【机器学习|学习笔记】集成学习Boosting算法详解!
【机器学习|学习笔记】集成学习Boosting算法详解!
·
【机器学习|学习笔记】集成学习Boosting算法详解!
【机器学习|学习笔记】集成学习Boosting算法详解!
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/148877490
前言
- Boosting 是机器学习中一种非常重要的集成学习方法,特别适用于提升弱分类器的性能。下面我们将从机器学习的发展脉络出发,系统讲解 Boosting 的原理、演化过程、核心算法(如 AdaBoost、Gradient Boosting)、并用 Python 演示其具体实现。
✅ 一、Boosting 是什么?为什么提出它?
📌 背景:
- 早期的弱分类器(如决策树、线性模型)在复杂问题中表现不佳,Boosting 被提出用来提升弱模型的性能。
📌 核心思想:
- 将多个弱分类器(如浅层树)串联在一起,每一步都试图纠正前一步的错误,从而提升整体准确率。
🧠 二、Boosting 的发展与代表算法
| 阶段 | 算法 | 特点 |
|---|---|---|
| 初代 | AdaBoost | 基于加权错误率,重新分配样本权重 |
| 二代 | Gradient Boosting | 通过拟合残差最小化损失函数 |
| 三代 | XGBoost / LightGBM / CatBoost | 高效实现,适合大规模数据 |
📐 三、Boosting 的原理详解(以 AdaBoost 为例)
✅ 1. 主要步骤
- 初始化样本权重(均匀分配)
- 训练一个弱分类器(如决策树 stump)
- 根据错误率调整样本权重(错分样本权重提高)
- 多轮迭代,组合所有弱分类器的加权输出
✅ 2. 公式(简化版)
- 初始权重:
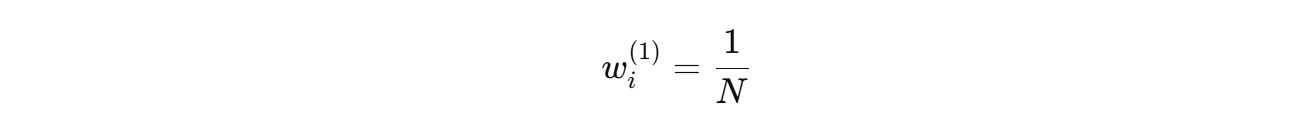
- 每轮训练弱分类器 h t ( x ) h_t(x) ht(x),计算加权错误率:
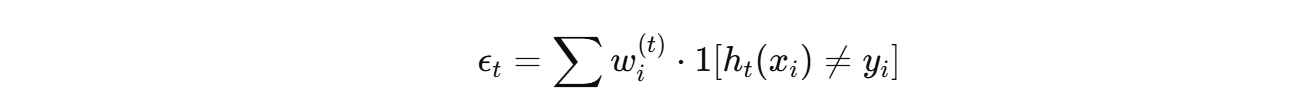
- 计算弱分类器权重:
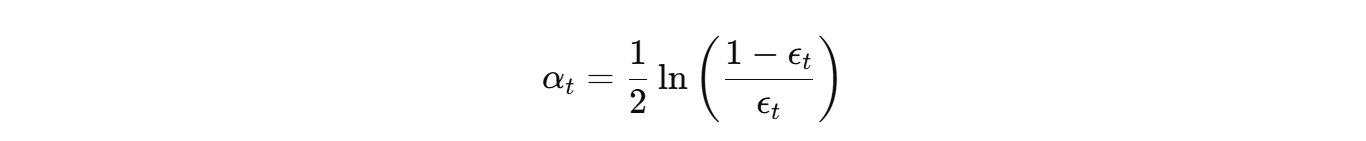
- 更新样本权重:
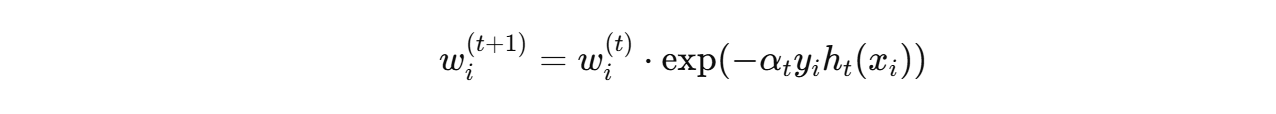
- 再归一化
🧪 四、Python 实战:AdaBoost 与 GradientBoosting
✅ 1. AdaBoost 示例
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 生成数据
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
# AdaBoost with decision stump
clf = AdaBoostClassifier(
base_estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
learning_rate=1.0
)
clf.fit(X_train, y_train)
# 输出结果
y_pred = clf.predict(X_test)
print("AdaBoost 分类报告:")
print(classification_report(y_test, y_pred))
✅ 2. Gradient Boosting 示例(GBDT)
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(
n_estimators=100, learning_rate=0.1, max_depth=3
)
gbdt.fit(X_train, y_train)
print("GBDT 分类报告:")
print(classification_report(y_test, gbdt.predict(X_test)))
📊 五、可视化效果(Boosting vs 单一模型)
- 你可以使用如下代码可视化训练过程的学习曲线:
import matplotlib.pyplot as plt
import numpy as np
stages = list(clf.staged_score(X_test, y_test))
plt.plot(np.arange(len(stages)), stages, label='AdaBoost test score')
plt.xlabel('Number of Estimators')
plt.ylabel('Accuracy')
plt.title('AdaBoost Test Accuracy Over Iterations')
plt.legend()
plt.grid(True)
plt.show()
⚙️ 六、主要参数说明(AdaBoost / GBDT)
| 参数 | 含义 | 建议 |
|---|---|---|
n_estimators |
弱分类器个数 | 通常 50~500 |
learning_rate |
每轮模型的贡献权重 | 小值防过拟合(如 0.01) |
max_depth(GBDT) |
决策树深度 | 控制模型复杂度 |
loss(GBDT) |
损失函数类型 | 可选 log_loss、deviance 等 |
✅ 七、Boosting 的优势与劣势
| 优点 | 缺点 |
|---|---|
| 可大幅提升弱分类器性能 | 训练较慢 |
| 可适配各种损失函数 | 对异常值敏感(AdaBoost) |
| 可用于回归、分类等多任务 | 容易过拟合小数据(需调参) |
🎓 八、小结
- Boosting 是提升模型性能的强大方法;
- 它将弱模型通过加权方式串联形成强模型;
- AdaBoost 关注样本权重,GBDT 关注残差;
- Python 中可使用
sklearn、xgboost、lightgbm等高效实现。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)