3D姿态估计【1】:【VGGT】Visual Geometry Grounded Transformer
一、核心要点
1. VGGT基于标准的大型Transformer,只做了轻量调整(local frame attention 和 global frame attention交替进行),支持一个、几个或者几百个视图的输入,并且输出场景所需的所有关键3D属性:相机内参、相机外参、depth、3D Point map、Tracks。
2. VGGT 是多任务统一预测,共享 backbone,利用不同的任务decoder进行特定任务的预测。作者认为并且实验验证,尽管潜在的冗余,但学习预测这些相互关联的3D属性仍提高了整体准确性,多任务统一训练要比单任务训练可以获得更好的效果。虽然 point map 有专门的预测头,但实际使用时,根据深度图 + 相机参数反推 point map,反而效果更好!
3. 作者在论文中强调,VGGT只需一次前向计算(单次推理),可以在不需要后处理优化的情况下,也可以获得比较好的效果(注:但在sanpo数据自测情况下,没有BA的后处理,姿态估计的效果不太准确)。论文中提到,在没有BA的情况下会不如DUSt3R、MASt3R、VGGSFM这类方法的结果,但相对其他方案仍有优势。
4. 作者认为,许多成功的 3D 方法都采用了Pairwise的训练方法,但这种方式存在瓶颈:训练阶段只处理图像对,而测试阶段却需要将多个图像对融合为一致的场景结构,二者之间存在结构性不匹配。这种不匹配导致模型在推理时依赖需要反复迭代,计算成本高的几何优化方法来进行后处理。
二、相关背景
Motivation
传统方法过于依赖视觉几何,主要是BA(Bundle Adjustment),这类方法都需要较高的计算开销和复杂度。例如VGGSFM这类方法,以及将深度学习和几何方法深度融合,并且通过可微分的BA实现端到端训练,但仍然无法完全绕过后期几何优化。虽然近期的一些方法,DUSt3R、MASt3R方法已经在尝试这样做,但只能处理两张图像,并且需要后处理才能得到完整重建结果
Contribution
- 提出 VGGT:可以一次性从任意数量的图像中预测出完整3D属性。
- 预测结果无需后处理就可直接使用,性能优于主流方法。
- 如果再加一点优化(如 BA 后处理),还能在所有任务上达到最优效果。
三、算法结构
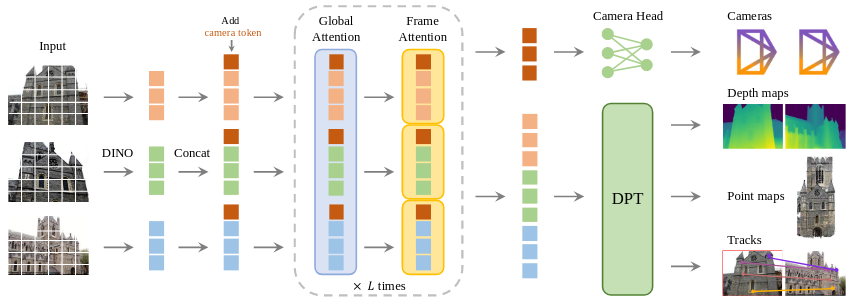
Input&Output: 输入一组图像序列,输出每一个图像的内外参、Depth、Point map、Tracks
其中,,
,
,
Feature Backbone: 每个输入图像最初都通过DINO处理成一组 k tokens,,DINO 是一个基于自监督的特征学习方法,能生成具有良好语义的 token 表达。
Add camera token: ,
是 camera token,
是 register token,第一帧会和其他帧区分开,可以是可学习的参数,也可以是认为设计的。现在refined camera 和 register token已经是针对于帧的嵌入信息,让transformer结构可以针对于不同帧有不同的处理结果,并且从相同图像中匹配
Alternating Attention(AA): 通过交替的自我和全局注意力层处理了所有组合图像的token集合,值的注意的是,AA方法中没有使用跨注意力的方式(如 Query-Key 不同源),全局注意力的实现方式是将所有token组合在一起,然后利用自注意力机制进行所有图像间的特征整合。论文中并未提到这种global attention的方式相较于cross attention优点在哪里。统一采用自注意力形式,这也是一种设计选择,可能是为了结构简单和训练稳定性。
Prediction heads:
-
所有预测结果(相机参数、点图、深度图)都在 第一帧的坐标系 下表达,第一帧的旋转四元数设置为单位四元数,平移向量设置为原点,这让其他帧的位姿预测都是相对第一帧的。
-
Camera Predictions:
通过 4 层自注意力 + 一层线性层预测出相机参数(内参+外参)。
-
Dense Predictions:
从每帧的refined token预测出深度图、点图、点轨迹。
Training Losses:
,损失函数使用的是 Huber 损失(
-鲁棒损失),比 L2 更抗离群值。
- 深度误差:带不确定性权重的残差
- 深度梯度误差:增强边缘清晰度
-
正则化项
,防止模型过度依赖不确定性掩盖误差。
-
点图损失与深度损失策略一致
四、算法思考
局限性(Limitations)
虽然模型在真实世界场景中具有良好的泛化能力,但仍存在三个主要限制:
- 不支持鱼眼或全景图像;
- 输入图像存在极端旋转时,重建效果显著下降;
- 虽然能处理轻微的非刚性变形,但在遇到大幅非刚性变形时会失败。
不过,作者强调其方法的适应性强:通过少量架构修改和在特定数据集上微调,就可以缓解这些限制。这比起其他方法更灵活,后者通常需要在测试阶段大幅修改结构才能适应特殊场景。
图像分块(Patchifying)
图像在输入网络前需要变成 token,作者尝试了两种方式:
-
自定义的 14×14 卷积;
-
使用 DINO v2 预训练模型。
实验发现 DINO v2 不仅性能更好,训练更稳定,对超参数如学习率、动量的敏感度更低,因此被选为默认方式。
可微 Bundle Adjustment(Differentiable BA)
-
作者尝试引入 “可微分 BA”(类似 VGGSfM 使用的)来优化3D重建。
-
初步实验显示效果不错,但 训练开销极大 —— 使用 Theseus 框架使每个训练步骤变慢约 4倍。
-
虽然加速 BA 是潜在方向,但不在本文研究范围,因此未纳入最终模型。
单视图重建(Single-view Reconstruction)
-
相比 DUSt3R 或 MASt3R 等需要复制图像组成图对的方法,VGGT 支持直接输入单张图像。
-
单图时,自注意力会退化为逐帧注意力(frame-wise attention)。
-
虽未专门为单图训练,但表现也很不错。可参见可视化结果

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)