将价值重新引入强化学习:通过统一LLM推理器与验证器实现更好的测试时间扩展
Kusha SareenMila, McGill UniversityMorgane M MossMila, Université de MontréalAlessandro SordoniMicrosoft Research, MilaRishabh Agarwal *Mila, McGill UniversityArian Hosseini *Google DeepMind, Mila####
Kusha Sareen
Mila, McGill UniversityMorgane M Moss
Mila, Université de MontréalAlessandro Sordoni
Microsoft Research, MilaRishabh Agarwal *
Mila, McGill UniversityArian Hosseini *Google DeepMind, Mila#### 摘要流行的用于微调LLM推理器的强化学习(RL)方法,例如GRPO或Leave-one-out PPO,放弃了学习到的价值函数,转而采用经验估计的回报。这阻碍了依赖于使用价值函数进行验证的测试时间计算扩展。在这项工作中,我们提出了RLV\mathrm{RL}^{V}RLV,该方法通过联合训练LLM作为推理器和生成式验证器来增强任何“无价值”的RL方法,添加验证功能而无需显著开销。实证上,RLV\mathrm{RL}^{V}RLV通过并行采样将MATH准确性提高了超过$20% $,并且相比基础RL方法实现了8−32×8-32 \times8−32×更高效的测试时间计算扩展。RLV\mathrm{RL}^{V}RLV还表现出强大的泛化能力,适用于从简单到复杂以及领域外的任务。此外,当联合扩展并行和顺序测试时间计算时,RLV\mathrm{RL}^{V}RLV使用长推理R1模型可实现1.2−1.6×1.2-1.6 \times1.2−1.6×更高的性能。AIME’24上的计算最优准确率和长度选择:R1-Distill-Qwen-1.5B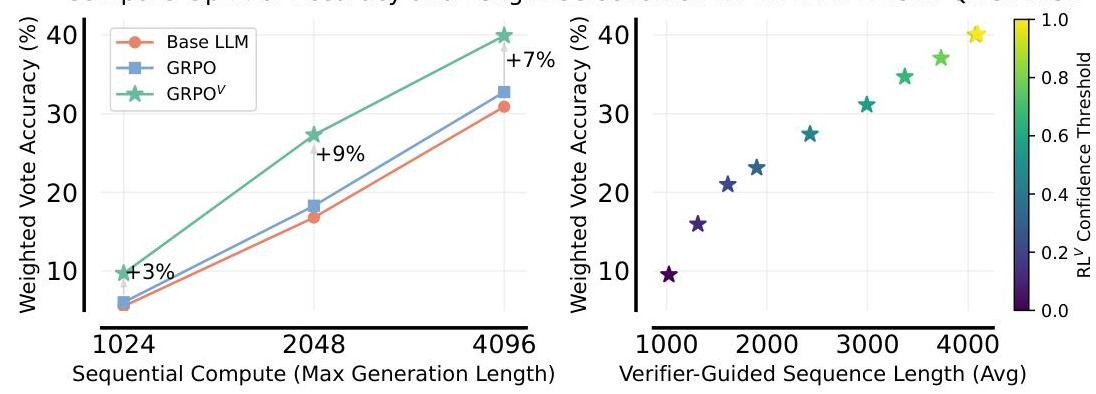 图1:左图:在AIME’24上使用R1-Distill-Qwen-1.5B作为基础LLM时,GRPO V{ }^{V}V与基线相比联合扩展顺序和并行计算的效果。我们使用Hendrycks的MATH进行RL微调。每个点表示在给定序列长度下使用64个并行样本所达到的计算最优准确率。右图:使用联合验证器进行长度选择。通过逐步增加生成长度直到达到选定的RLV\mathrm{RL}^{V}RLV置信度阈值,可以在给定顺序计算预算下获得最大准确率,允许模型动态为困难问题分配更多顺序计算资源。 *同等监督。通讯作者: {kusha.sareen, agarwalr}@mila.quebec, arianhosseini@google.com
图1:左图:在AIME’24上使用R1-Distill-Qwen-1.5B作为基础LLM时,GRPO V{ }^{V}V与基线相比联合扩展顺序和并行计算的效果。我们使用Hendrycks的MATH进行RL微调。每个点表示在给定序列长度下使用64个并行样本所达到的计算最优准确率。右图:使用联合验证器进行长度选择。通过逐步增加生成长度直到达到选定的RLV\mathrm{RL}^{V}RLV置信度阈值,可以在给定顺序计算预算下获得最大准确率,允许模型动态为困难问题分配更多顺序计算资源。 *同等监督。通讯作者: {kusha.sareen, agarwalr}@mila.quebec, arianhosseini@google.com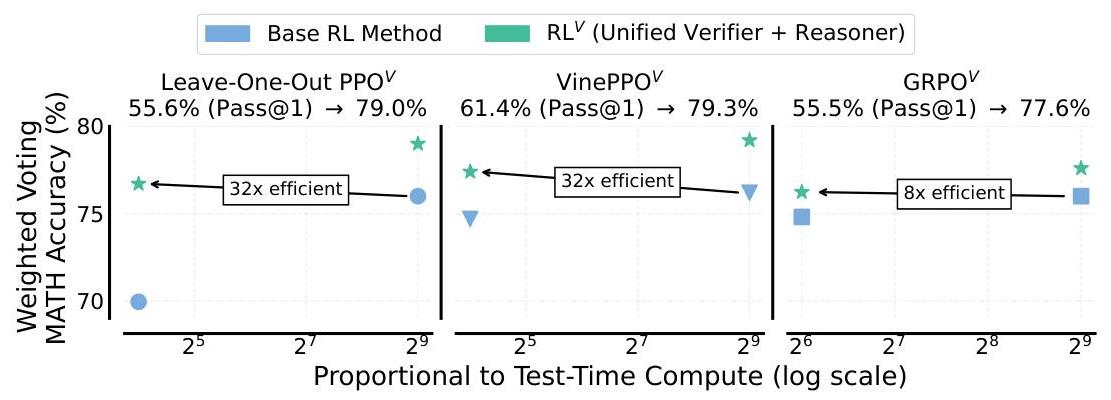 图2:在MATH500上使用加权多数投票扩展测试时间计算时,RLV\mathrm{RL}^{V}RLV相较于基础“无价值”RL方法提供了显著的计算效率和性能提升(Lightman等,2023)。对于评分解决方案,我们使用LLM-as-a-Judge作为基础方法的验证器,而RLV\mathrm{RL}^{V}RLV则使用训练好的统一验证器。这些结果基于对Qwen2.5-Math-1.5B在Hendrycks MATH上的RL微调。# 1 引言 在正确性奖励上的强化学习(RL)已成为提高大型语言模型(LLMs)高级推理能力的关键技术(DeepSeek-AI,2025)。在针对LLMs设计的最先进RL算法中,包括GRPO(Shao等,2024)、VinePPO(Kazemnejad等,2024)和Leave-one-out PPO(Chen等,2025b;Ahmadian等,2024),一个显著趋势是从经典的PPO(Schulman等,2017)方法转变,即放弃学习到的价值函数网络,转而依赖经验估计的回报。这种转变减少了计算需求和GPU内存消耗,这对于将RL训练扩展到越来越大的LLMs至关重要。尽管放弃学习到的价值函数对RL训练有益,但牺牲了其在测试时间的潜在用途。传统上,价值函数估计未来的预期奖励,使其能够充当结果验证器(Cobbe等,2021),以评估给定推理链的正确性。这种验证能力对于通过并行搜索策略如Best-of-N或加权多数投票扩展推理计算非常有价值。我们认为,主流RL方法尚未充分利用类似价值信号提供的高效测试时间计算扩展潜力。为了捕捉这一潜力而不牺牲训练可扩展性,我们提出RLV\mathrm{RL}^{V}RLV,该方法通过生成式验证器(Zhang等,2024)增强“无价值”方法。与仅预测标量奖励的传统价值函数不同,生成式验证器利用LLM的生成能力。我们的核心思想是利用RL训练期间产生的大量数据,同时将LLM作为推理器和验证器进行训练。具体而言,我们将标准RL目标与生成验证目标联合优化,将验证视为基于RL生成的推理序列的下一个标记预测任务。这使得同一LLM可以发挥双重功能:作为生成解决方案的策略,同时提供反映感知解决方案正确性的内在生成分数。实证上,RLV\mathrm{RL}^{V}RLV在测试时间扩展方面显示出显著优势。当使用并行采样时,它比基础RL方法提升了超过20%20 \%20%的MATH准确性,并且实现了实质上更高效的测试时间计算扩展,达到了8−32×8-32 \times8−32×的改进,如图2所示。此外,RLV\mathrm{RL}^{V}RLV表现出强大的泛化能力,不仅在MATH2\mathrm{MATH}^{2}MATH2(Shah等,2025)中的更难数学问题上优于基础RL方法,还在GPQA物理(Rein等,2024)等域外任务中表现优异,如图4所示。RLV\mathrm{RL}^{V}RLV的好处还延伸到长CoT推理模型,当扩展并行和顺序计算时,它的性能比基线方法高出1.2−1.6×1.2-1.6 \times1.2−1.6×,在不同的生成长度和平行样本数量下始终产生最佳结果(图1,6)。
图2:在MATH500上使用加权多数投票扩展测试时间计算时,RLV\mathrm{RL}^{V}RLV相较于基础“无价值”RL方法提供了显著的计算效率和性能提升(Lightman等,2023)。对于评分解决方案,我们使用LLM-as-a-Judge作为基础方法的验证器,而RLV\mathrm{RL}^{V}RLV则使用训练好的统一验证器。这些结果基于对Qwen2.5-Math-1.5B在Hendrycks MATH上的RL微调。# 1 引言 在正确性奖励上的强化学习(RL)已成为提高大型语言模型(LLMs)高级推理能力的关键技术(DeepSeek-AI,2025)。在针对LLMs设计的最先进RL算法中,包括GRPO(Shao等,2024)、VinePPO(Kazemnejad等,2024)和Leave-one-out PPO(Chen等,2025b;Ahmadian等,2024),一个显著趋势是从经典的PPO(Schulman等,2017)方法转变,即放弃学习到的价值函数网络,转而依赖经验估计的回报。这种转变减少了计算需求和GPU内存消耗,这对于将RL训练扩展到越来越大的LLMs至关重要。尽管放弃学习到的价值函数对RL训练有益,但牺牲了其在测试时间的潜在用途。传统上,价值函数估计未来的预期奖励,使其能够充当结果验证器(Cobbe等,2021),以评估给定推理链的正确性。这种验证能力对于通过并行搜索策略如Best-of-N或加权多数投票扩展推理计算非常有价值。我们认为,主流RL方法尚未充分利用类似价值信号提供的高效测试时间计算扩展潜力。为了捕捉这一潜力而不牺牲训练可扩展性,我们提出RLV\mathrm{RL}^{V}RLV,该方法通过生成式验证器(Zhang等,2024)增强“无价值”方法。与仅预测标量奖励的传统价值函数不同,生成式验证器利用LLM的生成能力。我们的核心思想是利用RL训练期间产生的大量数据,同时将LLM作为推理器和验证器进行训练。具体而言,我们将标准RL目标与生成验证目标联合优化,将验证视为基于RL生成的推理序列的下一个标记预测任务。这使得同一LLM可以发挥双重功能:作为生成解决方案的策略,同时提供反映感知解决方案正确性的内在生成分数。实证上,RLV\mathrm{RL}^{V}RLV在测试时间扩展方面显示出显著优势。当使用并行采样时,它比基础RL方法提升了超过20%20 \%20%的MATH准确性,并且实现了实质上更高效的测试时间计算扩展,达到了8−32×8-32 \times8−32×的改进,如图2所示。此外,RLV\mathrm{RL}^{V}RLV表现出强大的泛化能力,不仅在MATH2\mathrm{MATH}^{2}MATH2(Shah等,2025)中的更难数学问题上优于基础RL方法,还在GPQA物理(Rein等,2024)等域外任务中表现优异,如图4所示。RLV\mathrm{RL}^{V}RLV的好处还延伸到长CoT推理模型,当扩展并行和顺序计算时,它的性能比基线方法高出1.2−1.6×1.2-1.6 \times1.2−1.6×,在不同的生成长度和平行样本数量下始终产生最佳结果(图1,6)。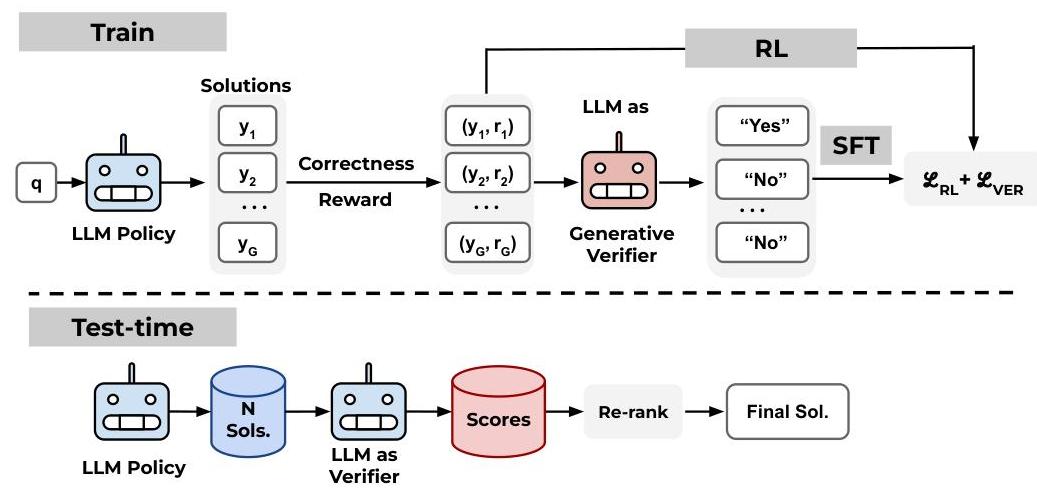 图3:RLV\mathrm{RL}^{\mathrm{V}}RLV概述:(顶部)在训练过程中,LLM策略生成解决方案yyy。此数据用于通过RL进行策略更新,同时通过监督微调(SFT)训练同一LLM作为生成式验证器,通过询问模型“这个解决方案是否正确?回答是或否”。(底部)在测试时,统一的LLM生成N个解决方案,同时也作为验证器为重新排名分配分数,使用Best-of-N或加权投票。# 2 相关工作 用于推理的RL。最近,通过RL从LLMs中引出改进推理的研究激增,包括传统的RL算法,如PPO(Zeng等,2025)。值得注意的是,可以利用PPO中训练的价值模型作为测试时间搜索的验证器(Liu等,2023)。然而,在最近的LLM应用中,“无价值”RL的趋势(Shao等,2024;DeepSeek-AI,2025;Kazemnejad等,2024;Ahmadian等,2024;Chen等,2025b)放弃了这种可能性,这种方法还涉及训练单独模型的开销。我们的工作旨在将验证与RL重新整合,提出一种简单的方法,其中生成式验证器与策略同时训练,利用RL训练期间生成的数据。测试时间验证。验证作为一种强大的方法,通过扩展时间时间计算来改善LLM推理,通常使用通过二元分类(Cobbe等,2021;Luo等,2024;Yu等,2024;Lightman等,2023;Setlur等,2025;Zhang等,2025)、偏好学习(Hosseini等,2024;Yuan等,2024)或最近使用下一个标记预测(Zhang等,2024;Mahan等,2024;Ankner等,2024)训练的单独模型。然而,这些单独的验证器带来了显著的开销:它们需要大量的训练数据集、额外的计算周期和大量的GPU内存,可能限制了加载在一起时LLM推理器的大小。相比之下,我们使用RL和生成式验证联合训练单一LLM。我们的方法几乎免费提供了一个有能力的验证器,几乎没有内存和极小的计算成本。此外,如图2所示,我们的方法在使用LLM-as-a-Judge作为验证器时,推断计算扩展效果远胜于RL策略。## 3 背景用于LLMs的强化学习涉及在一组提示X\mathcal{X}X下最大化LLM πθ\pi_{\theta}πθ的期望奖励,我们通常使用二元正确性奖励(DeepSeek-AI,2025)。为了保持稳定性和防止微调后的LLM与基础LLM πref\pi_{r e f}πref偏离太多,通常会添加一个KL散度惩罚,系数为β\betaβ,得到目标J(θ)\mathcal{J}(\theta)J(θ)(Stiennon等,2020):J(θ)=Ex∼X[JRL(θ;x)], where JRL(θ;x)=J(θ;x)−βDKL[πθ∥πref]\mathcal{J}(\theta)=\mathbb{E}_{\mathbf{x} \sim \mathcal{X}}\left[\mathcal{J}_{R L}(\theta ; \mathbf{x})\right], \text { where } \mathcal{J}_{R L}(\theta ; \mathbf{x})=\mathcal{J}(\theta ; \mathbf{x})-\beta D_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]J(θ)=Ex∼X[JRL(θ;x)], where JRL(θ;x)=J(θ;x)−βDKL[πθ∥πref]JRL(θ;x)\mathcal{J}_{R L}(\theta ; \mathbf{x})JRL(θ;x)通常使用策略梯度方法优化,如下所述。近端策略优化(PPO)(Schulman等,2017)是一个经典RL算法,用于微调LLMs,其中梯度更新受到裁剪机制的约束,以防止与前一策略发生大幅变化。目标描述如下:JPPO(θ;x):=Ey∼πθsld(.∣x)[1∣y∣∑t=1∣y∣min(pt(θ)A^t,clip(pt(θ),1−ϵ,1+ϵ)A^t)] where pt(θ)=πθ(yt∣x,y<t)πθsld(yt∣x,y<t)\begin{gathered}\mathcal{J}_{P P O}(\theta ; \mathbf{x}):=\mathbb{E}_{\mathbf{y} \sim \pi_{\theta_{s l d}}(. \mid \mathbf{x})}\left[\frac{1}{|\mathbf{y}|} \sum_{t=1}^{|\mathbf{y}|} \min \left(p_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(p_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right] \\\text { where } p_{t}(\theta)=\frac{\pi_{\theta}\left(y_{t} \mid \mathbf{x}, \mathbf{y}<t\right)}{\pi_{\theta_{s l d}}\left(y_{t} \mid \mathbf{x}, \mathbf{y}<t\right)}\end{gathered}JPPO(θ;x):=Ey∼πθsld(.∣x)
∣y∣1t=1∑∣y∣min(pt(θ)A^t,clip(pt(θ),1−ϵ,1+ϵ)A^t)
where pt(θ)=πθsld(yt∣x,y<t)πθ(yt∣x,y<t)其中ϵ\epsilonϵ是裁剪超参数,A^t\hat{A}_{t}A^t是令牌ttt的优势。优势通常使用GAE和学习到的价值网络估计(Schulman等,2018)。然而,对于LLMs,这种价值网络可能较慢、内存密集且不准确,导致最先进的方法放弃它。组相对策略优化(GRPO)(Shao等,2024)是PPO的一个变体,旨在缓解一些缺点,特别是训练LLMs时。GRPO的一个关键部分是它不需要显式的价值模型。相反,它直接从一组GGG输出{y1,y2,⋯ ,yG}\left\{\mathbf{y}_{1}, \mathbf{y}_{2}, \cdots, \mathbf{y}_{G}\right\}{y1,y2,⋯,yG}的奖励中估计优势计算的基线,这些输出为相同的提示x\mathbf{x}x生成。目标函数为:JGRPO(θ;x):=E{yi}i=1G∼πθsld(.∣x)[1G∑i=1G1∣yi∣∑t=1∣yi∣min(pt(θ)A^i,t,clip(pt(θ),1−ϵ,1+ϵ)A^i,t)] where A^i,t=ri−mean({r1,r2,⋯ ,rG})std({r1,r2,⋯ ,rG}),ri=r(x,yi)\begin{gathered}\mathcal{J}_{G R P O}(\theta ; \mathbf{x}):=\mathbb{E}_{\left\{\mathbf{y}_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{s l d}}(. \mid \mathbf{x})}\left[\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|\mathbf{y}_{i}\right|} \sum_{t=1}^{|\mathbf{y}_{i}|} \min \left(p_{t}(\theta) \hat{A}_{i, t}, \operatorname{clip}\left(p_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{i, t}\right)\right] \\\text { where } \quad \hat{A}_{i, t}=\frac{r_{i}-\operatorname{mean}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)}{\operatorname{std}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)}, r_{i}=r\left(\mathbf{x}, \mathbf{y}_{i}\right)\end{gathered}JGRPO(θ;x):=E{yi}i=1G∼πθsld(.∣x)
G1i=1∑G∣yi∣1t=1∑∣yi∣min(pt(θ)A^i,t,clip(pt(θ),1−ϵ,1+ϵ)A^i,t)
where A^i,t=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}),ri=r(x,yi)Leave-One-Out PPO(Chen等,2025b)也放弃了价值网络,类似于GRPO,并使用留一法估计器(Kool等,2019)估计优势。对于给定提示的KKK个输出,对于每个输出,使用剩余K−1K-1K−1个样本的平均奖励估计优势,即A^i,t=ri−1K−1∑t≠jrj\hat{A}_{i, t}=r_{i}-\frac{1}{K-1} \sum_{t \neq j} r_{j}A^i,t=ri−K−11∑t=jrj。VinePPO(Kazemnejad等,2024)通过计算中间状态的无偏蒙特卡洛价值估计改进PPO中的信用分配,而不是依赖于不准确的价值网络。具体而言,它使用当前策略πθ\pi_{\theta}πθ从状态st=x⊕y<ts_{t}=\mathbf{x} \oplus \mathbf{y}<tst=x⊕y<t开始生成KKK个生成yk′\mathbf{y}_{k}^{\prime}yk′,并平均其奖励以获得价值估计V^MC(st)\hat{V}_{M C}\left(s_{t}\right)V^MC(st)。然后将此估计插入优势计算中:A^t:=r(x,y<t+1)+V^MC(st+1)−V^MC(st), where V^MC(st):=1K∑k=1Kr(x,yk′)\hat{A}_{t}:=r\left(\mathbf{x}, \mathbf{y}<t+1\right)+\hat{V}_{M C}\left(s_{t+1}\right)-\hat{V}_{M C}\left(s_{t}\right), \text { where } \hat{V}_{M C}\left(s_{t}\right):=\frac{1}{K} \sum_{k=1}^{K} r\left(\mathbf{x}, \mathbf{y}_{k}^{\prime}\right)A^t:=r(x,y<t+1)+V^MC(st+1)−V^MC(st), where V^MC(st):=K1k=1∑Kr(x,yk′)测试时间计算扩展 突出的研究方向是在测试时间执行额外计算以提升LLMs的推理性能。流行的技术通常通过并行采样多个候选解决方案并使用启发式方法如多数投票选择最终答案(Wang等,2023)或使用验证器进行测试时间重排序,使用Best-of-N(Cobbe等,2021)或加权投票(Uesato等,2022)。最近,RL使按顺序生成长思维链(CoT)成为可能,这是推理模型如R1(DeepSeek-AI,2025)的特征。1{ }^{1}1 这与许多现代Reinforce Leave-One-Out (RLOO)(Ahmadian等,2024)实现相吻合,包括HuggingFace RLOOTrainer中的实现。生成式验证器 Zhang等(2024)将验证视为下一个标记预测,其中LLM接受问题x\mathbf{x}x和候选解决方案y\mathbf{y}y作为输入,并通过预测标记cyc_{\mathbf{y}}cy输出验证决策,该标记要么是‘Yes’要么是‘No’,以指示正确性。具体而言,我们使用监督微调(SFT)损失来最大化预测正确解决方案y+\mathbf{y}^{+}y+的‘Yes’和错误解决方案y−\mathbf{y}^{-}y−的‘No’的可能性:JVerify (θ;x):=E(x,y,I,cy)∼DVerify logπθ(cy∣x,y,I)\mathcal{J}_{\text {Verify }}(\theta ; \mathbf{x}):=\mathbb{E}_{(\mathbf{x}, \mathbf{y}, \mathbf{I}, c_{\mathbf{y}}) \sim \mathcal{D}_{\text {Verify }}} \log \pi_{\theta}\left(c_{\mathbf{y}} \mid \mathbf{x}, \mathbf{y}, \mathbf{I}\right)JVerify (θ;x):=E(x,y,I,cy)∼DVerify logπθ(cy∣x,y,I)其中DVerify ={(x,y+,I), ’Yes’ }⋃{(x,y−,I), ’No’ }\mathcal{D}_{\text {Verify }}=\left\{\left(\mathbf{x}, \mathbf{y}^{+}, \mathbf{I}\right), \text { 'Yes' }\right\} \bigcup\left\{\left(\mathbf{x}, \mathbf{y}^{-}, \mathbf{I}\right), \text { 'No' }\right\}DVerify ={(x,y+,I), ’Yes’ }⋃{(x,y−,I), ’No’ }是一个类别平衡的验证数据集,I\mathbf{I}I对应于提示‘这个解决方案是否正确?回答Yes或No。’。# 4 RL V^{V}V : 统一验证器与“无价值”RL推理器 流行的无价值RL方法(§3)改进了训练可扩展性,但放弃了价值网络,消除了像PPO这样的方法中可用的内在验证机制。这限制了依赖验证器在多个候选方案中选择最终解决方案的测试时间计算扩展方法。解决这一局限性目前涉及次优选择:部署单独的验证器模型或价值网络会产生显著的数据整理、计算和GPU内存开销(Ahmadian等,2024),而将基础LLM作为验证器(LLM-as-a-Judge)虽然开销最小,但由于缺乏特定任务的训练而效果较差(Zhang等,2024)。使用RL训练LLM推理器已经产生了大量的带有正确性奖励标签的解决方案数据,这些数据仅用于改进LLMs的推理能力。我们建议利用这些数据进行另一个目的:使用RL期间生成的这些解决方案同时在一个用于推理的LLM内训练生成式验证器。这种方法,我们称之为RL V{ }^{V}V,有效地构建了特定任务的验证能力,同时避免了单独验证器的高内存和计算成本,并且比基于提示的LLM-as-a-Judge 2{ }^{2}2更有效。统一训练。我们训练一个单一的LLM,以执行推理(解决问题)和验证任务。对于每一批次,验证目标使用RL过程中生成的(问题、解决方案、正确性奖励)元组作为训练示例。而不是使用具有回归或二元交叉熵损失的单独预测头(第5.4节探讨的替代方案),我们将生成式验证损失(方程4中的JVerify \mathcal{J}_{\text {Verify }}JVerify )添加到RL微调目标(方程1中的JRL\mathcal{J}_{R L}JRL),从而得出这个统一目标:JUnified (θ):=JRL(θ;x)+λJVerify (θ;x)\mathcal{J}_{\text {Unified }}(\theta):=\mathcal{J}_{R L}(\theta ; \mathbf{x})+\lambda \mathcal{J}_{\text {Verify }}(\theta ; \mathbf{x})JUnified (θ):=JRL(θ;x)+λJVerify (θ;x)其中超参数λ\lambdaλ平衡每个目标的贡献。具体而言,LLM学习预测‘Yes’或‘No’标记以评估给定解决方案的正确性。测试时间扩展 在测试时间,我们使用LLM验证器为其自身生成的解决方案打分,以指导最终答案的选择。这个得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)量化了验证器在其给定问题x\mathbf{x}x、解决方案y\mathbf{y}y和提示I\mathbf{I}I下的‘Yes’概率的信心,即s(x,y):=πθ(Yes∣x,y,I)s(\mathbf{x}, \mathbf{y}):=\pi_{\theta}(\operatorname{Yes} \mid \mathbf{x}, \mathbf{y}, \mathbf{I})s(x,y):=πθ(Yes∣x,y,I)。在这里,我们考虑三种并行采样方法:- 多数投票:一个没有验证器的基线,选择出现频率最高的答案。- Best-of-N:选择具有最高验证器得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)的解决方案。- 加权投票:对产生相同最终答案的解决方案的验证器得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)求和;选择具有最高累积得分的答案。## 5 实验我们的目标是研究我们提出的RL V{ }^{V}V方法的有效性和特性,该方法在单一LLM中统一了推理器和生成式验证器。我们回答几个2{ }^{2}2 对于基础RL(“无价值”)LLM-as-a-Judge实验,我们使用与RLV\mathrm{RL}^{V}RLV相同的验证提示,并在此设置中仅将预测‘Yes’的可能性作为得分,且不生成验证CoTs以进行公平比较。
图3:RLV\mathrm{RL}^{\mathrm{V}}RLV概述:(顶部)在训练过程中,LLM策略生成解决方案yyy。此数据用于通过RL进行策略更新,同时通过监督微调(SFT)训练同一LLM作为生成式验证器,通过询问模型“这个解决方案是否正确?回答是或否”。(底部)在测试时,统一的LLM生成N个解决方案,同时也作为验证器为重新排名分配分数,使用Best-of-N或加权投票。# 2 相关工作 用于推理的RL。最近,通过RL从LLMs中引出改进推理的研究激增,包括传统的RL算法,如PPO(Zeng等,2025)。值得注意的是,可以利用PPO中训练的价值模型作为测试时间搜索的验证器(Liu等,2023)。然而,在最近的LLM应用中,“无价值”RL的趋势(Shao等,2024;DeepSeek-AI,2025;Kazemnejad等,2024;Ahmadian等,2024;Chen等,2025b)放弃了这种可能性,这种方法还涉及训练单独模型的开销。我们的工作旨在将验证与RL重新整合,提出一种简单的方法,其中生成式验证器与策略同时训练,利用RL训练期间生成的数据。测试时间验证。验证作为一种强大的方法,通过扩展时间时间计算来改善LLM推理,通常使用通过二元分类(Cobbe等,2021;Luo等,2024;Yu等,2024;Lightman等,2023;Setlur等,2025;Zhang等,2025)、偏好学习(Hosseini等,2024;Yuan等,2024)或最近使用下一个标记预测(Zhang等,2024;Mahan等,2024;Ankner等,2024)训练的单独模型。然而,这些单独的验证器带来了显著的开销:它们需要大量的训练数据集、额外的计算周期和大量的GPU内存,可能限制了加载在一起时LLM推理器的大小。相比之下,我们使用RL和生成式验证联合训练单一LLM。我们的方法几乎免费提供了一个有能力的验证器,几乎没有内存和极小的计算成本。此外,如图2所示,我们的方法在使用LLM-as-a-Judge作为验证器时,推断计算扩展效果远胜于RL策略。## 3 背景用于LLMs的强化学习涉及在一组提示X\mathcal{X}X下最大化LLM πθ\pi_{\theta}πθ的期望奖励,我们通常使用二元正确性奖励(DeepSeek-AI,2025)。为了保持稳定性和防止微调后的LLM与基础LLM πref\pi_{r e f}πref偏离太多,通常会添加一个KL散度惩罚,系数为β\betaβ,得到目标J(θ)\mathcal{J}(\theta)J(θ)(Stiennon等,2020):J(θ)=Ex∼X[JRL(θ;x)], where JRL(θ;x)=J(θ;x)−βDKL[πθ∥πref]\mathcal{J}(\theta)=\mathbb{E}_{\mathbf{x} \sim \mathcal{X}}\left[\mathcal{J}_{R L}(\theta ; \mathbf{x})\right], \text { where } \mathcal{J}_{R L}(\theta ; \mathbf{x})=\mathcal{J}(\theta ; \mathbf{x})-\beta D_{K L}\left[\pi_{\theta} \| \pi_{r e f}\right]J(θ)=Ex∼X[JRL(θ;x)], where JRL(θ;x)=J(θ;x)−βDKL[πθ∥πref]JRL(θ;x)\mathcal{J}_{R L}(\theta ; \mathbf{x})JRL(θ;x)通常使用策略梯度方法优化,如下所述。近端策略优化(PPO)(Schulman等,2017)是一个经典RL算法,用于微调LLMs,其中梯度更新受到裁剪机制的约束,以防止与前一策略发生大幅变化。目标描述如下:JPPO(θ;x):=Ey∼πθsld(.∣x)[1∣y∣∑t=1∣y∣min(pt(θ)A^t,clip(pt(θ),1−ϵ,1+ϵ)A^t)] where pt(θ)=πθ(yt∣x,y<t)πθsld(yt∣x,y<t)\begin{gathered}\mathcal{J}_{P P O}(\theta ; \mathbf{x}):=\mathbb{E}_{\mathbf{y} \sim \pi_{\theta_{s l d}}(. \mid \mathbf{x})}\left[\frac{1}{|\mathbf{y}|} \sum_{t=1}^{|\mathbf{y}|} \min \left(p_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(p_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right] \\\text { where } p_{t}(\theta)=\frac{\pi_{\theta}\left(y_{t} \mid \mathbf{x}, \mathbf{y}<t\right)}{\pi_{\theta_{s l d}}\left(y_{t} \mid \mathbf{x}, \mathbf{y}<t\right)}\end{gathered}JPPO(θ;x):=Ey∼πθsld(.∣x)
∣y∣1t=1∑∣y∣min(pt(θ)A^t,clip(pt(θ),1−ϵ,1+ϵ)A^t)
where pt(θ)=πθsld(yt∣x,y<t)πθ(yt∣x,y<t)其中ϵ\epsilonϵ是裁剪超参数,A^t\hat{A}_{t}A^t是令牌ttt的优势。优势通常使用GAE和学习到的价值网络估计(Schulman等,2018)。然而,对于LLMs,这种价值网络可能较慢、内存密集且不准确,导致最先进的方法放弃它。组相对策略优化(GRPO)(Shao等,2024)是PPO的一个变体,旨在缓解一些缺点,特别是训练LLMs时。GRPO的一个关键部分是它不需要显式的价值模型。相反,它直接从一组GGG输出{y1,y2,⋯ ,yG}\left\{\mathbf{y}_{1}, \mathbf{y}_{2}, \cdots, \mathbf{y}_{G}\right\}{y1,y2,⋯,yG}的奖励中估计优势计算的基线,这些输出为相同的提示x\mathbf{x}x生成。目标函数为:JGRPO(θ;x):=E{yi}i=1G∼πθsld(.∣x)[1G∑i=1G1∣yi∣∑t=1∣yi∣min(pt(θ)A^i,t,clip(pt(θ),1−ϵ,1+ϵ)A^i,t)] where A^i,t=ri−mean({r1,r2,⋯ ,rG})std({r1,r2,⋯ ,rG}),ri=r(x,yi)\begin{gathered}\mathcal{J}_{G R P O}(\theta ; \mathbf{x}):=\mathbb{E}_{\left\{\mathbf{y}_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{s l d}}(. \mid \mathbf{x})}\left[\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|\mathbf{y}_{i}\right|} \sum_{t=1}^{|\mathbf{y}_{i}|} \min \left(p_{t}(\theta) \hat{A}_{i, t}, \operatorname{clip}\left(p_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{i, t}\right)\right] \\\text { where } \quad \hat{A}_{i, t}=\frac{r_{i}-\operatorname{mean}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)}{\operatorname{std}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)}, r_{i}=r\left(\mathbf{x}, \mathbf{y}_{i}\right)\end{gathered}JGRPO(θ;x):=E{yi}i=1G∼πθsld(.∣x)
G1i=1∑G∣yi∣1t=1∑∣yi∣min(pt(θ)A^i,t,clip(pt(θ),1−ϵ,1+ϵ)A^i,t)
where A^i,t=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}),ri=r(x,yi)Leave-One-Out PPO(Chen等,2025b)也放弃了价值网络,类似于GRPO,并使用留一法估计器(Kool等,2019)估计优势。对于给定提示的KKK个输出,对于每个输出,使用剩余K−1K-1K−1个样本的平均奖励估计优势,即A^i,t=ri−1K−1∑t≠jrj\hat{A}_{i, t}=r_{i}-\frac{1}{K-1} \sum_{t \neq j} r_{j}A^i,t=ri−K−11∑t=jrj。VinePPO(Kazemnejad等,2024)通过计算中间状态的无偏蒙特卡洛价值估计改进PPO中的信用分配,而不是依赖于不准确的价值网络。具体而言,它使用当前策略πθ\pi_{\theta}πθ从状态st=x⊕y<ts_{t}=\mathbf{x} \oplus \mathbf{y}<tst=x⊕y<t开始生成KKK个生成yk′\mathbf{y}_{k}^{\prime}yk′,并平均其奖励以获得价值估计V^MC(st)\hat{V}_{M C}\left(s_{t}\right)V^MC(st)。然后将此估计插入优势计算中:A^t:=r(x,y<t+1)+V^MC(st+1)−V^MC(st), where V^MC(st):=1K∑k=1Kr(x,yk′)\hat{A}_{t}:=r\left(\mathbf{x}, \mathbf{y}<t+1\right)+\hat{V}_{M C}\left(s_{t+1}\right)-\hat{V}_{M C}\left(s_{t}\right), \text { where } \hat{V}_{M C}\left(s_{t}\right):=\frac{1}{K} \sum_{k=1}^{K} r\left(\mathbf{x}, \mathbf{y}_{k}^{\prime}\right)A^t:=r(x,y<t+1)+V^MC(st+1)−V^MC(st), where V^MC(st):=K1k=1∑Kr(x,yk′)测试时间计算扩展 突出的研究方向是在测试时间执行额外计算以提升LLMs的推理性能。流行的技术通常通过并行采样多个候选解决方案并使用启发式方法如多数投票选择最终答案(Wang等,2023)或使用验证器进行测试时间重排序,使用Best-of-N(Cobbe等,2021)或加权投票(Uesato等,2022)。最近,RL使按顺序生成长思维链(CoT)成为可能,这是推理模型如R1(DeepSeek-AI,2025)的特征。1{ }^{1}1 这与许多现代Reinforce Leave-One-Out (RLOO)(Ahmadian等,2024)实现相吻合,包括HuggingFace RLOOTrainer中的实现。生成式验证器 Zhang等(2024)将验证视为下一个标记预测,其中LLM接受问题x\mathbf{x}x和候选解决方案y\mathbf{y}y作为输入,并通过预测标记cyc_{\mathbf{y}}cy输出验证决策,该标记要么是‘Yes’要么是‘No’,以指示正确性。具体而言,我们使用监督微调(SFT)损失来最大化预测正确解决方案y+\mathbf{y}^{+}y+的‘Yes’和错误解决方案y−\mathbf{y}^{-}y−的‘No’的可能性:JVerify (θ;x):=E(x,y,I,cy)∼DVerify logπθ(cy∣x,y,I)\mathcal{J}_{\text {Verify }}(\theta ; \mathbf{x}):=\mathbb{E}_{(\mathbf{x}, \mathbf{y}, \mathbf{I}, c_{\mathbf{y}}) \sim \mathcal{D}_{\text {Verify }}} \log \pi_{\theta}\left(c_{\mathbf{y}} \mid \mathbf{x}, \mathbf{y}, \mathbf{I}\right)JVerify (θ;x):=E(x,y,I,cy)∼DVerify logπθ(cy∣x,y,I)其中DVerify ={(x,y+,I), ’Yes’ }⋃{(x,y−,I), ’No’ }\mathcal{D}_{\text {Verify }}=\left\{\left(\mathbf{x}, \mathbf{y}^{+}, \mathbf{I}\right), \text { 'Yes' }\right\} \bigcup\left\{\left(\mathbf{x}, \mathbf{y}^{-}, \mathbf{I}\right), \text { 'No' }\right\}DVerify ={(x,y+,I), ’Yes’ }⋃{(x,y−,I), ’No’ }是一个类别平衡的验证数据集,I\mathbf{I}I对应于提示‘这个解决方案是否正确?回答Yes或No。’。# 4 RL V^{V}V : 统一验证器与“无价值”RL推理器 流行的无价值RL方法(§3)改进了训练可扩展性,但放弃了价值网络,消除了像PPO这样的方法中可用的内在验证机制。这限制了依赖验证器在多个候选方案中选择最终解决方案的测试时间计算扩展方法。解决这一局限性目前涉及次优选择:部署单独的验证器模型或价值网络会产生显著的数据整理、计算和GPU内存开销(Ahmadian等,2024),而将基础LLM作为验证器(LLM-as-a-Judge)虽然开销最小,但由于缺乏特定任务的训练而效果较差(Zhang等,2024)。使用RL训练LLM推理器已经产生了大量的带有正确性奖励标签的解决方案数据,这些数据仅用于改进LLMs的推理能力。我们建议利用这些数据进行另一个目的:使用RL期间生成的这些解决方案同时在一个用于推理的LLM内训练生成式验证器。这种方法,我们称之为RL V{ }^{V}V,有效地构建了特定任务的验证能力,同时避免了单独验证器的高内存和计算成本,并且比基于提示的LLM-as-a-Judge 2{ }^{2}2更有效。统一训练。我们训练一个单一的LLM,以执行推理(解决问题)和验证任务。对于每一批次,验证目标使用RL过程中生成的(问题、解决方案、正确性奖励)元组作为训练示例。而不是使用具有回归或二元交叉熵损失的单独预测头(第5.4节探讨的替代方案),我们将生成式验证损失(方程4中的JVerify \mathcal{J}_{\text {Verify }}JVerify )添加到RL微调目标(方程1中的JRL\mathcal{J}_{R L}JRL),从而得出这个统一目标:JUnified (θ):=JRL(θ;x)+λJVerify (θ;x)\mathcal{J}_{\text {Unified }}(\theta):=\mathcal{J}_{R L}(\theta ; \mathbf{x})+\lambda \mathcal{J}_{\text {Verify }}(\theta ; \mathbf{x})JUnified (θ):=JRL(θ;x)+λJVerify (θ;x)其中超参数λ\lambdaλ平衡每个目标的贡献。具体而言,LLM学习预测‘Yes’或‘No’标记以评估给定解决方案的正确性。测试时间扩展 在测试时间,我们使用LLM验证器为其自身生成的解决方案打分,以指导最终答案的选择。这个得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)量化了验证器在其给定问题x\mathbf{x}x、解决方案y\mathbf{y}y和提示I\mathbf{I}I下的‘Yes’概率的信心,即s(x,y):=πθ(Yes∣x,y,I)s(\mathbf{x}, \mathbf{y}):=\pi_{\theta}(\operatorname{Yes} \mid \mathbf{x}, \mathbf{y}, \mathbf{I})s(x,y):=πθ(Yes∣x,y,I)。在这里,我们考虑三种并行采样方法:- 多数投票:一个没有验证器的基线,选择出现频率最高的答案。- Best-of-N:选择具有最高验证器得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)的解决方案。- 加权投票:对产生相同最终答案的解决方案的验证器得分s(x,y)s(\mathbf{x}, \mathbf{y})s(x,y)求和;选择具有最高累积得分的答案。## 5 实验我们的目标是研究我们提出的RL V{ }^{V}V方法的有效性和特性,该方法在单一LLM中统一了推理器和生成式验证器。我们回答几个2{ }^{2}2 对于基础RL(“无价值”)LLM-as-a-Judge实验,我们使用与RLV\mathrm{RL}^{V}RLV相同的验证提示,并在此设置中仅将预测‘Yes’的可能性作为得分,且不生成验证CoTs以进行公平比较。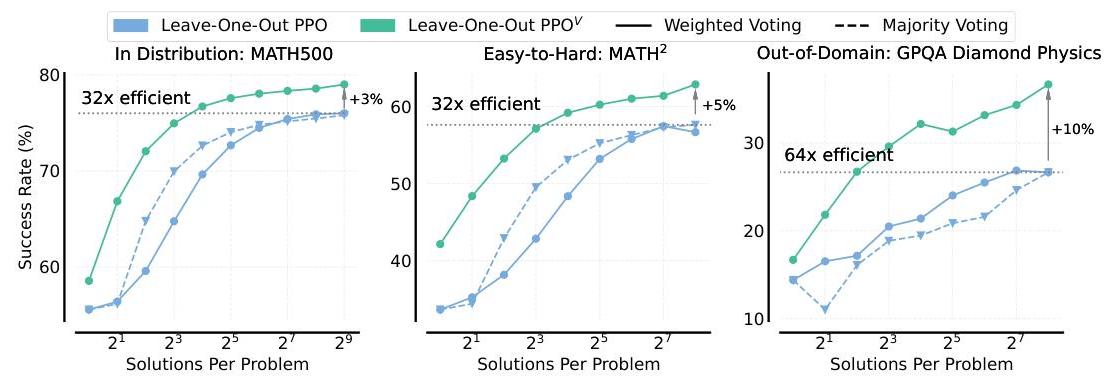 图4:RLV\mathrm{RL}^{V}RLV在相对于MATH训练数据集的不同泛化设置下,持续优于基础RL方法(Leave-One-Out-PPO),无论生成多少解决方案。 (左)在MATH500上的同分布泛化。(中心)在MATH2\mathrm{MATH}^{2}MATH2上的易到难泛化。(右)在GPQA Diamond拆分中的物理问题上的域外泛化。关于这种范式的关键问题:1)RLV\mathrm{RL}^{V}RLV如何与并行测试时间计算扩展?2)统一验证器应如何训练?3)统一验证器应在测试时间如何使用?4)RLV\mathrm{RL}^{V}RLV如何与思考模型中的顺序扩展交互?设置 所有实验的RL训练均使用Hendycks的MATH数据集(Hendrycks等,2021)并在4×4 \times4× A100 80G Nvidia GPU上运行3小时。评估报告在MATH500(Lightman等,2023)、MATH 2{ }^{2}2(Shah等,2025)、GPQA(Rein等,2024)和AIME’24上进行。对于涉及较短思维链(CoT)推理的实验,我们使用了Qwen2.5 Math 1.5B模型(Yang等,2024)。我们使用GRPO、Leave-One-Out PPO和VinePPO进行微调,带或不带统一验证。训练使用了1024个标记的上下文窗口。在推理期间,我们为MATH500生成最多1024个标记,为其他测试集生成最多2048个标记。为了展示模型扩展的影响,我们还使用Leave-One-Out PPO训练了Qwen2.5 Math 7B模型(Yang等,2024)。长CoT实验使用了DeepSeek-R1-Distill-Qwen-1.5B,这是DeepSeek-R1的蒸馏版本。我们对其进行GRPO调优,并使用SGLang(Zheng等,2024)进行推理。RL训练过程涉及在线迭代中每次采样32个问题,每个问题生成5个解决方案。使用批次大小为8,这导致每次迭代有32次更新。训练持续40个epoch。模型使用“长”思维链提示进行训练,该提示将推理包围在特殊标签中(见附录D.2)。# 5.1 测试时间计算扩展与RL V{ }^{V}V 同分布泛化 RLV\mathrm{RL}^{V}RLV在MATH500上使用512个样本时,比基线效率高出32×32 \times32×,准确率高出4%4 \%4%(图4)。此外,图2显示,在不同的RL方法中,RLV\mathrm{RL}^{V}RLV实现了更高的最终准确率水平。它还可以用显著较少的计算达到强准确率。图8显示这些收益在7B规模上得以维持。易到难泛化 Zhang等(2024)和Sun等(2024)证明,他们训练的验证器可以在遇到比训练期间更复杂的难题集时泛化到固定的独立LLM推理器。如图4(中心)所示,我们提出的方法RLV\mathrm{RL}^{V}RLV与统一的推理器和验证器,也在MATH2\mathrm{MATH}^{2}MATH2(Shah等,2025)上表现出强大的易到难泛化能力,包含需要非平凡结合来自MATH的两个不同技能的更难数学问题。
图4:RLV\mathrm{RL}^{V}RLV在相对于MATH训练数据集的不同泛化设置下,持续优于基础RL方法(Leave-One-Out-PPO),无论生成多少解决方案。 (左)在MATH500上的同分布泛化。(中心)在MATH2\mathrm{MATH}^{2}MATH2上的易到难泛化。(右)在GPQA Diamond拆分中的物理问题上的域外泛化。关于这种范式的关键问题:1)RLV\mathrm{RL}^{V}RLV如何与并行测试时间计算扩展?2)统一验证器应如何训练?3)统一验证器应在测试时间如何使用?4)RLV\mathrm{RL}^{V}RLV如何与思考模型中的顺序扩展交互?设置 所有实验的RL训练均使用Hendycks的MATH数据集(Hendrycks等,2021)并在4×4 \times4× A100 80G Nvidia GPU上运行3小时。评估报告在MATH500(Lightman等,2023)、MATH 2{ }^{2}2(Shah等,2025)、GPQA(Rein等,2024)和AIME’24上进行。对于涉及较短思维链(CoT)推理的实验,我们使用了Qwen2.5 Math 1.5B模型(Yang等,2024)。我们使用GRPO、Leave-One-Out PPO和VinePPO进行微调,带或不带统一验证。训练使用了1024个标记的上下文窗口。在推理期间,我们为MATH500生成最多1024个标记,为其他测试集生成最多2048个标记。为了展示模型扩展的影响,我们还使用Leave-One-Out PPO训练了Qwen2.5 Math 7B模型(Yang等,2024)。长CoT实验使用了DeepSeek-R1-Distill-Qwen-1.5B,这是DeepSeek-R1的蒸馏版本。我们对其进行GRPO调优,并使用SGLang(Zheng等,2024)进行推理。RL训练过程涉及在线迭代中每次采样32个问题,每个问题生成5个解决方案。使用批次大小为8,这导致每次迭代有32次更新。训练持续40个epoch。模型使用“长”思维链提示进行训练,该提示将推理包围在特殊标签中(见附录D.2)。# 5.1 测试时间计算扩展与RL V{ }^{V}V 同分布泛化 RLV\mathrm{RL}^{V}RLV在MATH500上使用512个样本时,比基线效率高出32×32 \times32×,准确率高出4%4 \%4%(图4)。此外,图2显示,在不同的RL方法中,RLV\mathrm{RL}^{V}RLV实现了更高的最终准确率水平。它还可以用显著较少的计算达到强准确率。图8显示这些收益在7B规模上得以维持。易到难泛化 Zhang等(2024)和Sun等(2024)证明,他们训练的验证器可以在遇到比训练期间更复杂的难题集时泛化到固定的独立LLM推理器。如图4(中心)所示,我们提出的方法RLV\mathrm{RL}^{V}RLV与统一的推理器和验证器,也在MATH2\mathrm{MATH}^{2}MATH2(Shah等,2025)上表现出强大的易到难泛化能力,包含需要非平凡结合来自MATH的两个不同技能的更难数学问题。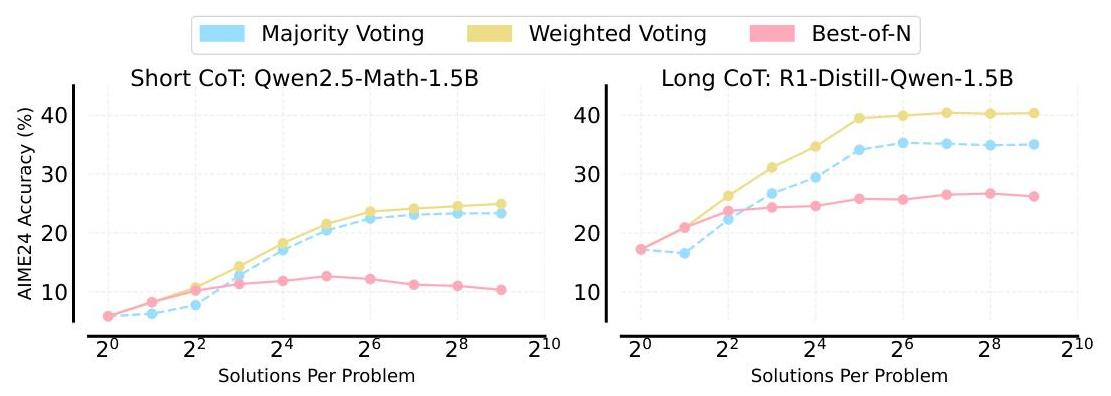 图5:比较测试时间计算策略 评估基于验证的答案例选择策略(加权投票、Best-of-N)和无验证的多数投票在AIME’24上的表现。最佳策略因短CoT和长CoT调优模型而异。域外泛化 超越易到难泛化,我们还评估了在GPQA物理问题(Rein等,2024)上的域外性能。RL V{ }^{V}V在加权投票中使用512个样本时,相比基线显示出超过10%10 \%10%的准确率改进。RLV\mathrm{RL}^{V}RLV可以带来更好的推理器 有趣的是,我们在所有这些任务中观察到,RLV\mathrm{RL}^{V}RLV的统一训练在没有任何额外测试时间计算的情况下,带来了pass@1(Chen等,2021)性能的积极转移,表明生成验证和RL目标之间存在协同效应(见图4)。这种改进在1.5B和7B规模的Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV模型中都有体现。# 5.2 计算最优扩展:如何使用您的RL V{ }^{V}V验证器? 如第§4\S 4§4节所述,可以在测试时间使用验证器对生成的解决方案进行评分。随后,可以根据这些评分使用Best-of-N(BoN)策略或基于这些评分的加权投票选择最终答案。我们在AIME 2024数据集上进行了GRPO V{ }^{V}V调优模型的实验。具体而言,我们测试了基于Qwen2.5-Math-1.5B和R1-Distill-Qwen-1.5B的变体,它们分别生成短和长CoTs(图5)。对于短CoT模型(Qwen2.5-Math-1.5B,图5左面板),当对每个问题采样8个或更多解决方案时,加权投票一致优于多数投票和Best-of-N。这一趋势也适用于长CoT模型(图5,右)。我们对推理策略的发现与使用相同模型的基线RL实验一致,在这些实验中我们不训练统一验证器,而是简单地将相同的微调推理模型作为验证器进行提示。### 5.3 补充长推理模型与RL V{ }^{V}V一种新兴技术是通过RL训练模型生成更长的思维链(CoTs),在回答之前模拟更深的推理。采用这种技术的模型,如DeepSeekR1(DeepSeek-AI,2025),可以在推理过程中额外分配顺序计算来进行自我验证、反思和精炼最终输出。然而,他们在思维过程中找到和验证解决方案所分配的计算量是不可控的。此外,他们推理的确切机制尚未完全理解。因此,可以可靠调用的验证器可能会进一步受益于推理时间扩展。我们提出的方法是对顺序推理计算扩展的补充。图6显示了不同方法在改变生成解决方案数量和允许生成长度(以标记为单位)时在AIME 24上取得的成功率。
图5:比较测试时间计算策略 评估基于验证的答案例选择策略(加权投票、Best-of-N)和无验证的多数投票在AIME’24上的表现。最佳策略因短CoT和长CoT调优模型而异。域外泛化 超越易到难泛化,我们还评估了在GPQA物理问题(Rein等,2024)上的域外性能。RL V{ }^{V}V在加权投票中使用512个样本时,相比基线显示出超过10%10 \%10%的准确率改进。RLV\mathrm{RL}^{V}RLV可以带来更好的推理器 有趣的是,我们在所有这些任务中观察到,RLV\mathrm{RL}^{V}RLV的统一训练在没有任何额外测试时间计算的情况下,带来了pass@1(Chen等,2021)性能的积极转移,表明生成验证和RL目标之间存在协同效应(见图4)。这种改进在1.5B和7B规模的Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV模型中都有体现。# 5.2 计算最优扩展:如何使用您的RL V{ }^{V}V验证器? 如第§4\S 4§4节所述,可以在测试时间使用验证器对生成的解决方案进行评分。随后,可以根据这些评分使用Best-of-N(BoN)策略或基于这些评分的加权投票选择最终答案。我们在AIME 2024数据集上进行了GRPO V{ }^{V}V调优模型的实验。具体而言,我们测试了基于Qwen2.5-Math-1.5B和R1-Distill-Qwen-1.5B的变体,它们分别生成短和长CoTs(图5)。对于短CoT模型(Qwen2.5-Math-1.5B,图5左面板),当对每个问题采样8个或更多解决方案时,加权投票一致优于多数投票和Best-of-N。这一趋势也适用于长CoT模型(图5,右)。我们对推理策略的发现与使用相同模型的基线RL实验一致,在这些实验中我们不训练统一验证器,而是简单地将相同的微调推理模型作为验证器进行提示。### 5.3 补充长推理模型与RL V{ }^{V}V一种新兴技术是通过RL训练模型生成更长的思维链(CoTs),在回答之前模拟更深的推理。采用这种技术的模型,如DeepSeekR1(DeepSeek-AI,2025),可以在推理过程中额外分配顺序计算来进行自我验证、反思和精炼最终输出。然而,他们在思维过程中找到和验证解决方案所分配的计算量是不可控的。此外,他们推理的确切机制尚未完全理解。因此,可以可靠调用的验证器可能会进一步受益于推理时间扩展。我们提出的方法是对顺序推理计算扩展的补充。图6显示了不同方法在改变生成解决方案数量和允许生成长度(以标记为单位)时在AIME 24上取得的成功率。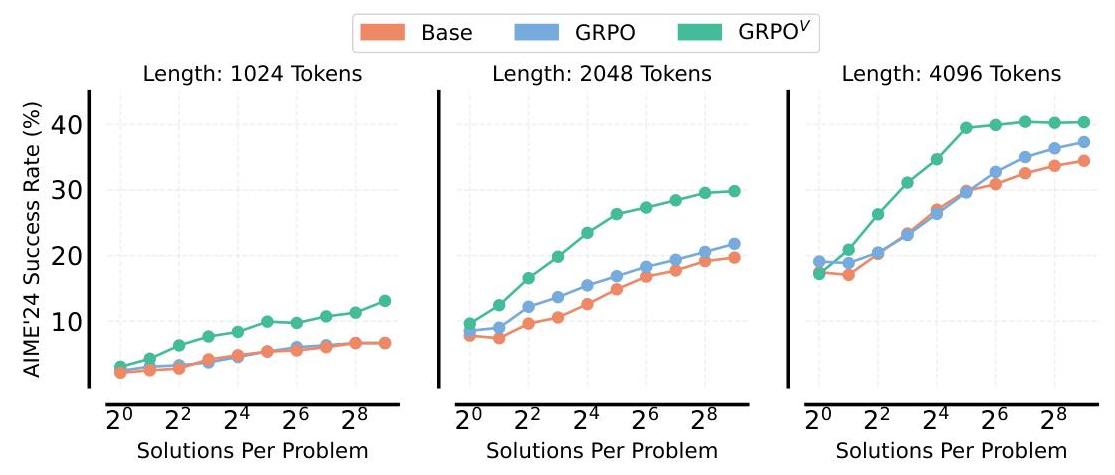 图6:使用RLV\mathrm{RL}^{V}RLV扩展并行计算补充顺序扩展。AIME’24成功率 vs 基础(初始检查点)、GRPO调优模型(无验证训练)和GRPO V{ }^{V}V(统一验证器和推理器)在不同生成长度下的生成解决方案数量。GRPO V{ }^{V}V始终优于GRPO,从增加的推理努力(更多解决方案,更长生成)中获益最多。对于每个模型,我们选择提供最高成功率的推理时间策略(Best-of-N、多数投票、加权投票)。详见预算强制详情在§B\S \mathrm{B}§B。预算强制(Muennighoff等,2025)。值得注意的是,GRPO V{ }^{V}V方法始终实现最高的成功率,在更长生成长度下更为明显,并且随着采样解决方案数量的增加表现良好,表明与顺序扩展有互补收益。此外,RLV\mathrm{RL}^{V}RLV验证器允许精细控制为给定问题生成的标记数量。在图1中,我们预先定义了一个加权投票答案需要达到的置信度阈值。如果具有给定序列长度(从1024、2048和4096)的解决方案未达到阈值,则选择更长的序列长度,直到达到阈值为止。这允许模型为更困难的问题动态分配更多的顺序计算资源。图1显示了AIME’24准确率随着平均生成长度的稳步增加。我们假设这种方法对于非常长上下文模型(例如32 K标记)可能会带来巨大的效率提升,因为正确答案通常在模型停止生成之前很久就已达到(DeepSeek-AI,2025)。# 5.4 如何训练您的统一验证器? 文献提供了几种训练统一验证器的选择。常见方法包括在策略网络之上添加专用验证头,使用二元交叉熵(BCE)(Cobbe等,2021;Lightman等,2023)或回归目标(Stiennon等,2020)进行分类以预测解决方案得分。Zhang等(2024)提出的生成验证表明,它可以生成有能力的验证器,而不会降低策略的核心推理性能,有时甚至可以提高性能。图7比较了各种验证器训练方法的推理器准确性(通过pass@1测量)和验证器准确性(在正确和错误解决方案的平衡集上测量)。值得注意的是,使用LLM-as-a-Judge和二元交叉熵(BCE)或回归(REG)进行单独验证头训练的Leave-One-Out PPO在作为推理器和验证器方面的表现都很差,而Leave-One-Out PPO V{ }^{V}V则显著优于这两种方法。总体而言,RLV\mathrm{RL}^{V}RLV在作为推理器和验证器方面都优于基础RL和带有单独验证头的RL方法。此外,RLV\mathrm{RL}^{V}RLV验证器的准确性与在同一RL运行记录数据上训练的单独验证器相当,显示出联合训练的最小损失。统一训练中的一个关键超参数是验证系数λ\lambdaλ(见方程5),它平衡推理和验证目标。其影响在图7b中进行了探讨。
图6:使用RLV\mathrm{RL}^{V}RLV扩展并行计算补充顺序扩展。AIME’24成功率 vs 基础(初始检查点)、GRPO调优模型(无验证训练)和GRPO V{ }^{V}V(统一验证器和推理器)在不同生成长度下的生成解决方案数量。GRPO V{ }^{V}V始终优于GRPO,从增加的推理努力(更多解决方案,更长生成)中获益最多。对于每个模型,我们选择提供最高成功率的推理时间策略(Best-of-N、多数投票、加权投票)。详见预算强制详情在§B\S \mathrm{B}§B。预算强制(Muennighoff等,2025)。值得注意的是,GRPO V{ }^{V}V方法始终实现最高的成功率,在更长生成长度下更为明显,并且随着采样解决方案数量的增加表现良好,表明与顺序扩展有互补收益。此外,RLV\mathrm{RL}^{V}RLV验证器允许精细控制为给定问题生成的标记数量。在图1中,我们预先定义了一个加权投票答案需要达到的置信度阈值。如果具有给定序列长度(从1024、2048和4096)的解决方案未达到阈值,则选择更长的序列长度,直到达到阈值为止。这允许模型为更困难的问题动态分配更多的顺序计算资源。图1显示了AIME’24准确率随着平均生成长度的稳步增加。我们假设这种方法对于非常长上下文模型(例如32 K标记)可能会带来巨大的效率提升,因为正确答案通常在模型停止生成之前很久就已达到(DeepSeek-AI,2025)。# 5.4 如何训练您的统一验证器? 文献提供了几种训练统一验证器的选择。常见方法包括在策略网络之上添加专用验证头,使用二元交叉熵(BCE)(Cobbe等,2021;Lightman等,2023)或回归目标(Stiennon等,2020)进行分类以预测解决方案得分。Zhang等(2024)提出的生成验证表明,它可以生成有能力的验证器,而不会降低策略的核心推理性能,有时甚至可以提高性能。图7比较了各种验证器训练方法的推理器准确性(通过pass@1测量)和验证器准确性(在正确和错误解决方案的平衡集上测量)。值得注意的是,使用LLM-as-a-Judge和二元交叉熵(BCE)或回归(REG)进行单独验证头训练的Leave-One-Out PPO在作为推理器和验证器方面的表现都很差,而Leave-One-Out PPO V{ }^{V}V则显著优于这两种方法。总体而言,RLV\mathrm{RL}^{V}RLV在作为推理器和验证器方面都优于基础RL和带有单独验证头的RL方法。此外,RLV\mathrm{RL}^{V}RLV验证器的准确性与在同一RL运行记录数据上训练的单独验证器相当,显示出联合训练的最小损失。统一训练中的一个关键超参数是验证系数λ\lambdaλ(见方程5),它平衡推理和验证目标。其影响在图7b中进行了探讨。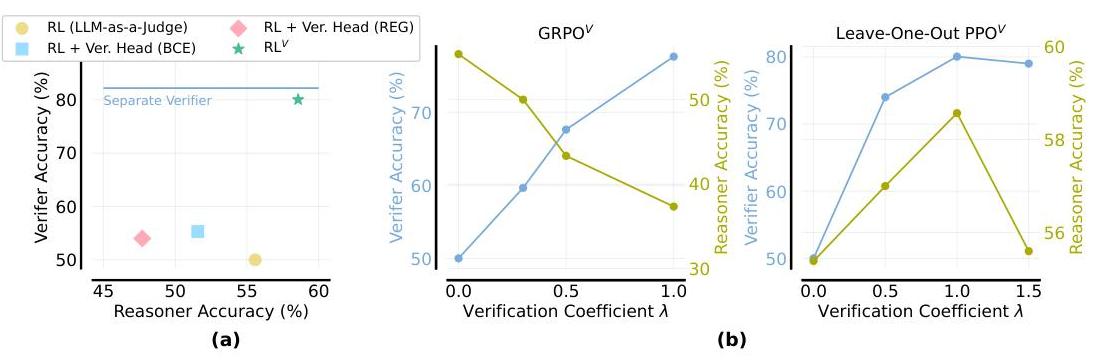 图7:(a) 不同统一验证器训练策略的推理器准确性与验证器准确性的比较。Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV显著优于使用LLM-as-a-Judge和单独验证头的Leave-OneOut PPO,在两个指标上使用二元交叉熵(BCE)或回归(REG)均有更好表现。(b) 验证系数λ\lambdaλ对RLV\mathrm{RL}^{V}RLV的推理器和验证器准确性的影响。对于GRPOV\mathrm{GRPO}^{V}GRPOV,存在明显的权衡。增加λ\lambdaλ显著提高验证器准确性(从∼50%\sim 50 \%∼50% 到∼80%\sim 80 \%∼80%),但大幅降低推理器准确性(从∼54%\sim 54 \%∼54% 下降到∼35%\sim 35 \%∼35%)。优先验证严重损害推理在这种设置下。相比之下,对于Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV,权衡更加微妙。验证器准确性随着λ\lambdaλ的增加持续改善直至饱和(从∼50%\sim 50 \%∼50% 到∼80%\sim 80 \%∼80%)。关键在于,推理器准确性在λ=1\lambda=1λ=1左右达到峰值后略有下降。这表明Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV可以实现更好的平衡,最佳推理性能发生在中间验证系数处,此时验证器准确性也很强。# 6 讨论与未来工作 我们提出了RLV\mathrm{RL}^{V}RLV,该方法在“无价值”RL框架中集成验证,而无需显著开销,从而在MATH、MATH 2{ }^{2}2、GPQA、AIME 24数据集上取得了推理准确性、测试时间计算效率和泛化的显著提升。这种方法补充了长推理CoT模型中的顺序扩展,并从生成验证训练中受益,证明优于其他替代方法。基于这些发现,未来的工作可以集中在增强生成式验证器以产生明确的CoT解释(Zhang等,2024)。然而,训练这样的验证器需要特定于验证的CoT数据或RL训练本身。我们推测未来的研究可以有利地探索这个方向,以通过RL实现解决方案生成和验证的统一框架。进一步调查RLT\mathrm{RL}^{\mathrm{T}}RLT在其他推理领域的适用性和与更大LLMs的可扩展性仍然相关。# 7 致谢 我们要感谢Khang Ngo在实验基础设施设置方面的支持。我们要感谢Siva Reddy和Arkil Patel对本文的宝贵反馈以及参与富有洞察力的讨论。我们还要感谢Mila的基础设施团队和微软研究院提供使本项目成为可能的计算资源。## 8 作者贡献KS领导了该项目,几乎完成了所有的实验和消融研究,并撰写了论文和编辑。MM负责长CoT实验并编辑了论文。AS为项目提供建议,对写作提供了反馈并编写了初始的GRPO和VinePPO代码。RA与AH一起构思了该项目,指导了KS,并对论文提供了反馈。AH和RA提出了多项想法和实验,撰写了初稿,并平等指导了该项目。AH仅担任顾问角色。## 参考文献Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 回归基础:重新审视用于从人类反馈中学习的强化学习优化方法。In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 1116, 2024, pp. 12248-12267. Association for Computational Linguistics, 2024. doi: 10.18653/ V1/2024.ACL-LONG.662. URL https://doi.org/10.18653/v1/2024.acl-long.662.Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. 公开批评奖励模型。arXiv preprint arXiv:2408.11791, 2024.Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 宪法AI:从AI反馈中实现无害性。arXiv preprint arXiv:2212.08073, 2022.Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, and Sercan Ö. Arik. SETS: 利用自验证和自校正实现改进的测试时间扩展。CoRR, abs/2501.19306, 2025a. doi: 10.48550/ARXIV.2501.19306. URL https://doi.or.
图7:(a) 不同统一验证器训练策略的推理器准确性与验证器准确性的比较。Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV显著优于使用LLM-as-a-Judge和单独验证头的Leave-OneOut PPO,在两个指标上使用二元交叉熵(BCE)或回归(REG)均有更好表现。(b) 验证系数λ\lambdaλ对RLV\mathrm{RL}^{V}RLV的推理器和验证器准确性的影响。对于GRPOV\mathrm{GRPO}^{V}GRPOV,存在明显的权衡。增加λ\lambdaλ显著提高验证器准确性(从∼50%\sim 50 \%∼50% 到∼80%\sim 80 \%∼80%),但大幅降低推理器准确性(从∼54%\sim 54 \%∼54% 下降到∼35%\sim 35 \%∼35%)。优先验证严重损害推理在这种设置下。相比之下,对于Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV,权衡更加微妙。验证器准确性随着λ\lambdaλ的增加持续改善直至饱和(从∼50%\sim 50 \%∼50% 到∼80%\sim 80 \%∼80%)。关键在于,推理器准确性在λ=1\lambda=1λ=1左右达到峰值后略有下降。这表明Leave-One-Out PPOV\mathrm{PPO}^{V}PPOV可以实现更好的平衡,最佳推理性能发生在中间验证系数处,此时验证器准确性也很强。# 6 讨论与未来工作 我们提出了RLV\mathrm{RL}^{V}RLV,该方法在“无价值”RL框架中集成验证,而无需显著开销,从而在MATH、MATH 2{ }^{2}2、GPQA、AIME 24数据集上取得了推理准确性、测试时间计算效率和泛化的显著提升。这种方法补充了长推理CoT模型中的顺序扩展,并从生成验证训练中受益,证明优于其他替代方法。基于这些发现,未来的工作可以集中在增强生成式验证器以产生明确的CoT解释(Zhang等,2024)。然而,训练这样的验证器需要特定于验证的CoT数据或RL训练本身。我们推测未来的研究可以有利地探索这个方向,以通过RL实现解决方案生成和验证的统一框架。进一步调查RLT\mathrm{RL}^{\mathrm{T}}RLT在其他推理领域的适用性和与更大LLMs的可扩展性仍然相关。# 7 致谢 我们要感谢Khang Ngo在实验基础设施设置方面的支持。我们要感谢Siva Reddy和Arkil Patel对本文的宝贵反馈以及参与富有洞察力的讨论。我们还要感谢Mila的基础设施团队和微软研究院提供使本项目成为可能的计算资源。## 8 作者贡献KS领导了该项目,几乎完成了所有的实验和消融研究,并撰写了论文和编辑。MM负责长CoT实验并编辑了论文。AS为项目提供建议,对写作提供了反馈并编写了初始的GRPO和VinePPO代码。RA与AH一起构思了该项目,指导了KS,并对论文提供了反馈。AH和RA提出了多项想法和实验,撰写了初稿,并平等指导了该项目。AH仅担任顾问角色。## 参考文献Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 回归基础:重新审视用于从人类反馈中学习的强化学习优化方法。In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 1116, 2024, pp. 12248-12267. Association for Computational Linguistics, 2024. doi: 10.18653/ V1/2024.ACL-LONG.662. URL https://doi.org/10.18653/v1/2024.acl-long.662.Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. 公开批评奖励模型。arXiv preprint arXiv:2408.11791, 2024.Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 宪法AI:从AI反馈中实现无害性。arXiv preprint arXiv:2212.08073, 2022.Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, and Sercan Ö. Arik. SETS: 利用自验证和自校正实现改进的测试时间扩展。CoRR, abs/2501.19306, 2025a. doi: 10.48550/ARXIV.2501.19306. URL https://doi.or.
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krähenbühl. 用于长视距互动LLM代理的强化学习,2025b.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 评估训练于代码的大语言模型,2021. URL https://arxiv.org/abs/2107.03374.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 训练验证器以解决数学文字问题。arXiv preprint arXiv:2110.14168, 2021.
DeepSeek-AI. Deepseek-r1:通过强化学习激励LLM的推理能力,2025. URL https://arxiv.org/abs/2501.12948.
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 使用数学数据集衡量数学问题解决能力。arXiv preprint arXiv:2103.03874, 2021.
Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-star: 训练验证器以实现自教推理器。arXiv preprint arXiv:2402.06457, 2024.
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: 解锁LLM推理的RL潜力通过精细信用分配,2024. URL https://arxiv.org/abs/2410. 01679 .
Seungone Kim, Jamin Shin, Yejin Choi, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: 在语言模型中诱导细粒度评估能力。在The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=8euJaTveKw.
Wouter Kool, Herke van Hoof, and Max Welling. 买4个REINFORCE样本,免费获得一个基线!在DeepRLStructPred@ICLR, 2019. URL https://api.semanticscholar.org/ CorpusID:198489118.
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 让我们逐步验证。在The Twelfth International Conference on Learning Representations, 2023.
Jiacheng Liu, Andrew Cohen, Ramakanth Pasunuru, Yejin Choi, Hannaneh Hajishirzi, and Asli Celikyilmaz. 别扔掉你的价值模型!使用价值引导蒙特卡洛树搜索解码生成更优选文本。arXiv preprint arXiv:2309.15028, 2023.
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. 通过自动化过程监督改进语言模型中的数学推理。CoRR, abs/2406.06592, 2024. doi: 10.48550/ARXIV.2406.06592. URL https://doi.org/10.48550/arXiv.2406.06592.
Dakota Mahan, Duy Van Phung, Rafael Rafailov, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak. 生成奖励模型。arXiv preprint arXiv:2410.12832, 2024.
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: 简单测试时间扩展。arXiv preprint arXiv:2501.19393, 2025.
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA:研究生水平的无谷歌证明问答基准。在第一届语言建模会议,2024.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 近端策略优化算法。CoRR, abs/1707.06347, 2017. URL http://arxiv.org/ abs/1707.06347.
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 高维连续控制使用广义优势估计,2018. URL https://arxiv.org/abs/1506.02438.
Amrith Setlur, Nived Rajaraman, Sergey Levine, and Aviral Kumar. 不进行验证或RL的测试时间计算扩展是次优的,2025. URL https://arxiv.org/abs/ 2502.12118 .
Vedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, s/2407.21009.
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: 推动开放语言模型中数学推理的极限,2024. URL https://arxiv.org/abs/ 2402.03300 .el M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 学习从人类反馈总结。CoRR, abs/2009.01325, 2020. URL https://arxiv.org/abs/2009.01325.
Zhiqing Sun, Longhui Yu, Yikang Shen, Weiyang Liu, Yiming Yang, Sean Welleck, and Chuang Gan. 易到难泛化:超越人类监督的可扩展对齐,2024. URL https://arx
iv.org/abs/2403.09472.
Jonathan Uesato, Nate Kushman, Ramana Kumar, H. Francis Song, Noah Y. Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 使用过程和结果反馈解决数学文字问题。CoRR, abs/2211.14275, 2022. doi: 10.48550/ ARXIV.2211.14275. URL https://doi.org/10.48550/arXiv.2211.14275.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 自一致性改进了语言模型中的思维链推理。在第十一次国际学习表示会议,2023. URL https://openreview.net/forum?id=1PL1NIMMrw.
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math技术报告:通过自我改进迈向数学专家模型。arXiv preprint arXiv:2409.12122, 2024.
Fei Yu, Anningzhe Gao, and Benyou Wang. OVM,用于数学推理规划的结果监督价值模型。在Kevin Duh, Helena Gómez-Adorno, 和Steven Bethard(eds.), ACL 2024发现论文,墨西哥城,墨西哥,2024年6月16日至21日,第858-875页。计算语言学协会,2024. doi: 10.18653/V1/2024.FINDINGS-NAACL.55. URL https://doi.org/10.18653/ v1/2024.findings-naacl.55.
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. 无需过程标签的自由过程奖励,2024. URL https://arxiv.org/abs/2412.01981.
Weihao Zeng, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, and Junxian He. 7B模型和8K示例:出现的有效且高效的推理与强化学习。HKUST-NLP博客,2025. URL https://hkust-nlp.notion.site/ simpler1-reason. 可用网址:https://hkust-nlp.notion.site/simpler1-reason.
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. 生成验证器:将奖励建模作为下一个标记预测。arXiv预印本arXiv:2408.15240, 2024.
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 数学推理中开发过程奖励c Zhao, Pranjal Awasthi, and Sreenivas Gollapudi. 样本、审查和扩展:通过扩展验证实现有效的推理时间搜索,2025. URL https://arxiv.org/abs/2502. 01839 .
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Li模型的经验教训,2025. URL https://arxiv.org/abs/2501.07301.
EriNisan Stiennon, Long Ouyang, Jeff Wu, DaniJiatong Yu, Yinghui He, Nan Rosemary Ke, Michael Mozer, Yoshua Bengio, Sanjeev Arora, and Anirudh Goyal. AI辅助生成困难数学问题,2025. URL https://arxiv.org/abg/10. 48550/arXiv. 2501.19306n, Zhuohan Li, Dacheng Li, Eric Xing, et al. 使用MT-Bench和Chatbot Arena评估LLM-as-a-Judge。神经信息处理系统进展,36:4659546623,2023.Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang:结构化语言模型程序的有效执行,2024. URL https://arxiv.org/abs/2312.07104.# 附录 ## A 基线的测试时间计算策略类似于图5,我们在AIME’24上评估了基于Qwen2.5-Math-1.5B和R1-Distill-Qwen-1.5B的基础RL调优(无验证训练)变体,它们分别生成短和长CoTs。对于GRPO V{ }^{V}V,对应的计算最优策略为Best-of-N(图1)。对于基础RL,图9显示多数投票和加权投票显著优于Best-of- N选择。我们在图1和图6中使用GRPO的最佳表现推理策略与GRPO V{ }^{V}V进行比较,以确保公平性。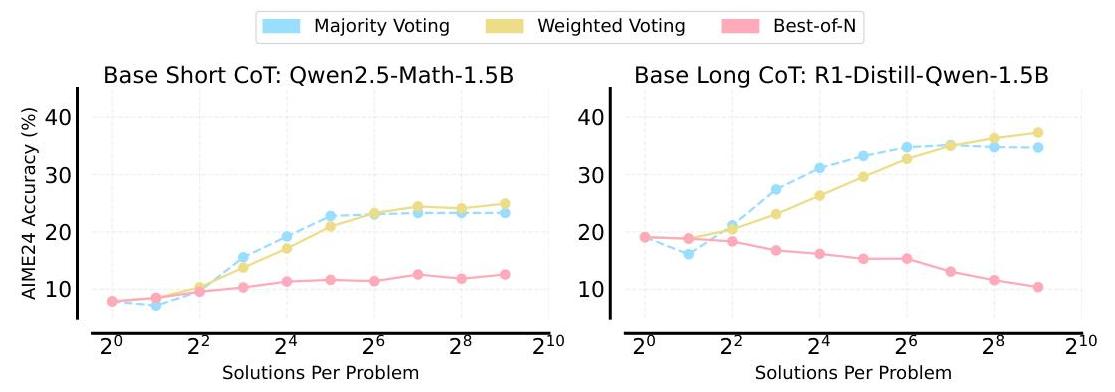 图9:基础RL(无验证训练)方法的测试时间计算策略显示出与图5不同的趋势。LLM-as-a-Judge不再提供高质量值,导致低Best-of- N得分。这里的计算最优策略对应于多数投票和加权投票。## B 推理细节预算强制 实现预算强制的方法可以描述如下:1. 定义总令牌预算,记为kkk。2. 确定缓冲令牌数量,记为bbb。3. 在推理过程中,生成最多k−bk-bk−b个令牌。4. 为了保持初始生成的同分布特性,这将作为后续生成的提示,截断生成文本到最后完成的句子。如果初始生成中没有句号(.),则保留整个生成文本。5. 添加结论令牌:KaTeX parse error: Undefined control sequence: \< at position 14: \text { ' ' }\̲<̲/ \text { think…将其附加到截断后的文本中。6. 使用此连接文本作为继续生成的提示,允许最多kkk个令牌。7. 最终响应是截断的初始生成、结论令牌和继续生成的连接。因此,令G0G_{0}G0为最多k−bk-bk−b个令牌的初始生成,T(G0)T\left(G_{0}\right)T(G0)表示截断至最后一个完整句子的G0G_{0}G0版本,或者如果没有句号,则为G0G_{0}G0本身。令CCC表示结论令牌:C=⋯< think >\n\n⋯C=\cdots<\text { think }>\backslash n \backslash n^{\cdots}C=⋯< think >\n\n⋯G1G_{1}G1是使用T(G0)⊕CT\left(G_{0}\right) \oplus CT(G0)⊕C作为提示的继续生成,其中⊕\oplus⊕表示连接。最终响应RRR由以下公式给出:R=T(G0)⊕C⊕G1R=T\left(G_{0}\right) \oplus C \oplus G_{1}R=T(G0)⊕C⊕G1其中RRR的总令牌数受初始预算kkk的约束。这种方法通过管理初始生成和后续延续,在较长生成的适当性和保留同分布特性之间取得平衡。# C 评估和指标 可靠的Best-of-N估计 为了估计平均成功率,我们执行MMM次独立试验。在每次试验中,我们从N(N>k)N(N>k)N(N>k)中抽取kkk个样本并选择最佳的一个(最高分)。最后,我们对这些选定样本的成功率取MMM次试验的平均值(Hosseini等,2024)。 Best-of- k:=1(Nk)∑i=0N−k(N−i−1k−1)αi\text { Best-of- } k:=\frac{1}{\binom{N}{k}} \sum_{i=0}^{N-k}\binom{N-i-1}{k-1} \alpha_{i} Best-of- k:=(kN)1i=0∑N−k(k−1N−i−1)αi其中[α0,α1,…,αN−1]\left[\alpha_{0}, \alpha_{1}, \ldots, \alpha_{N-1}\right][α0,α1,…,αN−1]是候选解决方案按其验证分数降序排列的二元正确性分数(0(0(0 或1)))。## D 提示## D. 1 生成数学问题的解决方案## 数学提示1 计算:$$ 1-2+3-4+5-\backslash$ dots $+99-100 $KaTeX parse error: Expected 'EOF', got '#' at position 2: 。#̲# D. 2 生成带有长思维链…$ 1-2+3-4+5-\backslash$ dots $+99-100 $。3考虑思维过程然后提供答案。45思维过程被包围在<think></think>标签内,即<think>在此处写推理过程</think>。将最终答案放在。3 考虑思维过程然后提供答案。45 思维过程被包围在<think> </think>标签内,即<think>在此处写推理过程</think>。将最终答案放在。3考虑思维过程然后提供答案。45思维过程被包围在<think></think>标签内,即<think>在此处写推理过程</think>。将最终答案放在\backslash \backslash$ boxed {}}\{\}\}{}}内。# D. 3 验证提示 ## 验证提示1 问题:2 计算:$$ 1-2+3-4+5-\backslash$ dots $+99-100 $$。34 解决方案:$5 \quad $(1-2)+(3-4)+\backslash$ dots +(97−98)+(99−100)=50(−1)=\+(97-98)+(99-100)=50(-1)=\backslash+(97−98)+(99−100)=50(−1)=\ boxed ${-50} . $$67 此解决方案是否正确?回答Yes或No。参考论文:https://arxiv.org/pdf/2505.04842
图9:基础RL(无验证训练)方法的测试时间计算策略显示出与图5不同的趋势。LLM-as-a-Judge不再提供高质量值,导致低Best-of- N得分。这里的计算最优策略对应于多数投票和加权投票。## B 推理细节预算强制 实现预算强制的方法可以描述如下:1. 定义总令牌预算,记为kkk。2. 确定缓冲令牌数量,记为bbb。3. 在推理过程中,生成最多k−bk-bk−b个令牌。4. 为了保持初始生成的同分布特性,这将作为后续生成的提示,截断生成文本到最后完成的句子。如果初始生成中没有句号(.),则保留整个生成文本。5. 添加结论令牌:KaTeX parse error: Undefined control sequence: \< at position 14: \text { ' ' }\̲<̲/ \text { think…将其附加到截断后的文本中。6. 使用此连接文本作为继续生成的提示,允许最多kkk个令牌。7. 最终响应是截断的初始生成、结论令牌和继续生成的连接。因此,令G0G_{0}G0为最多k−bk-bk−b个令牌的初始生成,T(G0)T\left(G_{0}\right)T(G0)表示截断至最后一个完整句子的G0G_{0}G0版本,或者如果没有句号,则为G0G_{0}G0本身。令CCC表示结论令牌:C=⋯< think >\n\n⋯C=\cdots<\text { think }>\backslash n \backslash n^{\cdots}C=⋯< think >\n\n⋯G1G_{1}G1是使用T(G0)⊕CT\left(G_{0}\right) \oplus CT(G0)⊕C作为提示的继续生成,其中⊕\oplus⊕表示连接。最终响应RRR由以下公式给出:R=T(G0)⊕C⊕G1R=T\left(G_{0}\right) \oplus C \oplus G_{1}R=T(G0)⊕C⊕G1其中RRR的总令牌数受初始预算kkk的约束。这种方法通过管理初始生成和后续延续,在较长生成的适当性和保留同分布特性之间取得平衡。# C 评估和指标 可靠的Best-of-N估计 为了估计平均成功率,我们执行MMM次独立试验。在每次试验中,我们从N(N>k)N(N>k)N(N>k)中抽取kkk个样本并选择最佳的一个(最高分)。最后,我们对这些选定样本的成功率取MMM次试验的平均值(Hosseini等,2024)。 Best-of- k:=1(Nk)∑i=0N−k(N−i−1k−1)αi\text { Best-of- } k:=\frac{1}{\binom{N}{k}} \sum_{i=0}^{N-k}\binom{N-i-1}{k-1} \alpha_{i} Best-of- k:=(kN)1i=0∑N−k(k−1N−i−1)αi其中[α0,α1,…,αN−1]\left[\alpha_{0}, \alpha_{1}, \ldots, \alpha_{N-1}\right][α0,α1,…,αN−1]是候选解决方案按其验证分数降序排列的二元正确性分数(0(0(0 或1)))。## D 提示## D. 1 生成数学问题的解决方案## 数学提示1 计算:$$ 1-2+3-4+5-\backslash$ dots $+99-100 $KaTeX parse error: Expected 'EOF', got '#' at position 2: 。#̲# D. 2 生成带有长思维链…$ 1-2+3-4+5-\backslash$ dots $+99-100 $。3考虑思维过程然后提供答案。45思维过程被包围在<think></think>标签内,即<think>在此处写推理过程</think>。将最终答案放在。3 考虑思维过程然后提供答案。45 思维过程被包围在<think> </think>标签内,即<think>在此处写推理过程</think>。将最终答案放在。3考虑思维过程然后提供答案。45思维过程被包围在<think></think>标签内,即<think>在此处写推理过程</think>。将最终答案放在\backslash \backslash$ boxed {}}\{\}\}{}}内。# D. 3 验证提示 ## 验证提示1 问题:2 计算:$$ 1-2+3-4+5-\backslash$ dots $+99-100 $$。34 解决方案:$5 \quad $(1-2)+(3-4)+\backslash$ dots +(97−98)+(99−100)=50(−1)=\+(97-98)+(99-100)=50(-1)=\backslash+(97−98)+(99−100)=50(−1)=\ boxed ${-50} . $$67 此解决方案是否正确?回答Yes或No。参考论文:https://arxiv.org/pdf/2505.04842

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)