监督学习单模型—线性模型—对数几率回归
目录
一、广义线性模型
考虑单调可微函数 g(·)(其中 g(·) 连续且充分光滑),令 y = g-1(ωTx+b) ,这样得到的模型称为 “广义线性模型”(generalized linear model),其中函数 g(·) 称为 “联系函数”(link function)。显然,对数线性回归是广义线性模型在 g(·) = ln(·) 时的特例。
广义线性模型的参数估计常通过 “加权最小二乘法” 或 “极大似然法” 进行。
与回归问题不同,分类问题中模型的最终输出是一个离散值。我们所说的图像分类、垃圾邮件识别、疾病检测等输出为离散值的问题都属于分类问题的范畴。那么如何完成分类任务?只需找到一个单调可微函数将分类任务的真实标签 y 与线性回归模型的预测值进行映射。
二、对数几率回归
1. 对数几率函数
在线性回归中,我们直接令模型学习逼近真实标签 y ,但在对数几率回归中,我们需要找到一个映射函数将线性回归模型的预测值转化为 0/1 值。
对数几率函数(logistics function)正好具备上述条件:单调可微,取值范围为 (0,1) ,且具有较好的求导特性。对数几率函数的表达式为:
y = 1 1 + e − z \small y = \frac{1}{1+e^{-z}} y=1+e−z1
对数几率函数的图像如下图所示:
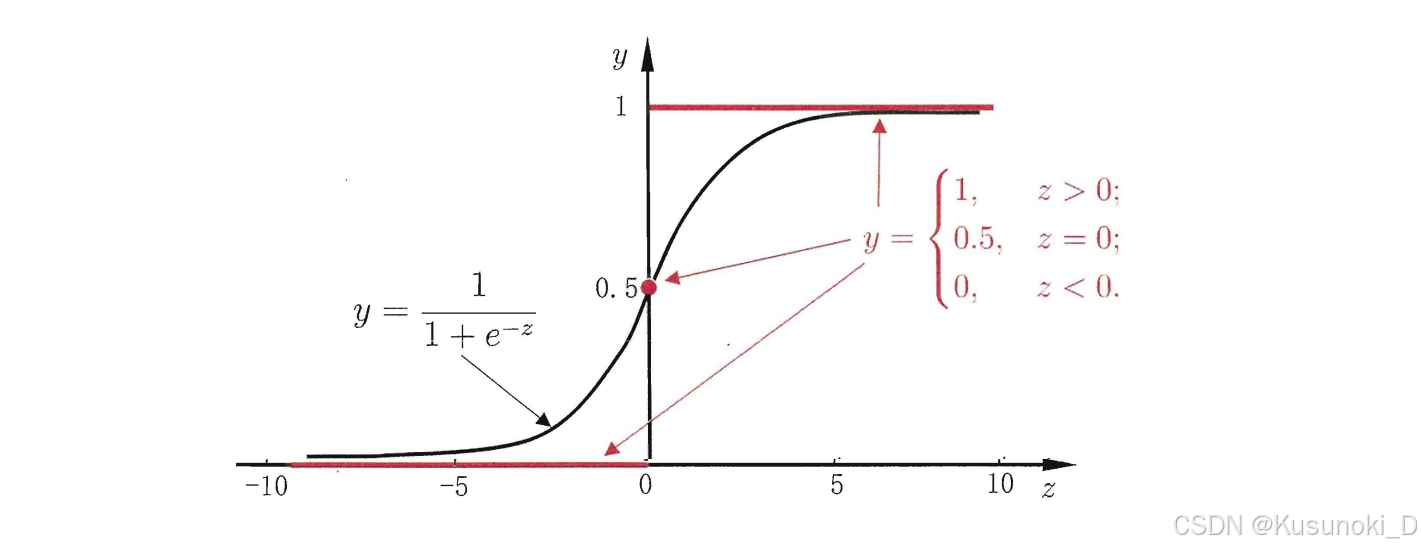
【拓展】:“单位阶跃函数”(unit-step function,亦称 Heaviside 函数):若预测值 z 大于零就判为正例,小于零则判为负例,等于临界值零则可以任意判别。注意:单位阶跃函数不连续。
Sigmoid 函数即形似 S 的函数,由上图可以看出,对数几率函数是 Sigmoid 函数中的一种。对数几率函数的一个重要特性是其求导函数可以用其本身来表达:
f ′ ( x ) = f ( x ) ⋅ ( 1 − f ( x ) ) \small f'(x) = f(x) · \big(1 - f(x)\big) f′(x)=f(x)⋅(1−f(x))
二元分类问题当中,因变量只属于两个类,0 表示负向类,1 表示正向类,即分类后训练样本的标签 y 都只等于 0 或 1 。对数几率回归是利用 Sigmoid 函数作为联系函数的广义线性模型解决二分类任务的一种方法。这个算法的性质是输出值保持在 0 到 1 之间,当算法输出值大于等于 0.5 时我们可以预测 y = 1 ,当算法输出值小于 0.5 时,我们预测 y = 0 ,从而进行数据的分类。
2. 对数几率回归的数学推导
已知 ω 为权重,b 为偏置,x 为输入特征。

若将 y 视为样本 x 作为正例的可能性,则 1 - y 是其反例的可能性,二者的比值 y 1 − y \small \frac{y}{1-y} 1−yy 称为 “几率”(odds),反映了 x 作为正例的相对可能性,对几率取对数则得到 “对数几率”(log odds,亦称 logit): ln [ y 1 − y ] \small \ln\big[\frac{y}{1-y}\big] ln[1−yy] 。
注意:对数几率回归(简称:对率回归)虽然名字含回归,但其实是一种分类学习方法!
对数几率回归的损失函数:
为了确定上述的模型参数 ω 和 b ,我们需要推导对数几率回归的损失函数,然后对损失函数进行最小化,得到 ω 和 b 的估计值。
1)交叉熵损失函数(Cross-entropy)

交叉熵是用来衡量实际分布和预测分布之间差异的指标(交叉熵的值越小,两个概率分布就越接近)。
【思考 1】:为什么 p ( y ∣ x ) = y ^ y + ( 1 − y ^ 1 − y ) \small p(y|x) = \hat{y}^y + (1-\hat{y}^{1-y}) p(y∣x)=y^y+(1−y^1−y) ?
p(y|x) 表示在给定特征 x 的条件下,y 取某个特定值(通常是 0 或 1)的概率。对于二分类的情境,已知 y ^ = p ( y = 1 ∣ x ) \small \hat{y} = p(y=1|x) y^=p(y=1∣x) ,则 1 − y ^ = p ( y = 0 ∣ x ) \small 1-\hat{y} = p(y=0|x) 1−y^=p(y=0∣x) 。
-
当 y = 1 时,yy = 1(即 11 = 1),(1 - y)(1-y) = 00 = 1(在数学上常被定义为 1,因此实际上在这里取值为 1)。
-
当 y = 0 时,yy = 1(即 00 = 1),而 (1 - y)(1-y) = 11 = 1 。
总结:当 y = 1 时,p(y=1|x) = 1 且 p(y=0|x) = 0 ;当 y = 0 时,p(y=0|x) = 1 且 p(y=1|x) = 0 。
【思考 2】:交叉熵损失函数前面为什么有一个负号?
已知对数函数 ln(x) 在区间 (0,1) 内为负,且 y ^ \small \hat{y} y^ 与 1 − y ^ \small 1-\hat{y} 1−y^ 的取值在 0 到 1 之间。机器学习中,我们通常希望通过优化算法(如梯度下降)最小化损失函数,因为交叉熵的输出是负值,我们在实践中会选择在损失函数前加一个负号,使得整体的损失能够为正值,方便优化。
【思考 3】:为什么要用 L ( y , y ^ ) = − [ y ⋅ ln ( y ^ ) + ( 1 − y ) ⋅ ln ( 1 − y ^ ) ] \small L(y,\hat{y}) = -[y\cdot \ln(\hat{y}) + (1-y)\cdot \ln(1-\hat{y})] L(y,y^)=−[y⋅ln(y^)+(1−y)⋅ln(1−y^)] 作为逻辑损失函数?
-
当 y = 1 时损失函数 L = − ln y ^ \small L = -\ln{\hat{y}} L=−lny^ ,如果想要损失函数 L 尽可能地小,那么 y ^ \small \hat{y} y^ 就要尽可能地大,因为 sigmoid 函数的取值是 [0, 1] ,所以 y ^ \small \hat{y} y^ 会无限接近于 1 .
-
当 y = 0 时损失函数 L = − ln ( 1 − y ^ ) \small L = -\ln{(1-\hat{y})} L=−ln(1−y^) ,如果想要损失函数 L 尽可能地小,那么 y ^ \small \hat{y} y^ 就要尽可能地小,因为 sigmoid 函数的取值是 [0, 1] ,所以 y ^ \small \hat{y} y^ 会无限接近于 0 。

基于 ω 和 b 的梯度下降对交叉熵损失最小化,相应的参数即为模型最优参数。
2)极大似然法(maximum likelihood method)


上式 𝓁(β) 是关于 β 的高阶可导连续凸函数,根据凸优化理论,经典的数值优化算法,如:梯度下降法、牛顿法、拟牛顿法等都可求得其最优解,于是就得到: β ∗ = arg min β l ( β ) \small \beta^\ast = \arg\min_\beta \mathscr{l}(\beta) β∗=argminβl(β) 。

从上述推导来看,对数几率回归虽是分类模型,但总体上仍属于线性模型框架,其推到思路跟线性回归有不少相似之处;一方面,我们可以直接基于模型主体推导出交叉熵损失函数,然后基于损失函数进行梯度优化;另一方面,也可以通过极大似然法来进行参数优化推导。
3. 对数几率回归的代码实现
1)基于 Numpy 的代码实现
【代码实现】:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets._samples_generator import make_classification
from sklearn.metrics import classification_report
# 定义sigmoid函数
def sigmoid(x):
z = 1 / (1 + np.exp(-x))
return z
# 定义参数初始化函数
def initialize_params(dims):
# 将权重向量初始化为零向量
w = np.zeros((dims, 1))
# 将偏置初始化为0
b = 0
return w, b
# 定义对数几率回归模型主体
def logistic(X, y, w, b):
# 训练样本数
num_train = X.shape[0]
# 训练特征数
# num_feature = X.shape[1]
# 对数几率回归模型输出
a = sigmoid(np.dot(X, w) + b)
# 交叉熵损失
cost = -1 / num_train * np.sum(y*np.log(a) + (1-y)*np.log(1-a))
# 权重梯度
dw = np.dot(X.T, (a-y)) / num_train
# 偏置梯度
db = np.sum(a-y) / num_train
# 压缩损失数组维度
cost = np.squeeze(cost)
return a, cost, dw, db
# 定义对数几率回归模型训练过程
def logistic_train(X, y, learning_rate, epochs):
# 初始化模型参数
w, b = initialize_params(X.shape[1])
# 初始化损失列表
cost_list = []
# 迭代训练
for i in range(epochs):
# 计算当前迭代的模型输出、损失和参数梯度
a, cost, dw, db = logistic(X, y, w, b)
# 参数更新
w = w - learning_rate * dw
b = b - learning_rate * db
# 记录和打印训练过程中的损失
if i % 100 == 0:
cost_list.append(cost)
print('epoch %d cost %f' % (i, cost))
# 保存参数
params = {'w':w, 'b':b}
return cost_list, params
# 定义预测函数
def predict(X, params):
# 模型预测值
y_predict = sigmoid(np.dot(X, params['w'] + params['b']))
# 基于分类阈值对概率预测值进行类别转换
for i in range(len(y_predict)):
if y_predict[i] > 0.5:
y_predict[i] = 1
else:
y_predict[i] = 0
return y_predict
# 生成100*2的模拟二分类数据集
X, labels = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=2)
# 设计随机数种子
rng = np.random.RandomState(2)
# 对生成的特征数据添加一组均匀分布噪声
X += 2 * rng.uniform(size=X.shape)
# 标签类别数
labels_unique = set(labels)
# 绘制模拟数据的散点图
for k in zip(labels_unique):
x_k = X[labels==k]
plt.plot(x_k[:,0], x_k[:,1], 'o')
plt.title('Simulated binary data set')
plt.show()
# 按9:1简单划分训练集与测试集
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], labels[:offset] # X_train:(90,2)
y_train = y_train.reshape((-1, 1)) # y_train:(90,1)
X_test, y_test = X[offset:], labels[offset:] # X_test:(10,2)
y_test = y_test.reshape((-1, 1)) # y_test:(10,1)
# 执行对数几率回归模型训练
learning_rate = 0.01
epochs = 1000
cost_list, params = logistic_train(X_train, y_train, learning_rate, epochs)
# 打印训练好的模型参数
print('对数几率回归模型的参数:\n', params)
# 基于训练参数对测试集进行预测
y_predict = predict(X_test, params)
print('基于模型对测试集进行预测的结果:\n', y_predict)
# 打印测试集分类预测评估报告
print('测试集分类预测评估报告:\n', classification_report(y_test, y_predict))
# 绘制对数几率回归分类决策边界
def plot_decision_boundary(X_train, y_train, params):
# 训练样本数
n = X_train.shape[0]
# 初始化类别坐标点列表
x_record1 = []
y_record1 = []
x_record2 = []
y_record2 = []
# 获取两类坐标点并存入列表
for i in range(n):
if y_train[i] == 1:
x_record1.append(X_train[i][0])
y_record1.append(X_train[i][1])
else:
x_record2.append(X_train[i][0])
y_record2.append(X_train[i][1])
# 创建绘图
fig = plt.figure()
ax = fig.add_subplot(111)
# 绘制两类散点,以不同颜色表示
ax.scatter(x_record1, y_record1, s=32, c='red')
ax.scatter(x_record2, y_record2, s=32, c='green')
# 取值范围
x = np.arange(-1.5, 3, 0.1)
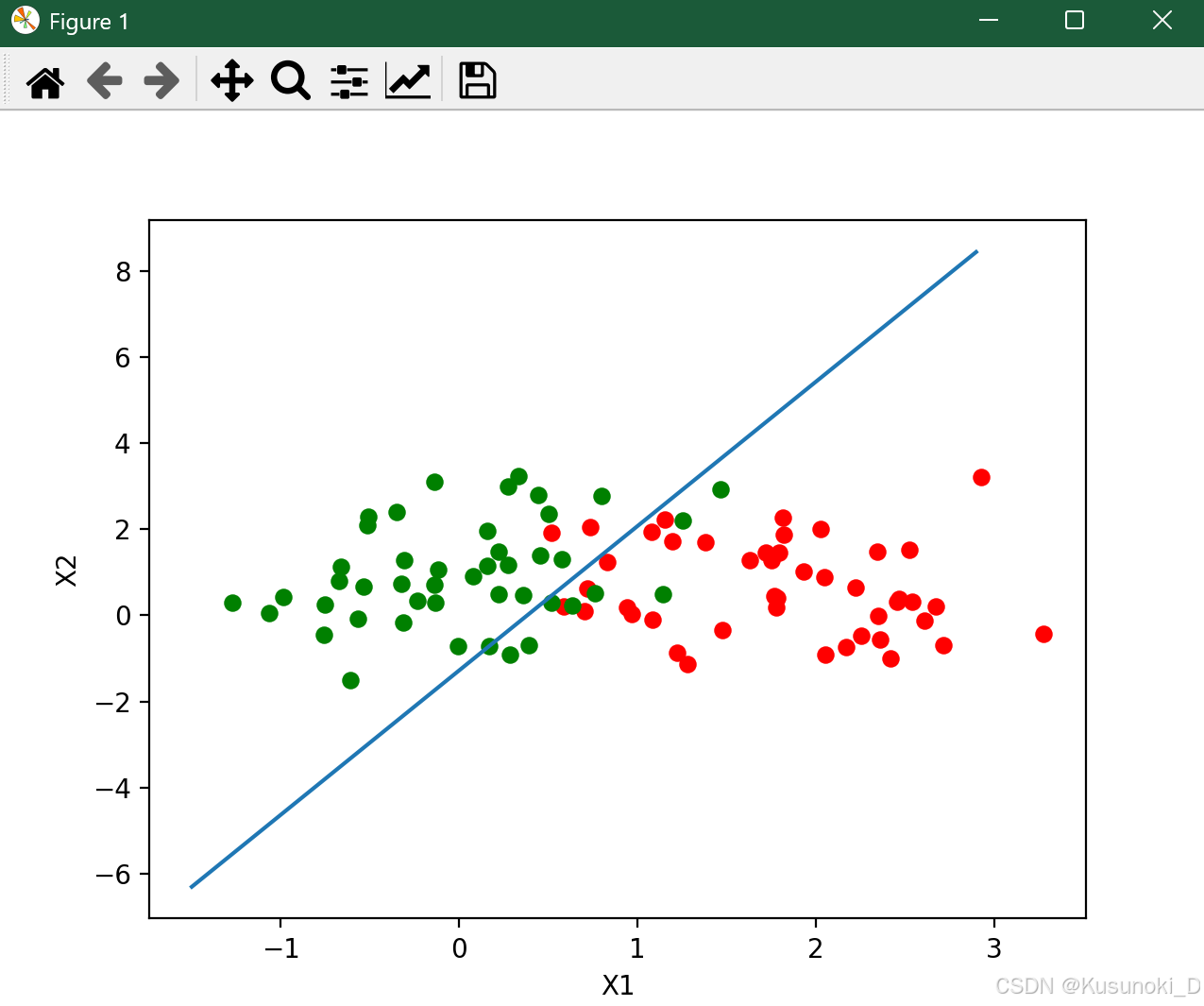
# 分类决策边界公式 w0·x+w1·y+b=0
y = (-params['b'] - params['w'][0] * x) / params['w'][1]
# 绘图
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
plot_decision_boundary(X_train, y_train, params)
【结果展示】:
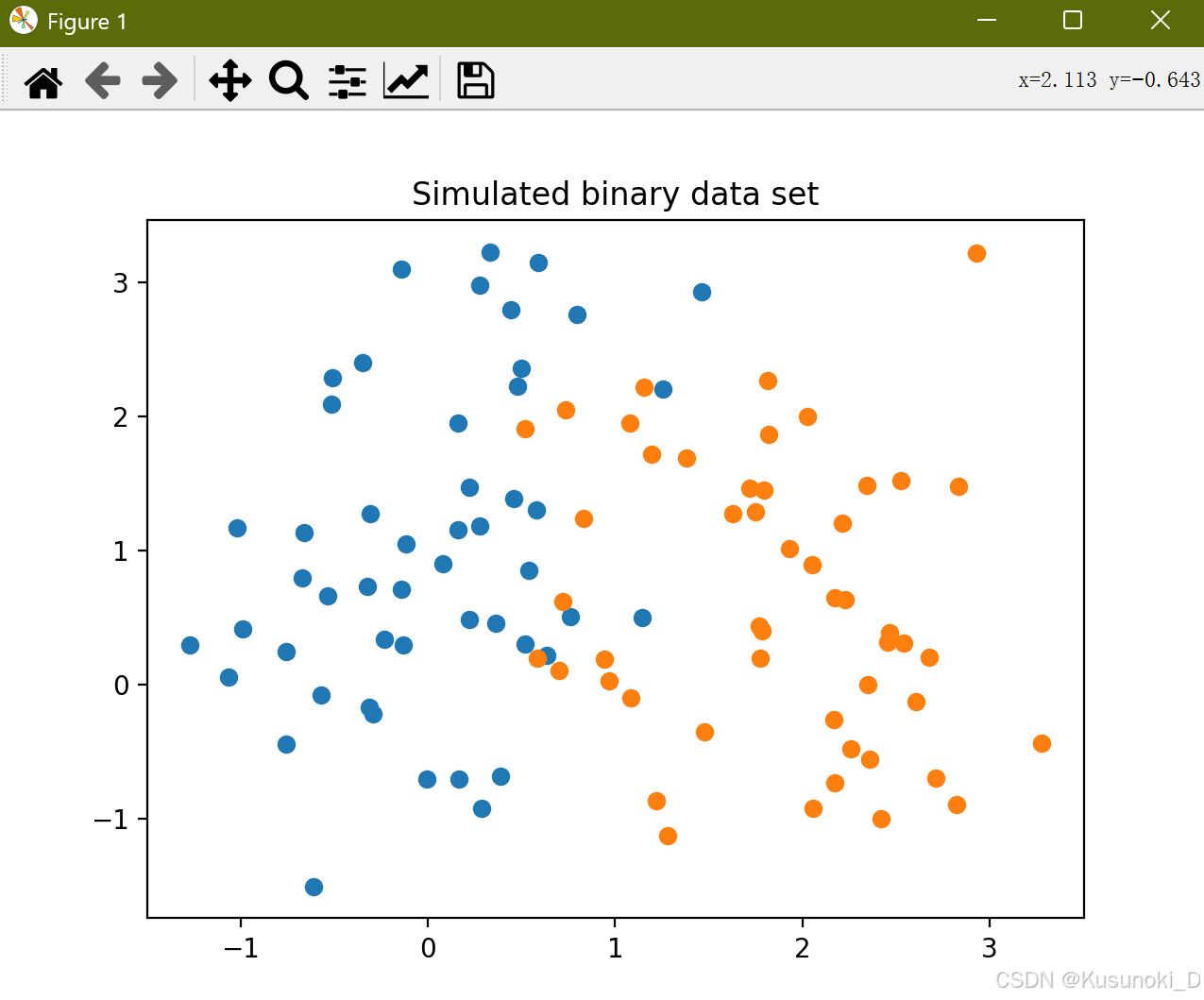
① 模拟二分类数据集的散点图:
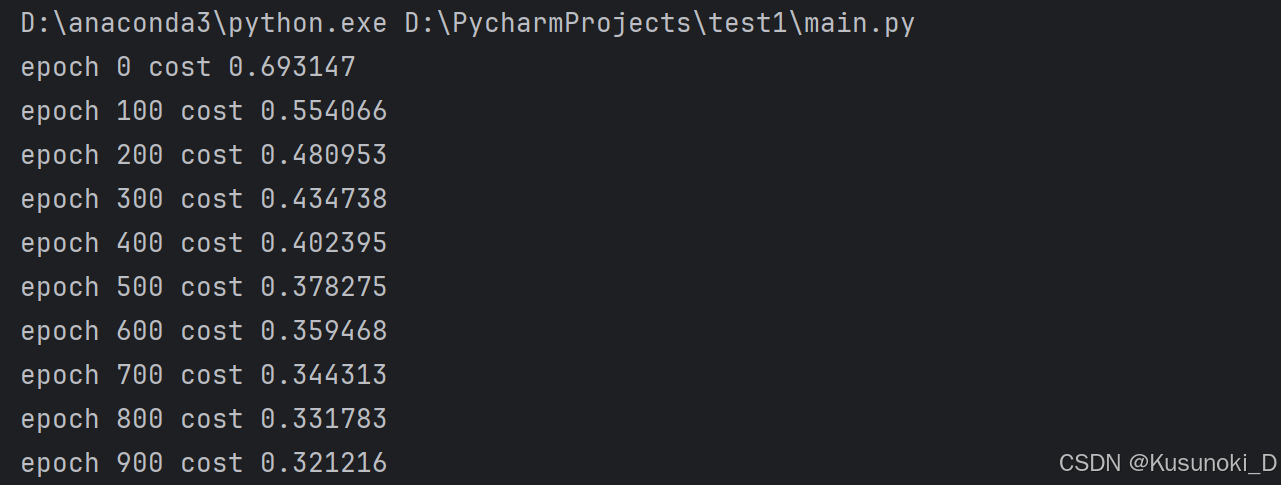
② 每 100 次迭代后的损失值:
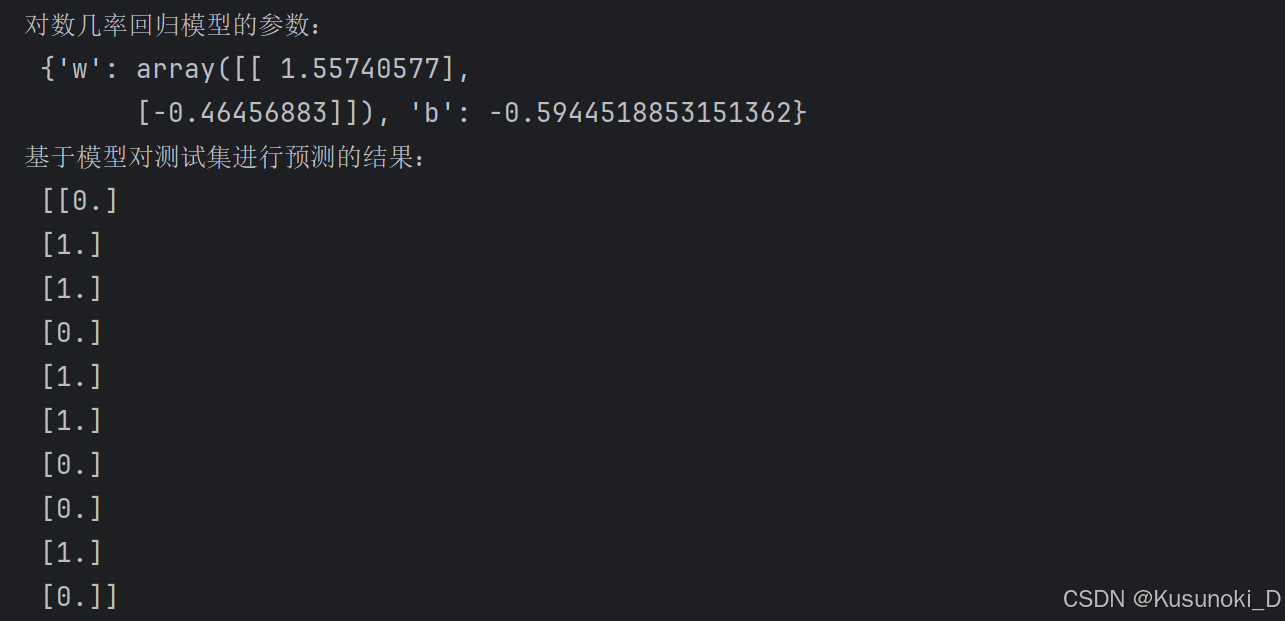
③ 训练模型的参数(ω 和 b)以及基于模型对测试集进行预测的结果:
④ 测试集上的分类准确率评估:
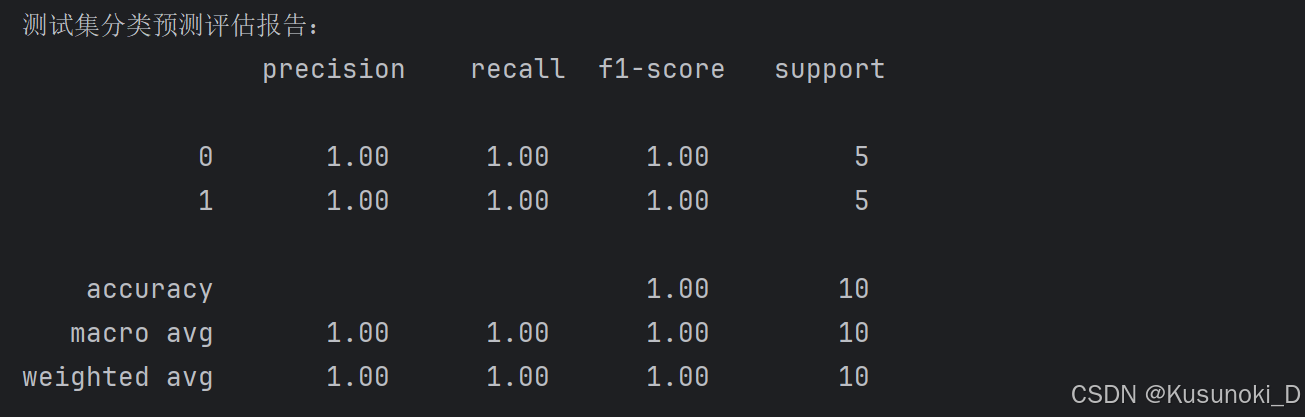
分类预测评估报告主要包括:精确率、召回率和 F1 得分等分类评估指标结果。各项结果均为 1 ,虽然数据集划分和模型预测有一定的随机性,但也说明基于 NumPy 实现的对数几率回归模型还是比较成功的。
⑤ 对数几率回归分类决策边界图:
2)基于 Sklearn 的模型实现
【代码实现】:
import numpy as np
from sklearn.datasets._samples_generator import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import mean_squared_error, r2_score
# 生成100*2的模拟二分类数据集
X, labels = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=2)
# 设计随机数种子
rng = np.random.RandomState(2)
# 对生成的特征数据添加一组均匀分布噪声
X += 2 * rng.uniform(size=X.shape)
# 按9:1简单划分训练集与测试集
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], labels[:offset] # X_train:(90,2) y_train:(90,1)
X_test, y_test = X[offset:], labels[offset:] # X_test:(10,2) y_test:(10,1)
# 拟合训练集
clf = LogisticRegression(random_state=0).fit(X_train, y_train)
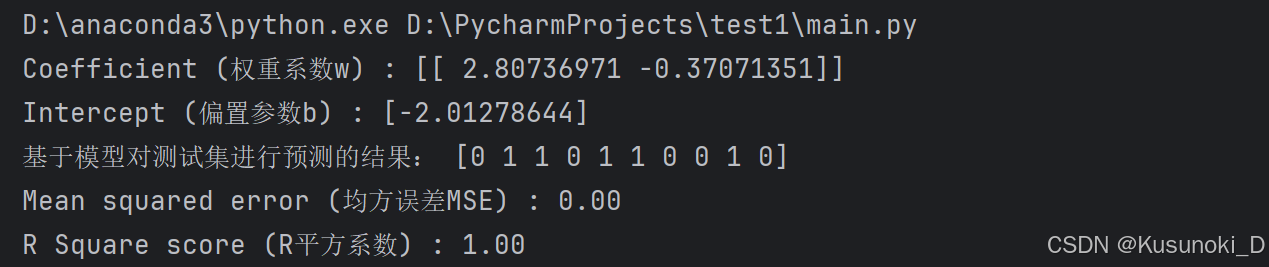
# 方程系数与截距
print('Coefficient (权重系数w) :', clf.coef_)
print('Intercept (偏置参数b) :', clf.intercept_)
# 预测测试集
y_predict = clf.predict(X_test)
# 打印预测结果
print('基于模型对测试集进行预测的结果:', y_predict)
# 输出模型均方误差
print("Mean squared error (均方误差MSE) : %.2f" % mean_squared_error(y_test, y_predict))
# 计算R**2系数
print("R Square score (R平方系数) : %.2f" % r2_score(y_test, y_predict))
【结果展示】:
3)基于西瓜数据集 3a 的代码实现
【数据集介绍】:
| 密度 | 含糖率 | 好瓜 |
|---|---|---|
| 0.697 | 0.46 | 1 |
| 0.774 | 0.376 | 1 |
| 0.634 | 0.264 | 1 |
| 0.608 | 0.318 | 1 |
| 0.556 | 0.215 | 1 |
| 0.403 | 0.237 | 1 |
| 0.481 | 0.149 | 1 |
| 0.437 | 0.211 | 1 |
| 0.666 | 0.091 | 0 |
| 0.243 | 0.267 | 0 |
| 0.245 | 0.057 | 0 |
| 0.343 | 0.099 | 0 |
| 0.639 | 0.161 | 0 |
| 0.657 | 0.198 | 0 |
| 0.36 | 0.37 | 0 |
| 0.593 | 0.042 | 0 |
| 0.719 | 0.103 | 0 |
【代码实现】:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
filepath = "D:\PycharmProjects\西瓜数据集3a.csv"
df = pd.read_csv(filepath, header=0, encoding='gb2312')
# print('展示数据集:\n', df)
# sigmoid函数
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
# 读取数据
def load_data():
x = [] # 西瓜密度and含糖量
y = [] # 是否为好瓜
for i in range(0, len(df)):
x.append([1, df.iloc[i][0], df.iloc[i][1]]) # 切片
y.append(df.iloc[i][2])
x_mat = np.mat(x) # (17,3)
y_mat = np.mat(y).T # (17,1)
return x_mat, y_mat
# 计算参数w0,w1,w2,用梯度下降
def w_calc(x_mat, y_mat, alpha, max_iter):
# 初始化w,以标准正态分布
w = np.mat(np.random.randn(3, 1)) # 3*1
# 梯度下降法优化w
for i in range(max_iter): # 下降次数
H = sigmoid(x_mat * w)
dw = x_mat.T * (H - y_mat)
w -= alpha * dw # 学习率
return w
# 实现
x_mat, y_mat = load_data()
# print('x_mat:', x_mat, x_mat.shape)
# print('y_mat:', y_mat, y_mat.shape)
alpha = 0.05
max_iter = 50001
W = w_calc(x_mat, y_mat, alpha, max_iter)
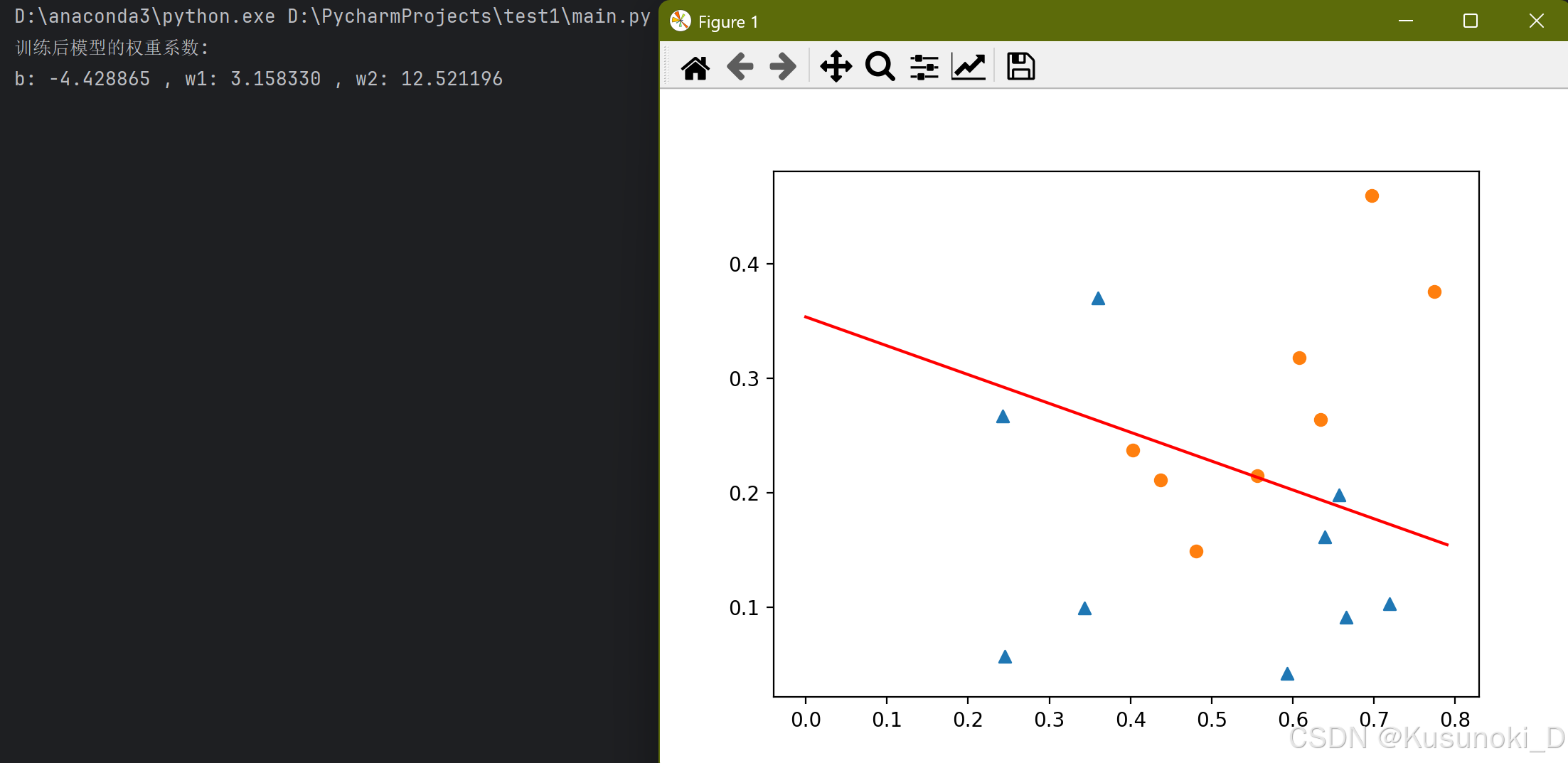
print('训练后模型的权重系数:\nb: %f , w1: %f , w2: %f' % (W[0, 0], W[1, 0], W[2, 0]))
# 可视化
w0 = W[0, 0]
w1 = W[1, 0]
w2 = W[2, 0]
plotx1 = np.arange(0, 0.8, 0.01)
# w0 + w1·x1 + w2·x2 = 0
plotx2 = - w0/w2 - w1*plotx1/w2
plt.plot(plotx1, plotx2, c='r', label='boundary')
plt.scatter(x_mat[:, 1][y_mat == 0].A, x_mat[:, 2][y_mat == 0].A, marker='^', label='label=0') # 横坐标x1,纵坐标x2
plt.scatter(x_mat[:, 1][y_mat == 1].A, x_mat[:, 2][y_mat == 1].A, label='label=1')
plt.show()
【结果展示】:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)