高质量数据集、多模态数据处理与数据标注之间的关系
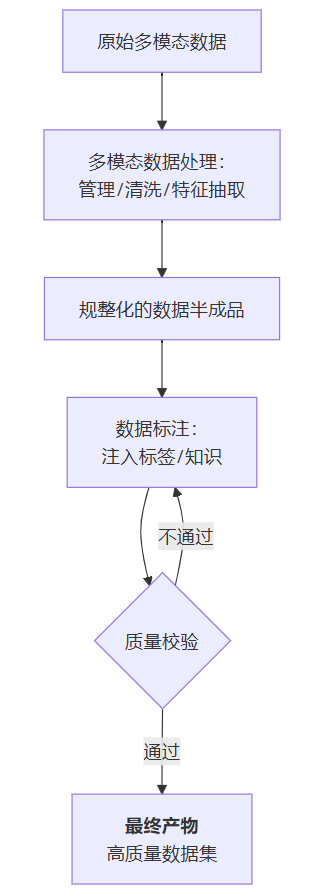
多模态数据处理、数据标注与高质量数据集构建构成递进式完整链路:数据处理是基础,通过清洗和格式统一使原始数据可用;数据标注是价值赋能,为数据添加语义标签;最终形成高质量数据集。三者环环相扣,分别解决"能用"、"有用"和"优质"问题,共同支撑AI模型训练的数据需求。
·
目录
三者是 “目标 - 手段 - 核心步骤” 的递进关系,共同构成 “从原始多模态数据到可用高质量数据” 的完整链路,具体关联如下:
1. 多模态数据处理是 “基础前提”
原始多模态数据(如杂乱的图像、带噪声的音频、未整理的文本)往往存在 “格式不统一、质量差、冗余” 等问题,无法直接用于模型训练。多模态数据处理(如之前提到的清洗、特征抽取、存储)的作用是 “把原始数据变‘可用’”:
- 先通过清洗去除噪声(如修复模糊图像、过滤音频杂音);
- 再通过格式适配、存储管理,让不同模态数据能被统一调用;
- 最终输出 “干净、规整” 的多模态数据,为后续标注和高质量数据集构建打下基础。
2. 数据标注是 “价值赋能”
“干净的多模态数据” 仍缺乏 “语义信息”(如图像里的 “猫”“狗”、文本里的 “正面 / 负面情绪”),模型无法理解其含义。数据标注的作用是 “给数据贴‘意义标签’”,让数据从 “无意义的字节” 变成 “有语义的样本”:
- 针对多模态场景,标注需覆盖不同类型(如文本分类标注、图像目标检测标注、音频情感标注);
- 标注质量直接决定数据集质量 —— 标注准确、一致,模型才能学到正确的规律。
3. 高质量数据集是 “最终结果”
当多模态数据经过 “处理(变可用)+ 标注(变有意义)” 后,再结合质量校验(如标注审核、数据均衡性调整),最终形成 “高质量数据集”。
简单说:多模态数据处理保障 “数据能用”,数据标注保障 “数据有用”,两者共同作用,才能产出高质量数据集。
总结三者之间的关系图:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)