时序数据集预处理
目录
参考TranAD(一个多元时间序列异常检测模型)中对于时序数据集预处理的方法,以SMD数据集为例展开讲讲如何处理这个数据集。
SMD数据集介绍:
SMD数据集下载链接: https://github.com/NetManAIOps/OmniAnomaly
在处理数据集前,我们需要充分了解这个数据集。
服务器机器数据集(Server Machine Dataset)
SMD是从一家大型互联网公司获得的数据集,收集28个不同机器的数据,总的时间周期为五周。数据集被均等分为训练集和测试集,并且各包含28个实体,每个实体包含了38个维度,其中训练集数据有708,405个样本,测试集有708,420个样本(1416825),训练数据集中的异常由专家标记,最后选择28个实体的平均分数作为最终的异常得分。
28个机器五周的数据,时间间隔1min,(五周总共有50400分钟,意味着每台机器要检测50401次,总共28台机器,则总共检测50401×28 = 1411228次)每个机器有38个特征。训练集和测试集的数据比例为1:1,适用于无监督异常检测模型。用SMD数据集跑模型的时候,28个机器的数据需要分开训练。
原文件:
原文件一共四个文件夹。分别是train,test,test_label,interpretation_label。28个机器分成了三组。(第一组有8个,第二组有9个,第三组10个)文件命名:machine-x-y.txt,表示第x组的第y个机器的特征。每一个machine-x-y.txt代表一个具体的机器的测试数据。38个特征包含CPU相关指标,内存相关指标,磁盘I/O指标,系统交换指标,TCP相关,UDP协议相关等。
其中的八个维度信息如图,红色区域表示异常。
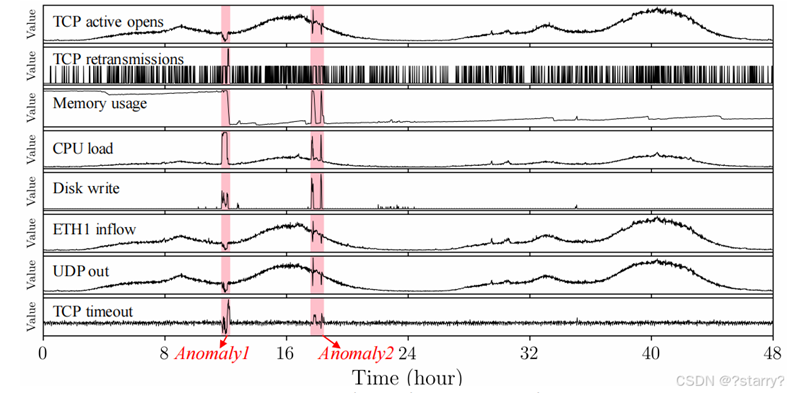
machine-1-1.txt,红圈中即第一台机器第一次在38个维度上测量的数据。
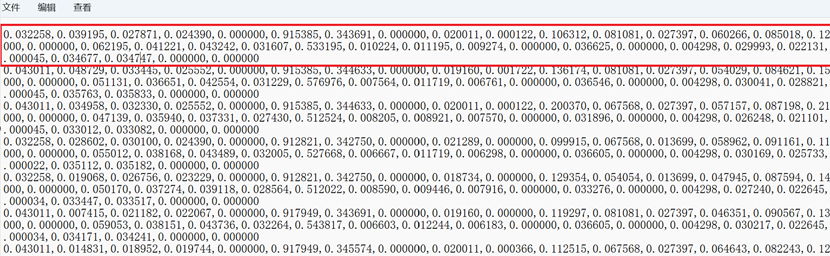
train:训练数据集,无标签。
test:测试数据集,有标签。
test_label:测试集的便签,0代表正常,1代表异常。
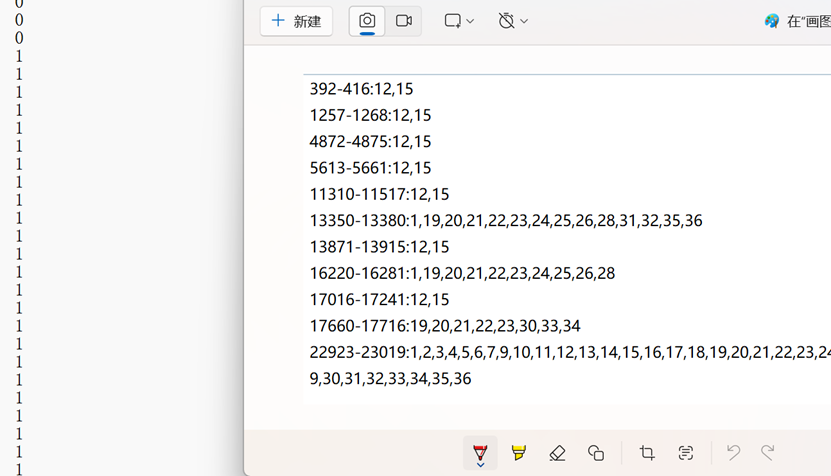
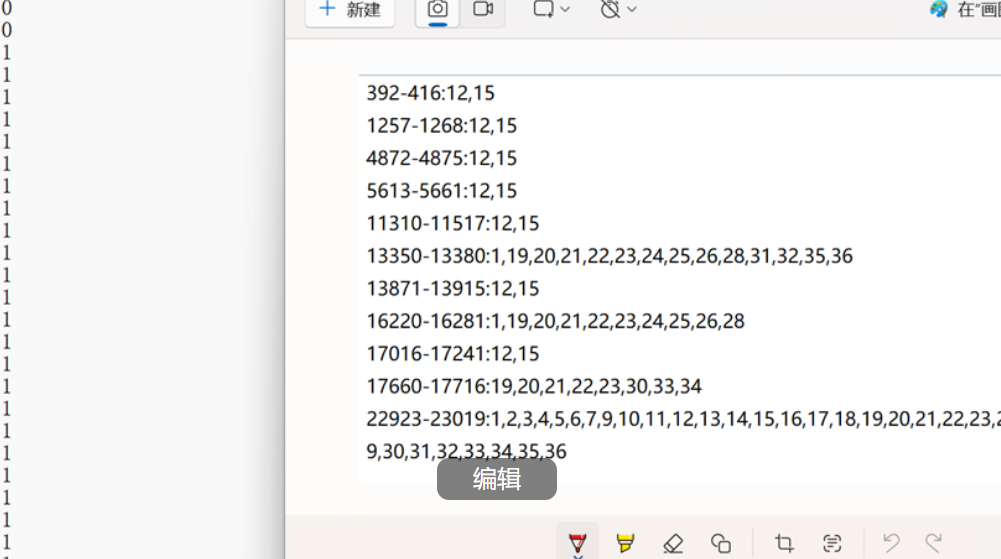
interpretation_label:对于异常数据,哪几个数据特征造成了最终的异常,只要有一个特征异常,本次测量就为异常,已验证interpretation_label中的异常区间和label中的异常值为1匹配,如下图右边的interpretation_label 中的392-416测量的12,15特征异常,对应左边label中的392-416行值为1。
SMD数据集预处理:
数据集最终处理后的格式:
下载SMD数据集后,经过我们的预处理后的数据集最终保存为如下图的numpy二进制数据格式,如machine-1-1,test,train,labels.npy的三个数据文件中存的数据维度都为(28456×38)。
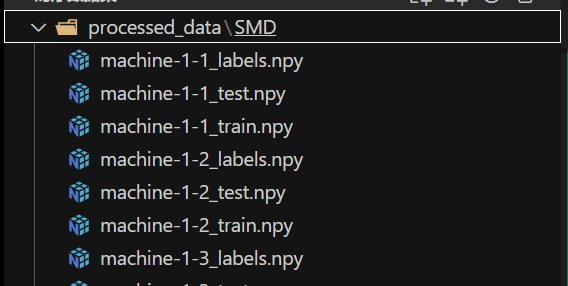
具体操作:
原始文件的数据是以csv格式保存的,我们需要将其转换为数组(numpy的二进制格式),在 numpy 中,无论是矩阵(二维数组)还是张量(多维数组 ),都可以通过 numpy 的二进制格式进行存储。比如使用numpy.save(),能够将矩阵或张量以二进制格式保存到文件中,后缀为npy,之后可以通过numpy.load()加载回内存。
由于trian,test和labels的数据文件的处理不同,我们将数据文件的处理分为两个函数,load_and_save()处理trian,test文件,load_and_save2()生成labels文件。
对于train和test中的machine-x-y.txt文件,直接修改后缀并将数据分割的“,”去掉,转换数据格式(dtype=np.float64,delimiter = ','),存为.npy就可以。
标签文件中的异常标签格式和test不匹配,为了标记test中的异常情况,需要将interpretation_label说明的异常情况转化为一个和test相同维度的矩阵(如28371×38)。具体操作是首先构造一个全零矩阵,如在interpretation_label中的machine-1-1.txt文件的第一行指明了392-416中的12,15特征异常,我们就把构造的对应的全零矩阵的391-415行索引,11列和15列索引的值变为1(矩阵式索引,需减去1)。
具体的处理构造labels操作代码如下:
# 逐行解析标签
for line in lines:
# 分割异常区间和异常维度(格式:"区间:维度列表")
pos_str, dims_str = line.split(':')[0], line.split(':')[1].split(',')
# print(f"处理标签: {pos_str} -> {dims_str}")
# 解析异常时间区间(格式:"start-end")
start, end = int(pos_str.split('-')[0]), int(pos_str.split('-')[1])
# 解析异常维度(原始数据是1-based索引,转换为0-based)
dims = [int(dim) - 1 for dim in dims_str]
# print(f"异常时间区间: {start}-{end}, 异常维度: {dims}")
# 在标签矩阵中标记异常
# 将对应时间区间和维度的位置设为1
# 注意:start-1和end-1是将1-based时间索引转换为0-based
temp[start-1:end-1, dims] = 1预处理完整代码:
import os
import sys
import numpy as np
# 定义输出文件夹根目录
output_folder = "./processed_data" # 所有处理后的文件将保存在此目录下
def load_and_save(category, filename, dataset, dataset_folder):
"""
加载指定类别的SMD数据文件,转换为NumPy数组并保存为.npy格式
参数:
- category: 数据类别('train'或'test')
- filename: 原始文件名(带.txt后缀)
- dataset: 数据集标识(去除.txt后缀的文件名)
- dataset_folder: SMD数据集根目录路径
返回:
- 数据的形状元组 (时间步数量, 特征维度)
"""
# 读取原始数据文件
# 使用numpy的genfromtxt函数读取CSV格式的文本文件
# 参数说明:
# - os.path.join: 拼接文件路径
# - dtype=np.float64: 强制转换为双精度浮点数
# - delimiter=',': 使用逗号作为分隔符
temp = np.genfromtxt(
os.path.join(dataset_folder, category, filename),
dtype=np.float64,
delimiter=','
)
# 打印数据基本信息
# 格式示例:SMD数据集 - machine-1-1 train 数据形状: (28479, 38)
print(f"SMD数据集 - {dataset} {category} 数据形状: {temp.shape}")
# 创建输出目录结构
# os.path.join: 拼接输出路径
# os.makedirs: 递归创建目录(如果不存在)
output_path = os.path.join(output_folder, "SMD")
os.makedirs(output_path, exist_ok=True)
# 保存处理后的数据
# 构建输出文件路径,格式为:{output_folder}/SMD/{dataset}_{category}.npy
# np.save: 将NumPy数组保存为二进制格式
output_file = os.path.join(output_path, f"{dataset}_{category}.npy")
np.save(output_file, temp)
print(f"已保存: {output_file}")
# 返回数据形状,用于标签矩阵的形状对齐
return temp.shape
def load_and_save2(category, filename, dataset, dataset_folder, shape):
"""
处理SMD的标签数据,将文本描述的异常区间转换为二进制矩阵并保存
参数:
- category: 数据类别(固定为'labels')
- filename: 原始标签文件名(带.txt后缀)
- dataset: 数据集标识(与测试数据对应)
- dataset_folder: SMD数据集根目录路径
- shape: 标签矩阵的形状(需与测试数据保持一致)
"""
# 创建标签矩阵
# 使用全零矩阵初始化,形状与测试数据相同
# 0表示正常,1表示异常
temp = np.zeros(shape)
# 解析标签文件
# 打开interpretation_label目录下的标签文件
# 标签文件格式示例:"100-200:1,3" 表示100-200时间步的第1、3维度为异常
with open(os.path.join(dataset_folder, 'interpretation_label', filename), "r") as f:
lines = f.readlines() # 按行读取所有标签信息
# 逐行解析标签
for line in lines:
# 分割异常区间和异常维度(格式:"区间:维度列表")
pos_str, dims_str = line.split(':')[0], line.split(':')[1].split(',')
# print(f"处理标签: {pos_str} -> {dims_str}")
# 解析异常时间区间(格式:"start-end")
start, end = int(pos_str.split('-')[0]), int(pos_str.split('-')[1])
# 解析异常维度(原始数据是1-based索引,转换为0-based)
dims = [int(dim) - 1 for dim in dims_str]
# print(f"异常时间区间: {start}-{end}, 异常维度: {dims}")
# 在标签矩阵中标记异常
# 将对应时间区间和维度的位置设为1
# 注意:start-1和end-1是将1-based时间索引转换为0-based
temp[start-1:end-1, dims] = 1
# 打印标签数据信息
# 格式示例:SMD数据集 - machine-1-1 labels 标签形状: (16499, 38)
# print(f"SMD数据集 - {dataset} {category} 标签形状: {temp.shape}")
# 创建输出目录结构
output_path = os.path.join(output_folder, "SMD")
os.makedirs(output_path, exist_ok=True)
# 保存标签矩阵
# 构建输出文件路径,格式为:{output_folder}/SMD/{dataset}_{category}.npy
output_file = os.path.join(output_path, f"{dataset}_{category}.npy")
np.save(output_file, temp)
print(f"已保存: {output_file}")
def load_data_smd():
"""专门处理SMD数据集的函数"""
# 输入数据路径
dataset_folder = "./SMD" # 当前目录下的SMD文件夹
# 确保输出目录存在
os.makedirs(os.path.join(output_folder, "SMD"), exist_ok=True)
# 处理所有训练文件
# 获取训练目录下的所有文件
train_dir = os.path.join(dataset_folder, "train")
# print(f"正在处理训练数据目录: {train_dir}")
file_list = os.listdir(train_dir)
print(f"找到 {len(file_list)} 个训练数据文件")
# 遍历所有txt文件(每个文件对应一个子数据集)
for filename in file_list:
if filename.endswith('.txt'): # 只处理txt格式文件
# 提取数据集名称(去除.txt后缀)
dataset_name = filename.strip('.txt')
# 处理训练数据
# 调用load_and_save函数加载并保存训练数据
load_and_save('train', filename, dataset_name, dataset_folder)
# 处理测试数据并获取形状
# 调用load_and_save函数加载并保存测试数据
# 同时获取测试数据的形状,用于标签矩阵的形状对齐
test_shape = load_and_save('test', filename, dataset_name, dataset_folder)
# testshape(23694, 38)
# 处理标签数据
# 调用load_and_save2函数处理标签数据
# 传入测试数据的形状,确保标签矩阵与测试数据对齐
load_and_save2('labels', filename, dataset_name, dataset_folder, test_shape)
if __name__ == '__main__':
# 脚本入口:仅处理SMD数据集
print("开始处理SMD数据集...")
load_data_smd() # 调用SMD数据集处理函数
# 打印最终输出路径
# os.path.abspath: 获取绝对路径
# os.path.join: 拼接路径
print(f"SMD数据集预处理完成,文件已保存到: {os.path.abspath(os.path.join(output_folder, 'SMD'))}")运行结果:
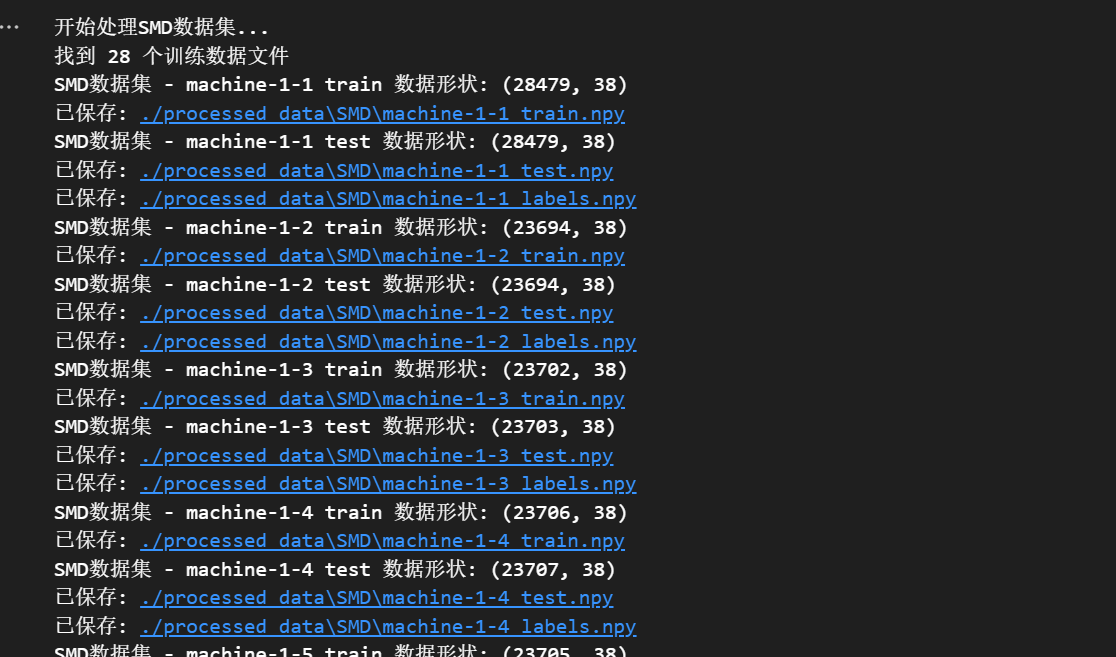
进一步查看我们保存的.npy文件信息
作者水平有限 ,如果你有任何问题或者想要与我交流异常检测这部分的研究,欢迎留言!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)