4. 深度学习-CNN卷积神经网络
1)是什么?
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理具有网格结构数据(如图像、视频)的深度学习模型。它通过卷积层、池化层和全连接层等结构,自动提取输入数据中的局部特征,广泛应用于计算机视觉任务。
核心组件:
- 卷积层:使用卷积核(filter)在输入上滑动,提取局部特征(如边缘、纹理)。
- 激活函数(如ReLU):引入非线性,增强模型表达能力。
- 池化层(如Max Pooling):降低特征图的空间维度,减少计算量并增强平移不变性。
- 全连接层:将提取的高级特征用于分类或回归。
- 特点:参数共享、局部连接、层次化特征提取。
✅ 小结:CNN是一种专为图像等二维数据设计的神经网络,通过卷积和池化操作高效提取空间特征,具备强大的表示能力。
2)为什么?
CNN之所以被广泛应用,是因为它天然适合处理图像这类具有空间相关性的数据。其设计原理基于以下几点:
- 局部感知:图像中相邻像素通常高度相关,CNN通过局部感受野捕捉这种局部依赖关系。
- 参数共享:同一个卷积核在整个图像上滑动,减少了参数数量,提高了泛化能力。
- 层次化特征提取:浅层提取低级特征(如边缘),深层提取高级语义特征(如物体轮廓),形成层次化的表征。
- 平移不变性:通过池化和卷积的组合,对图像中的目标位置变化不敏感。
3)什么时候用?
CNN适用于以下场景:
- 图像分类:如识别猫狗、人脸、医学影像诊断。
- 目标检测:如YOLO、Faster R-CNN中使用CNN提取特征。
- 图像分割:如U-Net、SegNet,实现像素级分类。
- 风格迁移与生成:如使用CNN提取内容与风格特征。
- 视频分析:将视频帧视为序列图像,结合RNN或Transformer处理时序信息。
✅ 小结:当任务涉及图像、视频或其他具有空间结构的数据时,CNN通常是首选模型,尤其适合需要提取局部和全局特征的任务。
4)什么时候不用?
尽管CNN强大,但在某些情况下并不适用或效果不佳:
- 非网格结构数据:如文本、语音、图结构数据——更适合RNN、Transformer或GNN。
- 高维稀疏数据:如推荐系统中的用户-物品矩阵,更合适使用协同过滤或嵌入方法。
- 长距离依赖问题:CNN的感受野有限,难以捕捉远距离依赖,此时Transformer更优。
- 实时性要求极高且资源受限:虽然轻量化CNN(如MobileNet)存在,但复杂CNN仍需大量算力。
✅ 小结:CNN不适合处理非空间结构数据或需要强长程依赖的任务,应根据数据类型和任务需求选择更合适的模型架构。
5) 总结
CNN是深度学习中最具影响力的模型之一,尤其在计算机视觉领域取得了革命性突破。它通过卷积和池化机制有效提取图像特征,具备良好的泛化能力和可解释性。然而,其应用范围受限于数据结构和任务需求。随着Transformer等新架构的发展,CNN正在与其他模型融合(如ViT+CNN),但仍保持重要地位。
✅ 最终小结:CNN是处理图像类任务的强大工具,理解其原理有助于合理选择与优化模型;但需结合具体任务灵活选用,避免“过度使用”。
概念
1. 图像概念
✅ 图像本质:
- 一张图像 = 一个多维数组
- 彩色图像:形状为 (H, W, C) 或 (C, H, W)
- H:高度(Height)
- W:宽度(Width)
- C:通道数(RGB → 3)
import numpy as np
# 一张 28x28 的灰度图
img_gray = np.random.rand(28, 28) # (28, 28)
# 一张 64x64 的 RGB 彩色图
img_rgb = np.random.rand(64, 64, 3) # (64, 64, 3)
✅ PyTorch 中的格式:(Batch, Channel, Height, Width) → (B, C, H, W)
CHW
- C:Channels(通道数)。对于彩色图像而言,通常有3个通道(RGB),而对于灰度图像,则只有1个通道。
- H:Height(高度)。表示图像的高度,即垂直方向上的像素数量。
- W:Width(宽度)。表示图像的宽度,即水平方向上的像素数量。
这种格式首先列出的是通道信息,然后是空间尺寸(高和宽),常用于某些深度学习框架中(例如PyTorch)作为默认的图像数据格式。
HWC
- H:Height(高度)
- W:Width(宽度)
- C:Channels(通道数)
与CHW不同,HWC格式首先列出的是空间尺寸,最后才是通道信息。这种格式更符合人类直觉地理解图像数据,也是许多传统图像处理库(如OpenCV)默认使用的格式。
NCHW
- N:Batch Size(批量大小)。指一次前向或后向传播过程中处理的样本数量。
- C、H、W:分别对应Channels(通道)、Height(高度)、Width(宽度)。
NCHW是一种四维张量格式,广泛应用于深度学习框架中,尤其是当处理批量图像时。第一个维度代表了批量中的样本数量,其余三个维度则描述了每个单独图像的属性(通道、高度、宽度)。这种格式被很多现代深度学习框架采用,包括TensorFlow和PyTorch。
相关API
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 读取图像
img = mpimg.imread('example.jpg')
# 显示图像
plt.imshow(img)
plt.axis('off') # 不显示坐标轴
plt.show()
# 保存图像(注意:Matplotlib不直接提供imsave函数,通常直接用plt.savefig)
plt.imsave('output_example_mp.png', img)
✅ 小结(仅 plt / Matplotlib)
读图:mpimg.imread() → 返回 RGB 格式(HWC),值范围自动适配([0,1] 或 [0,255])
显示:plt.imshow() + plt.show(),完美支持 Jupyter 和脚本
保存:plt.imsave(‘文件名’, 图像数组),自动处理颜色和归一化
2. 分层结构
2.1 输入层
✅ 功能:
接收原始图像数据,通常是 (B, C, H, W) 格式。
import torch
# 假设 batch size=32, 3通道RGB图像, 32x32像素
x = torch.randn(32, 3, 32, 32) # (B, C, H, W)
print(x.shape) # torch.Size([32, 3, 32, 32])
🎯 注意:输入前需归一化(如减均值、除标准差)
2.2 卷积层(滤波层)
✅ 核心思想:
使用卷积核(filter) 在图像上滑动,提取局部特征(边缘、纹理等)。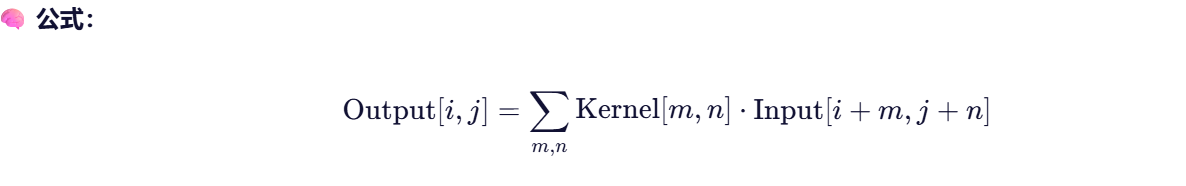
import torch.nn as nn
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
output = conv(x) # (32, 16, 32, 32)
print(output.shape) # torch.Size([32, 16, 32, 32])
✅ 参数说明:
in_channels=3:输入是RGB三通道
out_channels=16:输出16个特征图
kernel_size=3:3×3卷积核
padding=1:保持尺寸不变
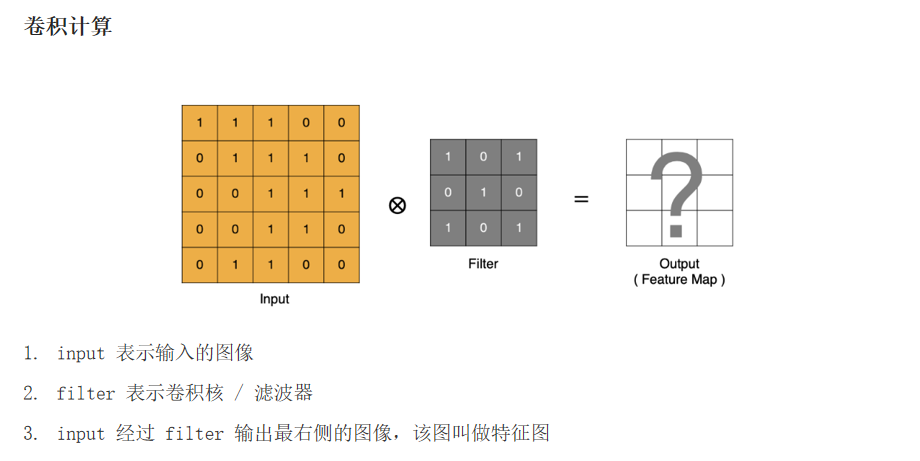
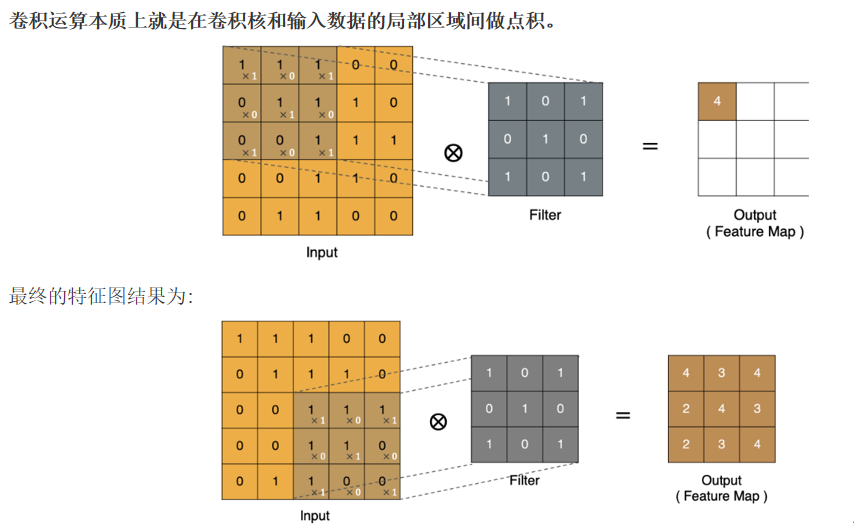
2.2.1 卷积计算
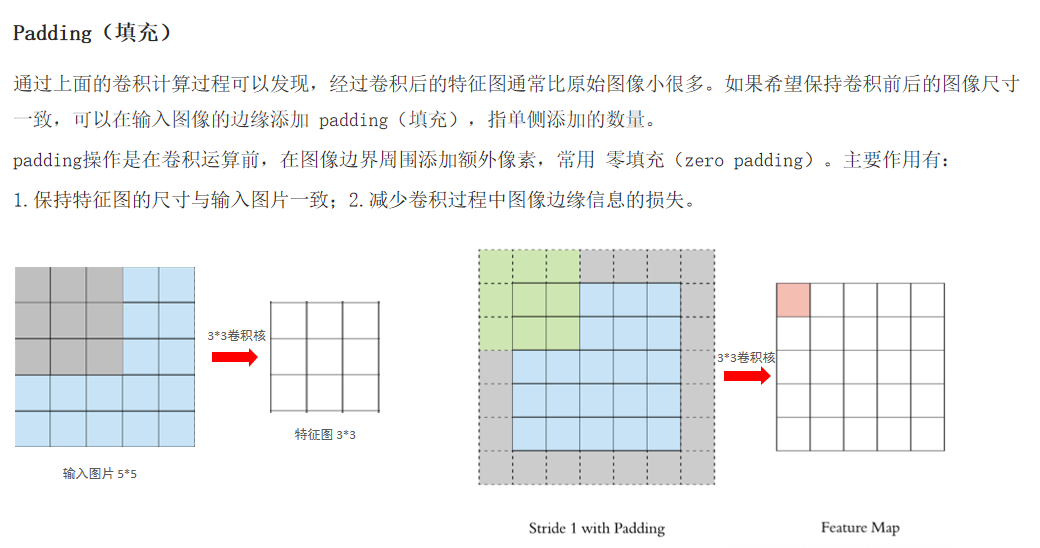
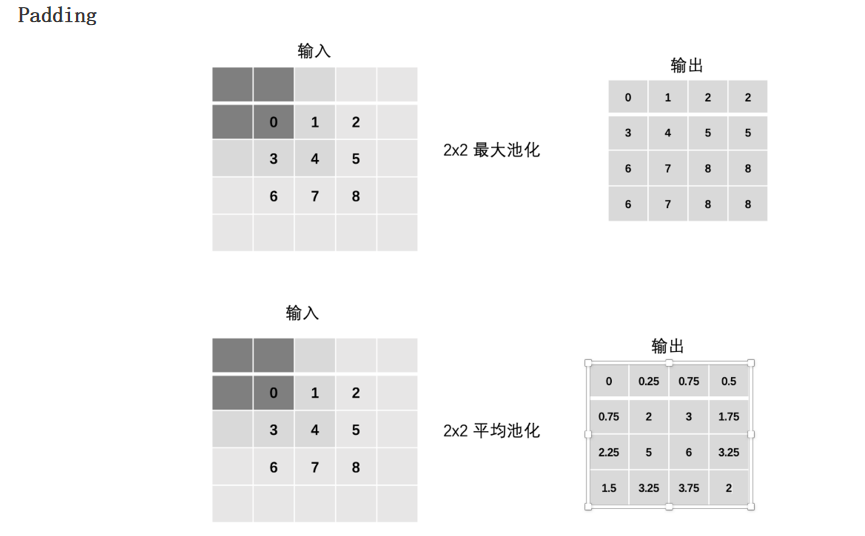
2.2.2 填充(padding)
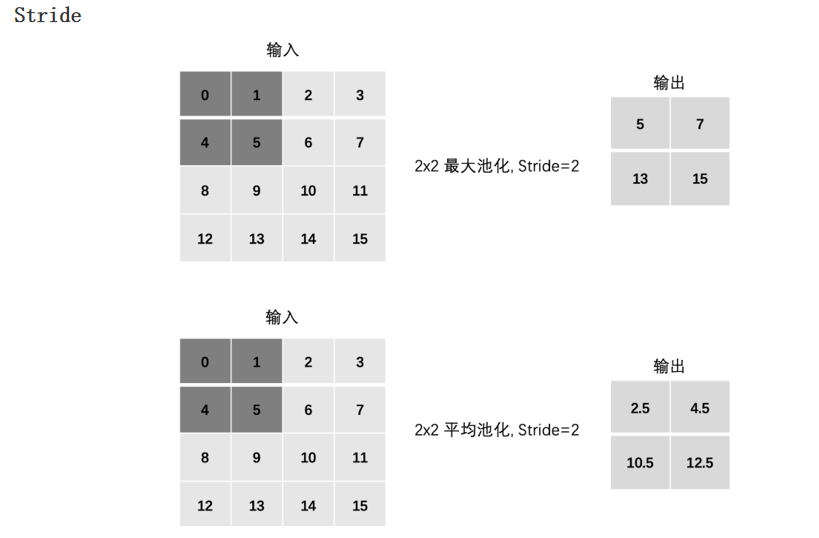
2.2.3 步长(stride)
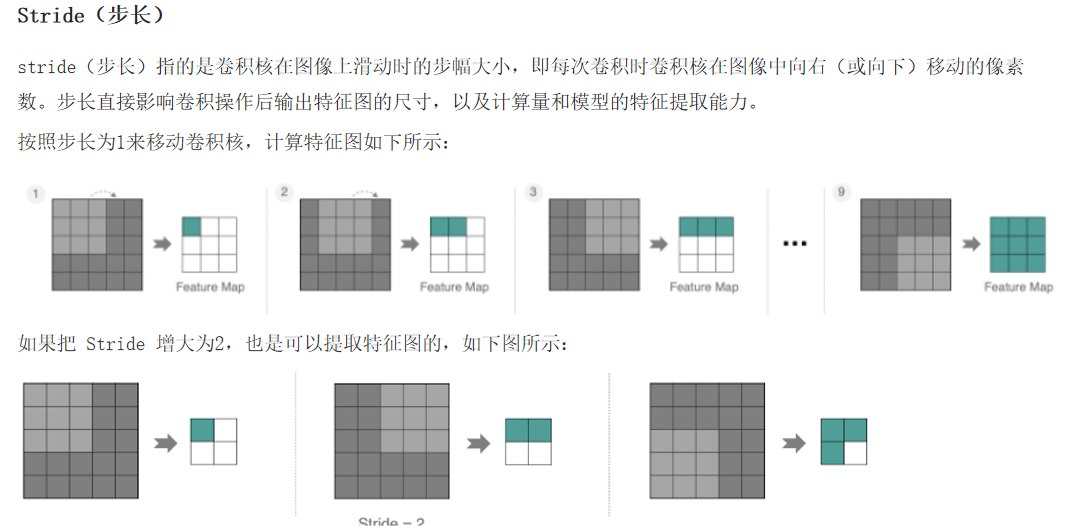
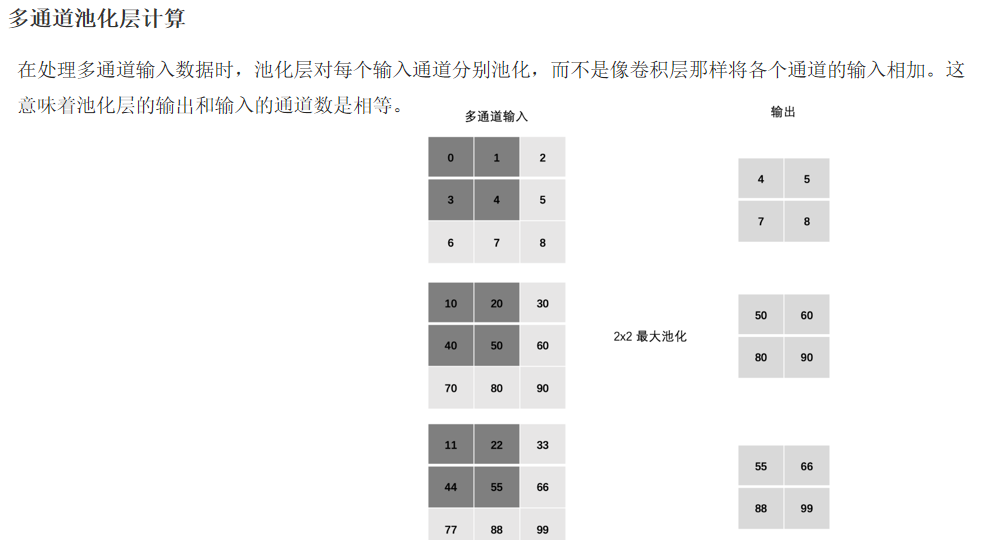
2.2.4 多通道卷积计算
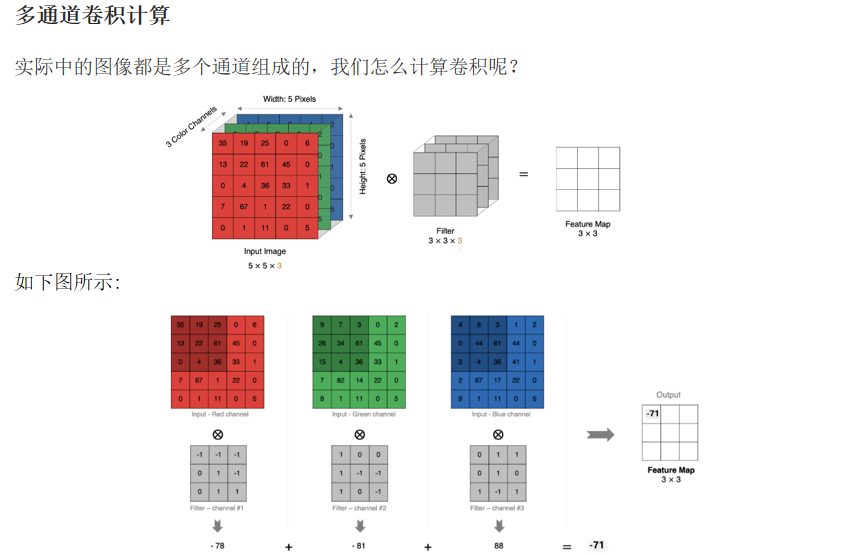
原则:先单通卷积,再多通卷积
2.2.5 特征图大小计算
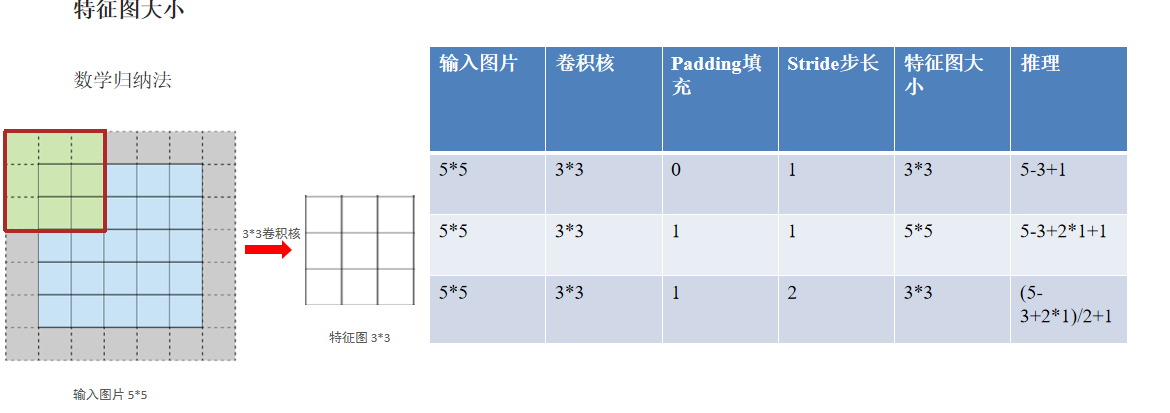

特征图大小 = [(图像大小 - 卷积核大小 + 2 * 填充) // 步长] + 1
2.2.6 PyTorch卷积层API
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,
out_channels: 输出通道,也可以理解为卷积核kernel的数量
kernel_size:卷积核的高和宽设置,一般为3,5,7...
stride:卷积核移动的步长
padding:在四周加入padding的数量,指单侧添加数量,默认补0
"""
2.3 激活层
✅ 功能:
引入非线性,使网络能拟合复杂函数。
relu = nn.ReLU()
sigmoid = nn.Sigmoid()
x = relu(conv(x)) # 加入ReLU激活
print(x.min().item(), x.max().item()) # 输出: 0.0 ~ 1.2
2.4 池化层
✅ 功能:
降低空间维度,减少计算量,增强平移不变性。
pool = nn.MaxPool2d(kernel_size=2, stride=2)
output = pool(x) # (32, 16, 16, 16)
print(output.shape) # torch.Size([32, 16, 16, 16])
✅ 每次池化后,特征图尺寸减半(若stride=2)
✅ 池化层不会改变通道的个数
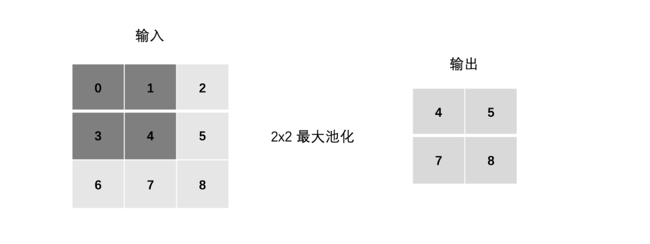
2.4.1 池化计算
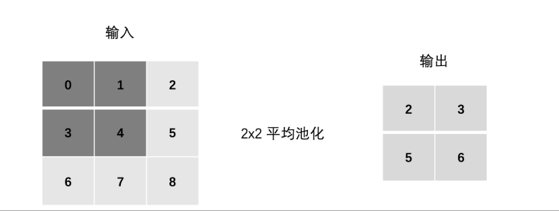
2.4.2 填充(padding)
2.4.3 步长(stride)
2.4.4 多通道池化计算
2.4.5 PyTorch池化API
最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
import torch
import torch.nn as nn
# 创建一个模拟的输入特征图:(Batch=1, Channel=1, H=4, W=4)
x = torch.tensor([[[[1., 2., 3., 4.],
[5., 6., 7., 8.],
[9.,10.,11.,12.],
[13.,14.,15.,16.]]]])
print("输入形状:", x.shape) # torch.Size([1, 1, 4, 4])
# 🔺 最大池化(取局部最大值)
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
y_max = max_pool(x)
print("最大池化输出:\n", y_max.squeeze())
# 输出:
# tensor([[ 6., 8.],
# [14., 16.]])
# 🔻 平均池化(取局部平均值)
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
y_avg = avg_pool(x)
print("平均池化输出:\n", y_avg.squeeze())
# 输出:
# tensor([[ 3.5, 5.5],
# [11.5, 13.5]])
2.5 全连接层
✅ 功能:
将前面提取的特征“展平”后,通过全连接层进行分类或回归。
flatten = nn.Flatten()
fc = nn.Linear(16 * 16 * 16, 10) # 假设最后是16x16x16
# 展平并分类
x_flat = flatten(output) # (32, 4096)
logits = fc(x_flat) # (32, 10)
print(logits.shape) # torch.Size([32, 10])
3. 图像分类案例
使用 CNN 对 CIFAR10 数据集进行图像分类。
3.1 CIFAR10数据集
CIFAR10是学术界常用于视觉训练的一个数据集,它服务于全体AI学习者
✅ 简介:
- 包含 60,000 张 32x32 彩色图像
- 10 类物体:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车
- 训练集:50,000 张,测试集:10,000 张

3.2 搭建图像分类网络结构
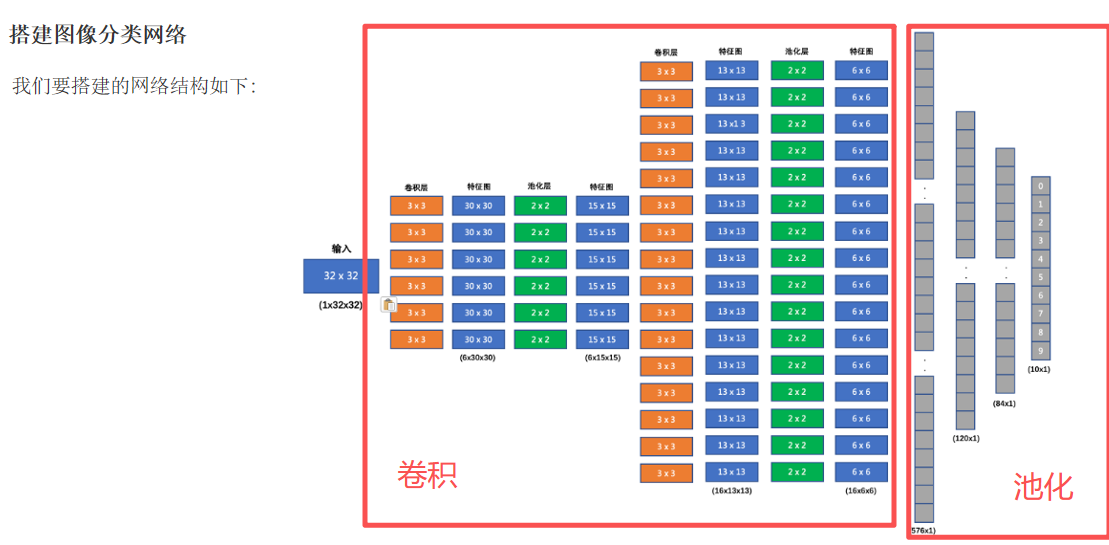
我们要搭建的网络结构如下:
1.输入形状: 32x32
2.第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
3.第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
4.第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
5.第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
6.第一个全连接层输入 576 维, 输出 120 维
7.第二个全连接层输入 120 维, 输出 84 维
8.最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
3.3 案例_图像分类
"""
案例:
演示 CNN图像分类案例,数据集为CIFAR10数据集
深度学习项目的一般工作流/步骤:
1.准备数据集
CIFAR10数据集,需要torchvision自带的CIFAR10数据集,包含50000张训练图片,10000张测试图片,10个类别,每个类别有6000张图片
2.搭建神经网络
这里使用CNN卷积神经网络
3.模型训练
创建数据加载器
设置损失函数和优化器
开始训练,遍历轮数
前向传播
计算损失
梯度清零
反向传播
更新参数
4.模型测试
"""
# 导包
import os
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
import time
import matplotlib.pyplot as plt
from torchsummary import summary
from tqdm import tqdm
# 定义批次大小
BATCH_SIZE = 64
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 1.准备数据集, 分别为训练集,验证集 和 测试集
def create_dataset():
# 1.获取训练集
train_dataset = CIFAR10(root="./data", train=True, transform=ToTensor(), download=True)
# 2.获取测试集
test_dataset = CIFAR10(root="./data", train=False, transform=ToTensor(), download=True)
# 打印原始数据形状(HWC)
print("Raw train_dataset.data shape:", train_dataset.data.shape)
print("Raw test_dataset.data shape:", test_dataset.data.shape)
# 3.拆分训练集为 训练集 和 验证集
train_size = int(0.9 * len(train_dataset)) # 45000
valid_size = len(train_dataset) - train_size # 5000
train_dataset, valid_dataset = random_split(train_dataset, [train_size, valid_size])
# 打印 CHW 格式(Tensor)示例
x, y = train_dataset[0] # 经过 ToTensor() 后
print("Tensor sample shape (CHW):", x.shape)
# 4.返回训练集,验证集,测试集
return train_dataset, valid_dataset, test_dataset
# 2.搭建神经网络
class ImageModelCNN(nn.Module):
# 1.定义__init__方法
def __init__(self):
# 初始化父类成员
super().__init__()
# 搭建神经网络
# 第一个卷积层,输入通道3,输出通道6,卷积核大小3,步长1,填充0
self.conv1 = nn.Conv2d(3, 6, 3, 1, 0)
# 第一个池化层,池化大小2,步长2
self.pool1 = nn.MaxPool2d(2, 2)
# 第二个卷积层, 输入通道6, 输出通道16, 卷积核大小3, 步长1, 填充0
self.conv2 = nn.Conv2d(6, 16, 3, 1, 0)
# 第二个池化层,池化大小2,步长2
self.pool2 = nn.MaxPool2d(2, 2)
# 全连接层
self.linear1 = nn.Linear(16 * 6 * 6, 120)
self.linear2 = nn.Linear(120, 84)
self.linear3 = nn.Linear(84, 10)
pass
# 2.定义forward 方法
def forward(self, x):
# 1.卷积层1, 卷积 + 激活 + 池化
x = self.pool1(torch.relu(self.conv1(x)))
# 2.卷积层2, 卷积 + 激活 + 池化
x = self.pool2(torch.relu(self.conv2(x)))
# 3.拉平数据, NHWC
x = x.reshape(x.size(0), -1) # 2D张量,形状(N, H*W*C)
# 4.全连接层
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = self.linear3(x) # 10分类, 原始输出, 称作logits, 范围(-inf, inf)
# 返回
return x
# 3.模型训练
def train(train_dataset, valid_dataset):
# 1.创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 2.创建神经网络模型对象
model = ImageModelCNN()
model.to(device)
# 3.设置 损失函数 和 优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-3)
# 3.开始训练,遍历轮数
# 定义总轮数
epochs = 10
# 记录最优的 验证损失
best_loss = float("inf")
# 遍历轮数
for epoch in range(epochs):
# 定义变量, 记录 总损失 总样本数 总正确数量
total_loss = 0.0
total_samples = 0
total_correct = 0
# 获取时间
start_time = time.time()
# 遍历数据加载器
for x, y in tqdm(train_loader):
# 0.设置训练模型
model.train()
# 1.迁移 数据到设备device
x = x.to(device)
y = y.to(device)
# 2.前向传播, 模型预测
y_pred = model(x) # 形状(N, 10), 原始logits, 范围(-inf, inf)
# 获取预测类别
# y_pred_cls = torch.argmax(y_pred, dim=-1)
# print(f"y_pred_cls: {y_pred_cls}")
# print(f"y: {y}")
# 3.计算损失
loss = loss_fn(y_pred, y)
# 更新 总损失
total_loss += loss.item() * x.size(0)
total_samples += x.size(0)
# 更新 总预测正确数量
total_correct += (torch.argmax(y_pred, dim=-1) == y).sum().item()
# 4.梯度清零
optimizer.zero_grad()
# 5.反向传播
loss.backward()
# 6.更新参数
optimizer.step()
pass
# 计算 当前轮次的 训练损失 和 训练准确率
train_loss = total_loss / total_samples
train_acc = total_correct / total_samples
epoch_time = time.time() - start_time
# 计算 当前轮次的 验证损失 和 验证准确率
valid_loss, valid_acc, valid_time = evaluate(valid_dataset, model)
# 判断 验证损失 是否小于最优损失
if valid_loss < best_loss:
# 更新最优损失为当前验证损失
best_loss = valid_loss
# 保存最优模型
torch.save(model.state_dict(), "../day07/model/image_model.pth")
print(f"保存最优模型, 验证损失: {valid_loss:.4f}")
# 打印训练信息
print(f"epoch: {epoch} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"train_time: {epoch_time:.4f} | "
f"valid_loss: {valid_loss:.4f} | "
f"valid_acc: {valid_acc:.4f} | "
f"valid_time: {valid_time:.4f} "
)
# 4.模型测试
@torch.no_grad() # 取消自动微分
def evaluate(test_dataset, model=None):
# 1.创建数据加载器
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 2.定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 3.创建神经网络模型
if model is None:
model = ImageModelCNN()
model.load_state_dict(torch.load("../day07/model/image_model.pth")) # pickle文件, pytorch文件格式
model.to(device)
# 4.设置为测试模式
model.eval()
# 5.定义变量, 记录 总损失 总样本数 总正确数量
total_loss = 0.0
total_samples = 0
total_correct = 0
start_time = time.time()
# 遍历数据加载器
for x, y in test_loader:
# 1.迁移 数据到设备device
x = x.to(device)
y = y.to(device)
# 2.前向传播, 模型预测
y_pred = model(x)
# 获取预测结果
y_pred_cls = torch.argmax(y_pred, dim=-1)
# 3.计算损失
loss = loss_fn(y_pred, y)
# 更新 总损失
total_loss += loss.item() * x.size(0)
total_samples += x.size(0)
total_correct += (y_pred_cls == y).sum().item()
pass
# 计算 测试准确率 和 测试损失
test_loss = total_loss / total_samples
test_acc = total_correct / total_samples
test_time = time.time() - start_time
# 返回
return test_loss, test_acc, test_time
# 测试
if __name__ == '__main__':
# 1.准备数据集
train_dataset, valid_dataset, test_dataset = create_dataset()
print(f"训练集类型:{type(train_dataset)}")
print(f"训练集大小:{len(train_dataset)}")
print(f"验证集大小:{len(valid_dataset)}")
print(f"测试集形状:{test_dataset.data.shape}")
# 绘制图像,3*3
# plt.figure(figsize=(9, 9))
# for i in range(9):
# plt.subplot(3, 3, i + 1)
# # 获取图片
# img = train_dataset.dataset.data[i] # HWC: (32, 32, 3)
# label = train_dataset.dataset.targets[i]
# label_name = train_dataset.dataset.classes[label]
# # 绘制图片
# plt.imshow(img)
# plt.title(label_name)
# plt.axis("off")
# plt.show()
# 2.搭建神经网络
# model = ImageModelCNN()
# model.to(device)
# # 统计模型参数
# summary(model, (3, 32, 32))
# 3.模型训练
train(train_dataset, valid_dataset)
# 4.模型测试
test_loss, test_acc, test_time = evaluate(test_dataset)
print(f"测试损失: {test_loss:.4f} | 测试准确率: {test_acc:.4f} | 测试时间: {test_time:.4f}")
pass
4.残差神经网络(ResNet)
1)是什么
🧩 一句话定义:
ResNet 是一种通过引入“跳跃连接”(Skip Connection)来解决深度神经网络退化问题的卷积神经网络架构。
传统 CNN 中,每一层都试图直接拟合输入到输出的映射函数 H(x)。当网络很深时,优化器难以找到最优路径,导致梯度消失或爆炸,甚至出现“越深越差”的现象。
2)为什么
神经网络主要问题在于梯度消失/爆炸和网络退化,ResNet就是主要解决网络退化的问题
3)什么时候用
| 场景 | 原因 |
|---|---|
| 图像分类任务 | ResNet 是图像分类的“默认选择”,尤其适合大规模数据集如 ImageNet |
| 目标检测(如 Faster R-CNN、Mask R-CNN) | 使用 ResNet 作为骨干网络提取特征,效果稳定 |
| 语义分割(如 DeepLab、U-Net with ResNet) | 高分辨率特征图 + 强表达能力 = 更精准分割 |
| 迁移学习 | 预训练的 ResNet 模型(如 resnet18、resnet50)可以直接加载,快速适配新任务 |
| 医学影像分析 | 对细节敏感的任务中,ResNet 的深度结构有助于捕捉微弱特征 |
4)什么时候不用
| 场景 | 原因 | 替代建议 |
|---|---|---|
| 实时推理需求高(如移动端、嵌入式设备) | ResNet 参数多、计算量大,延迟较高 | MobileNet、ShuffleNet、EfficientNet-Lite |
| 内存受限环境 | 如手机 App、IoT 设备,ResNet 占用内存较多 | TinyML 模型、蒸馏模型 |
| 小样本任务 | 数据不足时,ResNet 容易过拟合 | 使用轻量级模型 + 正则化,或先用迁移学习 |
| 序列建模任务(如 NLP、语音) | ResNet 是为图像设计的,不适合序列数据 | Transformer、RNN、LSTM |
| 需要全局注意力机制 | ResNet 局部感受野有限,无法捕捉长距离依赖 | Vision Transformer (ViT)、Swin Transformer |
5)总结
🌟 一句话总结:
ResNet 是深度学习中的一次“优雅妥协”——它不强行让网络变得更聪明,而是给它一条“逃生通道”,让它既能学习,也能休息。
🎯 生动比喻
想象你在爬山,每走一步都要自己踩实地面。传统网络就像这样一步步往上爬,稍有不慎就会滑倒。
而 ResNet 给你装了一个“安全绳索”——当你觉得太累或者路太陡时,可以直接顺着绳子回到之前的安全点,再继续前进。
你不会因为太深而崩溃,反而可以稳稳地走到山顶。
🚀 最终结论:ResNet 不是最快的,也不是最炫的,但它是最稳的。在深度学习的世界里,有时候“稳健”比“惊艳”更重要。
4.1 论文地位
“Deep Residual Learning for Image Recognition” ——2015年何恺明团队提出,CVPR 2016 最佳论文,开启深度网络新时代!
ResNet 是计算机视觉史上的一座里程碑。它首次证明:网络越深,性能不一定越差。在 ImageNet 比赛中,ResNet-152 以 3.57% 的 top-5 错误率刷新纪录,击败了所有传统模型。
更关键的是,它提出了“残差学习”思想,解决了深度神经网络训练中的梯度消失与退化问题,为后续模型(如 DenseNet、EfficientNet)铺平道路。
✅ 小结:ResNet 不仅是技术突破,更是范式变革——它让“更深=更强”成为现实,被誉为深度学习时代的“深度之王”。
4.2 残差块
💡 生动比喻:想象你在爬山,每走一步都累得要命,但突然有人告诉你:“别硬往上冲,直接抄近道!”——这就是残差连接的智慧。
传统神经网络希望每一层学习一个复杂的函数 H(x),而 ResNet 提出:为什么不学一个“变化量” F(x)=H(x)−x 呢?
于是,我们定义:
H(x)=F(x)+x
这个 x 就是恒等映射(identity mapping),通过“跳跃连接(skip connection)”实现。如果某层发现“我不用变”,那就直接把输入传过去,避免信息丢失。
可以粗暴的理解为“一个跳跃连接越过的层组合起来就是残差块” -> 公式:残差块 = 跳跃连接 + 被它跨过的子网络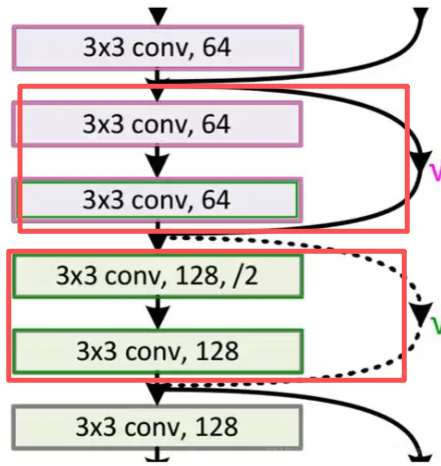
✅ 小结:残差块的核心是“让网络学会‘做增量’而非‘从零开始’”,这就像升级系统时打补丁,而不是重装系统,高效又稳定。
4.3 ResNet架构
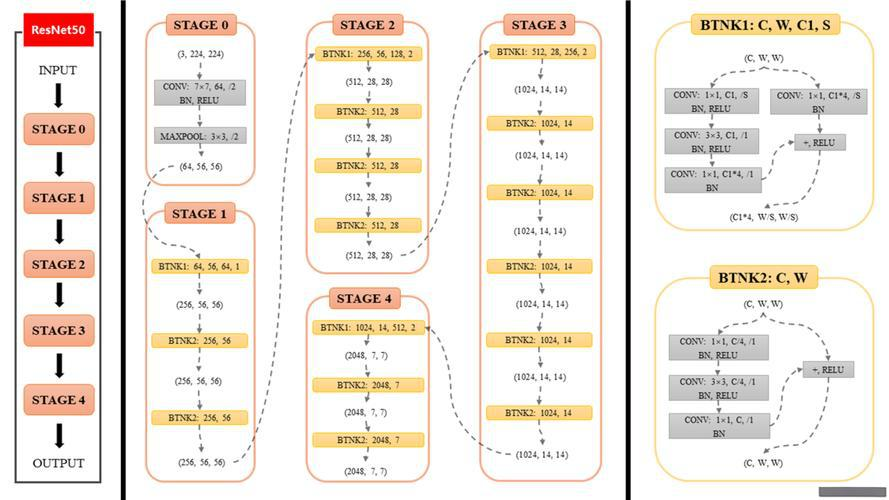
这张图就像是一座精心设计的摩天大楼,每一层都代表了ResNet-50架构中的一个关键组成部分。让我们一起探索这座“建筑”的内部结构吧!
🏗️ 大厦入口:输入干(Stage 0)
你首先会遇到大厦的宏伟入口——输入干。这里由一个7×7的大窗户(卷积层)和一个大堂(最大池化层)组成,它们共同作用,将你手中的图片(原始输入)迅速缩小,变成更容易处理的尺寸(从224x224变为56x56),同时提取出初步的特征信息。
🌈 第一层楼:Stage 1
进入第一层楼,你会发现这里有三个相同的房间(Bottleneck块)。每个房间里都有一个小走廊(1x1卷积),接着是一个稍微宽敞一点的通道(3x3卷积),最后又是一个小走廊(另一个1x1卷积)。这些房间通过一种特别的设计——跳跃连接直接与入口相连,确保信息能够无阻碍地传递,同时也让楼层之间的过渡更加平滑。
🚀 高层展望:Stage 2至Stage 4
随着电梯(下采样层)带你逐层上升,你会注意到每层楼的房间数量逐渐减少,但每个房间的空间却变得更大(通道数增加)。在第二层楼(Stage 2),你首次遇到了需要乘坐电梯才能到达的房间,这意味着你需要通过一个步长为2的卷积来缩小空间尺寸,以便更高效地处理信息。同样的设计也出现在第三层(Stage 3)和第四层(Stage 4),每上一层,你都会感受到信息被更加浓缩和提炼的过程。
🎯 屋顶花园:全局平均池化 + 全连接层
终于,当你来到大厦的顶层,这里的景象与下面几层截然不同。这里没有复杂的走廊或房间,只有一个宽阔的屋顶花园(全局平均池化层),它将所有楼层的信息汇总起来,再通过一扇通往外界的大门(全连接层)输出最终的结果。
📖 小结
在这座名为ResNet-50的“摩天大楼”中,每一个细节都被精心设计,以确保信息能够在楼层之间自由流动,不受阻碍。而这一切的核心,就是那些巧妙的跳跃连接,它们像是一条隐形的电梯,帮助数据轻松跨越楼层间的障碍,使得即使是最高层的信息也能清晰无误地传达出来。这正是ResNet之所以能在深度学习领域中独树一帜的原因所在!
4.5 ResNet152
ResNet-152 是一个拥有 152 层的残差网络,在 ImageNet 图像分类任务中达到当时顶尖性能,证明了“越深越好”在合理结构下是可行的。
🔧 核心特点
| 特性 | 说明 |
|---|---|
| 层数 | 共 152 层(含卷积层和全连接层) |
| 参数量 | 约 6000 万(比 VGG 少,但更深) |
| 基础模块 | 使用 Bottleneck 残差块(1×1 → 3×3 → 1×1 卷积) |
| 跳跃连接 | 所有残差块均带 shortcut,解决梯度消失 |
| 输入尺寸 | 224×224 RGB 图像 |
| 输出 | 1000 类 ImageNet 分类结果 |
🏗️ 网络架构详解(分阶段)
ResNet-152 的结构按 5 个阶段(Stage) 组织,每个阶段包含若干 Bottleneck 块:
| 阶段 | 操作 | Bottleneck 块数量 | 输出特征图尺寸 | 通道数 |
|---|---|---|---|---|
| Stem | 7×7 conv (stride=2) + MaxPool | - | 56×56 | 64 |
| Stage 1 | Bottleneck × 3 | 3 | 56×56 | 256 |
| Stage 2 | Bottleneck × 8 | 8 | 28×28 | 512 |
| Stage 3 | Bottleneck × 36 | 36 | 14×14 | 1024 |
| Stage 4 | Bottleneck × 3 | 3 | 7×7 | 2048 |
| Head | Global Avg Pool + FC | - | 1×1 | 1000 |
这是 ResNet-152 区别于 ResNet-50(3-4-6-3)和 ResNet-101(3-4-23-3)的核心——Stage 3 用了 36 个残差块,使其总层数达到 152。
📐 层数计算方式:
- Stem: 1(conv)+ 1(pool)≈ 不计入主干
- 每个 Bottleneck 块 = 3 个卷积层
- 总卷积层数 = (3 + 8 + 36 + 3) × 3 = 150 层
- 加上最后的全连接层 → 152 层
⚡ 为什么能训练这么深?
传统 CNN 在超过 20 层后就会出现退化问题(准确率反而下降),但 ResNet-152 通过以下设计克服了这一难题:
- 残差学习(Residual Learning)
网络不再直接拟合目标映射 H(x),而是学习残差 F(x)=H(x)−x,使得优化更容易。
- 跳跃连接(Shortcut Connection)
输入 x 直接加到输出上:y=F(x)+x,让梯度可以“抄近路”回传,避免消失。
- Bottleneck 结构
用 1×1 卷积降维/升维,大幅减少计算量,使 152 层变得可行。
📊 性能表现(ImageNet)
| 模型 | Top-1 准确率 | Top-5 准确率 | 参数量 |
|---|---|---|---|
| ResNet-50 | 76.0% | 93.0% | 25.6M |
| ResNet-101 | 77.4% | 93.7% | 44.5M |
| ResNet-152 | 78.3% | 94.1% | 60.2M |
✅ ResNet-152 在 ILSVRC 2015 中夺冠,成为当时最强的图像分类模型之一。
🛠️ 应用场景
虽然如今已有更高效的模型(如 EfficientNet、ViT),但 ResNet-152 仍广泛用于:
- 迁移学习:作为强大的特征提取器(backbone)
- 目标检测:Faster R-CNN、Mask R-CNN 默认使用 ResNet-101/152
- 医学影像分析:因鲁棒性强,常用于 X 光、MRI 分类
- 学术研究基线:评估新方法时的对比模型
✅ 总结
ResNet-152 是深度学习史上的工程奇迹:它用简单的“加法”(x + F(x))撬动了百层网络的大门,证明了深度不是障碍,而是力量。
4.6 代码案例
✅ ResNet-152 被主流深度学习框架(如 PyTorch、TensorFlow/Keras)作为官方预训练模型,提供了开箱即用的 API 封装,你无需手动搭建网络,一行代码即可加载。
import torchvision.models as models
# 加载未训练的 ResNet-152
model = models.resnet152()
# 加载在 ImageNet 上预训练的 ResNet-152(推荐!)
model = models.resnet152(pretrained=True) # ⚠️ 注意:新版本已改为 weights 参数
# 新写法(PyTorch >= 1.12 推荐)
from torchvision.models import resnet152, ResNet152_Weights
weights = ResNet152_Weights.DEFAULT
model = resnet152(weights=weights)
# 查看结构
print(model)
4.7 总结
🌈 终极升华:ResNet 不仅是一个模型,更是一种思维范式——它告诉我们:有时候,最好的方式不是“努力变得更好”,而是“聪明地保持原样”。
- 它用“捷径”解决深度困境;
- 它用“残差”简化学习目标;
- 它用“堆叠”实现无限深化。
今天,ResNet 已成为无数下游任务(医学影像、自动驾驶、人脸识别)的基础组件。虽然 Transformer 正在崛起,但 ResNet 依然稳坐“经典之王”宝座。
✅ 最终小结:ResNet 是深度学习史上的“破局者”——它让深度不再恐惧,让网络真正“越深越强”。无论未来如何演变,它的思想都将永存。
5. 亚历克斯网络(AlexNet)
1)是什么
AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出的深度卷积神经网络(CNN),是首个在大规模图像分类任务中显著超越传统方法的深度学习模型。它在 ImageNet 大规模视觉识别挑战赛(ILSVRC-2012) 中以 Top-1 错误率 37.5% 的成绩夺冠,标志着深度学习时代的开启。
- 网络结构:共 8 层(5 个卷积层 + 3 个全连接层)
- 输入:224×224×3 RGB 图像
- 输出:1000 类别分类结果
- 训练设备:使用两块 NVIDIA GTX 580 GPU 并行训练
✅ 核心特点:首次大规模应用 ReLU、Dropout、数据增强、重叠池化等技术。
2)为什么
AlexNet 的提出具有里程碑意义,主要贡献包括:
- 证明了深度 CNN 的可行性与强大性能
- 首次用端到端方式从原始像素中自动提取特征,取代手工设计特征(如 SIFT、HOG)。
- 在 ImageNet 上取得突破性结果,错误率远低于传统方法。
- 引入关键技术组件并验证其有效性
- ReLU 激活函数:加速训练,缓解梯度消失。
- Dropout:有效防止过拟合,提升泛化能力。
- 数据增强:通过裁剪、翻转、颜色扰动等方式扩大训练集。
- 重叠池化(Overlapping Pooling):减少空间信息丢失,提升精度。
- 局部响应归一化(LRN):模拟生物神经元竞争机制(虽后续被 BN 取代)。
- 推动硬件与算法协同发展
- 首次大规模使用 GPU 加速训练,展示了深度学习对算力的需求。
- 奠定了现代 CNN 的基本架构范式:卷积 → 激活 → 池化 → 全连接
- 引爆深度学习浪潮
- 直接促使计算机视觉进入“深度学习时代”,后续 VGG、GoogLeNet、ResNet 等均受其启发。
3)什么时候用
- 学习深度学习基础时,作为理解 CNN 架构的经典案例;
- 在资源有限但需要快速实现图像分类任务时,可作为轻量级模型参考;
- 用于教学演示或历史对比研究(如与 LeNet、VGG 对比);
- 当目标数据集较小,且希望避免复杂模型时,可借鉴其结构设计思想。
💡 实际应用中,AlexNet 已基本被更优模型取代,但在理论学习中仍具重要地位。
4)什么时候不用
- 现代图像分类任务:已被 ResNet、EfficientNet、ViT 等模型大幅超越;
- 计算资源受限:参数量约 6000 万,推理速度慢,不适合移动端或实时系统;
- 高精度需求场景:Top-1 准确率仅 ~75%,远低于当前主流模型(如 ResNet-50 > 80%);
- 小样本学习:容易过拟合,缺乏现代正则化手段(如 BatchNorm)的支持。
⚠️ 总体而言:AlexNet 是一个“历史模型”,不再用于生产环境,但值得深入理解其设计理念。
5) 总结
| 维度 | 内容 |
|---|---|
| 地位 | 深度学习复兴的标志性模型,计算机视觉的“开山之作” |
| 核心创新 | ReLU、Dropout、GPU 并行训练、大规模数据驱动 |
| 关键影响 | 推动 CNN 成为主流,奠定现代深度学习基础 |
| 局限性 | 参数多、计算量大、结构较浅、部分技术已过时 |
| 学习价值 | 理解 CNN 基本流程、激活函数选择、正则化策略的重要案例 |
🌟 一句话总结:
AlexNet 不是当今最优模型,却是深度学习史上最重要的“第一块砖”——它证明了“深度神经网络能解决真实世界难题”。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)