一文看懂GPT-4o图像生成,颠覆想象!GPT-4o图像生成革命
OpenAI在ChatGPT和SORA中引入了GPT-4o的多模态图像生成功能,该模型整合了文本、图像和音频处理能力,实现更自然的交互。相比早期版本依赖外部工具(如DALL·E 3),GPT-4o原生支持图像生成,能结合上下文记忆、复杂指令执行和文本嵌入,改进编辑迭代和图像质量。其技术融合自回归转换器和扩散解码器,逐步生成像素。实际应用中,用户已利用该功能快速原型设计、创作艺术、生成模因及逼真场景
OpenAI 终于在 ChatGPT 和 SORA 中引入了 GPT-4o 图像生成。GPT-4o (omni) 是一种多模态 AI 模型;它可以与文本、图像和音频等不同形式进行交互,从而实现比早期版本的 AI 更加自然的交互。在 4o 的语音模型之后,现在他们已经训练模型生成完全不同比例的图像。通过此更新,ChatGPT 现在可以直接创建图像作为其响应的一部分,而无需依赖外部工具。在这篇博文中,我们将分解这项新功能是什么、它是如何工作的以及为什么它很重要。此外,我们还将探索如何利用 gpt4o 的最新映像生成功能来使我们的工作更快、更好。
令人兴奋,对吧?让我们开始吧!
什么是 GPT-4o 的原生图像生成?
OpenAI 基本上将图像创建融合到 GPT-4o 模型本身中。事实上,“GPT-4o”代表 GPT-4 “omni”——omni 表示它是从头开始设计的,可以在一个统一的系统中处理多种模式(文本、图像甚至音频)。
这与早期的型号有何不同? 过去,如果你想让 ChatGPT 制作图像,它就使用一个单独的扩散模型,比如 DALL·E 3 虽然功能强大,但仍然是一个松散地附属于 ChatGPT 的独特系统。DALL·E 经常摸索着在图像中生成可读文本,难以遵循非常复杂的指令,并且无法记住多次图像编辑的细节。
GPT-4o 改变了这一点。它将图像功能直接合并到聊天模型中,因此在创建图片时可以利用 GPT-4o 的整个知识库和上下文。
实际上,您可以向 GPT-4o 索取各种图像——从简单的绘图或徽标到具有多个元素的复杂场景——它会尽最大努力为您绘制。都在同一个聊天中。除了描述您想要的内容之外,不需要任何特殊命令。这种原生方法与 GPT-4(纯文本输出)或 ChatGPT+DALL·E 组合。
GPT-4o 图像生成改进
在后台,GPT-4o 的图像生成通过结合高级语言建模和图像合成技术来实现——但我们将保持简单。从本质上讲,当您键入图像提示时,GPT-4o 会使用其语言理解在内部解释您的请求,然后逐步生成图像。
它不仅仅是猜测;它实际上已经看到了数百万个将单词与视觉概念联系起来的例子。OpenAI 还对此功能进行了一些大量的微调和优化(他们提到了 “积极的后训练”,以使模型在视觉上流畅。从技术上讲,GPT-4o 可能会使用其 transformer 网络来生成一种视觉表示(如图像令牌或潜在代码),然后通过解码器将其转换为最终图像。最疯狂的是,这种图像生成的工作方式不像 DALL·E. 那又如何???
它使用了一种独特的混合方法:
自回归转换器:
- 产生视觉标记(可能是离散的潜在代码)。
- 代币顺序至关重要(例如,从上到下、从左到右)。
Rolling Diffusion-like 解码器:
- 使用按组扩散过程将视觉标记解码为像素。
- 这不是一次完整的图像去噪过程,而是以组(色块或条带)的形式完成 — 逐步滚动图像。

OpenAI 团队在白板上涂鸦暗示了这一点:“代币 -> [变压器] -> [扩散] -> 像素。这张图片告诉我们 GPT-4o 在图像生成方面的整个架构改进。这多酷啊!
因为图像生成是 GPT-4o 原生的,所以有几件事比以前好得多:
- 它记住上下文:您可以进行来回对话以完善图像,GPT-4o 会记住它刚刚绘制的内容以及您对它的评价。
- 编辑和迭代改进:该模型支持迭代编辑。提供反馈,例如“使其成为模因”、“将背景更改为黑色”或“调整瓶子大小并删除文本”,它将生成更新版本。
- 它严格遵循复杂的指令:GPT-4o 在处理具有许多细节的详细提示方面要好得多。
- 它可以在图像中生成清晰的文本:这是一个巨大的飞跃。任何尝试过旧版图像 AI 的人都知道,当被要求写单词时,它们经常会产生乱码(比如带有无意义字母的停止标志)。GPT-4o 擅长在图像中准确呈现文本。需要一个标牌、一张海报或一份带有实际文字的菜单吗?GPT-4o 可以做到。它可以在板上绘制字母、单词,甚至方程式。
- 它对上传的图像具有上下文感知能力:GPT-4o 不仅可以从头开始创建图像,还可以获取您提供的图像并将其用作上下文。您可以上传一张照片并要求 GPT-4o 对其进行修改或从中汲取灵感。例如,它可以分析上传的图像,然后生成引用它的新图像。
- 它支持各种样式和照片级真实感:GPT-4o 接受过各种图像样式的训练,因此适应性很强。它可以制作逼真的图像(以至于某些输出看起来像真实照片),还可以按需生成插图、卡通、素描等。想要漫画风格的图像吗?水彩画外观?或者只是一张清晰的产品照片?GPT-4o 可能会模仿它。
所有这些都标志着 GPT-4 或 DALL·E 无法做到的。现在让我们做一些动手实验,看看 GPT-4o 生成图像的能力如何。
实际应用:人们如何使用它
自发布以来,互联网上的用户一直在尝试 GPT-4o 的图像生成,结果无处不在——从 Reddit 线程和推文,到 LinkedIn 帖子和技术博客演示。让我们看一些真实世界的示例和用例,它们显示了各种可能性:
设计和原型制作
一个令人兴奋的应用程序是应用程序和 Web 设计的快速原型设计。让我们尝试一下基本提示符:
提示 – 为我的图像升频应用程序生成 UI/UX 模型
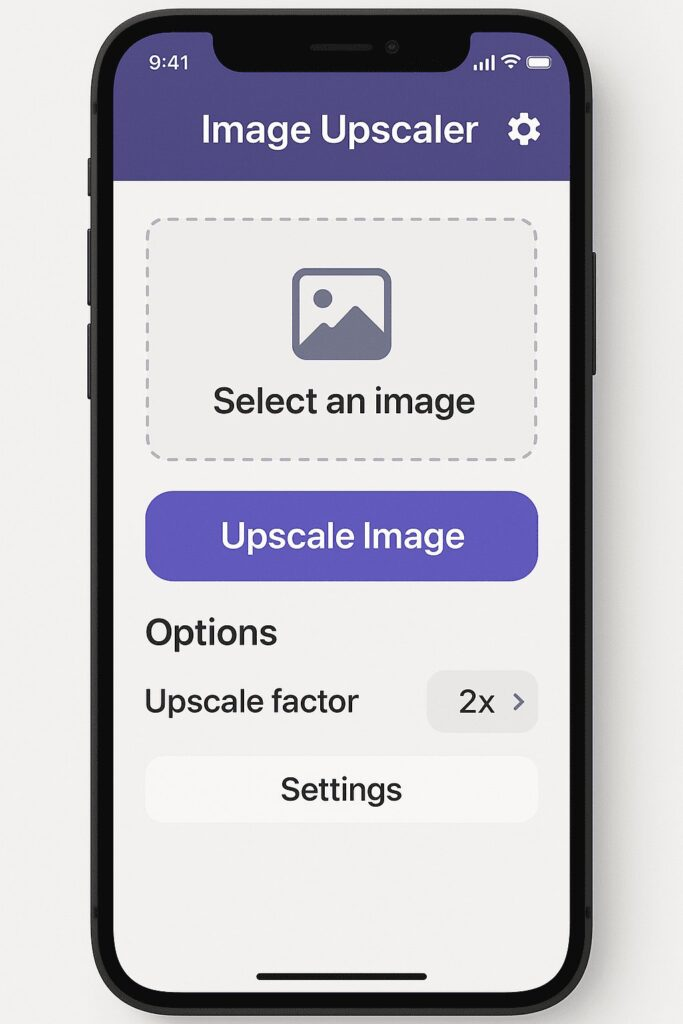
GPT-4o 提供了一个精美的 UI 布局,看起来像设计师可能在 Figma 或 Webflow 中创建的东西。它包括一个上传框、号召性用语按钮、示例输出图像和简洁的整体设计。
让我们尝试另一个:
提示 – 为我的送餐 SAAS 生成 UI/UX 设计
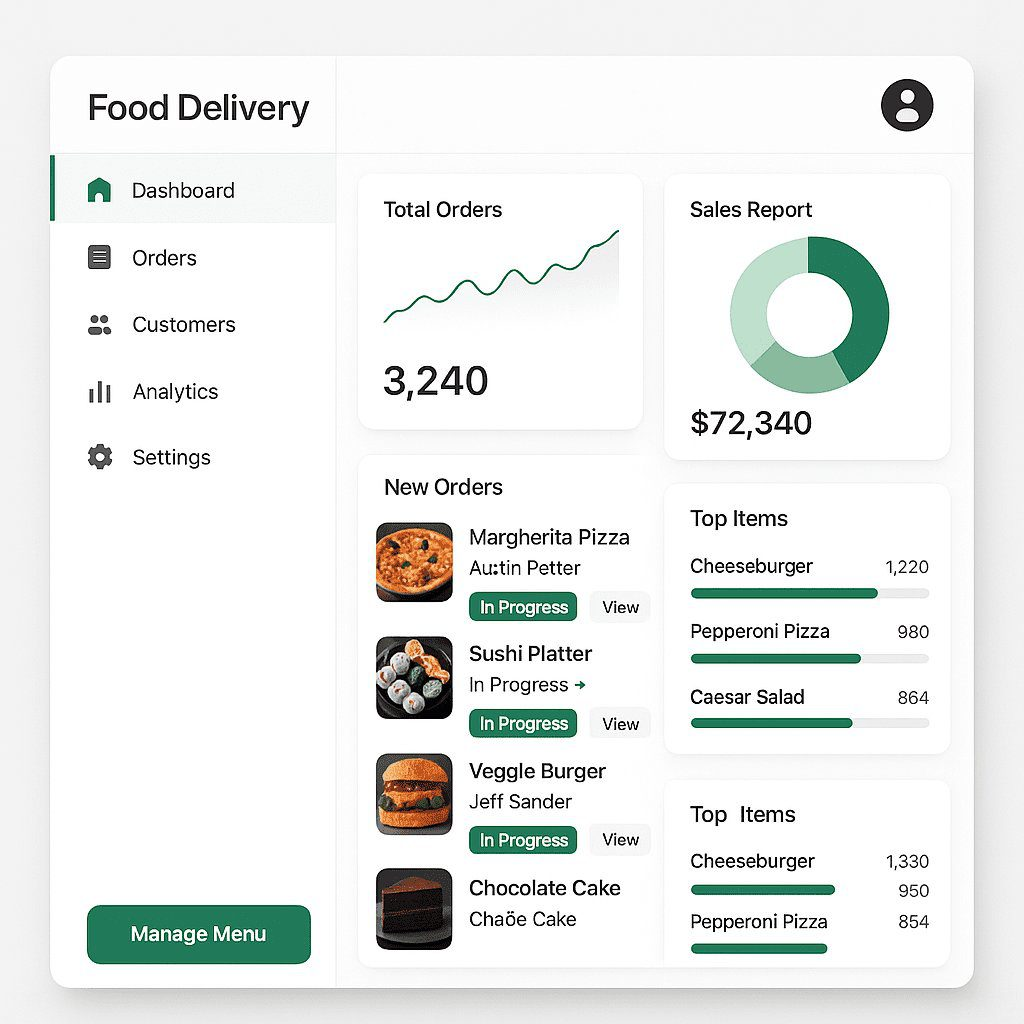
想想看——只需一个提示,GPT-4o 就为应用程序生成了一个功能外观的设计。这表明需要快速模型的开发人员、初创公司和设计师具有巨大的潜力。您可以让 AI 起草一个界面,然后您可以对其进行改进(通过要求更改或自己编辑),而不是手动绘制草图。
您甚至可以通过更详细的提示进行更深入的了解。
提示–
制作一张 4 格漫画风格的海报,标题为“How to Live in
Paris”,顶部用粗体红色字母书写。使用浅米色背景和干净的卡通插图样式。每个面板都应具有蓝色背景,并具有以下特点:左上面板:一位戴着红色贝雷帽和黑白条纹衬衫的时尚女士,手放在胸前,看起来很戏剧化。图片说明:“1. 穿得花哨”。
右上面板:一名恼怒的巴黎男子瞪着两个困惑的游客,他们拿着相机、地图和饮料杯。图片说明:“2. 讨厌游客”。
左下角面板:一个人高兴地咬着一个大法式长棍面包。图片说明:“3. 吃法式长棍面包”。
右下面板:一位女士拿着一杯红酒,表情严肃。图片说明:“4. 不要被打动”。 使用富有表现力的卡通面孔和简约的细节来强调幽默感。

创意艺术、模因和视觉叙事
不出所料,互联网立即尝试使用 GPT-4o 来制作有趣和有创意的图像。社交媒体上充斥着幽默或富有想象力的例子:
来自一个提示的复杂场景:
提示 - 1990 年代杂货店的监控摄像头仍然显示一个穿着全套中世纪盔甲的男人偷烤鸡,这些鸡在冲刺经过乳制品区时被冻住了…时间戳显示为 ‘08/13/96 04:44 AM’…运动模糊增加了混乱的能量,荒谬而强烈,带有 VHS 色彩出血的低保真度。

模因和流行文化混搭:人们已经测试了 GPT-4o 生成著名虚构人物和场景的图像以制作模因。
吉卜力工作室风格的模因
提示 - 制作吉卜力工作室风格的动漫 [插入原始模因图片]

提示 - 制作吉卜力工作室风格的动漫 [插入原始模因图片]

逼真的图像:
提示 – 从 [UNIVERSITY] 生成一个逼真的 [DEGREE] 学士学位,授予 [NAME],并附有荣誉,包括公章、校长签名和安全功能,并拍摄挂在墙上的照片。[插入图片:学位的照片参考]

提示 – 两个 20 多岁的女巫(一个是灰烬 balayage,一个留着长长的波浪形赤褐色头发)阅读路牌的逼真图像。
背景:纽约州威廉斯堡一条随机街道上的一条城市街道,一根杆子完全被许多详细的街道标志(例如,街道清扫时间、所需的停车许可证、车辆分类、拖车规则)覆盖,包括中间的一些荒谬标志:(转述它以制作这些合法的路标)“C区不允许为女巫提供扫帚停车”和“仅限魔毯装卸(15 分钟限制)”和“仅限许可证的驯鹿停车(12 月 24 日至 25 日)\n 违规者将被列入淘气名单。路标在街道的右侧。不要重复标志。标志必须是现实的。
角色:一个女巫拿着扫帚,另一个拿着卷起的魔毯。他们在前景中,背对着镜头微微倾斜,在仔细检查标志时头部微微倾斜。
从背景到前景的构图:街道 + 停放的汽车 + 建筑物 -> 路标 ->女巫。角色必须最接近拍摄的摄像机。

提示 – 一位有着蓝色 LED 纹身的赛博朋克女性在霓虹雨中拍摄的非常详细的逼真肖像,使用 50 毫米镜头、浅景深、电影照明拍摄。

扩散型转移
一篇病毒式帖子描述了如何使用带有 GPT-4o 的 ChatGPT 移动应用程序来生成图像,甚至提出了一个例子:上传照片并提示“制作这个吉卜力动漫风格”。

不仅这个,我们还有很多很酷的款式可供选择!
Prompt (提示) – 将其制作成体素 3D 风格的艺术。 [插入图片:照片参考]

提示 – 将其制作成 Disney Pixar 风格的艺术。 [插入图片:照片参考]

提示 – 制作梵高风格的艺术。[插入图片:照片参考]

我们可以通过使用这些图像创建视频动画来超越这一点!
商业、营销和教育用途
除了娱乐之外,GPT-4o 的图像生成被证明对于更实用的日常内容创作很有用。因为它可以生成图表、图形、幻灯片或库存照片场景等“主力”视觉效果,营销人员和教育工作者正在关注这些可能性:
信息图表和解释器
白板和头脑风暴视觉效果:
提示 – 详细解释牛顿棱柱实验的信息图
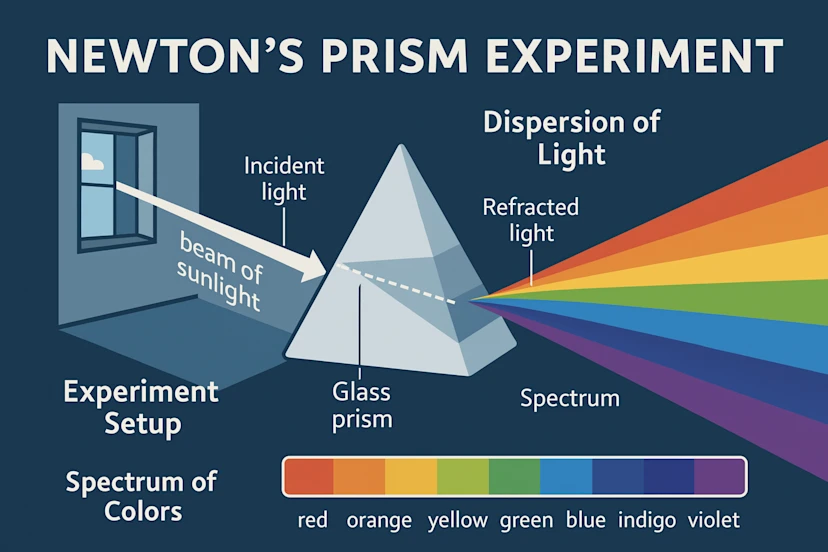
提示 – 现在生成一个人在他们的笔记本上画这个图的 POV,在华盛顿广场公园的一张圆形咖啡桌上。

这很酷,对吧?它使用知识库,并将上下文保存在内存中,因此您可以超越文本创建图像并扩展您的创造力。现在让我们看一个白板示例。
提示 – 非常详细地绘制人脑及其各部分和功能的简单白板图。
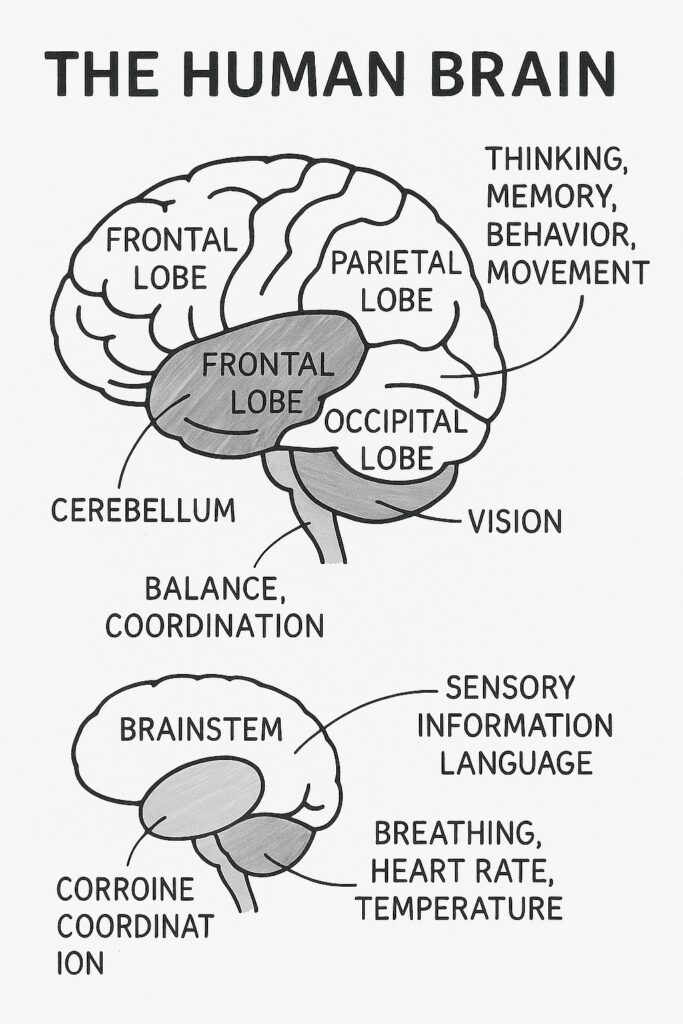
提示 – 创建一个六面板白板式转换图像,显示艺术家对猫头鹰的分步素描过程 - 从粗略的轮廓开始,逐渐发展到详细的、完全着色的肖像。

最后的思考
GPT-4o 的原生图像生成是 AI 能力的一个里程碑——它以一种非常自然的方式融合了文本和视觉世界。我们现在有一个 AI 模型,它可以在一个连续的流程中进行对话、推理和绘图。这为创作者、教育工作者、企业以及任何有想象力的人提供了绝佳的机会。您可以在早上制作应用程序界面的原型,在午餐时制作模因,在下午起草营销图形,所有这些都使用相同的工具。当然,强大的力量伴随着一些谨慎。GPT-4o 可以生成超逼真的图像(包括真人或商标)这一事实引发了道德问题。OpenAI 已经实施了保护措施——例如,他们在每张图像中嵌入了一个隐藏的水印(C2PA 元数据),以将其标记为 AI 生成的。
对于 AI 来说,这是一个令人兴奋(而且有点疯狂)的时刻,所以请继续给 GPT-4o 一些创造性的提示。您可能会被它为您描绘的东西所震撼!
国内如何使用对接
极速AI-https://api.jisuai.top
急速AI是一个统一的大模型API源头网关,支持300+热门模型,适合低成本,快速接入AIGC应用,无论你是商用还是个人使用,都能快速接入,本文介绍的gpt-4o-image也完全支持,您无需科学上网,并且无封号风险,额度不过期,一个API key全模型通用。急速AI官网地址:https://api.jisuai.top

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)