强化学习—DQN算法
在前面介绍的Q-learning算法中,我们以矩阵的方式建立了一张存储每个状态下所有动作Q值的表格,表格中的每一个动作价值 Q (s,a) 表示在状态s下选择动作a然后继续遵循某一策略预期能够得到的期望回报。然而,这种用表格存储action value的做法只在环境的状态的动作都是离散的,并且空间都比较小的情况下适用。当状态或者动作数量非常大的时候,这种做法就不适用了。例如,当状态是一张RGB图像
1、简介
在前面介绍的Q-learning算法中,我们以矩阵的方式建立了一张存储每个状态下所有动作Q值的表格,表格中的每一个动作价值 Q (s,a) 表示在状态s下选择动作a然后继续遵循某一策略预期能够得到的期望回报。然而,这种用表格存储action value的做法只在环境的状态的动作都是离散的,并且空间都比较小的情况下适用。当状态或者动作数量非常大的时候,这种做法就不适用了。例如,当状态是一张RGB图像时,假设图像大小是 210 * 160 *3,此时一共有 种状态,在计算机中存储这个数量级的Q值表格是不现实的。甚至当状态或动作连续的时候,就有无限个状态动作对,我们更加无法使用这种表格形式来记录各个状态动作对的Q值。
对于这种情况,我们需要用函数拟合的方法来估计Q值,即将这个复杂的Q值表格视作数据,使用一个参数化的函数 来拟合这些数据。很显然,这种函数拟合的方法存在一定的精度损失,因此被称为近似方法。接下来要介绍的DQN算法便可以用来解决连续状态下离散动作的问题。

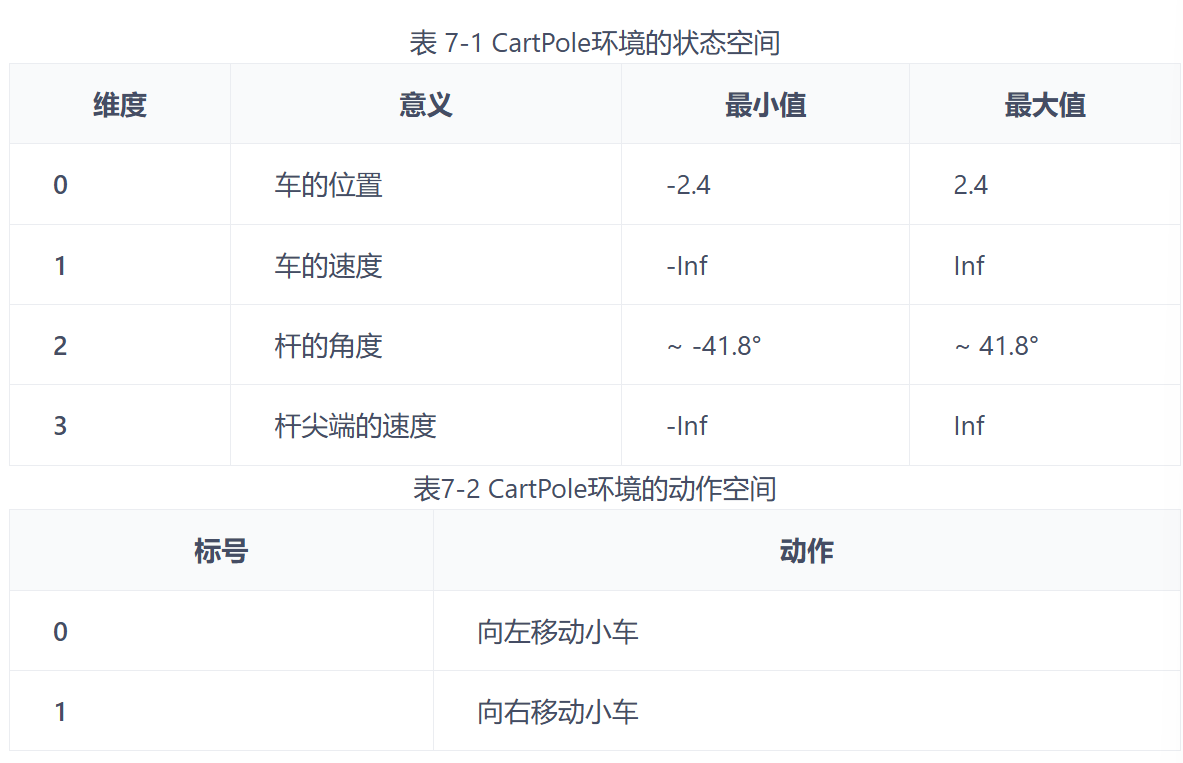
2、DQN
现在我们想在类似车杆的环境中得到action value Q(s,a) ,由于状态的每一维度的值都是连续的,无法使用表格记录,因此一个常见的解决方法便是使用函数拟合。由于神经网络具有强大的表达能力,因此我们可以用一个神经网络来表示函数Q。如果动作是连续(无限)的,神经网络的输入是 s 和 a, 然后输出一个标量,表示在状态s下采取动作a能获得的价值。如果动作是离散(有限)的,我们还可以只将 s 输入到神经网络中,使其同时输出每一个动作的Q值。通常DQN只能处理动作离散的情况,因为在函数Q 的更新过程中有 max a 这一操作。 假设神经网络用来拟合函数w 的参数,每一个状态 s 下的所有可能动作a 的Q值我们都能表示为 ,我们将用于拟合函数Q 的神经网络称为Q网络。
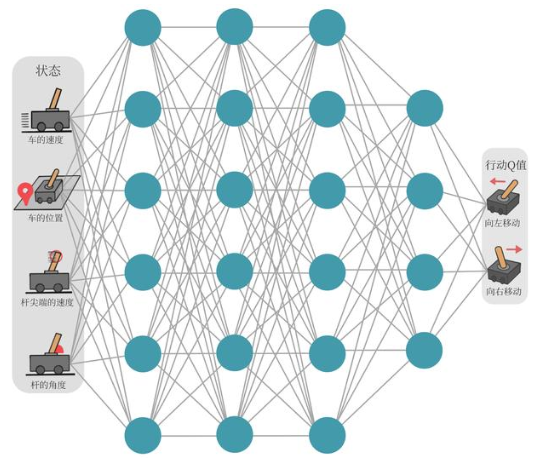
那么Q网络的损失函数是什么呢?我们先来回顾一下Q-learning的更新规则:
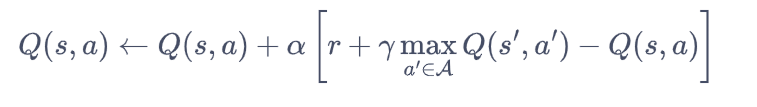
上述公式用TD时序差分学习目标 ![]() 来增量式更新Q(s,a), 也就是说要使Q(s,a) 和TD目标
来增量式更新Q(s,a), 也就是说要使Q(s,a) 和TD目标![]() 靠近。于是,对于一组数据
靠近。于是,对于一组数据![]() ,我们可以很自然地将Q网络的损失函数构造成均方误差的形式。
,我们可以很自然地将Q网络的损失函数构造成均方误差的形式。
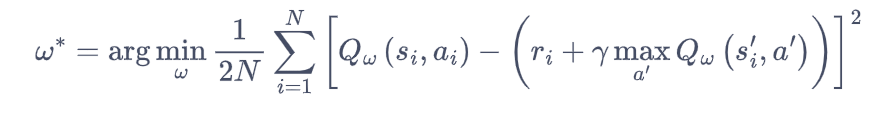
至此,我们就可以将Q-learning扩展到神经网络形式-深度Q网络(DQN)算法。由于DQN是离线策略算法,因此我们在收集数据时可以使用-greedy 来平衡探索和利用,将收集到的数据存储起来,在后续训练中使用。DQN中还有两个非常重要的模块—经验回放和目标网络,它们能够帮助DQN取得稳定、出色的性能。
2.1 经验回放
在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。在原来的Q-learning中,每一个数据只会用来更新一次Q值,为了更好的将其与深度神经网络结合,DQN算法采用了经验回放方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练Q网络的时候再从回放缓冲区中随机采样若干数据来进行训练,这样可以起到以下两个作用:
①使样本满足独立假设。在MDP中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态与上一时刻的状态有关,非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。DQN中对神经网络的训练本质依然是SGD,SGD要求多次利用样本。Replay buffer会存储过去遇到的transition,忘记太过久远的transition,训练时,从replay buffer中随机抽样训练,抽样间隔时间大,可以打破样本之间的相关性,使其满足独立假设。
②提高样本效率,每一个样本可以被应用多次,适合深度神经网络的梯度学习。
2.2 目标网络
DQN算法最终更新的目标就是让 逼近
![]() ,由于TD误差目标本身就包含神经网络的输出,因此在更新网络参数的同时,目标也在不断的改变,这非常容易造成神经网络训练的不稳定性。为了解决这一问题,DQN便使用了目标网络的思想:既然训练过程中Q网络的不断更新会导致目标不断发生改变,不如暂时先将TD目标中的Q网络固定住,为了实现这一思想,我们需要利用两套Q网络。
,由于TD误差目标本身就包含神经网络的输出,因此在更新网络参数的同时,目标也在不断的改变,这非常容易造成神经网络训练的不稳定性。为了解决这一问题,DQN便使用了目标网络的思想:既然训练过程中Q网络的不断更新会导致目标不断发生改变,不如暂时先将TD目标中的Q网络固定住,为了实现这一思想,我们需要利用两套Q网络。
- 原来的训练网络
,用于计算原来的损失函数
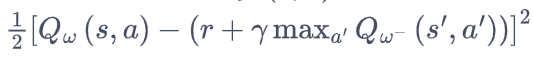 中的
中的 - 目标网络
,用于计算原来的损失函数中的
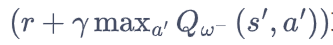 ,其中w- 表示目标网络中的参数。如果两套网络的参数随时保持一致,则仍为原来不够稳定的算法。为了让更新目标更稳定,目标网络并不会每一步都更新。具体而言,目标网络使用训练网络的一套较旧的参数,训练网络
,其中w- 表示目标网络中的参数。如果两套网络的参数随时保持一致,则仍为原来不够稳定的算法。为了让更新目标更稳定,目标网络并不会每一步都更新。具体而言,目标网络使用训练网络的一套较旧的参数,训练网络
DQN算法具体流程:
- 用随机的网络参数w初始化网络
- 复制相同的参数 w- = w来初始化目标网络Qw‘
- 初始化经验回放池R
- for 序列 e = 1→ E do
- 获取环境初始状态s1
- for 时间步 t = 1→T do
- 根据当前网络
- 执行
,获得回报
,环境状态变成
- 将(
,
,
)存储进回放池R
- 若R中数据足够,从R中采样N个数据
- 对每个数据,用目标网络计算
- 最小化目标损失,以此更新当前网络Qw
- 更新目标网络
- end for
- end for

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)