YOLO V1目标检测模型
YOLO(You Only Look Once)算法是一种目标检测算法,是经典的one-stage方法。YOLO v1 开创了单阶段目标检测的先河,其简洁的架构和高效的推理为后续版本(YOLOv2-v8)奠定了基础。尽管存在小目标检测和定位精度的局限性,但其“端到端”的设计思想深刻影响了目标检测领域的发展。YOLO-v1通过回归思想革新了目标检测流程,以速度和全局信息优势成为实时检测的里程碑。
文章目录
前言
YOLO(You Only Look Once)算法是一种目标检测算法,是经典的one-stage方法。YOLO v1 开创了单阶段目标检测的先河,其简洁的架构和高效的推理为后续版本(YOLOv2-v8)奠定了基础。尽管存在小目标检测和定位精度的局限性,但其“端到端”的设计思想深刻影响了目标检测领域的发展。
一、yolo v1模型的核心思想
将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。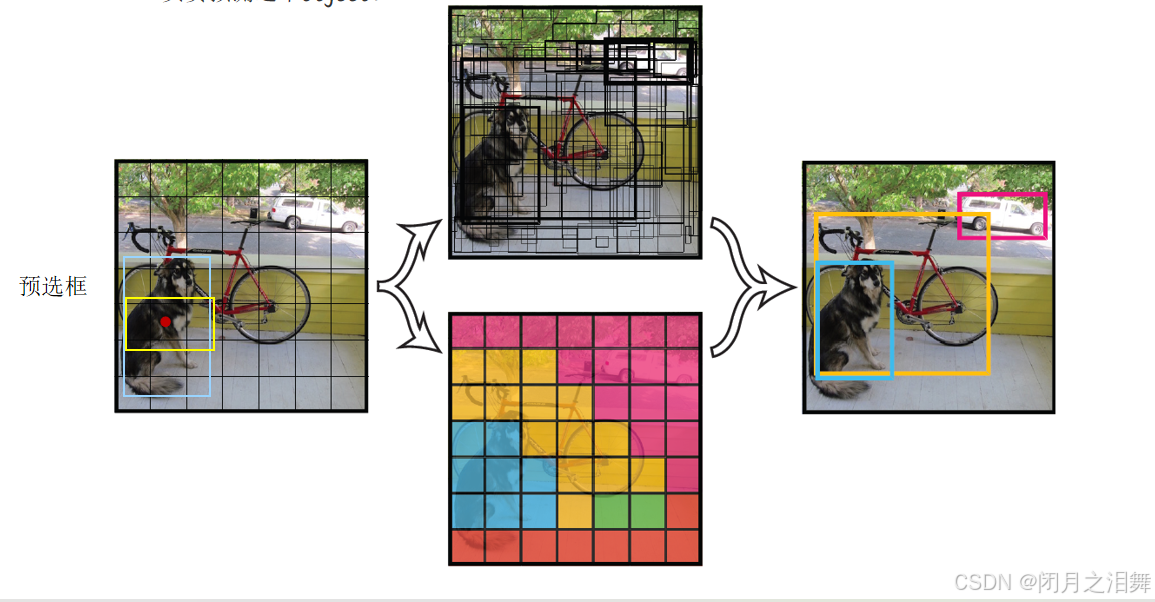
二、yolo v1的网络架构
1.网络架构
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )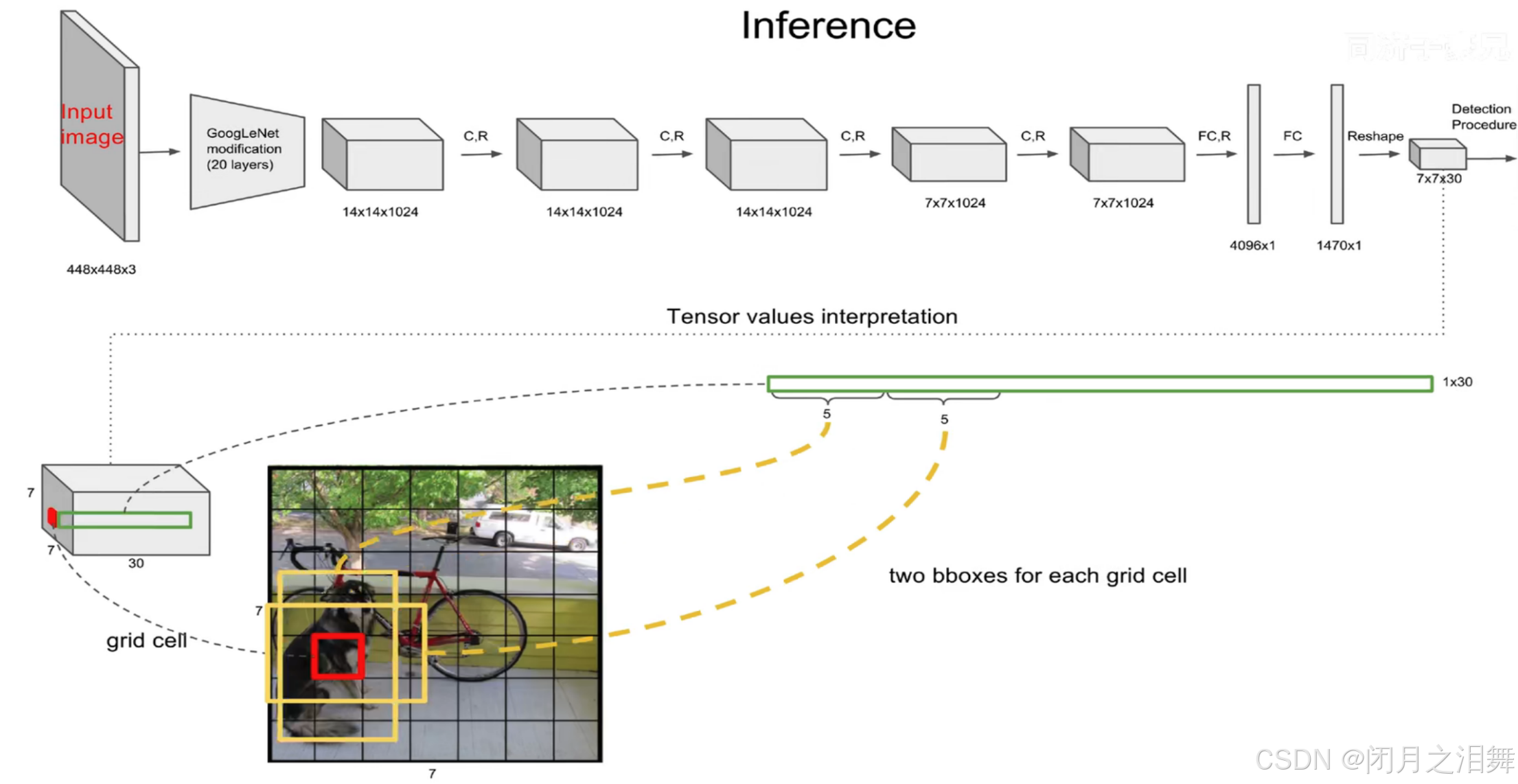
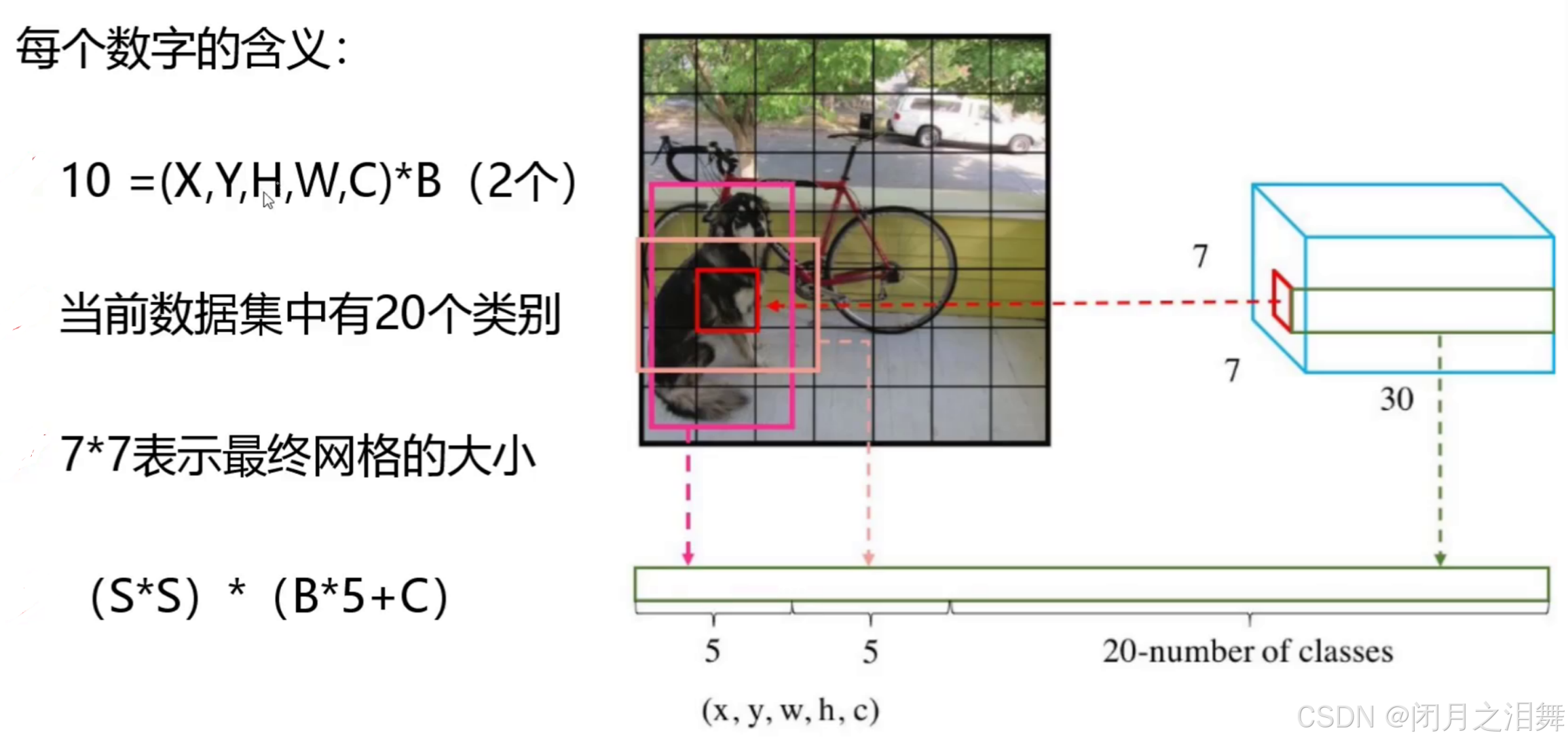
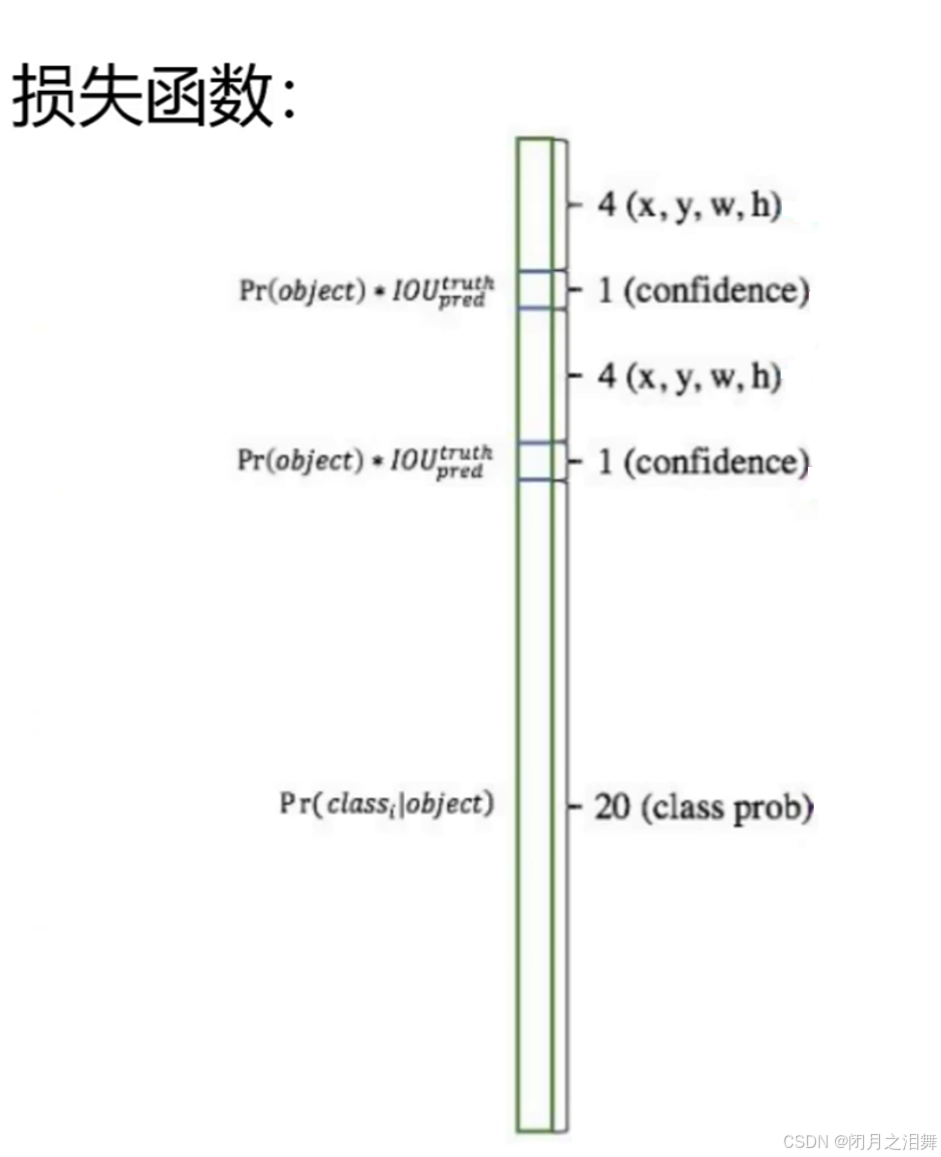
从上面的网络结构中发现经历多次卷积以及两次全连接后神经元的个数为1x1470,经过reshape后刚好变为7x7x30,7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中2个预测框(yolo-v1模型是有两个预测框的),每个预测框包含5个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度(confidence),剩下20个是针对数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。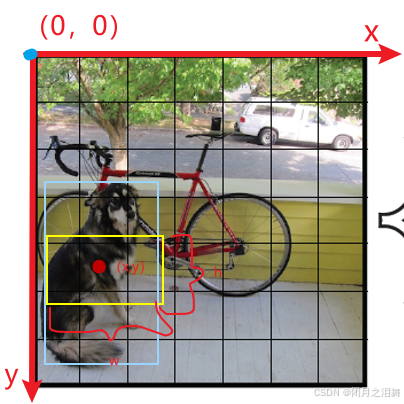
每个grid有30维,这30维中,8维是回归box的坐标,2个B是box的confidence,还有20维是类别。 其中坐标的x,y(相对于网格单元格边界的框的中心)用对应网格的归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。每个预测框的中心位置坐标是不同的。
三、损失函数
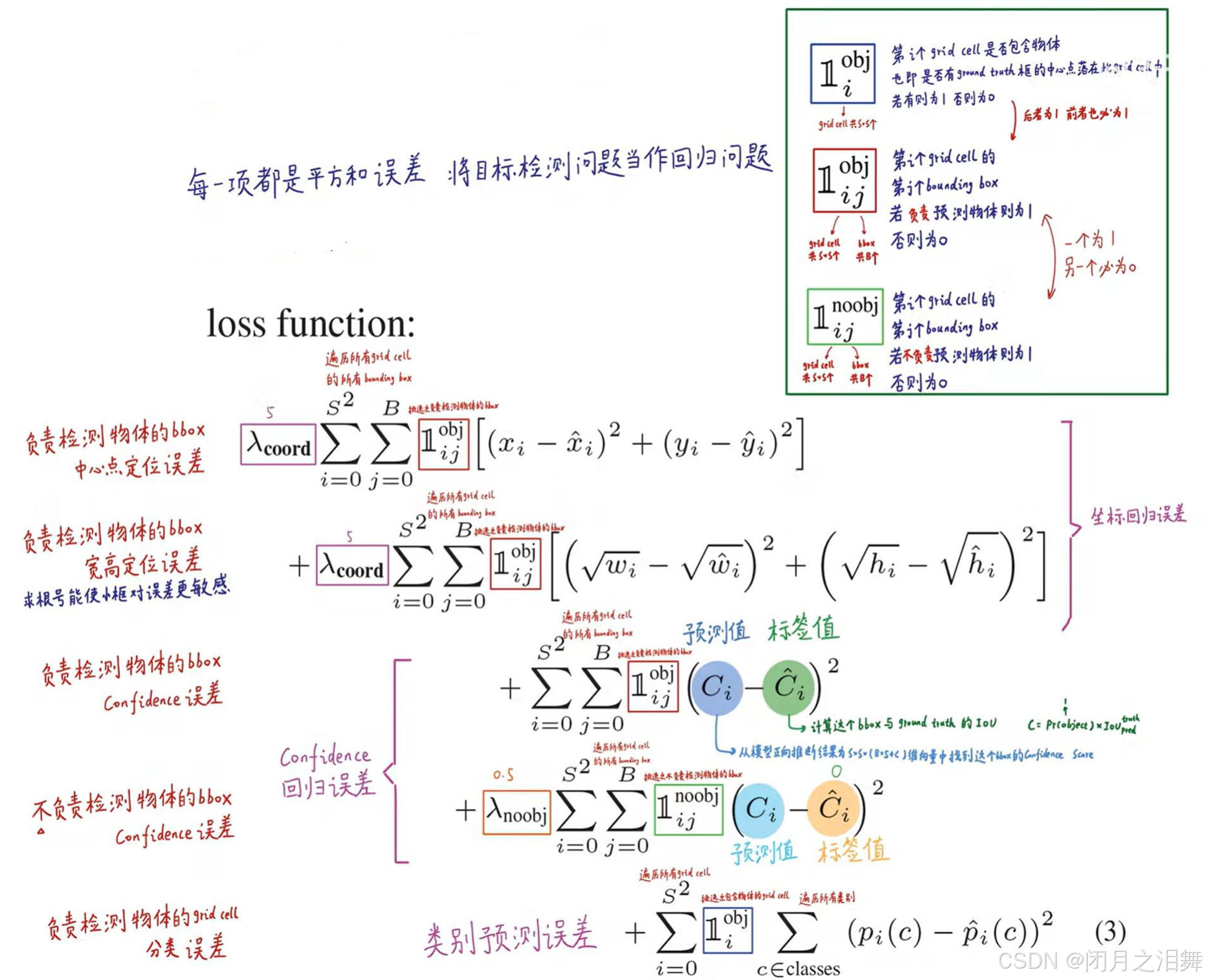
YOLO-V1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么YOLO的损失就包括三部分:位置误差,confidence误差,分类误差。
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。
1、三种误差与30维中的对应
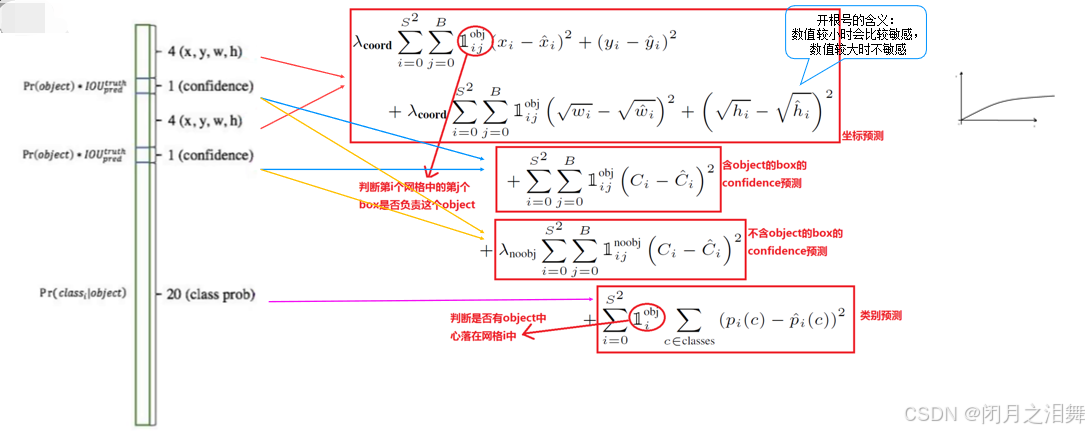
2、损失函数的组成
3、损失函数的详细计算
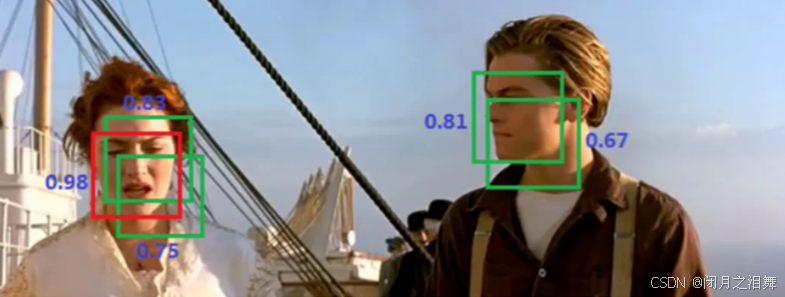
四、yolo v1中的非极大值抑制(NMS)
非极大值抑制(Non-Maximum Suppression, NMS)是目标检测中用于消除冗余检测框的后处理算法,其核心思想是:
在重叠区域中,仅保留置信度最高的检测框,抑制其他同类别且重叠度高的低置信度框,从而避免对同一物体多次重复检测。
1、核心步骤(yolo中):
(1)按置信度排序:对所有预测框按置信度(confidence score)从高到低排序。
(2)选取最高分框:将当前最高置信度的框作为保留结果。
(3)抑制重叠框:计算该框与剩余框的交并比(IoU),若IoU超过设定阈值(如0.5),则视为冗余框并剔除。
(4)循环迭代:对剩余未处理的框重复步骤2-3,直到所有框被处理。
2、关键作用
解决重复检测:模型可能对同一物体预测多个重叠框,NMS保留最优结果。
提升输出质量:减少假阳性(False Positive),使检测结果更简洁、准确。
平衡精度与召回率:通过调整IoU阈值,控制检测框的严格程度(阈值越高,保留框越少)。
五、yolo v1的优缺点
1、优点
实时性强
YOLO-v1的检测速度远超传统两阶段方法(如Faster R-CNN),基础模型可达到45 FPS,Fast YOLO版本甚至可达155 FPS,满足实时检测需求。
全局信息利用
模型以整张图像作为输入,利用全局上下文信息进行预测,减少了背景误检(背景错误率比Fast R-CNN低约50%)。
泛化能力强
由于学习的是目标的通用特征,YOLO-v1在迁移到新场景(如艺术作品或不同分辨率的图像)时表现较好,适应性优于基于区域提议的模型。
端到端训练
无需复杂的候选框生成步骤,直接通过回归输出边界框和类别概率,简化了训练流程,提升了效率。
2、缺点
定位精度不足
因使用均方误差(MSE)损失函数,定位误差(尤其是小目标的宽高预测)较大,导致平均精度(mAP)低于同期两阶段模型。
小目标检测效果差
输入图像被划分为7×7的网格,每个网格仅能预测一个目标,导致密集或小目标(如鸟群)易被漏检。
网格数量限制
每个网格最多预测2个边界框,且仅能输出一个类别,无法处理同一网格内多个目标重叠的情况。
对异常长宽比目标适应性差
模型在训练时未充分覆盖极端长宽比的物体,测试时对这类目标的检测性能显著下降。
全连接层限制
网络末端的全连接层需固定输入分辨率(448×448),导致检测时无法灵活适应不同尺寸的图像,可能因缩放引入形变误差。
总结
YOLO-v1通过回归思想革新了目标检测流程,以速度和全局信息优势成为实时检测的里程碑。然而,其定位精度和密集目标处理能力受限,后续版本(如YOLOv2/v3)通过引入锚框(Anchor Boxes)、多尺度预测等策略逐步优化了这些问题。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)