python基于随机森林的气温预测模型
摘要:本文提出了一种基于Python随机森林算法的气温预测模型,通过整合多维气象数据(温度、湿度、气压等)实现精准预测。模型采用Scikit-learn工具构建"数据采集-预处理-特征选择-训练预测"全流程,优化决策树参数提升性能。应用测试显示模型在农业、交通等领域具有实用价值,未来可通过特征扩展和算法集成进一步优化。
Python基于随机森林的气温预测模型
第一章 模型开发背景与核心意义
气温作为影响农业生产、交通出行、能源调度及日常生活的关键气象要素,其精准预测对社会各领域决策具有重要支撑作用。传统气温预测多依赖气象学公式推导或单一统计模型,难以充分捕捉气温与多重影响因素(如湿度、气压、风向、季节变化等)的非线性关联,预测精度与时效性难以满足实际需求。
随机森林算法凭借其抗过拟合能力强、处理高维数据高效、可解释性较好的优势,成为非线性回归预测的优选方案。Python依托Scikit-learn、Pandas、NumPy等成熟工具库,为随机森林模型的快速构建与优化提供了便捷环境。该模型的核心意义在于,通过整合多维度气象数据,利用随机森林算法挖掘气温变化的潜在规律,实现短中期气温的精准预测,为农业生产调度、灾害预警、公众出行规划等提供科学依据,提升气象服务的实用性与针对性。
第二章 模型整体设计框架
模型采用模块化递进架构,以Python为核心开发语言,构建“数据采集-数据预处理-特征工程-模型训练-预测输出”的全流程技术链路,确保预测的精准性与可靠性。
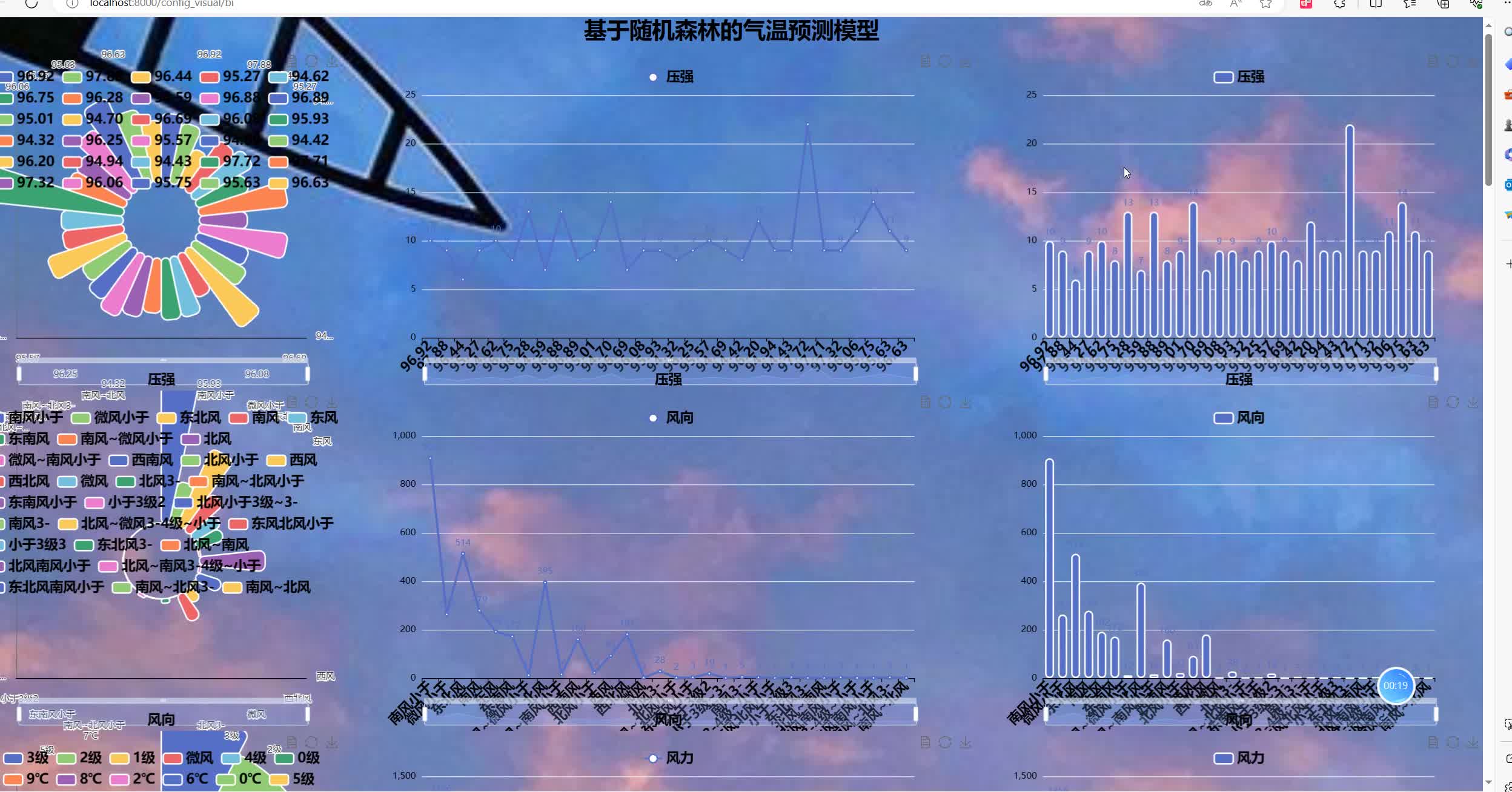
数据采集模块通过Python爬虫获取公开气象数据集(如国家气象科学数据中心、NOAA数据集),涵盖历史气温、湿度、气压、降水量、风向风速、日照时长等核心指标,支持多地区、多时段数据的批量采集与定时更新。数据预处理模块基于Pandas完成数据清洗(去重、剔除异常值)、缺失值填充(均值/中位数填充、插值法)与格式标准化,消除数据噪声干扰。特征工程模块通过相关性分析筛选关键影响因素,构建包含时间特征(季节、月份)、气象特征(湿度、气压)的特征集,提升模型输入质量。模型训练模块搭建随机森林回归模型,预测输出模块实现气温预测与性能评估。
第三章 模型核心功能实现
模型核心功能围绕气温的精准预测展开,聚焦数据处理与模型优化的关键环节,确保预测性能。
特征工程环节借助Python工具完成关键步骤:通过相关性分析与随机森林的特征重要性评估,筛选出对气温影响显著的核心特征(如前一日气温、相对湿度、气压变化、日照时长),剔除冗余信息,降低模型计算成本。模型构建采用Scikit-learn库中的RandomForestRegressor,通过网格搜索与交叉验证优化关键参数——设置决策树数量为100-200棵、最大深度为8-15层,平衡模型复杂度与泛化能力。
训练过程中,将数据集按7:3比例划分为训练集与测试集,采用均方误差(MSE)、平均绝对误差(MAE)作为评估指标,实时监控模型训练效果。预测阶段,输入预处理后的实时气象特征数据,模型快速输出短期(1-3天)或中期(7天内)气温预测值,同时通过特征重要性排名直观呈现各因素对气温的影响程度,提升预测结果的可解释性。
第四章 模型应用价值与未来展望
该模型的落地应用为多领域提供了高效的气温预测解决方案,具备显著实用价值。在农业领域,可精准预测气温变化助力作物播种时间规划、病虫害防治与灌溉调度,降低气象灾害对农作物的影响;在交通领域,为道路结冰、暴雨等恶劣天气预警提供气温数据支撑,保障通行安全;在能源领域,辅助电力部门预判制冷/供暖负荷,优化能源调度效率;在公众生活中,为出行、衣物穿搭等提供精准参考,提升生活便捷度。
未来,模型可进一步优化升级:拓展特征维度,融入地形地貌、城市化水平、卫星遥感数据等因素,提升复杂区域的预测精度;融合梯度提升树(XGBoost)、LightGBM等算法构建集成模型,强化预测性能;基于Python优化模型轻量化部署,适配移动端与边缘设备,提升实时预测能力;拓展预测时间尺度,结合长期气象数据实现月尺度、季尺度的气温趋势预测,为更长周期的决策提供支撑。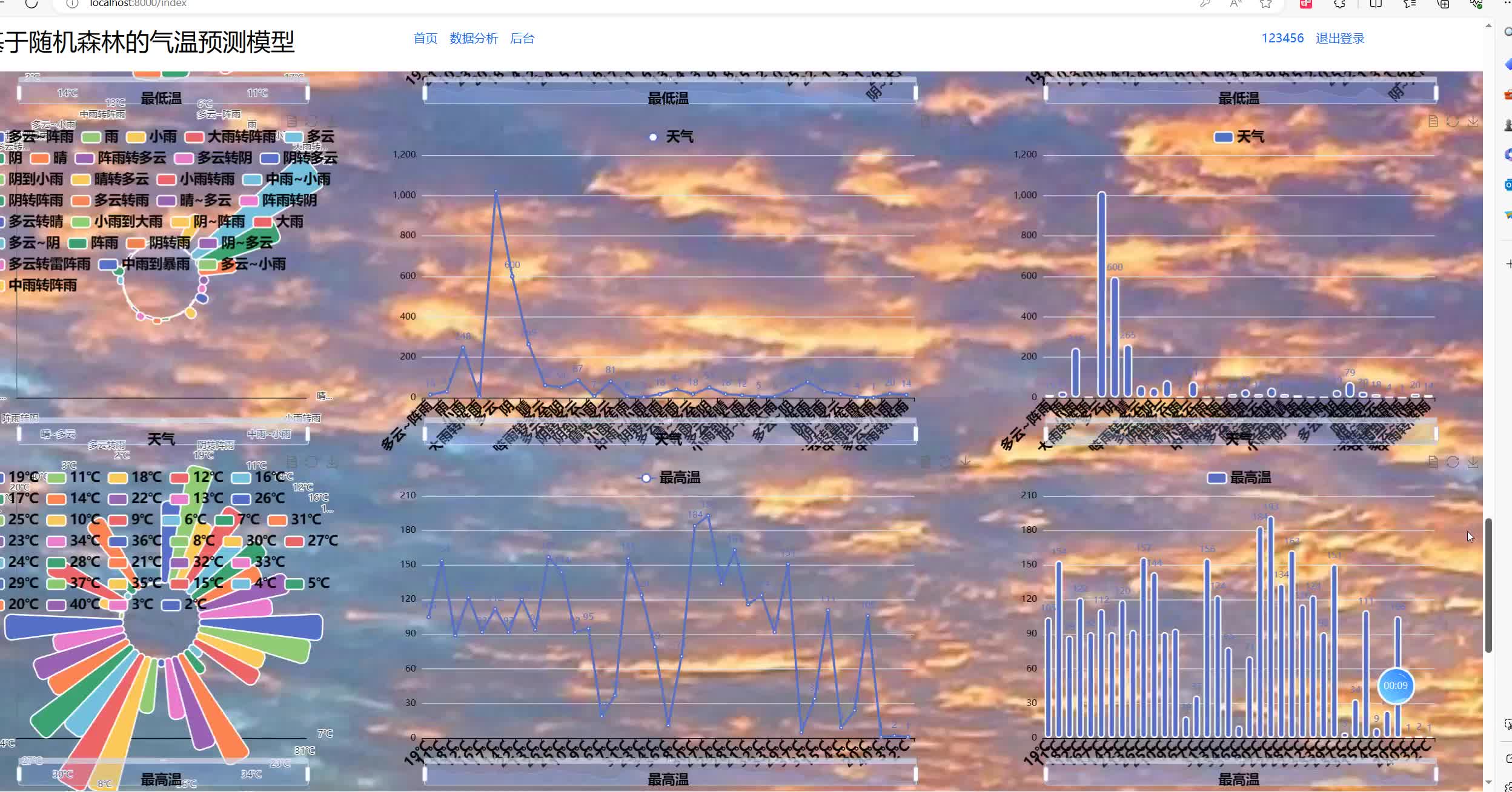
文章底部可以获取博主的联系方式,获取源码、查看详细的视频演示,或者了解其他版本的信息。
所有项目都经过了严格的测试和完善。对于本系统,我们提供全方位的支持,包括修改时间和标题,以及完整的安装、部署、运行和调试服务,确保系统能在你的电脑上顺利运行。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)