实验部分小结:数据集处理部分
多视图多标签数据集处理
在进行实验部分时,首先要得到文章的源代码,一般文章中的数据集只会有一个,通过运行它,然后结合一些评价指标,通过与文章中的实验结果进行对比,来验证此方法的有效性。那么,我作为一个读者,不仅需要把现成的数据集跟方法联合一起运行出来,然后还要学会利用别的数据集在此方法中进行运行,以此来验证方法的有效性。并且利用现有的数据集在其他方法上运行,得到结果与提出方法进行比较。那么在这里,就涉及到了数据集处理问题
1.多视图多标签数据集下载问题:
https://mulan.sourceforge.net/datasets-mlc.html
https://archive.ics.uci.edu/ml/datasets.php
http://lear.inrialpes.fr/people/guillaumin/data.php
http://123.57.240.48/forum.php?mod=viewthread&tid=1391
http://lear.inrialpes.fr/data/
通过这些网页找到相应的数据集进行下载
2.多视图多标签数据集处理问题:
下载后的数据集大多是没有处理过的,里面又许多的多视图特征,比如颜色特征,全局特征等等,还有标签的训练集和测试集,这时一般的方法是通过三个m文件进行处理,分别是 vec_read.m,vec_write.m,以及数据集的对应的m文件。比如:
比如在load_espgame_data.m中,我们在里面可以根据自己的需要选择多视图的维度特征,需要4维或者5维等
Note:
1.注意这里对数据集处理的时候一定要先看下原文章中的数据集格式是什么样的,否则处理后的数据可能在文中的方法中无法运行。
比如下面这个例子中,因为在处理数据时没有添加Dim这一项,导致运行的时候报错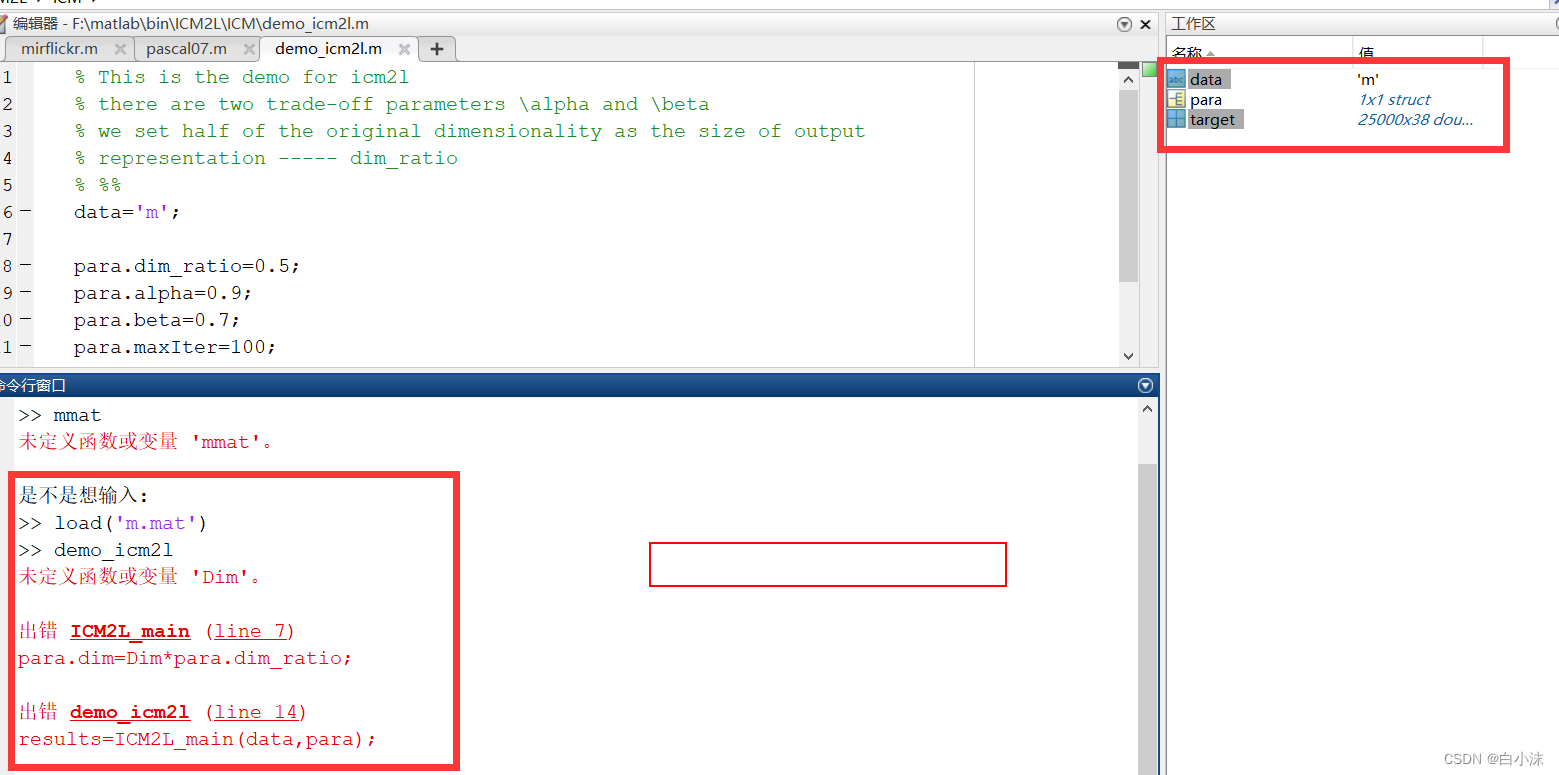
2.那么在处理数据集的时候,需要按照文章中给出的数据集的要素来进行处理吗?比如这张图?这是不是代表我必须要有25000的样本数,类别数也要一样,其他也要一样才行呢?如果不一样,会不会影响到数据的结果?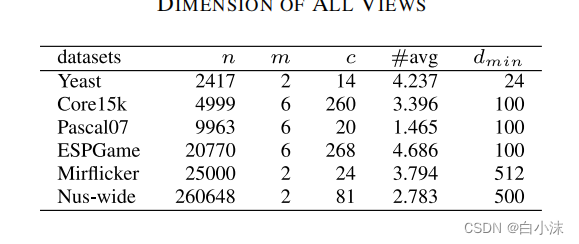
根据实践结果显示,在处理数据集的时候并不需要完全按照表格中的各个元素来进行处理,毕竟也许你下载到的数据集类别可能本身就不一样,或者因为你电脑内存的问题导致你根本无法运行几十万的样本标签,这时你只能选择其中的一部分数据进行运行了。由于电脑内存的原因,无法得到一个最优结果的话,这种情况下要么换一个内存更大的电脑,要不就是对数据集进行拆分,选择一部分数据。然后多次实验,选择最优结果。
3.在处理数据集的时候,一定要保证标签的数量和特征的数量一致,也就是标签维度和特征维度一致,否则就会报出下面的错误来。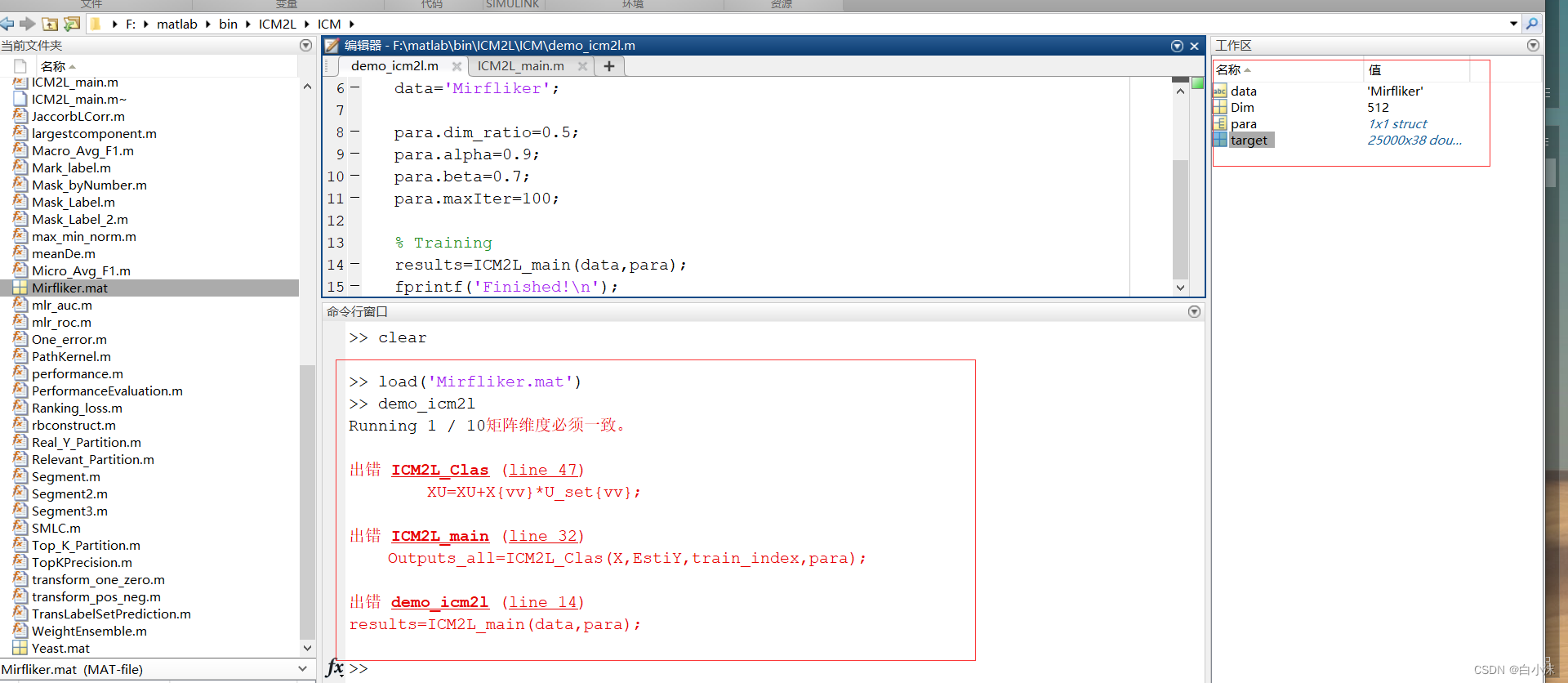
4.遇到下面这种情况,可能是因为数据集文件里含有.txt文件,
错误提示如下:
错误使用 fread
文件标识符无效。使用 fopen 生成有效的文件标识符。
出错 vec_read (line 56)
出错 pascal07 (line 16)
这时对于txt文件,直接采用matlab中的load函数处理数据即可,具体语句如下(在命令行出直接输入即可):
load(‘数据集名称_train_classes.txt’)
load(‘数据集名称_test_classes.txt’
5.遇到这种问题时: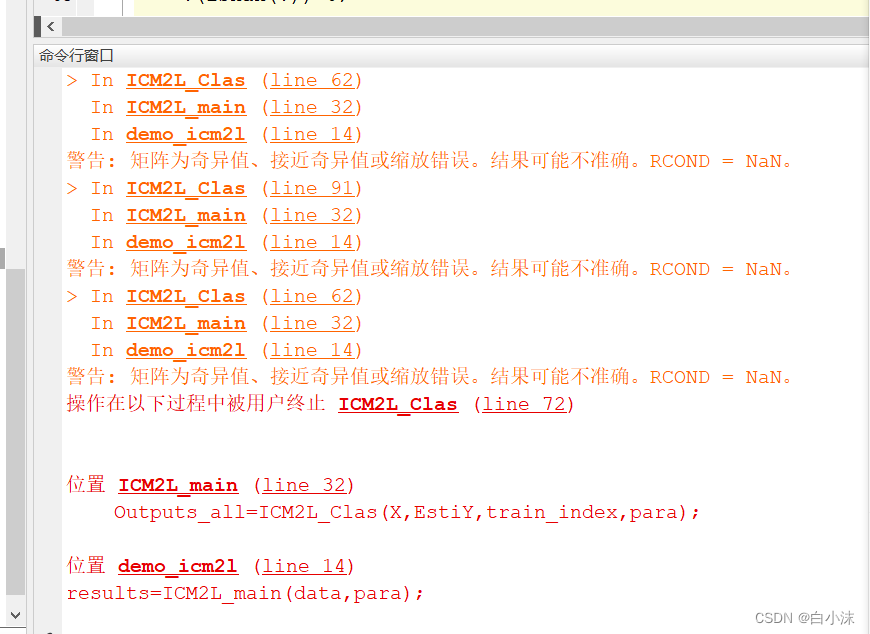
在网上搜索到的解决方法,一般是针对矩阵求逆时引起的这种错误,然后又对应的解决方法,参考这个:http://t.csdn.cn/NyEQr
但针对我的实际情况来看,并没有求逆的运算,所以有可能是因为这种原因导致报错。如下:
或者仅仅是因为我处理的这个数据集跟文章中提出的方法命名备份有些冲突……这个也是很有可能的,毕竟利用别的数据集进行运行没有报出这样的错误

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)