基于图像的卷积神经网络微带天线建模
卷积神经网络(CNN)对图像具有强大的特征提取能力,在目标检测和图像识别中表现出高效率和高精度。当CNN用于建模微波设备时,现有文献通常将其尺寸参数作为一维(1-D)输入,这没有充分发挥CNN的图像处理能力。为充分利用CNN的特性,本文将微波设备的一维输入转换为图像模型形式,即将一维输入转换为由0和1组成的二维(2-D)矩阵作为输入。图像模型与CNN相结合,称为基于图像的CNN(ICNN),建立了
基于图像的卷积神经网络微带天线建模
作者信息
符浩¹,田雨波²⁺,孟飞²,李庆¹,任雪峰¹
¹江苏科技大学海洋学院,镇江市,中国
²广州航海学院信息与通信工程学院,广州市,中国
⁺通讯邮箱:tianyubo@just.edu.cn
摘要
卷积神经网络(CNN)对图像具有强大的特征提取能力,在目标检测和图像识别中表现出高效率和高精度。当CNN用于建模微波设备时,现有文献通常将其尺寸参数作为一维(1-D)输入,这没有充分发挥CNN的图像处理能力。为充分利用CNN的特性,本文将微波设备的一维输入转换为图像模型形式,即将一维输入转换为由0和1组成的二维(2-D)矩阵作为输入。图像模型与CNN相结合,称为基于图像的CNN(ICNN),建立了微波设备物理参数与电气特性之间的深度学习替代模型,提高了模型的精度和泛化能力。以微带天线的谐振频率为仿真例子,通过所提出的ICNN进行建模,并与主流机器学习方法进行比较。结果表明,该方法具有高收敛性和拟合精度。
引言
全波电磁仿真软件已成为天线设计的重要工具,然而,其高保真度仿真非常昂贵。因此,由于计算成本高,天线优化设计可能会受到电磁仿真求解器的限制。为解决这个问题,可以利用快速准确的机器学习(ML)替代模型。ML可以从输入数据中学习特征并给出预测结果。到目前为止,已有多种算法应用于微波设备建模,如高斯过程(GP)、支持向量机(SVM)、深度学习(DL)等。
J. P. Jacobs[1]提出了一种基于GP回归的双频微带天线谐振频率的精确建模方法。Jing Gao[2]提出了一种基于不同核函数的半监督GP协同训练方法用于天线谐振频率建模,将少量标记样本和未标记样本结合起来不断提高模型的准确性。Xie Zheng[3]提出了一种基于渐进GP的单极子天线设计。
Jing Gao[2]提出了一种基于GP和SVM的半监督协同训练算法。Dan Shi[4]提出了一种智能天线合成方法,根据天线性能要求自动选择适当的天线类型,并使用SVM提供最佳几何参数。
Jing Jin[5]将深度神经网络(DNN)方法引入高维微波建模领域,并提出了一种用于高维微波建模及其在微波滤波器参数提取中应用的DNN技术。Andrea Massa[6]提到,由于天线数值问题的复杂性,实时解决前向电磁(EM)问题仍然非常具有挑战性,而DNN正迅速成为显著加速标准EM求解器的有前途的候选者。
由于添加了局部感受野、参数共享和稀疏权重,卷积神经网络(CNN)相比其他神经网络具有平移和尺度不变性的特点,这使CNN能够有效提取特征,更适合图像数据处理[7]。张[8]提出了结合粒子群优化(PSO)和CNN的算法,用于高维紧凑像素微带天线的设计。与传统仿真软件的结果相比,优化结果很快获得。Jacobs[9]提出了一种基于CNN回归的双频像素微带天线谐振频率的精确建模方法,将天线的整个像素化表面作为输入。Hai-Ying[10]提出了一种使用CNN对超宽带(UWB)天线进行参数建模的方法。给定天线图像,CNN可以快速预测其电磁响应并加速设计过程。张提出的模型输入是天线尺寸参数的一维输入,而Jacobs和Hai-Ying提出的模型输入都是天线本身的图像。
现有文献中建立的模型通常将天线尺寸参数作为一维(1-D)输入,没有充分发挥CNN的图像处理能力。因此,为了提高CNN的建模精度,将微带天线尺寸参数建模为图像模型,即将一维模型输入映射为由1和0组成的二维(2-D)矩阵,类似于黑白图像数据,形成基于图像的CNN,并在本文中与传统ML方法获得的结果进行比较其预测性能。
模型构建
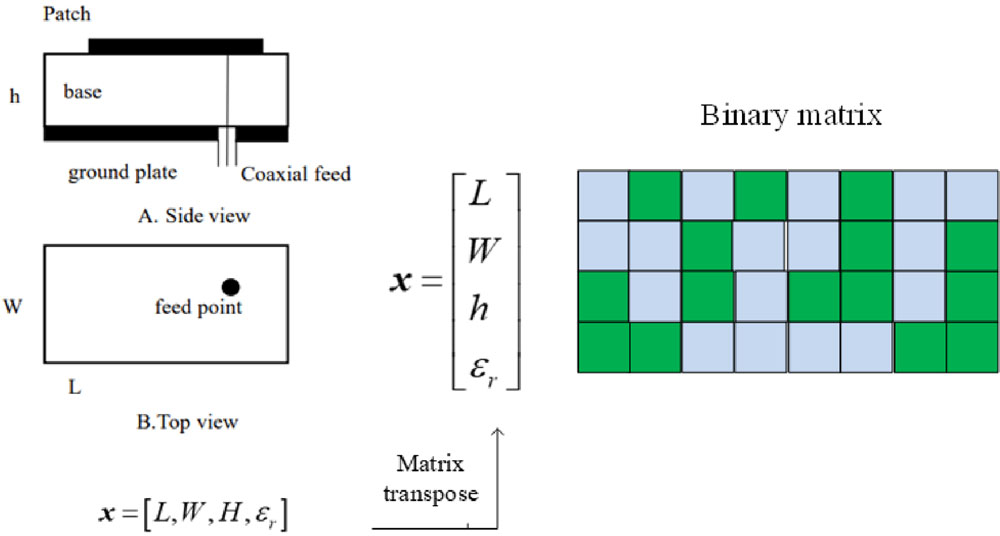
图1: 矩形微带天线图像模型的构建。
为了详细说明本文定义的图像模型,使用矩形微带天线(RMSA)进行说明。天线的长度为 L L L,宽度为 W W W,介电层的厚度为 h h h,相对介电常数为 ε r \varepsilon_r εr。
当CNN对RMSA的谐振频率进行建模时,其输入参数可以表示为 x = [ L , W , h , ε r ] x = [L, W, h, \varepsilon_r] x=[L,W,h,εr]。考虑到一维CNN不能充分发挥CNN模型的特性,构建了二维图像模型的形式,如图1所示。
具体而言,我们将天线的输入 x x x转置为由0或1组成的二进制字符串,其值表示为:
x i = ( x i ) ∗ m i n + ∑ ∗ k = 0 m − 1 a k 2 k 2 m − 1 ( ( x i ) ∗ m a x − ( x i ) ∗ m i n ) x_i = (x_i)*{min} + \frac{\sum*{k=0}^{m-1}a_k 2^k}{2^m-1}((x_i)*{max}-(x_i)*{min}) xi=(xi)∗min+2m−1∑∗k=0m−1ak2k((xi)∗max−(xi)∗min)
在公式中, ( x i ) ∗ m i n (x_i)*{min} (xi)∗min表示 x i x_i xi范围内的最小值, ( x i ) ∗ m a x (x_i)*{max} (xi)∗max表示 x i x_i xi范围内的最大值,m是二进制字符串的长度, a k a_k ak是1或0,表示该位置的存在。
在上述方程中,如果 ∑ k = 0 m − 1 a k 2 k \sum_{k=0}^{m-1}a_k 2^k ∑k=0m−1ak2k被视为 A A A,可以得出:
A = x i − ( x i ) ∗ m i n ( x i ) ∗ m a x − ( x i ) m i n ( 2 m − 1 ) A = \frac{x_i-(x_i)*{min}}{(x_i)*{max}-(x_i)_{min}}(2^m-1) A=(xi)∗max−(xi)minxi−(xi)∗min(2m−1)
其中, x i x_i xi、 ( x i ) ∗ m i n (x_i)*{min} (xi)∗min、 ( x i ) ∗ m a x (x_i)*{max} (xi)∗max和 m m m的含义与方程(1)相同。因此,可以获得A表示的十进制值,并形成天线结构参数(即问题空间)表示的十进制值与图1表示的二进制字符串(即图像模型空间)之间的对应关系。转换后以二维二进制字符串形式构建的图像模型用作CNN的输入,形成基于图像的CNN(ICNN),可以充分发挥CNN的视觉处理特性,使模型相比一维CNN更加准确。
在问题空间和图像模型空间之间的转换过程中,应满足以下三个规范:
- 完整性:问题空间中的每个一维向量都可以由图像模型空间中的二维二进制图像表示;
- 合理性:图像模型空间中的二维二进制图像对应于问题空间中的所有一维向量;
- 非冗余性:意味着问题空间中的一维向量与图像模型空间中的二维二进制图像之间的一对一关系。
仿真实验
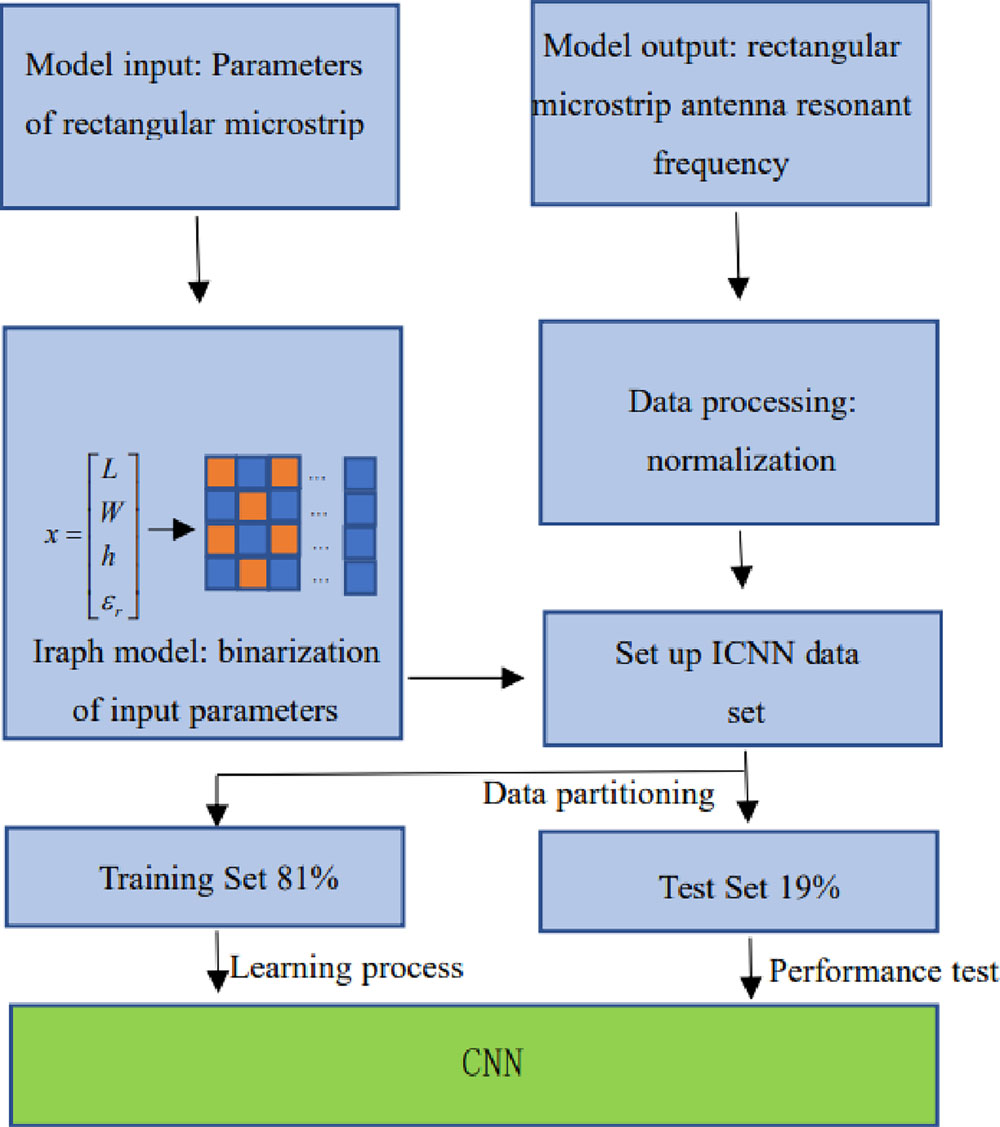
图2: 所提出的基于图像的卷积神经网络的流程图。
在这部分,通过所提出的ICNN对RMSA的谐振频率进行建模。
步骤1 传统上,当CNN用于对RMSA的谐振频率进行建模时,输入是由四个元素组成的一维向量 x = [ L , W , h , ε r ] x = [L, W, h, \varepsilon_r] x=[L,W,h,εr]。在所提出的ICNN中,如果控制每个元素的二进制字符串长度为10,则在图像模型处理后可以生成4×10的二维矩阵。总共有33组数据,分为两部分,其中27组(81%)用作训练样本,6组(19%)用作测试样本。图2是用于对RMSA谐振频率建模的ICNN流程图。
步骤2 确定ICNN的超参数是一个复杂的工程问题,对训练神经网络的准确性和泛化能力有显著影响,简要说明如下。
- 激活函数:为增强解决复杂问题的能力,神经网络中引入激活函数进行非线性变换。对于ICNN,我们使用Relu函数。
- 损失函数:损失函数确保ICNN在训练数据集上获得最佳性能。在本实验中,使用均方根误差(RMSE)和平均百分比误差(APE)来衡量回归输出值与现实目标值之间的偏差,使用决定系数R²来衡量回归模型的拟合程度。其公式如下:
R M S E = 1 N ∑ i = 1 N ( y i − Y i ) 2 RMSE = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(y_i-Y_i)^2} RMSE=N1i=1∑N(yi−Yi)2
A P E = 1 N ∑ i = 1 N ∣ y i − Y i ∣ ∣ y i ∣ ∗ 100 APE = \frac{1}{N}\sum_{i=1}^{N}\frac{|y_i-Y_i|}{|y_i|}*100 APE=N1i=1∑N∣yi∣∣yi−Yi∣∗100
R 2 = 1 − S S r e s S S t o t R^2 = 1-\frac{SS_{res}}{SS_{tot}} R2=1−SStotSSres
其中 S S r e s = ∑ i = 1 N ( y i − Y i ) 2 SS_{res} = \sum_{i=1}^{N}(y_i-Y_i)^2 SSres=∑i=1N(yi−Yi)2, S S t o t = ∑ i = 1 N ( y i − y ˉ ) 2 SS_{tot} = \sum_{i=1}^{N}(y_i-\bar{y})^2 SStot=∑i=1N(yi−yˉ)2, y ˉ = 1 N ∑ i = 1 N y i \bar{y} = \frac{1}{N}\sum_{i=1}^{N}y_i yˉ=N1∑i=1Nyi, y i y_i yi是实际值, Y i Y_i Yi是预测值, N N N是样本数量。
-
特征优化器:特征优化器用于找到损失函数的最优值。自适应矩估计(ADAM)计算梯度的一阶矩估计和二阶矩估计,设计不同参数的独立自适应学习率。随机梯度下降(SGD)是一种基于梯度的优化算法,可以帮助找到使损失函数最小化的参数。均方根传播(RMSProp)使用超参数来平滑动量项和平方梯度。它在目标函数的最优解方向上取得更大进展,可以减少迭代过程中梯度摆动过大的问题。
-
轮次数和批量大小:一个轮次是当整个数据集通过神经网络正向和反向传递一次时。如果整个数据集不能一次性传入算法,则必须将其分成几个小批量。批量大小是指单个批次中存在的训练样本总数。
根据实验的具体情况和一些先验知识,在表1中确定了模型超参数。CNN由三个卷积层和两个全连接层组成。在设置超参数的基础上,表2中显示了图像模型中卷积神经网络的结构。
步骤3 根据现有模型超参数使用训练样本对ICNN模型进行训练。为确保实验的公平性和结果的可靠性,每个实验独立运行20次以获得最优值。在表3-5中显示了不同丢弃概率和优化器下RMSA的谐振频率测量结果。
表1:模型超参数
| 参数 | 值 |
|---|---|
| 优化器选择 | Sgd/Adam/Rmsprop |
| 卷积核 | 3 × 5 和 2 × 2 |
| 神经元数量 | 20 |
| 批量大小 | 3 |
| Dropout | 0.01/0.05/0.1/0.2/0.3/0.4 |
| 训练轮次 | 200 |
表2:卷积神经网络的结构
| 输入尺寸 | 输出尺寸 | 权重矩阵尺寸 | |
|---|---|---|---|
| 卷积层1 | 4 × 10 × 1 | 4 × 8 × 2 | 2 × 5 × 2 |
| 卷积层2 | 4 × 8 × 2 | 4 × 6 × 4 | 2 × 5 × 4 |
| 卷积层3 | 4 × 6 × 4 | 3 × 5 × 8 | 2 × 2 × 8 |
| 全连接层1 | 120 | 100 | 100 × 120 |
| 全连接层2 | 100 | 20 | 20 × 100 |
| 输出层 | 20 | 1 | 1 × 20 |
比较和分析
在本节中,通过比较实验结果验证模型性能。
案例1:比较不同丢弃概率和优化器测量的RMSA谐振频率结果。
所提出的ICNN的参数设置如表1所示,实验结果如表3-表5所示。可以看出,不同的丢弃概率和优化器对实验结果有显著影响。在丢弃概率范围内,当丢弃概率等于0.1时,模型收敛性能达到最佳,然后随着丢弃概率的增加,收敛性能逐渐下降。三种优化器都有一定的收敛性能,但SGD比其他优化器具有更高的收敛精度。
表3:不同丢弃概率和优化器下矩形微带天线谐振频率的APE值
| 丢弃概率 | Sgd | Adam | Rmsprop |
|---|---|---|---|
| 0.01 | 1.2109 | 0.63047 | 1.3618 |
| 0.05 | 0.7728 | 0.9865 | 1.242 |
| 0.1 | 0.48210 | 1.2851 | 1.3187 |
| 0.2 | 0.6820 | 1.2163 | 1.3297 |
| 0.3 | 1.4585 | 1.7366 | 2.1876 |
| 0.4 | 2.8103 | 2.1548 | 1.5058 |
表4:不同丢弃概率和优化器下矩形微带天线谐振频率的RMSE值
| 丢弃概率 | Sgd | Adam | Rmsprop |
|---|---|---|---|
| 0.01 | 107.16 | 57.90 | 109.69 |
| 0.05 | 57.57 | 86.22 | 112.60 |
| 0.1 | 54.43 | 121.59 | 97.15 |
| 0.2 | 74.89 | 85.76 | 100.06 |
| 0.3 | 121.91 | 135.76 | 172.40 |
| 0.4 | 220.05 | 182.52 | 139.94 |
表5:不同丢弃概率和优化器下矩形微带天线谐振频率的R²值
| 丢弃概率 | Sgd | Adam | Rmsprop |
|---|---|---|---|
| 0.01 | 0.9721 | 0.9732 | 0.9594 |
| 0.05 | 0.9809 | 0.9670 | 0.9306 |
| 0.1 | 0.9977 | 0.9510 | 0.9262 |
| 0.2 | 0.9661 | 0.9253 | 0.8983 |
| 0.3 | 0.9108 | 0.9139 | 0.8690 |
| 0.4 | 0.8402 | 0.8464 | 0.8654 |
案例2:比较不同模型测量的RMSA谐振频率结果。
在这个案例中,表6列出了几个模型。它显示了ICNN、GP、深度核学习(DKL52)[11]和一维CNN对RMSA谐振频率建模和预测的比较结果。可以看出,与一维CNN相比,ICNN的精度提高了48%,与GP的APE相比提高了24%,与DKL52相比提高了18%。结果表明,ICNN具有更高的建模精度和更好的泛化能力。根据表6,表7中显示了表6中一维CNN模型的超参数。图3显示了RMSA谐振频率的实际值和ICNN的预测值。
表6:不同建模方法对矩形微带天线的预测结果
| f (MHz) | 1D CNN | GP [11] | DKL52 [11] | ICNN |
|---|---|---|---|---|
| 3200 | 3216.23 | 3196.581 | 3196.579 | 3149.43 |
| 3580 | 3597.51 | 3582.141 | 3584.779 | 3580.81 |
| 4805 | 4826.13 | 4830.272 | 4823.193 | 4789.17 |
| 5100 | 5122.44 | 5145.394 | 5088.715 | 5092.45 |
| 6200 | 6205.49 | 6198.311 | 6197.412 | 6162.057 |
| 8450 | 8142.09 | 8251.843 | 8239.441 | 8504.42 |
| APE | 0.9348 | 0.6400 | 0.519 | 0.4821 |
表7:一维卷积神经网络模型超参数
| 参数 | 值 |
|---|---|
| 优化器选择 | sgd |
| 卷积核 | 2×1 |
| 批量大小 | 3 |
| Dropout | 0.1 |
| 训练轮次 | 200 |
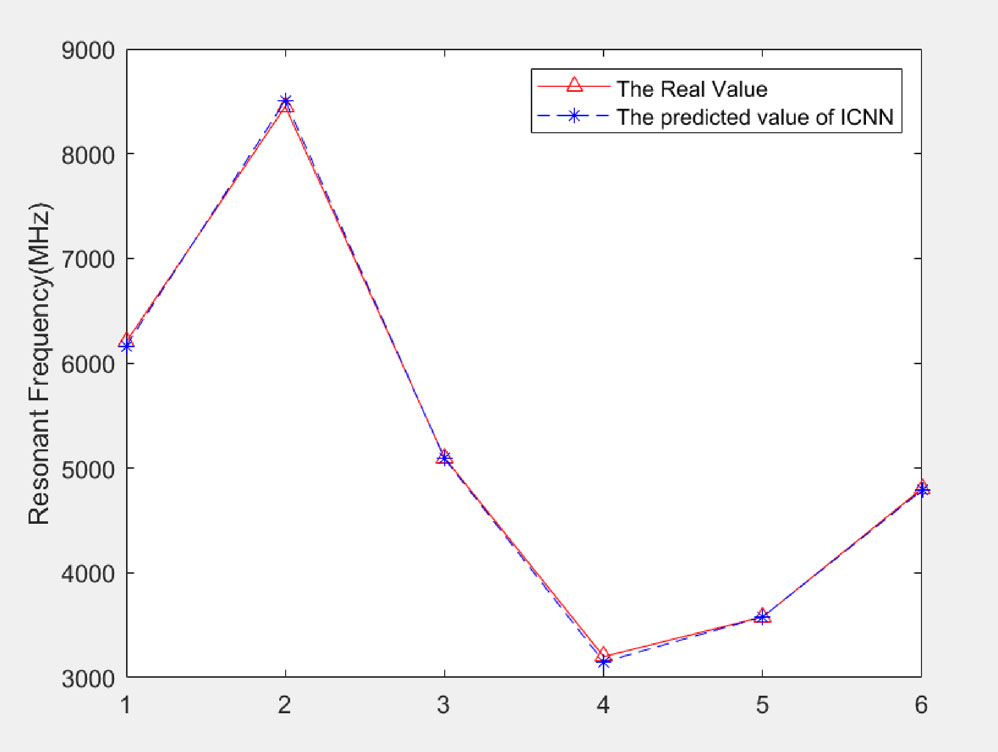
图3:矩形微带天线共振频率的真实值和基于图像的卷积神经网络的预测值
结论
在本文中,我们提出了一种新的数据处理技术-图像模型,将原始一维数据转换为二维图像,以增强CNN建模的强大特征提取能力。通过微带天线谐振频率建模示例,测试了算法的性能。实验结果表明,所提出的替代模型的性能优于其他建模方法。本文所述方法可以轻松扩展到其他微波工程领域。
致谢
本研究得到中国广东省自然科学基金(资助号2023A1515011272)、中国广东高校重点领域专项项目(编号2022ZDZX1020)和中国广州市教育局高等教育科研项目(编号202234598)的支持。
参考文献
- Jacobs, J.P.: Efficient resonant frequency modeling for dual-band microstrip antennas by Gaussian process regression. IEEE Antennas Wirel. Propag. Lett. 14, 337–341 (2014)
- Gao, J., Tian, Y., Chen, X.: Antenna optimization based on co-training algorithm of Gaussian process and support vector machine. IEEE Access 8, 211380–211390 (2020). https://doi.org/10.1109/ACCESS.2020.3039269
- Zheng, X., Meng, F., Tian, Y.,Zhang, X.: Design of monopole antennasbased on progressive Gaussian process. Int. J. Microwave Wireless Technolog. 15(2), 1–8 (2022). https://doi.org/10.1017/S1759078722000125
- Shi, D., Lian, C., Cui, K., Chen, Y., Liu, X.: An intelligent antenna synthesis method based on machine learning. IEEE Trans. Antennas Propag. 70(7), 4965–4976 (2022). https://doi.org/10.1109/TAP.2022.3182693
- Jin, J., Zhang, C., Feng, F., Na, W., Ma, J., Zhang, Q.-J.: Deep neural network technique for high-dimensional microwave modeling and applications to parameter extraction of microwave filters. IEEE Trans. Microwave Theory Tech. 67(10), 4140–4155 (2019). https://doi.org/10.1109/TMTT.2019.2932738
- Massa, A., Marcantonio, D., Chen, X., Li, M., Salucci, M.: DNNs as applied to electromagnetics, antennas, and propagation–A review. IEEE Antennas Wirel. Propag. Lett. 18(11), 2225–2229 (2019) https://doi.org/10.1109/LAWP.2019.2916369
- McCann, M.T., Jin, K.H., Unser, M.: Convolutional neural networks for inverse problems in imaging: A review. IEEE Signal Process Mag. 34(6), 85–95 (2017)
- Zhang, X., Tian, Y., Zheng, X.: Optimal design of fragment-type antenna structure based on PSO-CNN[C], In: 2019 International Applied Computational Electromagnetics Society Symposium-China (ACES), pp. 1–2. IEEE, Piscataway, NJ (2019)
- Jacobs, J.P.: Accurate modeling by convolutional neural-network regression of resonant frequencies of dual-band pixelated microstrip antenna. IEEE Antennas Wirel. Propag. Lett. 20(12), 2417–2421 (2021)
- Luo, H.-Y., Hong, Y., Lv, Y.-H., Shao, W.: Parametric modeling of UWB antennas using convolutional neural networks, In: 2020 IEEE International Symposium on Antennas and Propagation and North American Radio Science Meeting, pp. 2055–2056. IEEE, Piscataway, NJ (2020). https://doi.org/10.1109/IEEECONF35879.2020.9329697
- Han, S., Tian, Y., Ding, W., Li, P.: Resonant frequency modeling of microstrip antenna based on deep kernel learning. IEEE Access 9, 39067–39076 (2021) https://doi.org/10.1109/ACCESS.2021.3062940
我参考这篇论文中这些参数的设置,基于Pytorch 2.5.0+cpu对该ICNN模型进行了重新的训练。其中数据集选择200组,并划分为80%作为训练集,20%作为验证集。此外,额外使用15组数据作为测试集
| 类型 | 数量(组,每一组是一张图片) |
|---|---|
| 训练集 | 160组 |
| 验证集 | 40组 |
| 测试集 | 15组 |
下面将展示用于训练的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from PIL import Image
import pandas as pd
import os
# 超参数设置
batch_size = 3
learning_rate = 0.001
num_epochs = 200
train_val_split = 0.8 # 训练集占80%
dropout_rate = 0.1
normalization_mean = [0.5]
normalization_std = [0.5]
class ImageRegressionDataset(Dataset):
def __init__(self, csv_path, img_dir, transform=None):
self.labels_df = pd.read_csv(csv_path) # 直接读取CSV
self.img_dir = img_dir # 图片路径
self.transform = transform
def __getitem__(self, idx):
img_name = os.path.join(self.img_dir, self.labels_df.iloc[idx, 0])
image = Image.open(img_name)
label = torch.tensor(self.labels_df.iloc[idx, 1], dtype=torch.float32)
if self.transform:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.labels_df)
# 定义数据预处理 - 移除Resize操作
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize(mean=normalization_mean, std=normalization_std) # 使用超参数
])
# 创建数据集并划分训练集/验证集
full_dataset = ImageRegressionDataset(
csv_path="./data/label.csv", # CSV路径
img_dir="./data/image/", # 图片文件夹路径
transform=transform
)
# 按比例划分
train_size = int(train_val_split * len(full_dataset)) # 使用超参数
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
# 创建DataLoader
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 定义新的CNN架构 - 基于表格的网络结构
class CNNRegressor(nn.Module):
def __init__(self):
super(CNNRegressor, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=(1, 3), stride=1) # 卷积层1: 输入 4×10×1, 输出 4×8×2
self.conv2 = nn.Conv2d(in_channels=2, out_channels=4, kernel_size=(1, 3), stride=1) # 卷积层2: 输入 4×8×2, 输出 4×6×4
self.conv3 = nn.Conv2d(in_channels=4, out_channels=8, kernel_size=(2, 2), stride=1) # 卷积层3: 输入 4×6×4, 输出 3×5×8
# 全连接层
self.fc1 = nn.Linear(3 * 5 * 8, 100) # 120 -> 100
self.fc2 = nn.Linear(100, 20) # 100 -> 20
self.fc3 = nn.Linear(20, 1) # 20 -> 1
# 激活函数
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout_rate)
def forward(self, x):
# 卷积层
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
# 展平
x = x.view(-1, 3 * 5 * 8)
# 全连接层
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型、损失函数和优化器
model = CNNRegressor()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
print(f"Using device: {device}")
criterion = nn.MSELoss(reduction='mean') # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # 使用超参数
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs):
best_val_loss = float('inf')
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
for images, labels in train_loader:
# 将数据移到GPU
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs.view(-1), labels) # 修改:使用view(-1)替代squeeze()
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
# 验证阶段
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, labels in val_loader:
# 将数据移到GPU
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs.view(-1), labels)
val_loss += loss.item() * images.size(0)
val_loss = val_loss / len(val_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs} | "
f"Train Loss: {epoch_loss:.4f} | Val Loss: {val_loss:.4f}")
# 保存最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), "best_model.pth")
print("Training complete. Best Val Loss: {:.4f}".format(best_val_loss))
# 开始训练
train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs)
def predict(image_path, model, transform):
model.eval()
image = Image.open(image_path)
image = transform(image).unsqueeze(0).to(device) # 添加batch维度并移到GPU
with torch.no_grad():
prediction = model(image)
return prediction.item()
# 加载最佳模型
model.load_state_dict(torch.load("best_model.pth", weights_only=True))
# Generate consecutive image IDs
image_ids = [f"{i:03d}" for i in range(1, 16)]
for img_id in image_ids:
image_path = f"./验证集/validation_{img_id}.png"
predicted_value = predict(image_path, model, transform)
print(f"Predicted value for image_{img_id}.png: {predicted_value:.4f}")
完整的项目代码已经上传到github ICNN_res_frequency_predict上

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)