强化学习联合注意力机制!双热点在手,发文我不愁!
最近看顶会,发现的热度暴涨!ICML、NeurIPS等都有多篇,效果也都拔群!像是在交通信号控制任务中,违规率直降79%的SAC-GNN、性能狂提60%的CMTA……主要是因为,在强化学习中引入注意力机制,能帮助模型更好地理解和利用环境信息。无论是在状态表示、动作选择还是奖励预测阶段,注意力机制都能发挥重要作用。它能够突出关键信息,抑制无关信息,从而模型在决策时更加准确和迅速。目前这种结合在游戏A
最近看顶会,发现强化学习+注意力机制的热度暴涨!ICML、NeurIPS等都有多篇,效果也都拔群!像是在交通信号控制任务中,违规率直降79%的SAC-GNN、性能狂提60%的CMTA……
主要是因为,在强化学习中引入注意力机制,能帮助模型更好地理解和利用环境信息。无论是在状态表示、动作选择还是奖励预测阶段,注意力机制都能发挥重要作用。它能够突出关键信息,抑制无关信息,从而模型在决策时更加准确和迅速。
目前这种结合在游戏AI、自动驾驶、金融、NLP、图像处理等领域,都有着广泛的应用,是非常有前景的方向。且相比其他领域,还不算“红海”,创新空间很大。
为让大家能够把准领域的研究脉络,早点发出自己的文章,我给大家准备了12种前沿创新思路,以及开源代码。
论文原文+开源代码需要的同学看文末
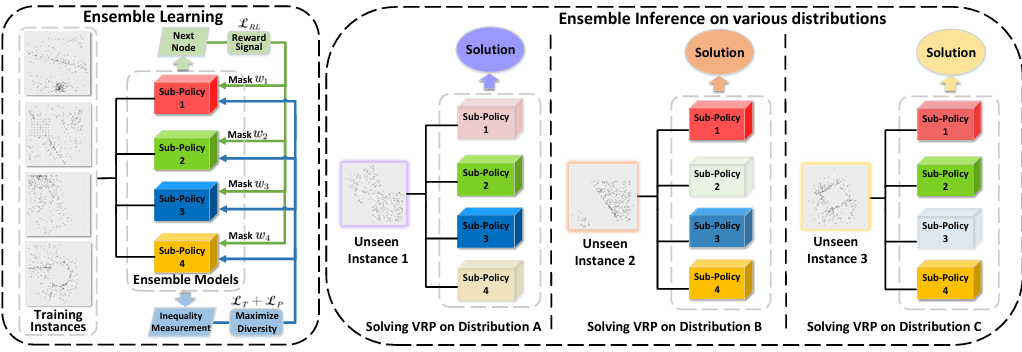
Ensemble-based Deep Reinforcement Learning for Vehicle Routing Problems under Distribution Shift
内容:论文提出了一种基于集成的深度强化学习方法,用于解决车辆路径问题(VRPs)中的分布偏移问题。该方法通过学习一组多样化的子策略来应对不同的实例分布,并通过引导式引导和正则化项在训练过程中增强子策略之间的多样性。实验结果表明,该方法在多种分布的随机生成实例以及TSPLib和CVRPLib基准实例上均优于现有的神经基线方法,显示出良好的跨分布泛化能力。
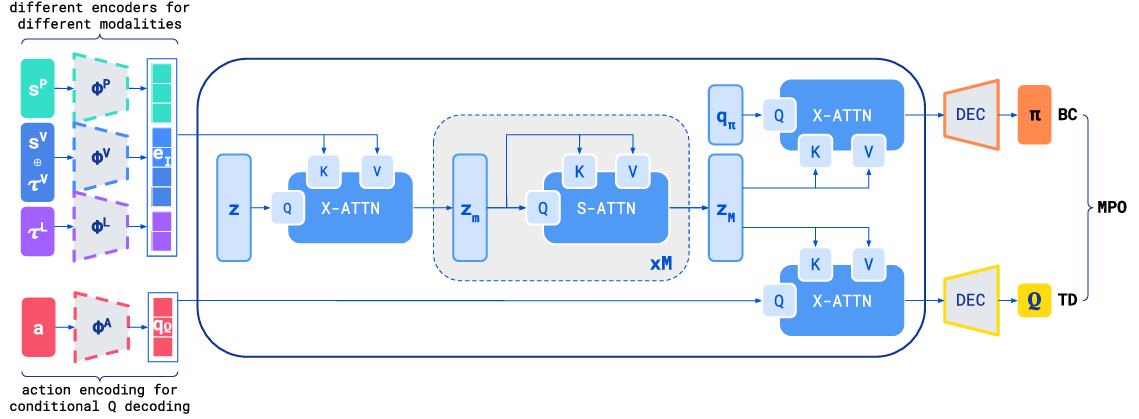
Offline Actor-Critic Reinforcement Learning Scales to Large Models
内容:论文介绍了一种能够扩展到大型模型,通过利用离线数据来训练强化学习中的Actor-Critic框架,从而提高了算法的样本效率并减少了在线交互的需求,这对于需要处理大规模模型的复杂任务具有重要意义。
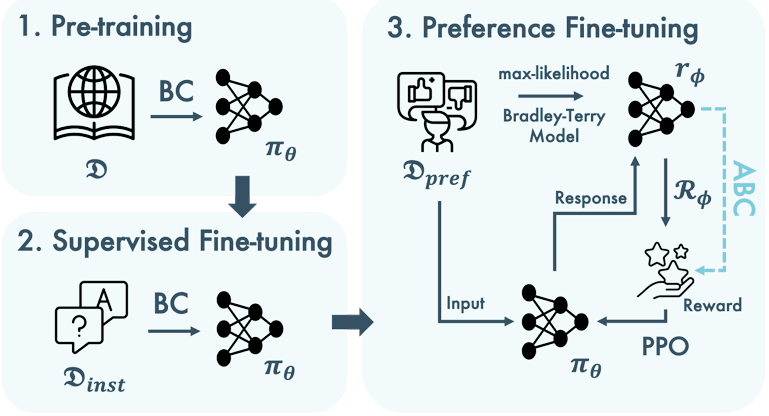
Dense Reward for Free in Reinforcement Learning from Human Feedback
内容:论文介绍了一种名为ABC的方法,用于改进从人类反馈中学习的强化学习(RLHF)过程。ABC方法通过利用奖励模型中的注意力权重将稀疏奖励信号分散到整个语言模型生成过程中,从而实现奖励信号的密集化,这有助于提高训练的稳定性和学习效率,并且可能帮助模型找到更好的局部最优解。
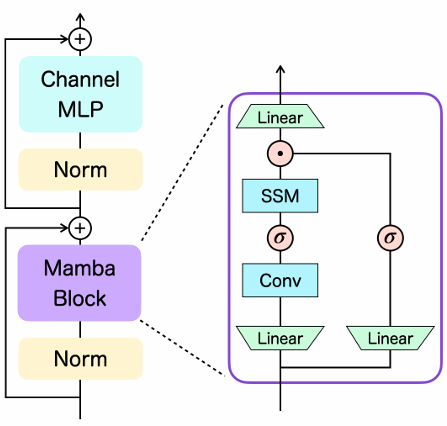
Decision Mamba: Reinforcement Learning via Sequence Modeling with Selective State Spaces
内容:论文介绍了一种名为新型强化学习模型,该模型将Mamba框架集成到Decision Transformer架构中,以提高序列决策任务的性能。通过一系列实验,论文比较了Decision Mamba与传统的Decision Transformer的性能,发现Decision Mamba在多种决策环境中具有竞争力,表明Mamba框架能够显著提升基于Transformer的模型在强化学习场景中的效率和效果。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【强化学习】获取完整论文
👇

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)