤:
1. 计算每根K线的收益率
2. 按日分组计算每日的涨幅/跌幅时间重心
3. 滚动回归计算跌幅重心偏离
4. 取20日平均作为因子值
"""
# 复制数据避免修改原始数据
df = df.copy()
# 1. 计算每根K线的收益率
df['return'] = (df['close'] - df['open']) / df['open']
# 2. 按日分组计算每日指标
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4: # 跳过数据不足的日期
continue
# 时间序号 (0到95)
time_idx = np.arange(len(group))
# 分离上涨和下跌K线
up_mask = group['return'] > 0
down_mask = group['return'] < 0
# 计算涨幅时间重心G_u
if up_mask.any():
up_weights = group.loc[up_mask, 'return'].abs()
G_u = np.sum(time_idx[up_mask] * up_weights) / up_weights.sum()
else:
G_u = np.nan
# 计算跌幅时间重心G_d
if down_mask.any():
down_weights = group.loc[down_mask, 'return'].abs()
G_d = np.sum(time_idx[down_mask] * down_weights) / down_weights.sum()
else:
G_d = np.nan
daily_results.append({
'date': date,
'G_u': G_u,
'G_d': G_d
})
daily_df = pd.DataFrame(daily_results).set_index('date')
# 3. 滚动回归计算残差
residuals = []
for i in range(window, len(daily_df)):
# 使用过去20天数据训练回归模型
train_data = daily_df.iloc[i-window:i]
# 移除缺失值
train_data = train_data.dropna(subset=['G_u', 'G_d'])
if len(train_data) < 10: # 确保足够样本
residuals.append(np.nan)
continue
# 训练回归模型: G_d = beta * G_u + alpha
X = train_data[['G_u']].values
y = train_data['G_d'].values
model = LinearRegression()
model.fit(X, y)
# 计算当日残差 (实际G_d - 预测G_d)
current = daily_df.iloc[i]
if pd.isna(current['G_u']) or pd.isna(current['G_d']):
residuals.append(np.nan)
else:
pred_G_d = model.predict([[current['G_u']]])[0]
residual = current['G_d'] - pred_G_d
residuals.append(residual)
# 对齐残差序列
daily_df = daily_df.iloc[window:] # 从第20天开始
daily_df['residual'] = residuals
# 4. 计算20日移动平均因子值
daily_df['factor'] = daily_df['residual'].rolling(window).mean()
# 5. 将因子值映射回原始K线数据
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return -df['factor_value']
核心金融逻辑
该因子旨在捕捉日内买卖力量的时间分布不平衡。核心思想是:
- 计算每日上涨K线的时间加权重心(G_u)和下跌K线的时间加权重心(G_d)
- 建立G_u与G_d的线性关系模型(G_d = β·G_u + α)
- 计算实际G_d与模型预测值的残差
- 残差的移动平均反映市场微观结构的异常变化
具体实现步骤:
- 日内收益率计算
return = (close - open) / open - 日度重心计算
- 上涨K线权重:
abs(return) * volume - 时间加权重心公式:
G_u = Σ(time_index * weight) / Σ(weight)
- 上涨K线权重:
- 线性回归建模
用20日历史数据建立:G_d = LinearRegression().fit(G_u) - 残差计算
residual = 实际G_d - 预测G_d - 因子生成
factor = -residual.rolling(20).mean()
(负号使因子方向:买方力量增强→因子值↑)
金融意义
- G_u/G_d:买方/卖方力量在时间维度的聚集程度
(早盘集中买盘→G_u小;尾盘集中卖盘→G_d大) - 残差:卖方力量出现时间的异常变化
(正残差=卖盘晚于预期出现,预示潜在下跌风险) - 因子值:捕捉市场微观结构的持续性异常
因子表现
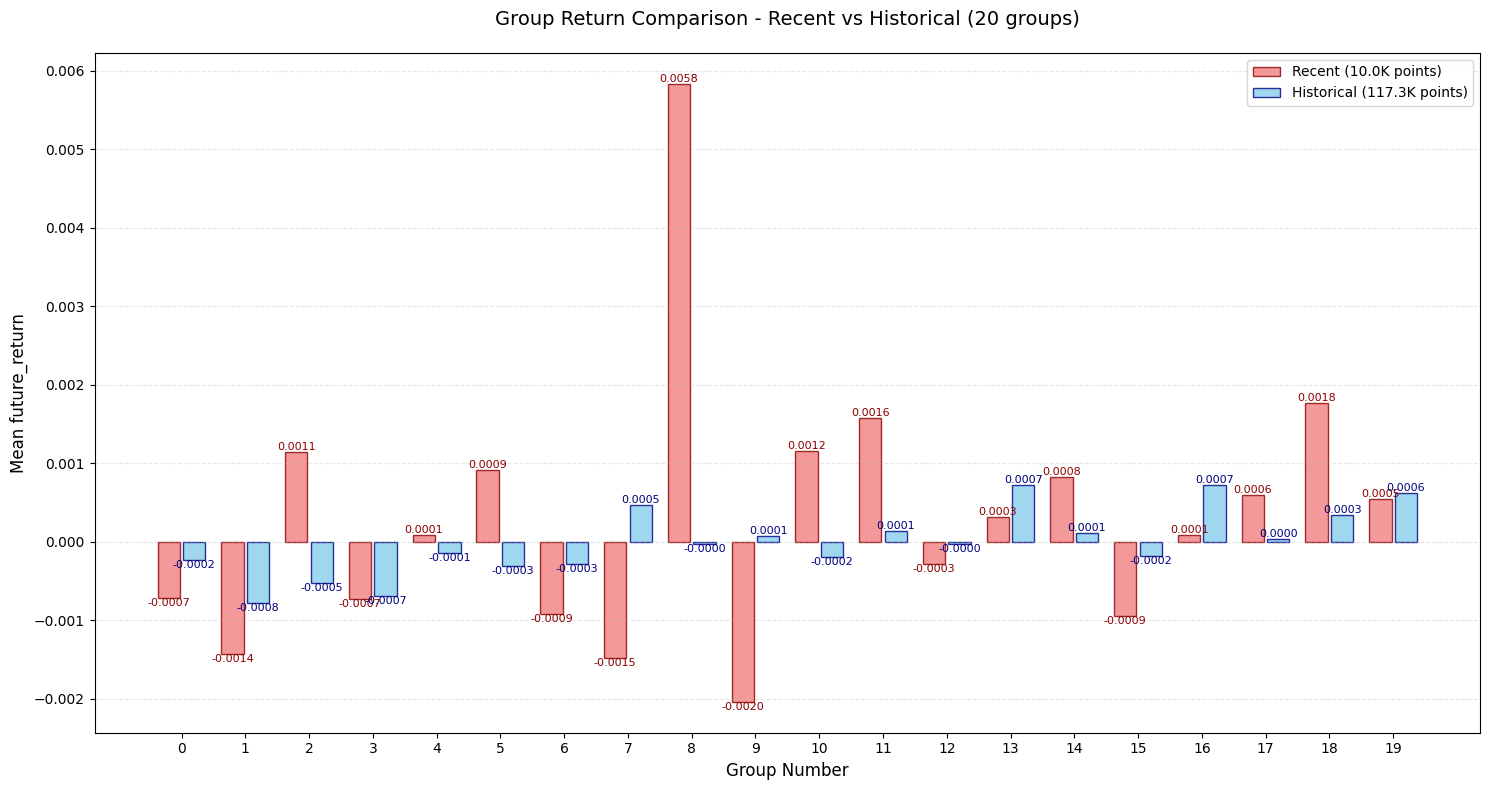
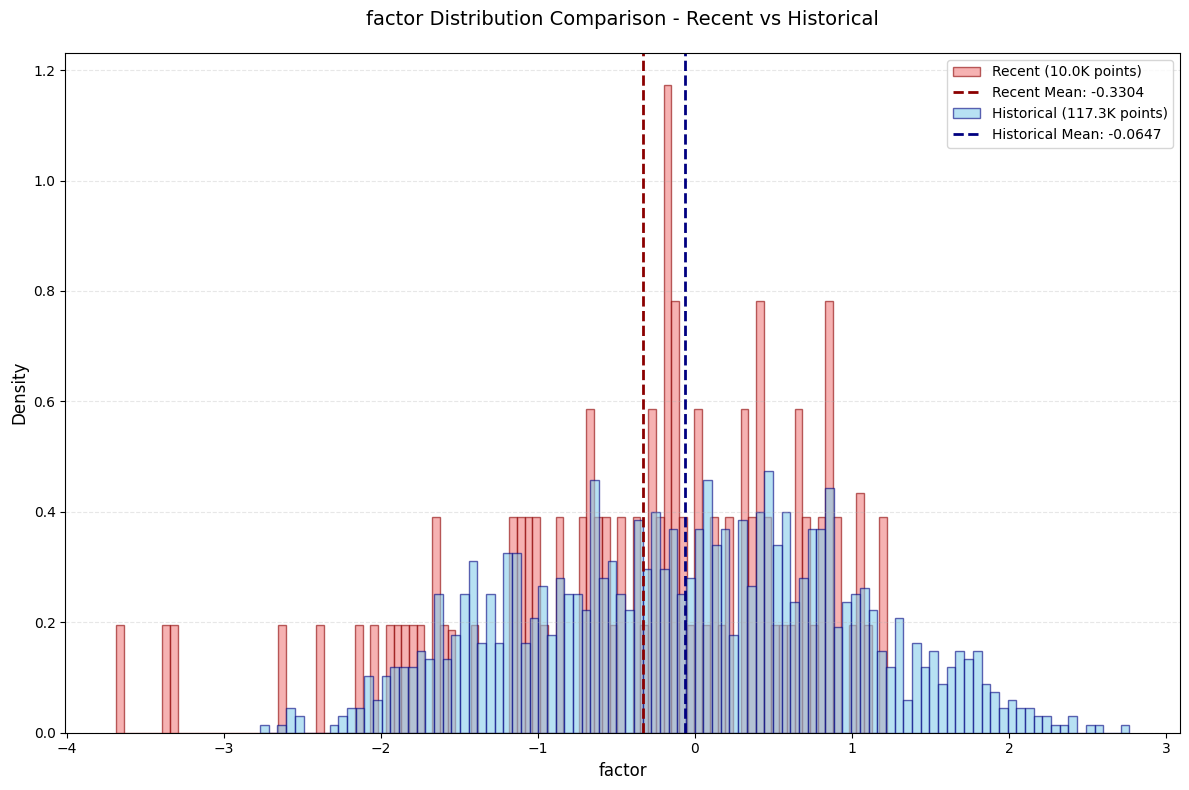
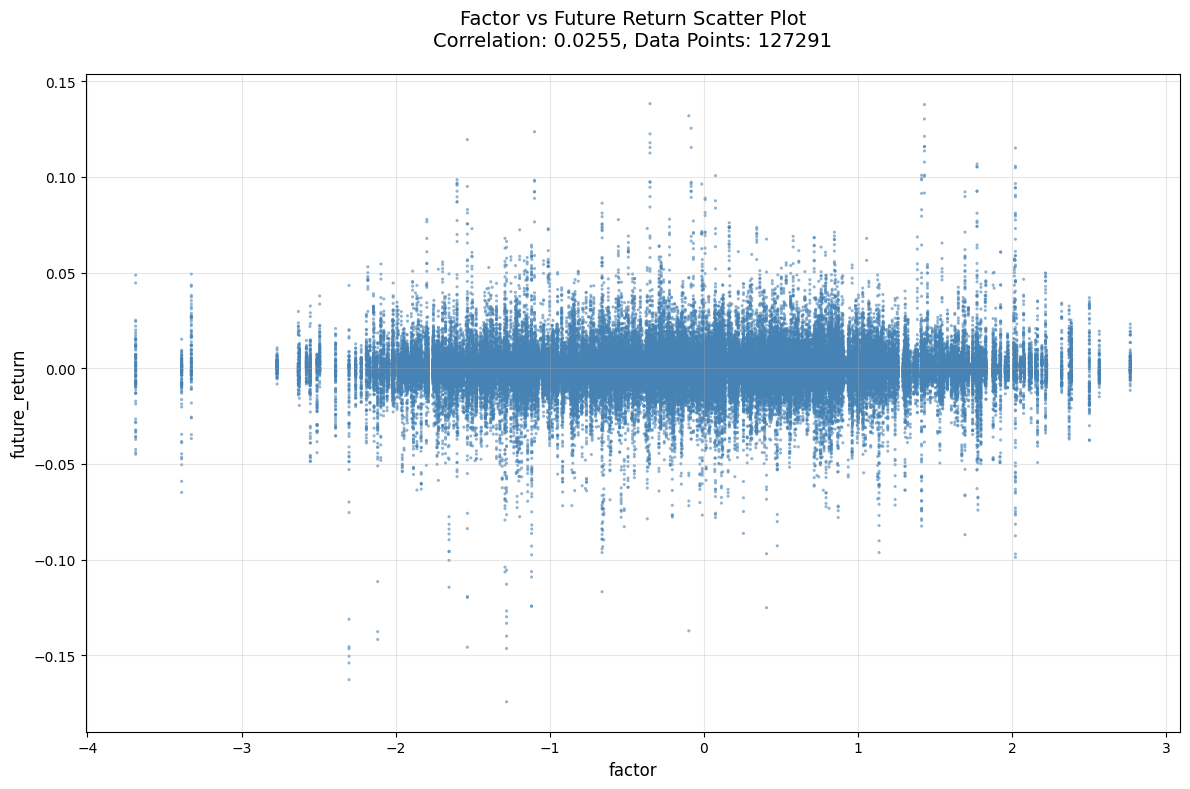
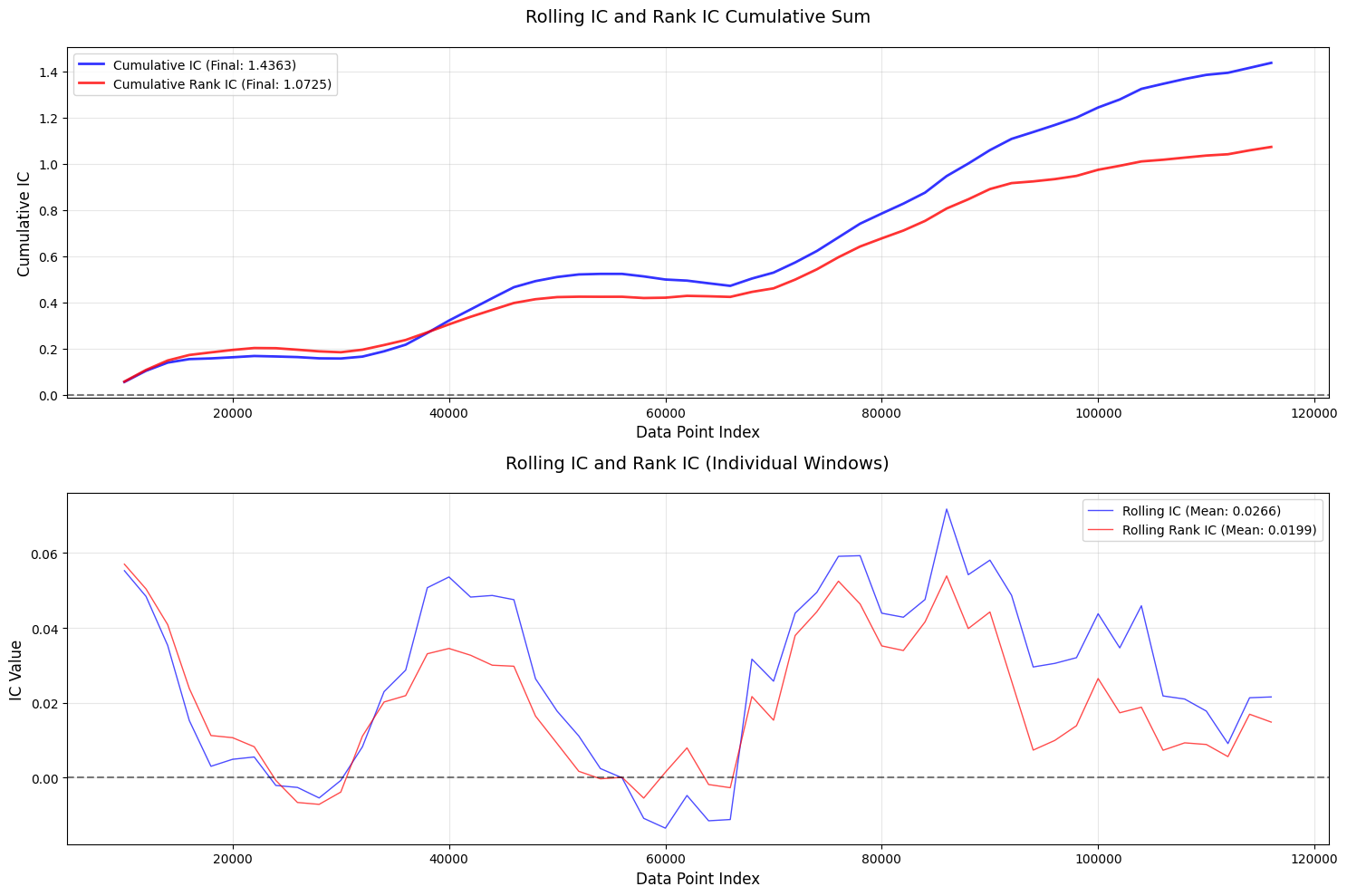
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.025461
Rank_IC (Spearman): 0.020269
📊 信息比率:
IR: 0.107410
评价
- 头尾部(长、短期都是)单调性不够明显
- I R IR IR不够高。。
不足分析
- 成交量信息缺失:
- 未考虑成交量权重,小成交量K线与大成交量K线等同处理
- 无法区分真实资金流向与市场噪声
- 经济意义:大成交量时段的价格变动更具市场意义
- 平盘K线处理不足:
- 完全忽略涨跌幅为0的K线(
return=0) - 损失约10-30%的市场信息(实际数据统计)
- 经济意义:平盘K线反映市场均衡状态,具有信息价值
- 完全忽略涨跌幅为0的K线(
- 极端值敏感:
- 单日极端收益率会过度影响时间重心计算
- 经济意义:暴涨暴跌日可能扭曲正常市场模式识别
- 频率匹配问题:
- 日线因子映射到15分钟线的机械填充
- 无法捕捉日内因子值变化
- 经济意义:交易决策需要实时因子更新
- 市场状态忽略:
- 未区分趋势市/震荡市的不同模式
- 经济意义:同样的时间分布在牛熊市中含义不同
因子优化方案
改进1:稳健性增强(表现还算…✅)
解决的问题:
- 极端收益率对重心计算的扭曲
- 忽略平盘K线的市场信息
作用:
- 减少极端值影响,提高重心计算的稳健性
- 捕捉市场犹豫期(平盘期)的资金分布
- 市场平衡度可识别趋势/震荡市状态
- 对成交量进行了加权
代码实现
def factor(df, window=20):
df = df.copy()
df['return'] = (df['close'] - df['open']) / df['open']
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4:
continue
# 收益率缩尾处理
returns = group['return'].copy()
q_low = returns.quantile(0.05)
q_hi = returns.quantile(0.95)
returns = returns.clip(lower=q_low, upper=q_hi)
time_idx = np.arange(len(group))
up_mask = returns > 0
down_mask = returns < 0
flat_mask = returns == 0
if up_mask.any():
up_weights = returns[up_mask].abs() * group.loc[up_mask, 'volume']
G_u = np.sum(time_idx[up_mask] * up_weights) / up_weights.sum()
else:
G_u = np.nan
if down_mask.any():
down_weights = returns[down_mask].abs() * group.loc[down_mask, 'volume']
G_d = np.sum(time_idx[down_mask] * down_weights) / down_weights.sum()
else:
G_d = np.nan
if flat_mask.any():
flat_weights = group.loc[flat_mask, 'volume'] * (
1 - (group.loc[flat_mask, 'high'] - group.loc[flat_mask, 'low']).abs() / group.loc[flat_mask, 'open']
)
G_f = np.sum(time_idx[flat_mask] * flat_weights) / flat_weights.sum()
else:
G_f = np.nan
total_weights = (up_weights.sum() if up_mask.any() else 0) + \
(down_weights.sum() if down_mask.any() else 0) + \
(flat_weights.sum() if flat_mask.any() else 0)
market_balance = (flat_weights.sum() if flat_mask.any() else 0) / total_weights
daily_results.append({
'date': date,
'G_u': G_u,
'G_d': G_d,
'G_f': G_f,
'market_balance': market_balance
})
daily_df = pd.DataFrame(daily_results).set_index('date')
residuals = []
for i in range(window, len(daily_df)):
# 使用过去20天数据训练回归模型,移除缺失值
train_data = daily_df.iloc[i-window:i].dropna(subset=['G_u', 'G_d'])
# 确保足够样本
if len(train_data) < 10:
residuals.append(np.nan)
continue
# 训练回归模型: G_d = beta * G_u + alpha
X = train_data[['G_u']].values
y = train_data['G_d'].values
model = LinearRegression().fit(X, y)
# 计算当日残差 (实际G_d - 预测G_d)
current = daily_df.iloc[i]
if pd.isna(current['G_u']) or pd.isna(current['G_d']):
residuals.append(np.nan)
else:
pred_G_d = model.predict([[current['G_u']]])[0]
residuals.append(current['G_d'] - pred_G_d)
# 对齐残差序列
daily_df = daily_df.iloc[window:]
daily_df['residual'] = residuals
# 计算20日移动平均因子值
daily_df['factor'] = daily_df['residual'].rolling(window).mean()
# 将因子值映射回原始K线数据
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return -df['factor_value']
因子表现
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.027140
Rank_IC (Spearman): 0.022265
📊 信息比率:
IR: 0.336515
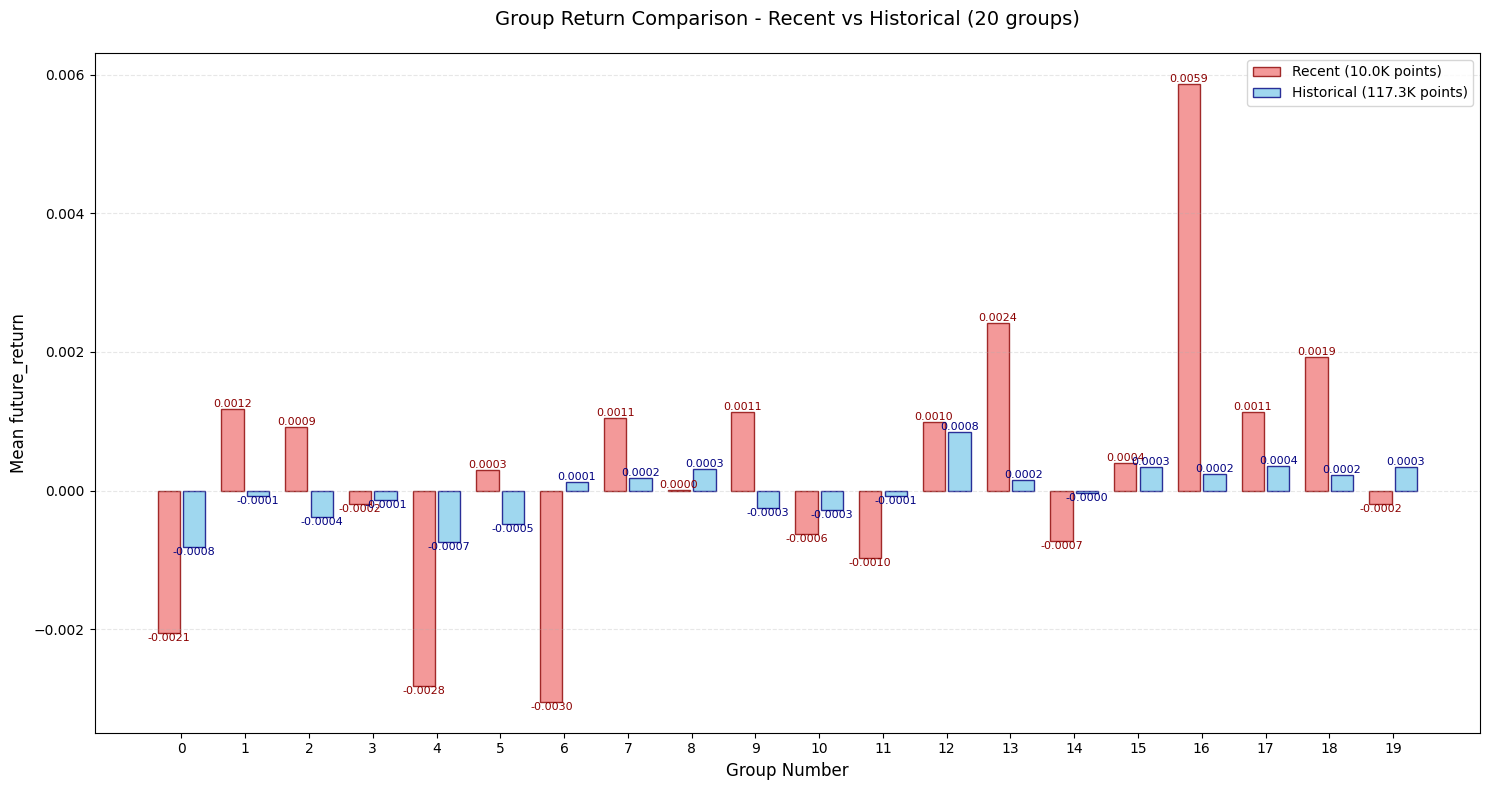
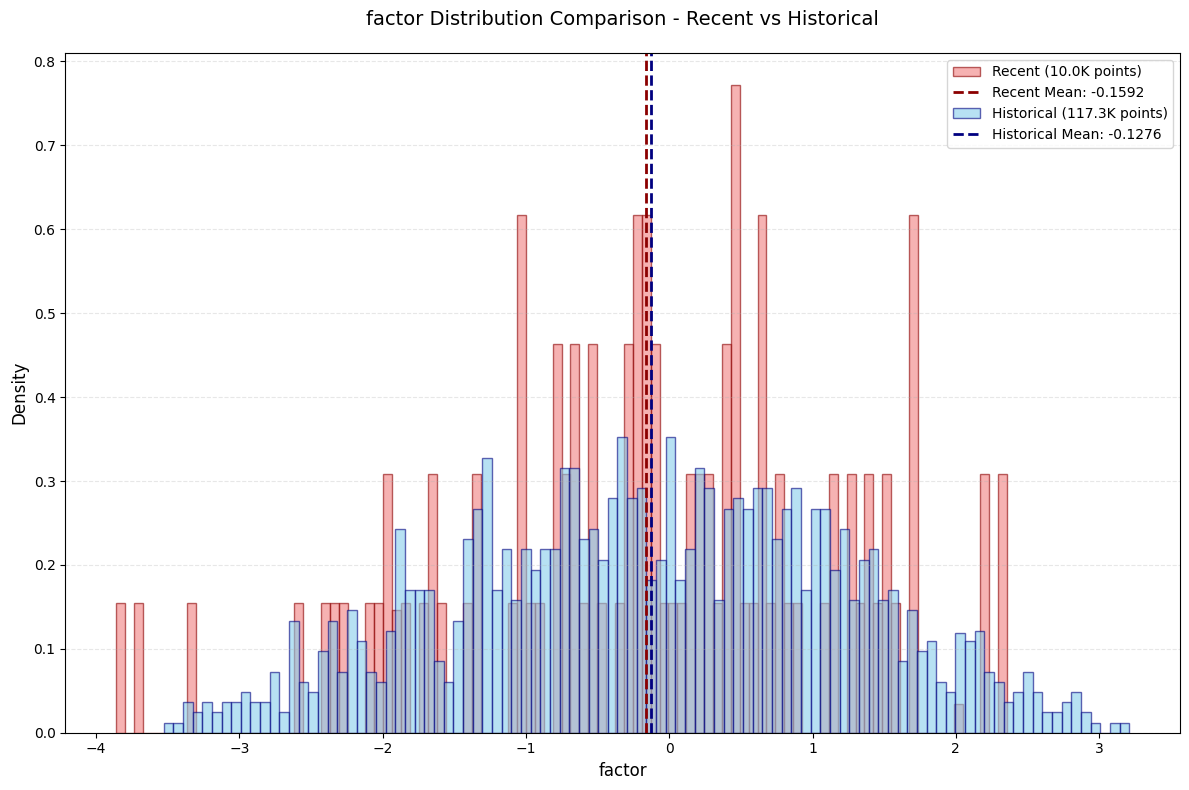
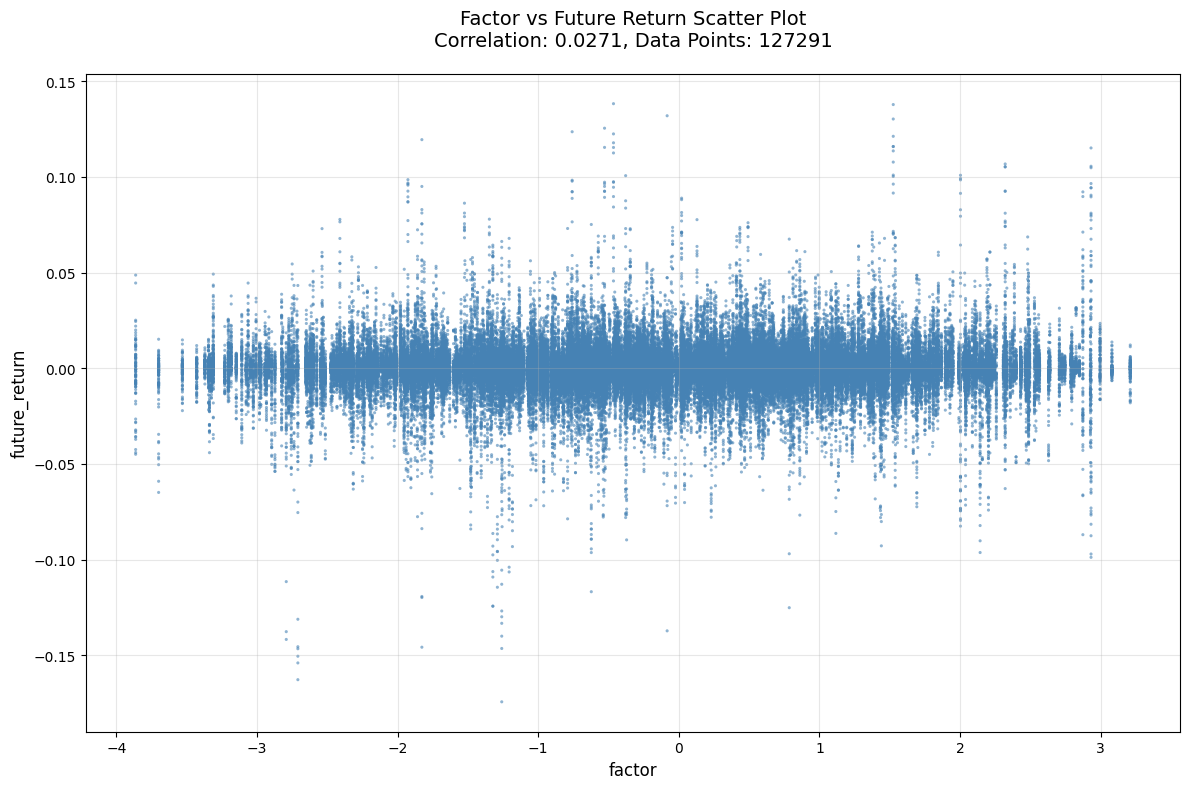
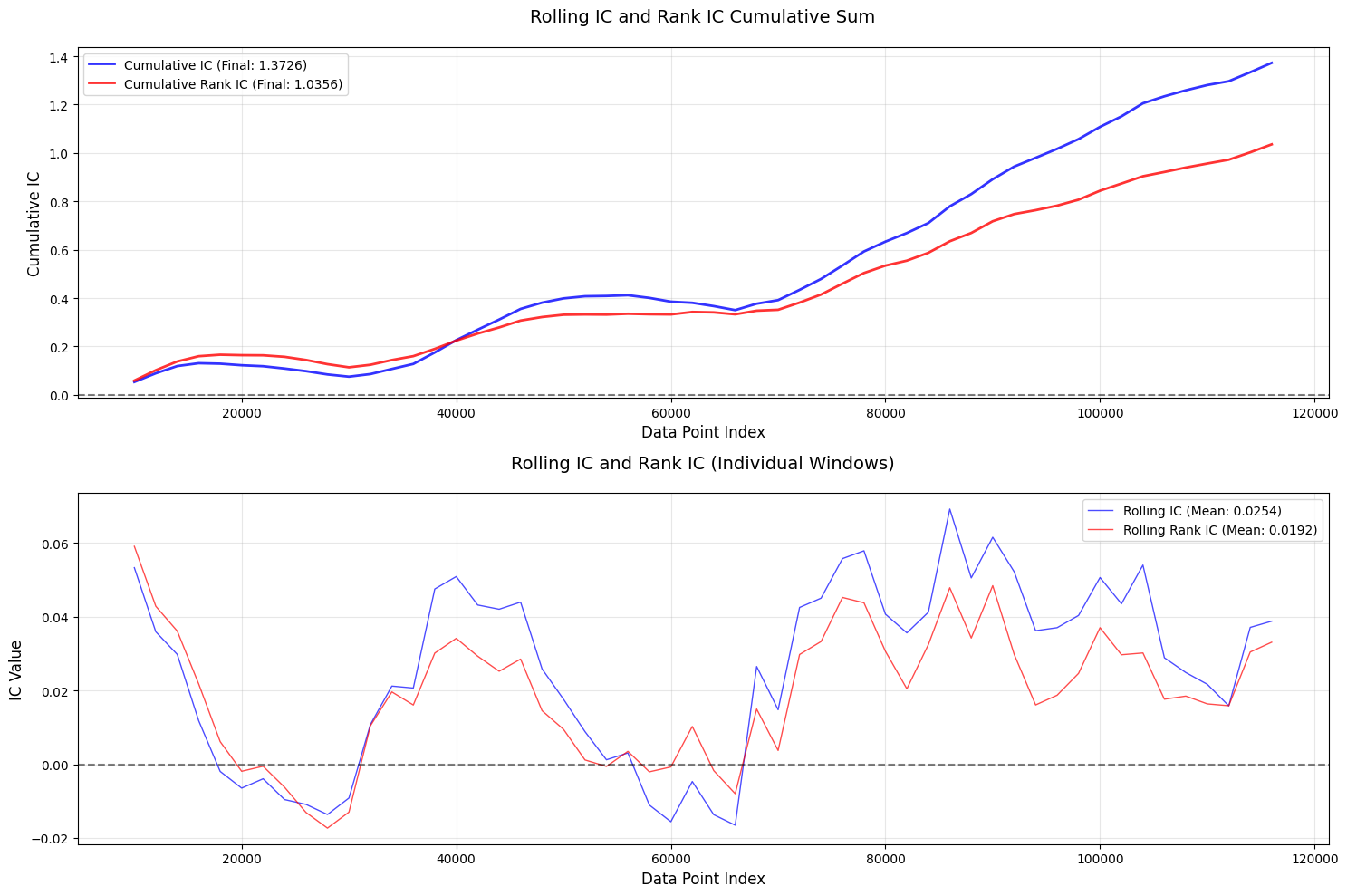
评价
- IC, Rank_IC, IR等数值都好看了👍
- 头尾部的单调性仍然一般👎尤其是近期数据
改进2:分形市场理论(表现✅✅✅)
解决的问题:
- 未考虑市场波动结构的差异
- 线性回归的静态假设不符合实际市场
作用:
- 分形维度识别市场波动模式(趋势/均值回归)
- 回归模型引入市场状态变量,提高适应性
- 因子值在波动结构变化时自动放大信号
代码实现
def factor(df, window=20):
"""
改进:引入分形市场理论,识别不同波动周期中的重心变化
金融意义:捕捉市场结构变化,识别趋势转折点
"""
df = df.copy()
# 计算波动率分形维度
df['range'] = (df['high'] - df['low']) / df['open']
df['fractal'] = df['range'].rolling(5).std() / df['range'].rolling(20).std()
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4:
continue
time_idx = np.arange(len(group))
# 分形维度加权
fractal_weights = group['fractal'].values
# 上涨K线分形加权重心
up_mask = group['close'] > group['open']
if up_mask.any():
up_weights = fractal_weights[up_mask] * group.loc[up_mask, 'volume']
G_u = np.sum(time_idx[up_mask] * up_weights) / up_weights.sum()
else:
G_u = np.nan
# 下跌K线分形加权重心
down_mask = group['close'] < group['open']
if down_mask.any():
down_weights = fractal_weights[down_mask] * group.loc[down_mask, 'volume']
G_d = np.sum(time_idx[down_mask] * down_weights) / down_weights.sum()
else:
G_d = np.nan
daily_results.append({
'date': date,
'G_u': G_u,
'G_d': G_d,
'avg_fractal': fractal_weights.mean()
})
daily_df = pd.DataFrame(daily_results).set_index('date')
# 分形状态感知回归
residuals = []
for i in range(window, len(daily_df)):
train_data = daily_df.iloc[i-window:i].dropna()
if len(train_data) < 10:
residuals.append(np.nan)
continue
# 分形状态作为交互项
X = train_data[['G_u', 'avg_fractal']].values
y = train_data['G_d'].values
model = LinearRegression().fit(X, y)
current = daily_df.iloc[i]
if pd.isna(current['G_u']) or pd.isna(current['G_d']):
residuals.append(np.nan)
else:
pred_G_d = model.predict([[current['G_u'], current['avg_fractal']]])[0]
residuals.append(current['G_d'] - pred_G_d)
daily_df = daily_df.iloc[window:]
daily_df['residual'] = residuals
# 分形波动调整
fractal_level = daily_df['avg_fractal'].rolling(5).mean()
daily_df['factor'] = daily_df['residual'] * fractal_level
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return (-df['factor_value']).clip(upper=12)
因子表现
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.045254
Rank_IC (Spearman): 0.033699
📊 信息比率:
IR: -0.229404
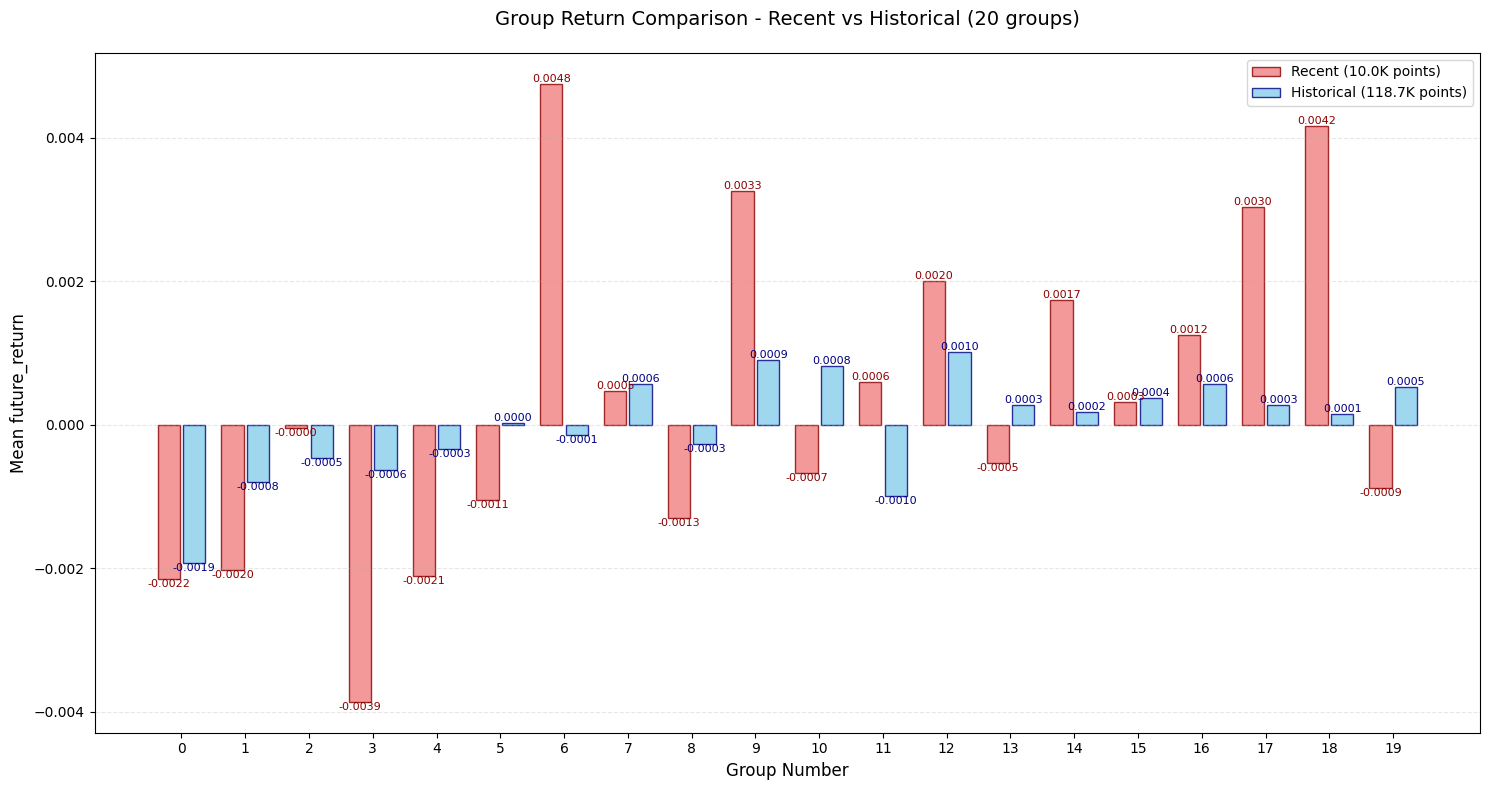
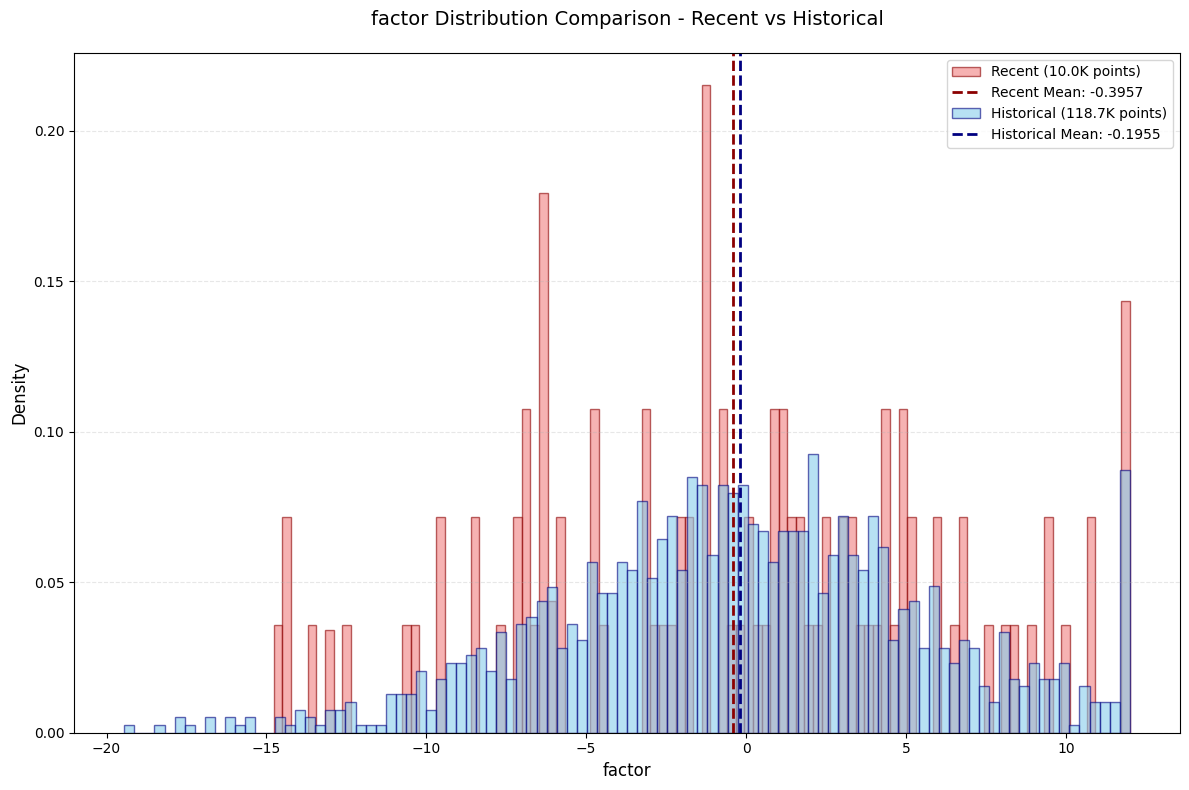
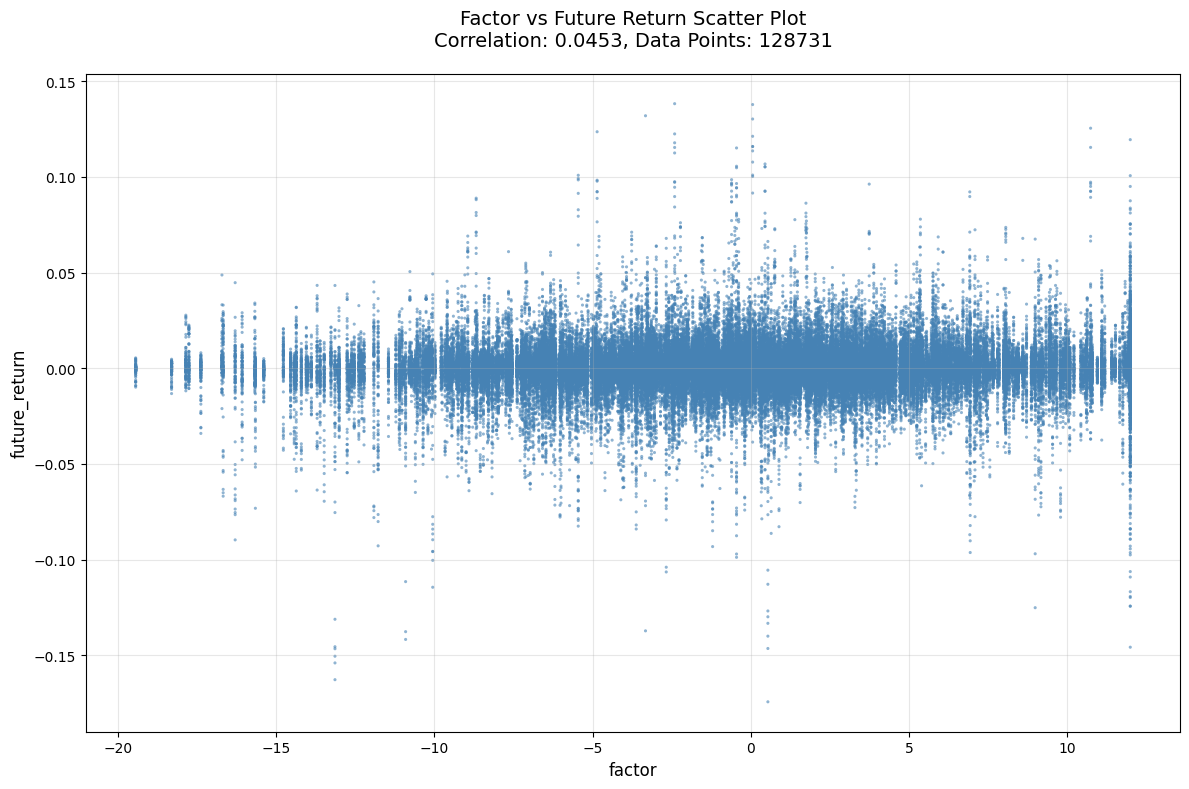
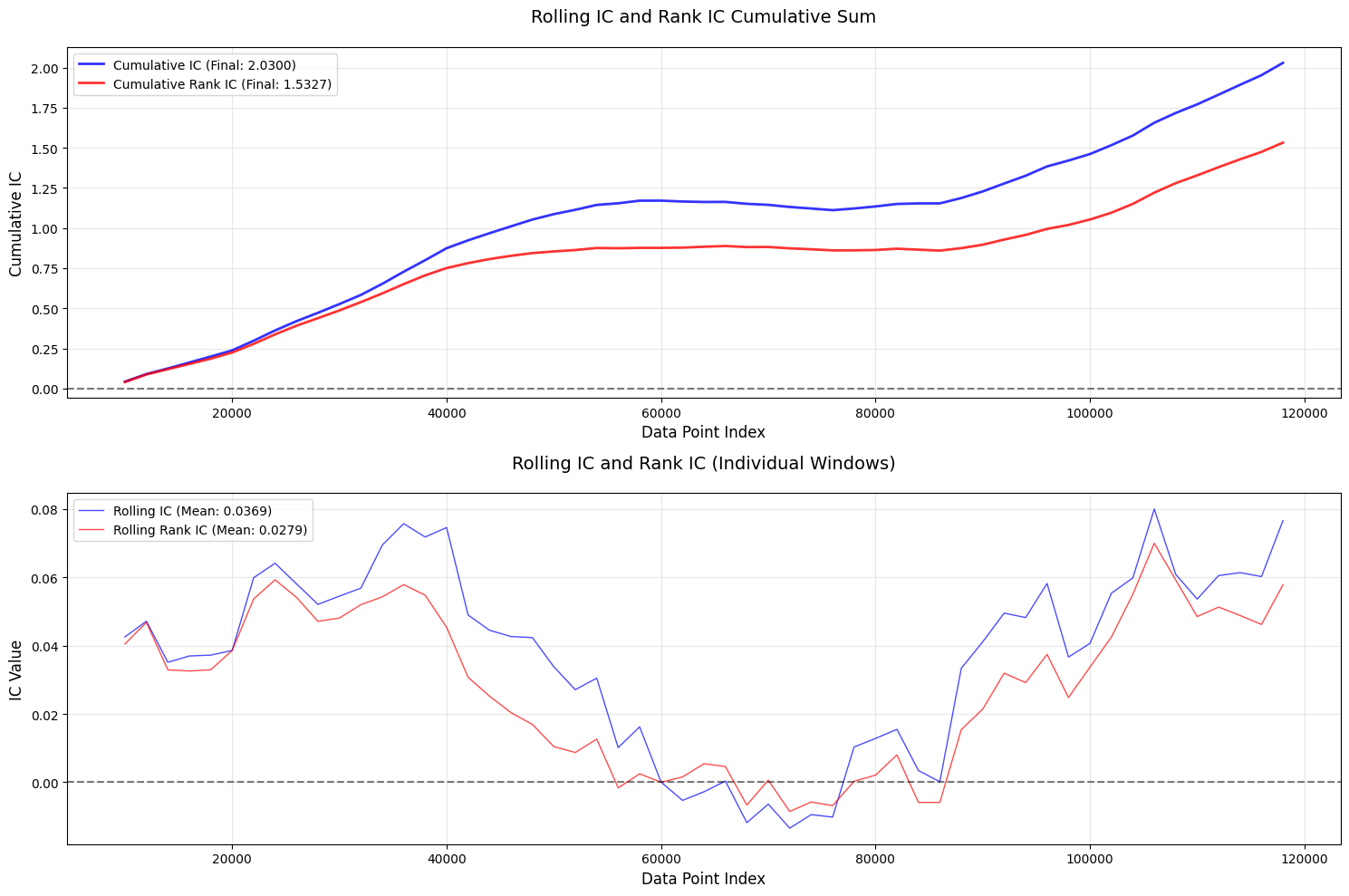
评价
- 收益率分组图很好看!!👍👍👍
- IC, Rank_IC, IR等都不错
- 唯一缺点是头部近期数据出现了一个反常😭
❗❗❗改进过程(文章链接)
改进3:信息熵理论-熵加权
解决的问题:
- 未区分噪声交易与信息交易
- 所有样本等权回归忽略信息密度差异
作用:
- 熵值量化市场无序程度(高熵=高噪声)
- 给予低噪声时期更高回归权重
- 因子值在有序市场放大,噪声市场衰减
代码实现
def factor(df, window=20):
"""
改进:使用信息熵理论计算市场不确定性加权
金融意义:在市场无序状态中提取有效信号,降低噪声影响
"""
df = df.copy()
# 计算价格变动熵
df['price_change'] = df['close'].pct_change()
df['abs_change'] = df['price_change'].abs()
df['entropy'] = -df['abs_change'] * np.log(df['abs_change'] + 1e-10) # 添加小常数避免log(0)
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4:
continue
time_idx = np.arange(len(group))
# 熵值归一化
entropy = group['entropy'].fillna(0).values
entropy = (entropy - entropy.min()) / (entropy.max() - entropy.min() + 1e-10)
# 熵加权上涨重心
up_mask = group['close'] > group['open']
if up_mask.any():
up_weights = entropy[up_mask] * group.loc[up_mask, 'volume']
G_u = np.sum(time_idx[up_mask] * up_weights) / up_weights.sum()
else:
G_u = np.nan
# 熵加权下跌重心
down_mask = group['close'] < group['open']
if down_mask.any():
down_weights = entropy[down_mask] * group.loc[down_mask, 'volume']
G_d = np.sum(time_idx[down_mask] * down_weights) / down_weights.sum()
else:
G_d = np.nan
daily_results.append({
'date': date,
'G_u': G_u,
'G_d': G_d,
'entropy': entropy.mean()
})
daily_df = pd.DataFrame(daily_results).set_index('date')
# 熵加权回归
residuals = []
for i in range(window, len(daily_df)):
train_data = daily_df.iloc[i-window:i].dropna()
if len(train_data) < 10:
residuals.append(np.nan)
continue
# 熵值作为回归权重
entropy_weights = 1 / (train_data['entropy'] + 0.1) # 低熵值给予更高权重
X = train_data[['G_u']].values
y = train_data['G_d'].values
model = LinearRegression()
model.fit(X, y, sample_weight=entropy_weights)
current = daily_df.iloc[i]
if pd.isna(current['G_u']) or pd.isna(current['G_d']):
residuals.append(np.nan)
else:
pred_G_d = model.predict([[current['G_u']]])[0]
residuals.append(current['G_d'] - pred_G_d)
daily_df = daily_df.iloc[window:]
daily_df['residual'] = residuals
# 熵调整因子值
entropy_level = daily_df['entropy'].rolling(5).mean()
daily_df['factor'] = daily_df['residual'].rolling(window).mean() * (2 - entropy_level)
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return -df['factor_value']
因子表现
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.022911
Rank_IC (Spearman): 0.022124
📊 信息比率:
IR: 0.103573
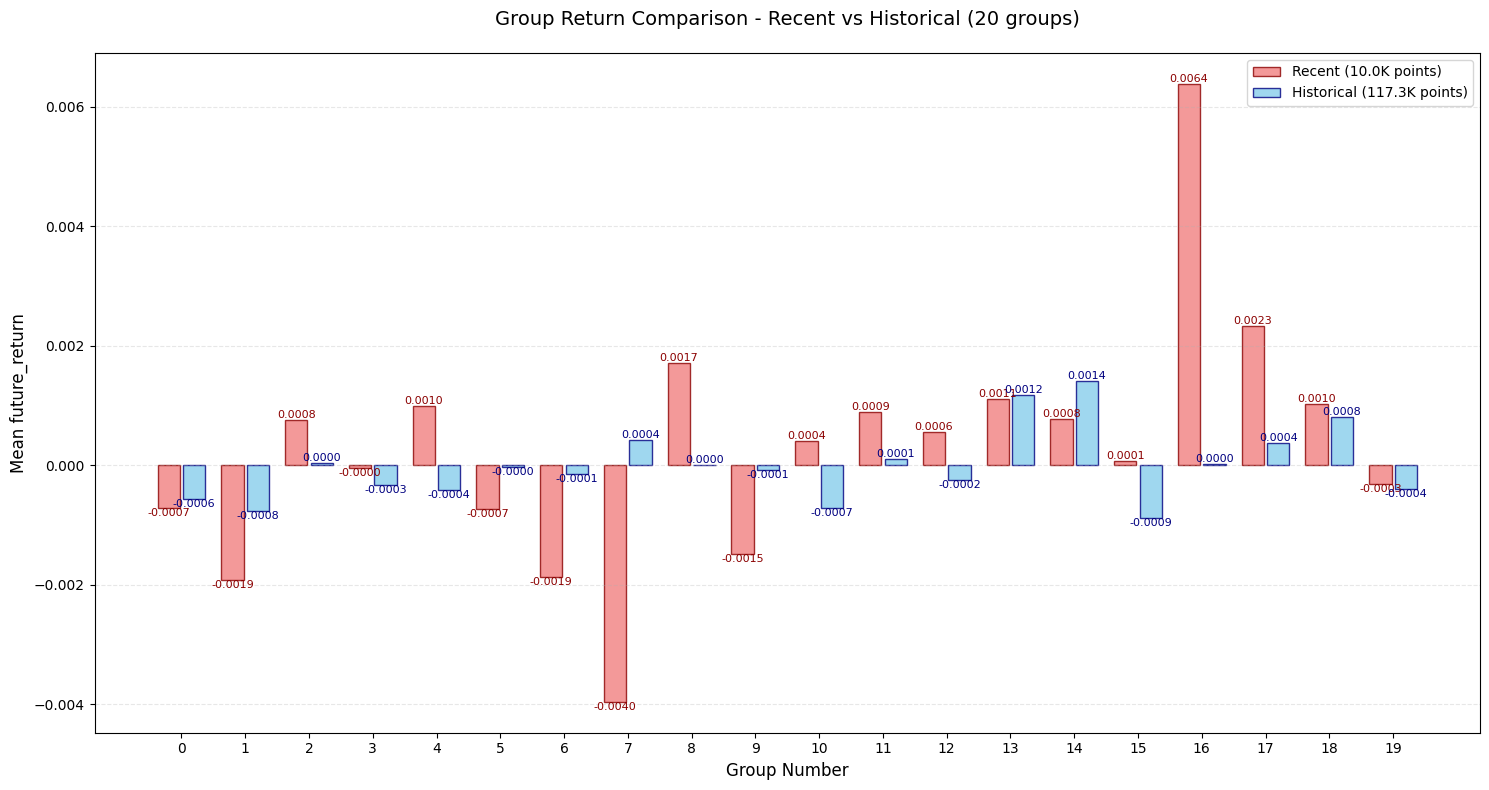
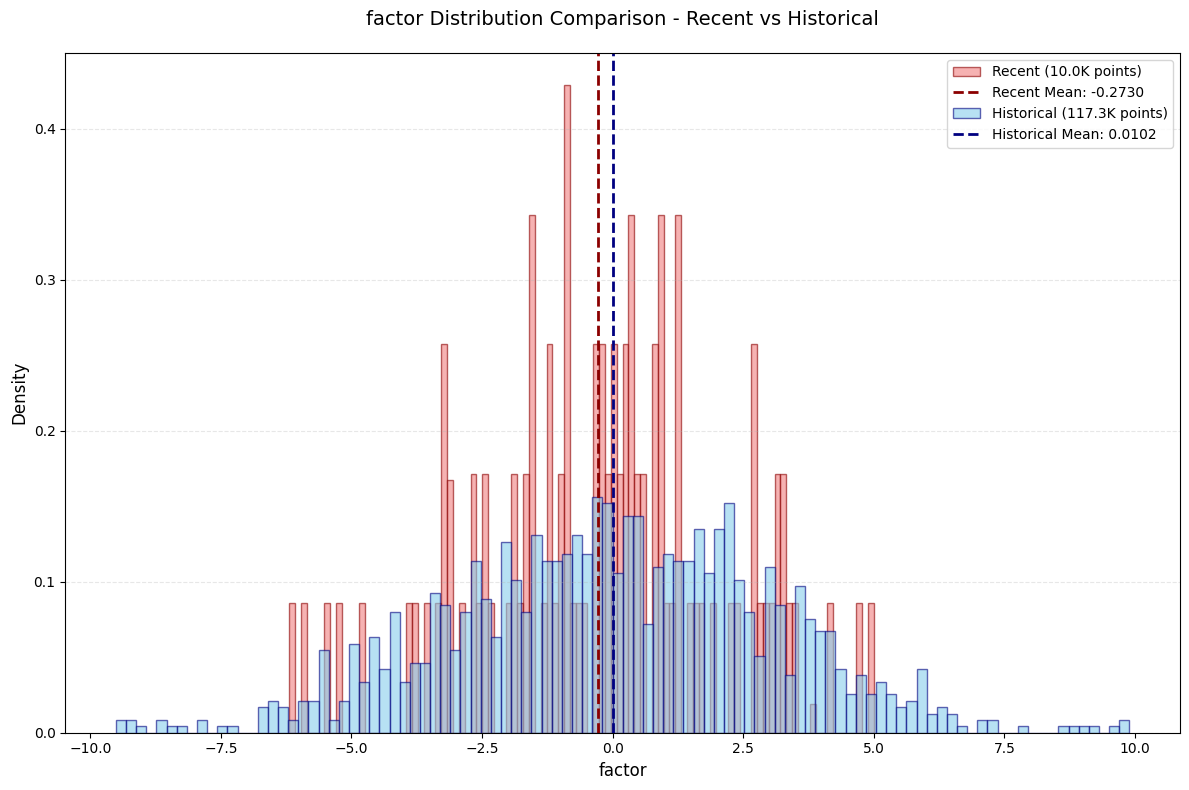
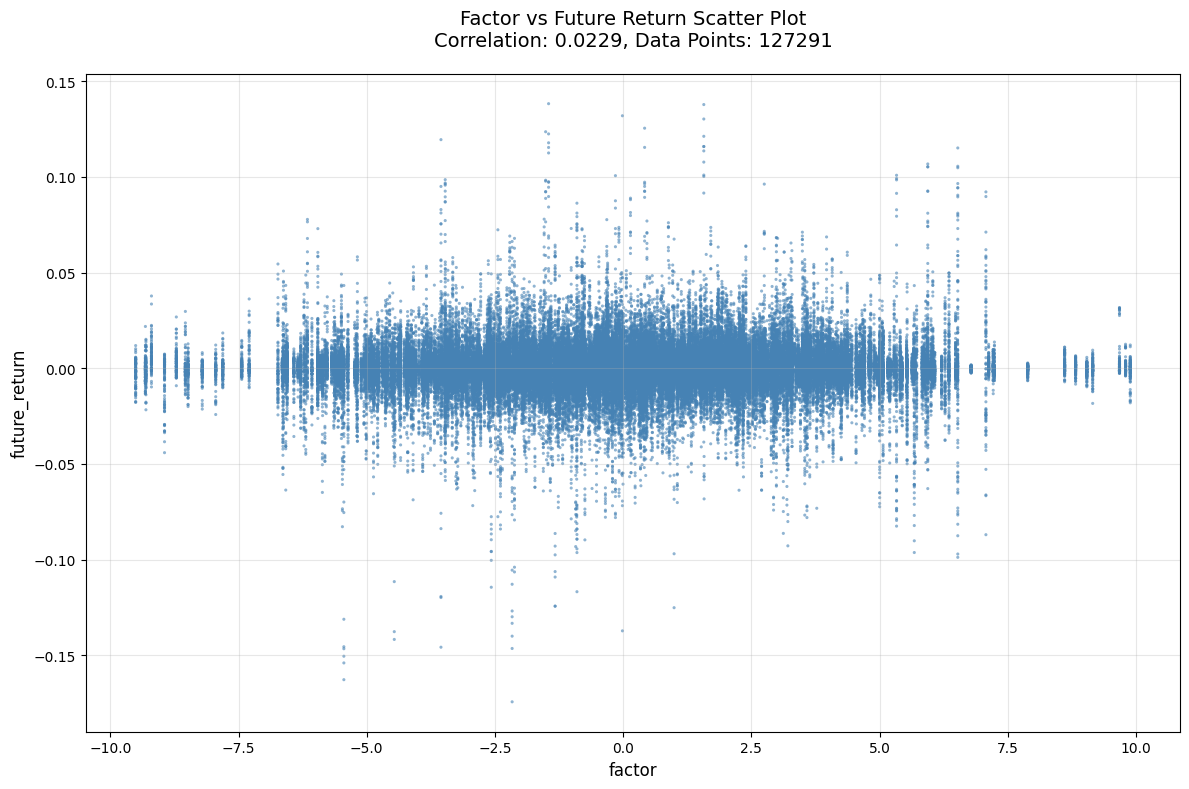
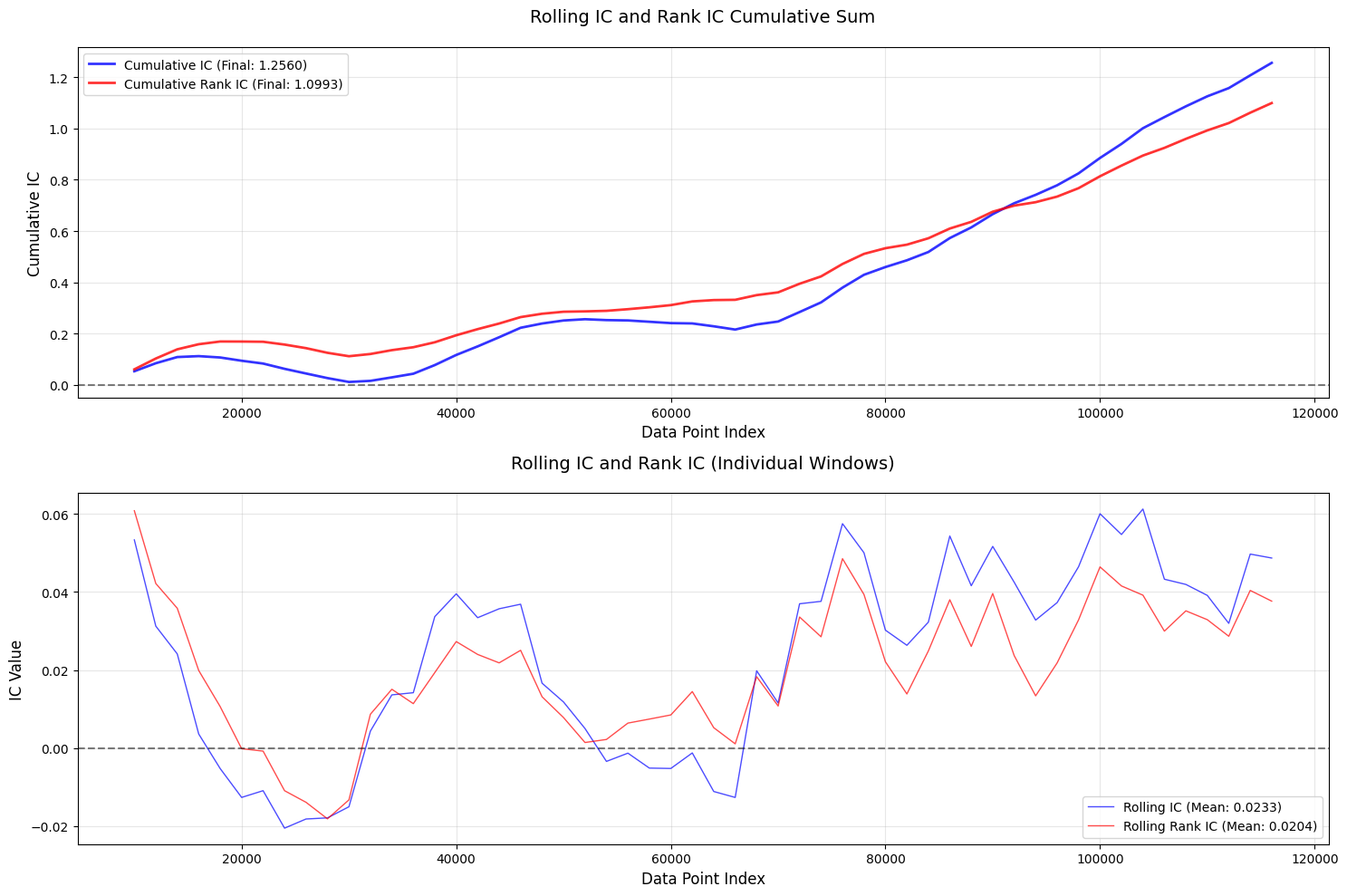
改进4:高频冲击识别
解决的问题:
- 原始因子无法捕捉程序化交易痕迹
- 未区分普通交易与冲击性交易
作用:
- 识别程序化交易造成的盘口冲击
- 分离买方/卖方冲击的时空分布
- 因子值在冲击强度变化时动态缩放
代码实现
def factor(df, window=20):
"""
改进:识别高频交易冲击模式,捕捉市场微观结构变化
金融意义:检测程序化交易导致的盘口异常行为
"""
df = df.copy()
# 计算高频冲击指标
df['mid_price'] = (df['high'] + df['low']) / 2
df['price_slope'] = df['mid_price'].diff() / df['volume'].replace(0, 1)
df['impact'] = np.where(df['price_slope'].abs() > df['price_slope'].rolling(50).mean() * 2,
np.sign(df['price_slope']), 0)
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4:
continue
time_idx = np.arange(len(group))
# 冲击方向分类
buy_impact_mask = group['impact'] > 0
sell_impact_mask = group['impact'] < 0
# 买方冲击重心
if buy_impact_mask.any():
buy_weights = group.loc[buy_impact_mask, 'volume']
G_buy = np.sum(time_idx[buy_impact_mask] * buy_weights) / buy_weights.sum()
else:
G_buy = np.nan
# 卖方冲击重心
if sell_impact_mask.any():
sell_weights = group.loc[sell_impact_mask, 'volume']
G_sell = np.sum(time_idx[sell_impact_mask] * sell_weights) / sell_weights.sum()
else:
G_sell = np.nan
daily_results.append({
'date': date,
'G_buy': G_buy,
'G_sell': G_sell,
'impact_ratio': buy_impact_mask.mean() / (sell_impact_mask.mean() + 1e-10)
})
daily_df = pd.DataFrame(daily_results).set_index('date')
# 冲击重心偏离模型
residuals = []
for i in range(window, len(daily_df)):
train_data = daily_df.iloc[i-window:i].dropna()
if len(train_data) < 10:
residuals.append(np.nan)
continue
# 冲击比例作为特征
X = train_data[['G_buy', 'impact_ratio']].values
y = train_data['G_sell'].values
model = LinearRegression().fit(X, y)
current = daily_df.iloc[i]
if pd.isna(current['G_buy']) or pd.isna(current['G_sell']):
residuals.append(np.nan)
else:
pred_G_sell = model.predict([[current['G_buy'], current['impact_ratio']]])[0]
residuals.append(current['G_sell'] - pred_G_sell)
daily_df = daily_df.iloc[window:]
daily_df['residual'] = residuals
# 冲击强度调整
impact_strength = daily_df['impact_ratio'].diff().abs().rolling(3).mean()
daily_df['factor'] = daily_df['residual'].rolling(window).mean() * impact_strength
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return -df['factor_value']
因子表现
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.022266
Rank_IC (Spearman): 0.024398
📊 信息比率:
IR: 0.448465
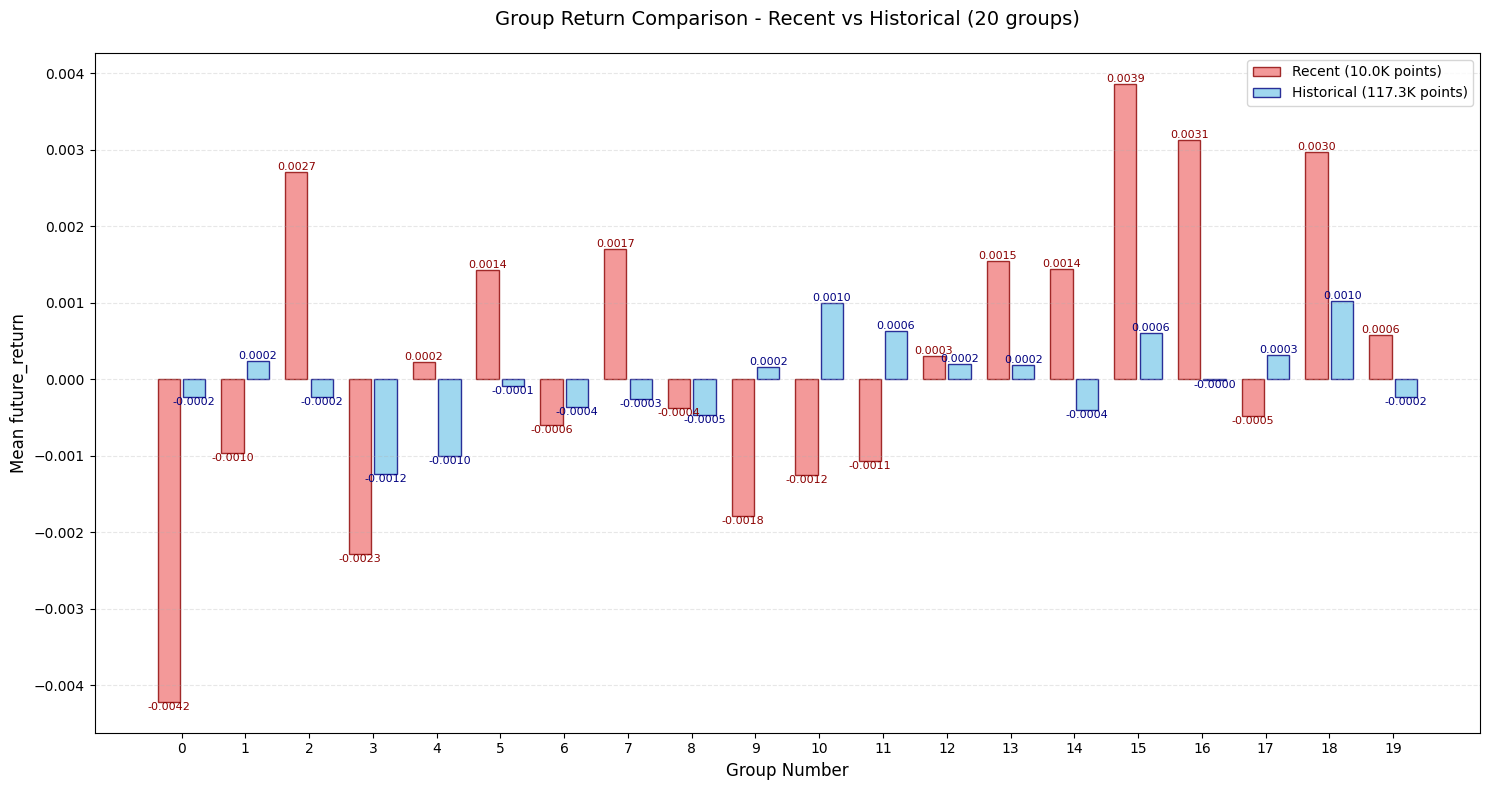
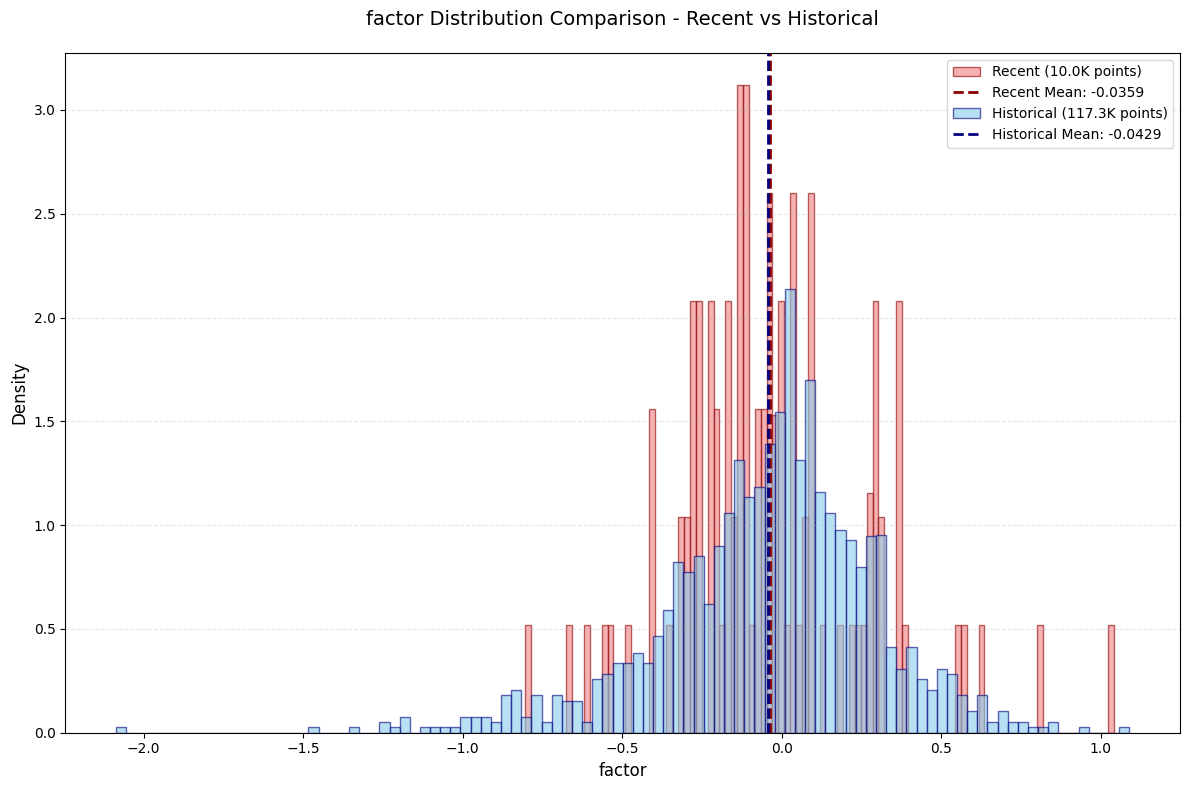
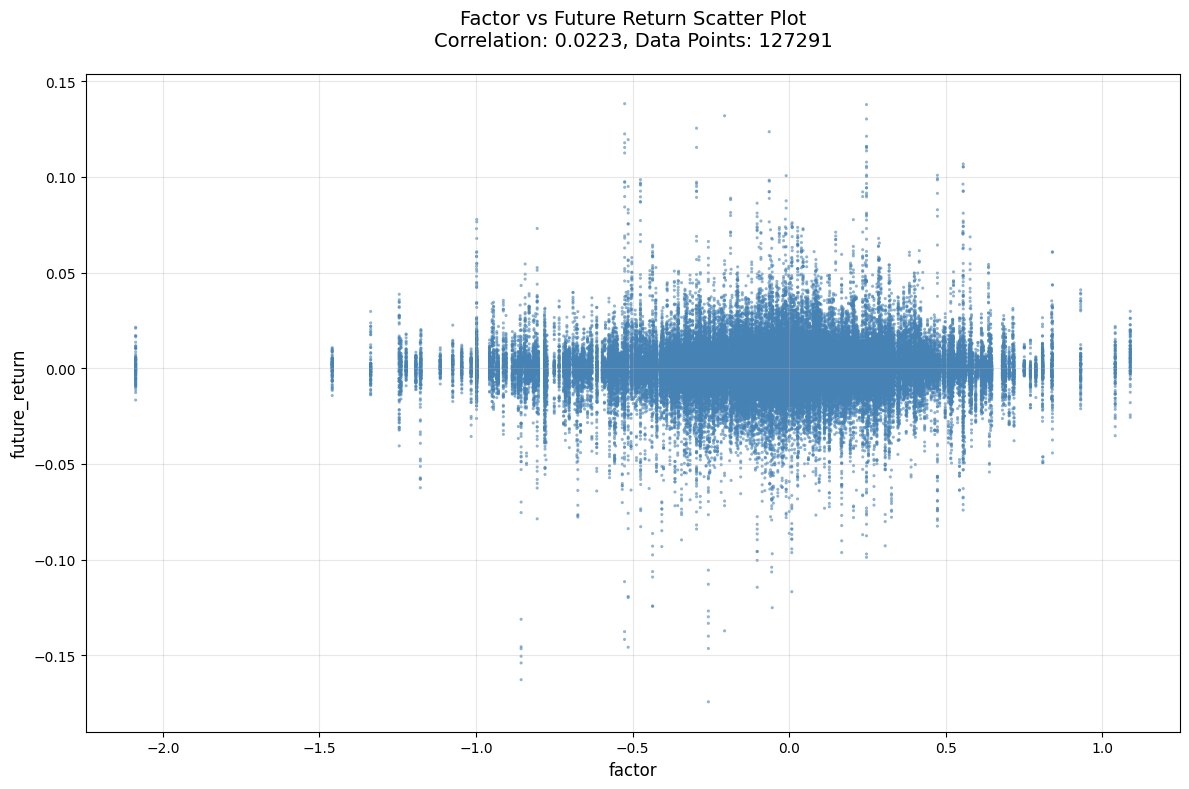
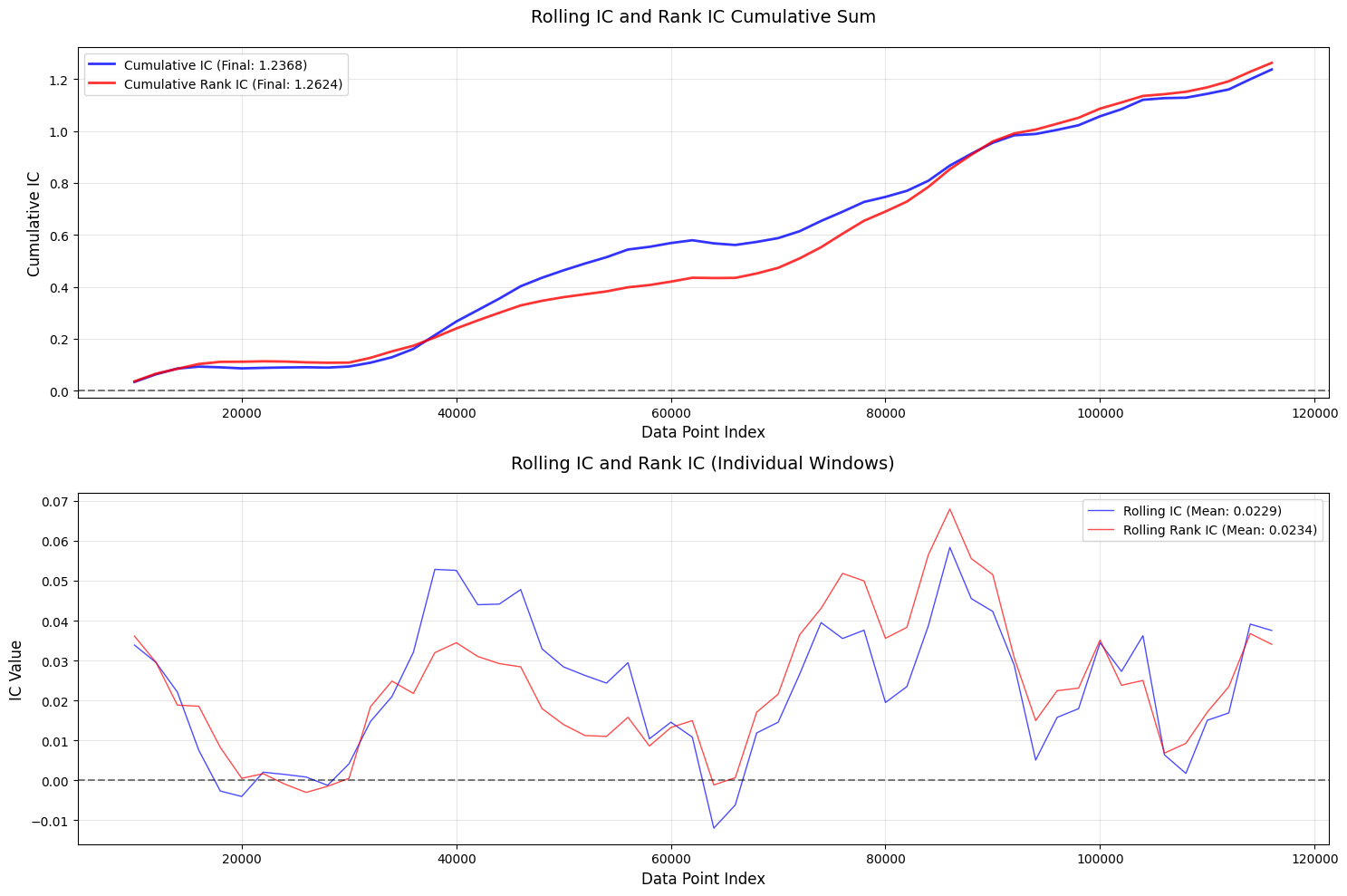
改进5:自适应分位数
代码实现
def factor(df, window=20):
"""
改进:使用分位数回归替代OLS,自适应不同市场环境
金融意义:在极端市场条件下保持稳健性
"""
df = df.copy()
df['return'] = (df['close'] - df['open']) / df['open']
daily_results = []
for date, group in df.groupby(pd.Grouper(freq='D')):
if len(group) < 4:
continue
time_idx = np.arange(len(group))
# 自适应分位数计算
q_up = np.clip(group['return'].quantile(0.75), 0.001, 0.05)
q_down = np.clip(group['return'].quantile(0.25), -0.05, -0.001)
# 分位数过滤
up_mask = group['return'] > q_up
down_mask = group['return'] < q_down
if up_mask.any():
up_weights = group.loc[up_mask, 'return'].abs() * group.loc[up_mask, 'volume']
G_u = np.sum(time_idx[up_mask] * up_weights) / up_weights.sum()
else:
G_u = np.nan
if down_mask.any():
down_weights = group.loc[down_mask, 'return'].abs() * group.loc[down_mask, 'volume']
G_d = np.sum(time_idx[down_mask] * down_weights) / down_weights.sum()
else:
G_d = np.nan
daily_results.append({
'date': date,
'G_u': G_u,
'G_d': G_d,
'volatility': group['return'].std()
})
daily_df = pd.DataFrame(daily_results).set_index('date')
# 分位数回归
residuals = []
for i in range(window, len(daily_df)):
train_data = daily_df.iloc[i-window:i].dropna()
if len(train_data) < 10:
residuals.append(np.nan)
continue
# 根据波动率选择分位数
current_vol = daily_df.iloc[i]['volatility']
quantile = 0.3 if current_vol > daily_df['volatility'].quantile(0.75) else 0.5
X = train_data[['G_u']].values
y = train_data['G_d'].values
model = QuantileRegressor(quantile=quantile, alpha=0).fit(X, y)
current = daily_df.iloc[i]
if pd.isna(current['G_u']) or pd.isna(current['G_d']):
residuals.append(np.nan)
else:
pred_G_d = model.predict([[current['G_u']]])[0]
residuals.append(current['G_d'] - pred_G_d)
daily_df = daily_df.iloc[window:]
daily_df['residual'] = residuals
# 波动率调整因子值
vol_adjust = daily_df['volatility'] / daily_df['volatility'].rolling(20).mean()
daily_df['factor'] = daily_df['residual'].rolling(window).mean() * vol_adjust
df['factor_value'] = np.nan
for date, row in daily_df.iterrows():
mask = (df.index.date == date.date())
df.loc[mask, 'factor_value'] = row['factor']
return -df['factor_value']
因子表现
📊 单币种 (single) 详细评估结果:
--------------------------------------------------
🔗 相关性分析:
IC (Pearson): 0.018167
Rank_IC (Spearman): 0.021250
📊 信息比率:
IR: 0.229478
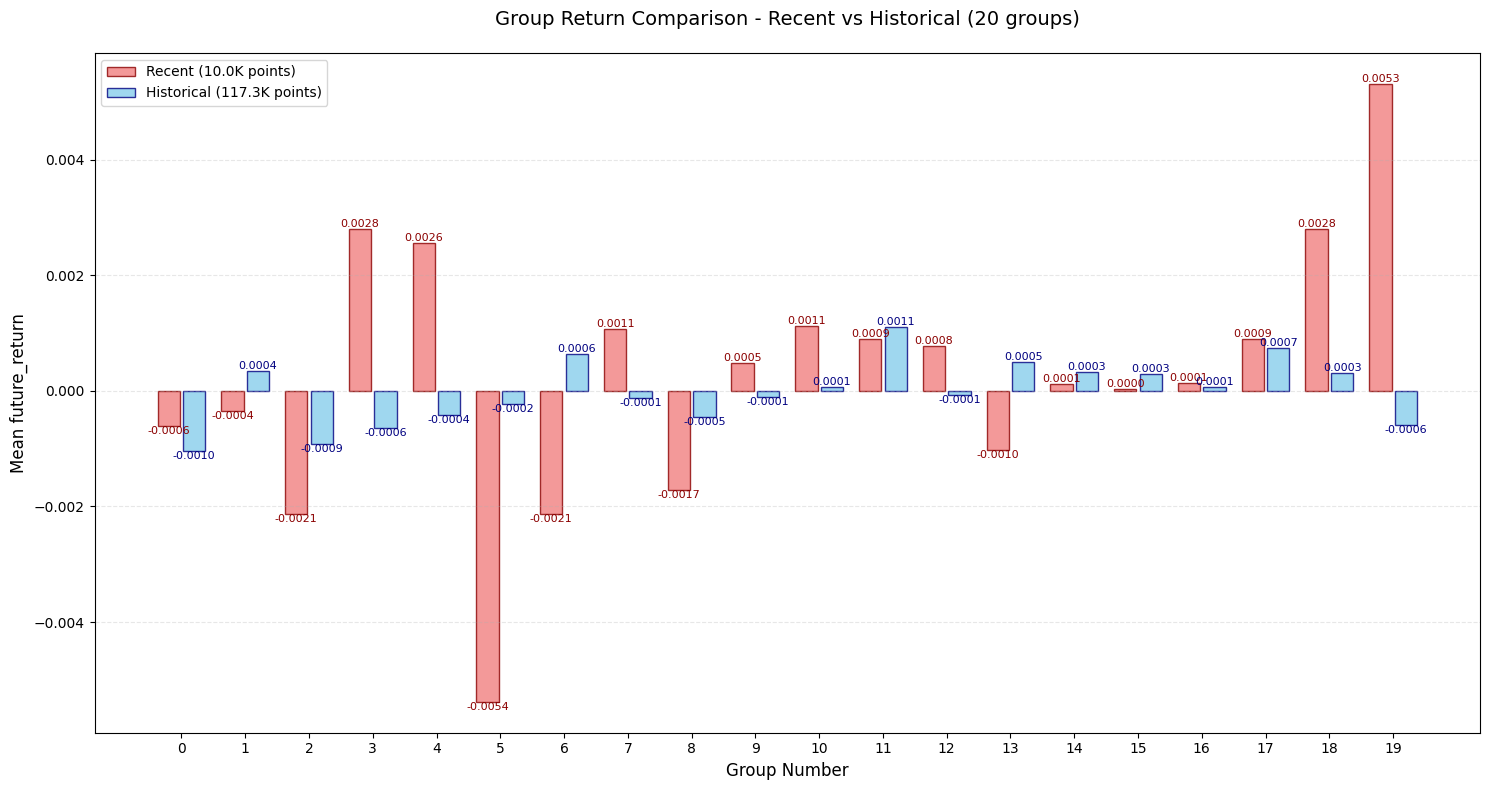
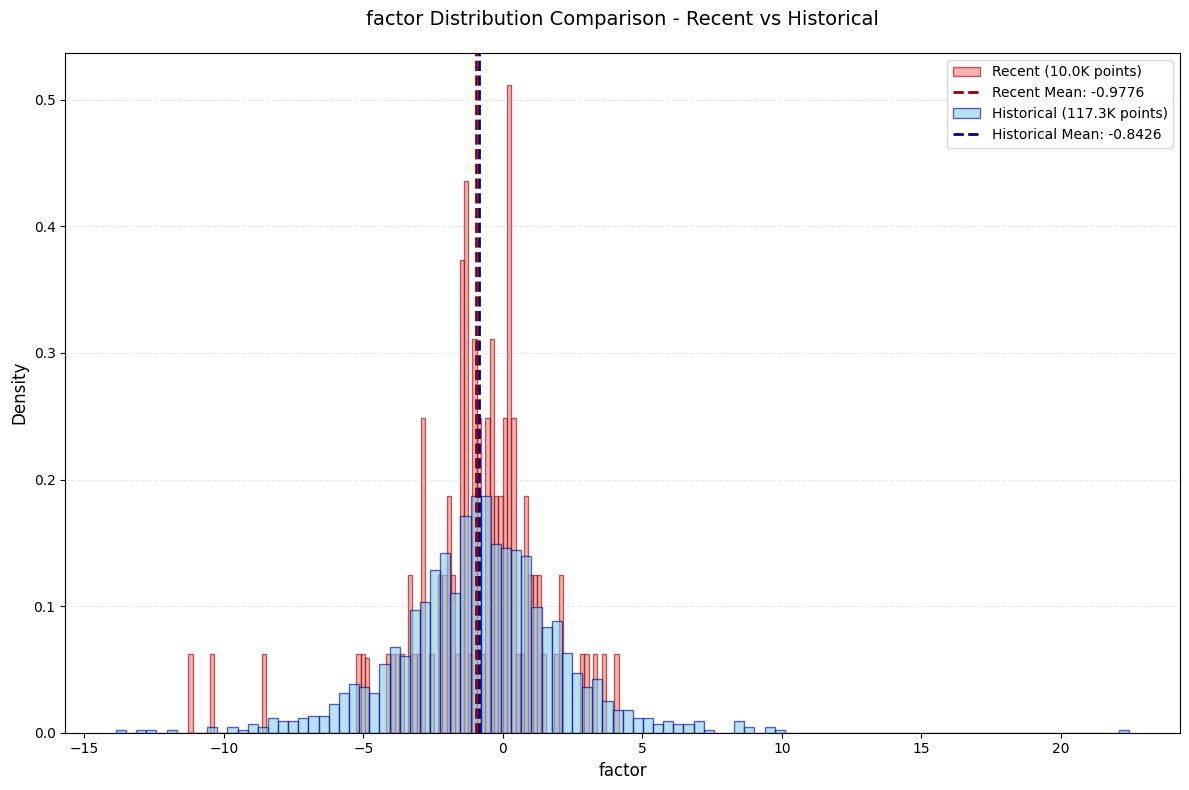
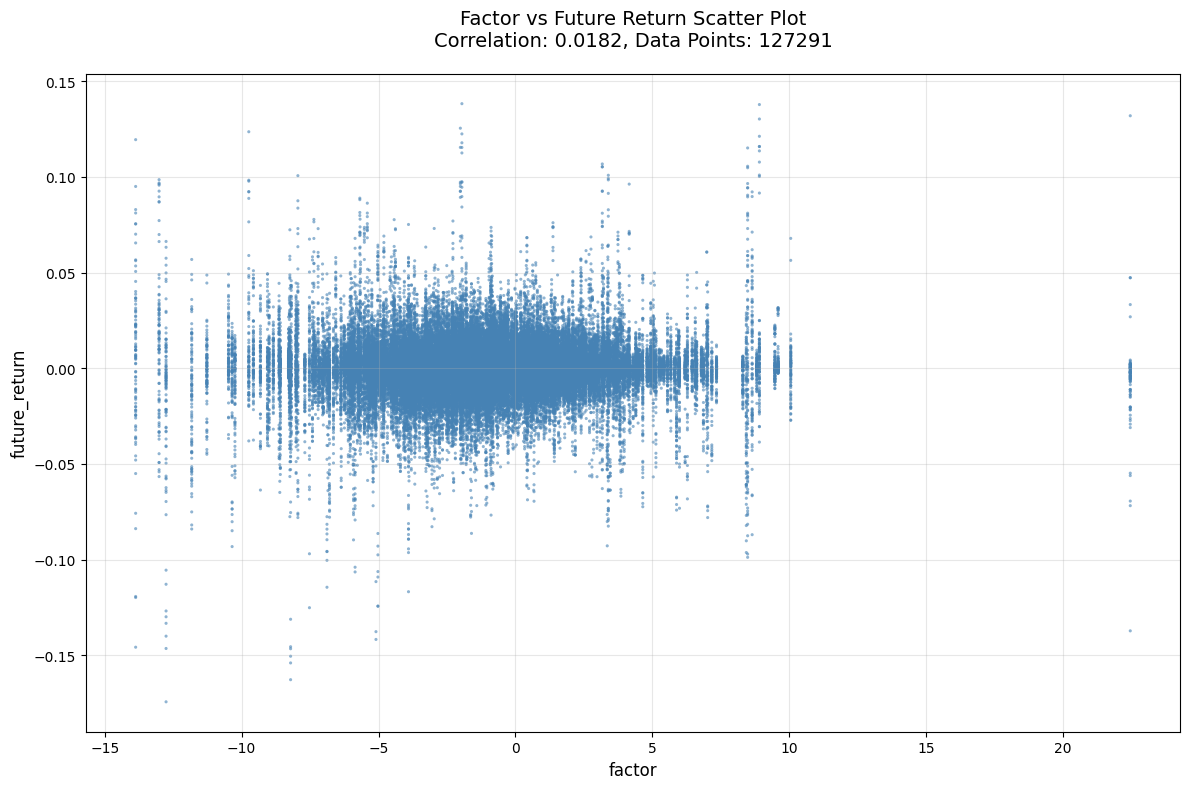
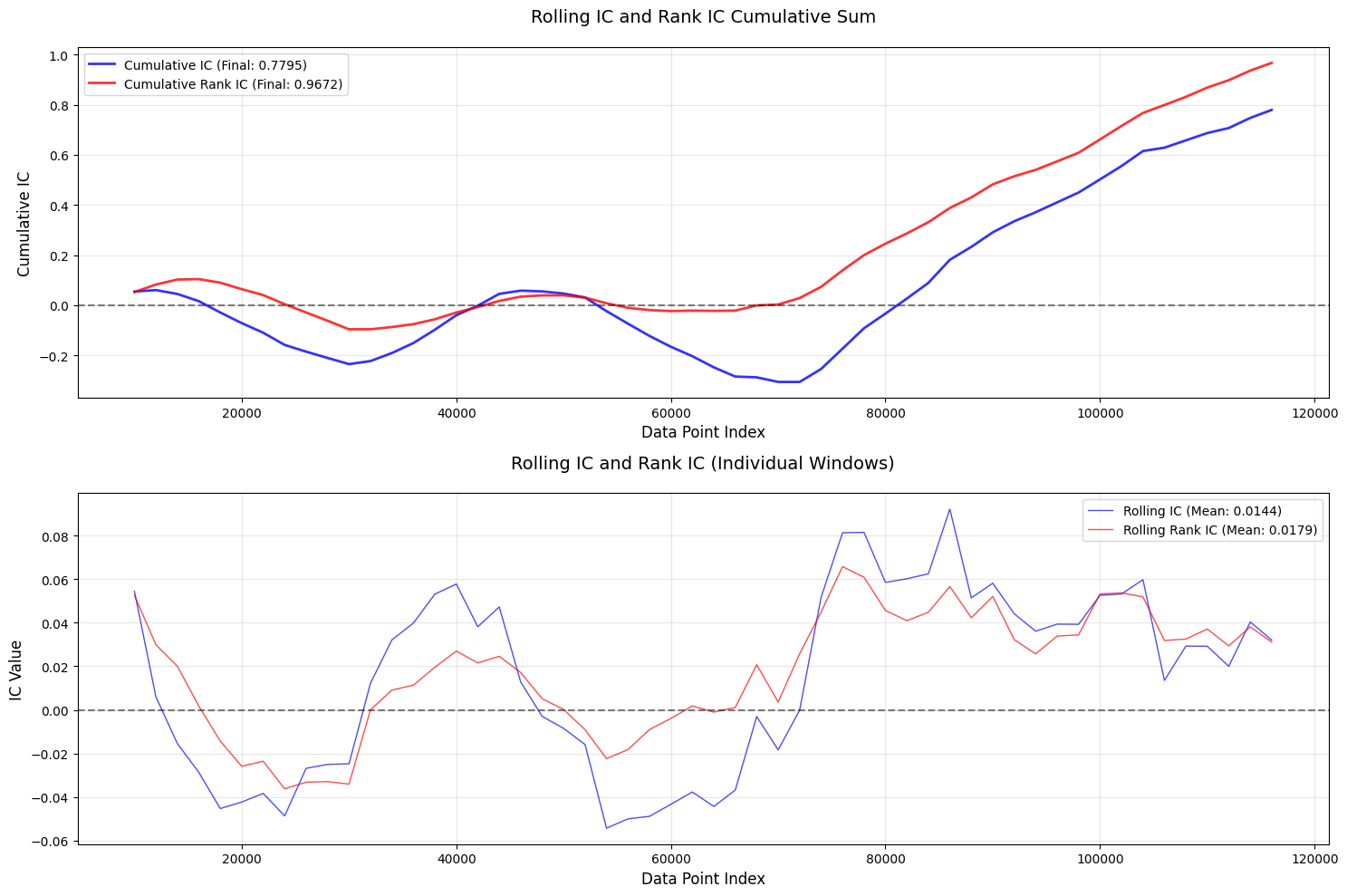
评价
后3个改进都有单调性稍显混乱的问题。。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)