强化学习 FrozenLake 简单探索 2个例子。
对于 4x4 的地图,很容易得到结果,但是如果换成 8x8 的地图,很容易失败!就是因为地图太大,所以失败率太高,永远无法到达目标!第3种方法, sarsa , 后面再继续写。搜索范围越大,越容易失败。
·
起因, 目的:
先说失败的原因:
对于 4x4 的地图,很容易得到结果,但是如果换成 8x8 的地图,很容易失败!!!
就是因为地图太大,所以失败率太高,永远无法到达目标!!!
举个例子, 假设对于同一个苹果而言:
- 在一个抽屉里面找一个苹果
- 在一个房间里面找一个苹果
- 在一个学校里面找一个苹果
- 在一个城市里面找一个苹果.
搜索范围越大,越容易失败。
要求, 使用3种方法来解决这个问题:
- First-visit Monte Carlo control without exploring starts.
- SARSA with an ϵ-greedy behavior policy.
- 𝑄-learning with an ϵ-greedy behavior policy
过程:
1. 先理解一下环境,我觉得是最重要的一步。
g1.py
import gymnasium as gym # pip install gymnasium
# 参考视频:https://www.youtube.com/watch?v=ZhoIgo3qqLU&ab_channel=JohnnyCode
def run():
# map_name="4x4", 或是 4x4 8x8
# is_slippery=True, 会导致用户的选择,失效,路太滑了,比如,我想往右,却滑到左边了.
env = gym.make('FrozenLake-v1', map_name="10x10", is_slippery=False, render_mode="human")
# Reset the environment to generate the first observation
# reset(), 作用是 returning an initial observation and info.
# 此时的 state 其实是数组的下标,从 0--63, 表示当前处于哪个格子。 等一下打印一下看看。
state = env.reset()[0]
terminated = False # terminated 掉进洞里, 或是到达目标了。
truncated = False # actions > 200, 成功了200次?
# for _ in range(1000):
score = 0
while not terminated and not truncated:
# this is where you would insert your policy
# action 0, 1, 2, 3, 移动方向,上下左右
action = env.action_space.sample()
# step (transition) through the environment with the action
# receiving the next observation, reward and if the episode has terminated or truncated
# observation 也被叫做是 new_state 新的状态
new_state, reward, terminated, truncated, info = env.step(action)
# print("action:", action, "new_state:", new_state, "reward:", reward, "terminated:", terminated, "truncated:", truncated, "info:", info)
print("action:", action, "new_state:", new_state, "reward:", reward, "score:", score)
# If the episode has ended then we can reset to start a new episode
# if terminated or truncated:
# observation, info = env.reset()
state = new_state
score += 1
env.close()
if __name__ == '__main__':
run()
2. 使用 q-table 来尝试解答
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
def run(episodes, img_name):
rng = np.random.default_rng(1) # 随机种子?
print(rng.random())
# env = gym.make('FrozenLake-v1', map_name="8x8", is_slippery=False, render_mode=None)
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=False, render_mode=None)
# 初始化 q-table 64行 * 4 列
q = np.zeros((env.observation_space.n, env.action_space.n))
learning_rate_a = 0.9 # alpha
discount_factor_g = 0.9 # gamma
epsilon = 1 # 1 = 100% 随机选择
epsilon_decay_rate = 0.0001 # 训练多少轮? 1 / 0.0001 = 10,000
# 统计一下训练的效果。
rewards_per_episode = np.zeros(episodes)
# 训练多少轮?
for i in range(episodes):
print(i)
state = env.reset()[0]
terminated = False
truncated = False
# 下面的过程,只是一局游戏。
while not terminated and not truncated:
if rng.random() < epsilon:
action = env.action_space.sample()
else:
# 使用 q-table 来选择行为, 方向。
action = np.argmax(q[state, :])
new_state, reward, terminated, truncated, info = env.step(action)
# 更新 q-table, 根据获得的奖励,来更新
q[state, action] = q[state, action] + learning_rate_a * ( reward + discount_factor_g * np.max(q[new_state, :]) - q[state, action] )
state = new_state
# 下面这些,依然是属于一次训练过程。
epsilon = max(epsilon - epsilon_decay_rate, 0)
if epsilon == 0:
epsilon_decay_rate = 0.0001
if reward == 1:
rewards_per_episode[i] = 1
env.close()
# 画图。
sum_rewards = np.zeros(episodes)
for t in range(episodes):
# 这里表示的是, 每100轮训练的奖励总共是多少
sum_rewards[t] = np.sum(rewards_per_episode[max(0, t-100): (t+1)])
plt.plot(sum_rewards)
plt.savefig(f"q-table--4x4-{img_name}.png")
if __name__ == '__main__':
for x in range(10):
run(15000, x)
得到效果大概是: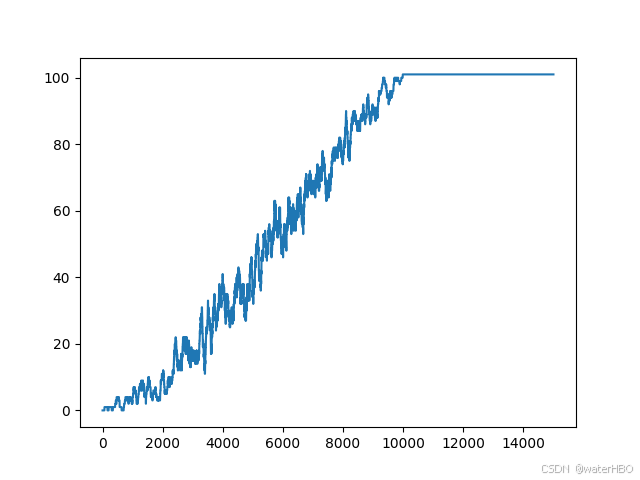
3. 使用 First-visit Monte Carlo
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
def run(episodes, img_name):
# env = gym.make('FrozenLake-v1', map_name="8x8", is_slippery=False, render_mode=None)
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery=False, render_mode=None)
# 初始化 Q 表:状态数 × 动作数
Q = np.zeros([env.observation_space.n, env.action_space.n])
# 用于记录每个 (state, action) 对被更新的次数(用于计算平均值)
New_Q = np.zeros([env.observation_space.n, env.action_space.n])
current_epsilon = 1.0
max_epsilon = 1.0
min_epsilon = 0.001
decay_rate = 0.0001
Reward_list = []
rng = np.random.default_rng() # 随机种子
for i in range(episodes):
print(i)
state, _ = env.reset()
visited_pairs = set() # 用于记录当前 episode 中已更新过的 (state, action)
y_list = [] # 用于存储本局中访问过的 (state, action) 序列
score = 0.0
terminated = False
truncated = False
while not terminated and not truncated:
if rng.random() < current_epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q[state, :])
new_state, reward, terminated, truncated, _ = env.step(action)
y_list.append((state, action))
score += reward # 对于 FrozenLake,reward 通常只有终点为1,否则为0
state = new_state
Reward_list.append(score)
# 仅对每个 (state, action) 的首次出现进行更新
visited = set()
for (s, a) in y_list:
if (s, a) not in visited:
visited.add((s, a))
New_Q[s, a] += 1.0
learning_rate = 1.0 / New_Q[s, a]
# 使用整个 episode 的总奖励(score)作为回报
Q[s, a] += learning_rate * (score - Q[s, a])
# 衰减 epsilon(保证探索)
current_epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * i)
env.close()
# 画图。
window_size = 100
success_rates = []
for t in range(len(Reward_list)):
start = max(0, t - window_size)
success_rates.append(np.mean(Reward_list[start:t + 1]))
plt.figure(figsize=(12, 6))
plt.plot(success_rates)
plt.title("Training Progress (100-episode moving average)")
plt.xlabel("Episode")
plt.ylabel("Average Reward")
plt.grid(True)
plt.savefig(f"mc-4x4-{img_name}.png")
if __name__ == '__main__':
for i in range(10):
run(20000, i)
print()
效果大概是: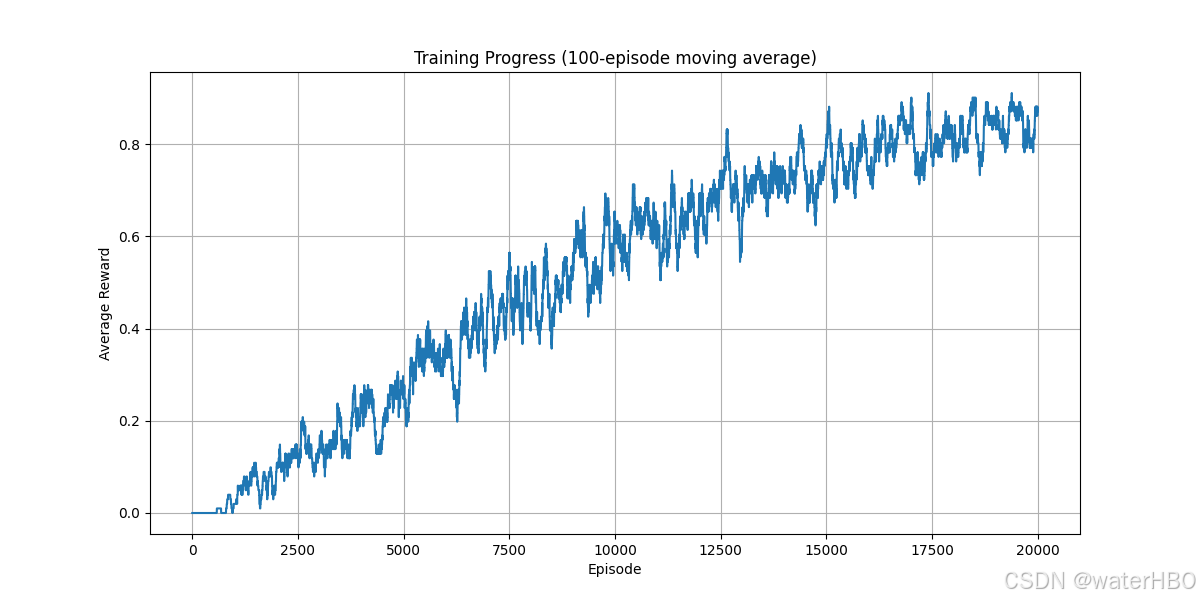
结论 + todo
第3种方法, sarsa , 后面再继续写。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)