强化学习之Policy Gradient
1.什么是策略梯度
1.1.策略梯度是属于强化学习的一种算法,他是Q-learning和DQN的改进,强化学习是通过奖惩来不断学习的机制,有学习奖惩的值,有根据价值选行为的Q-learning和DQN,也有不通过奖励值直接输出动作的概率Policy Gradients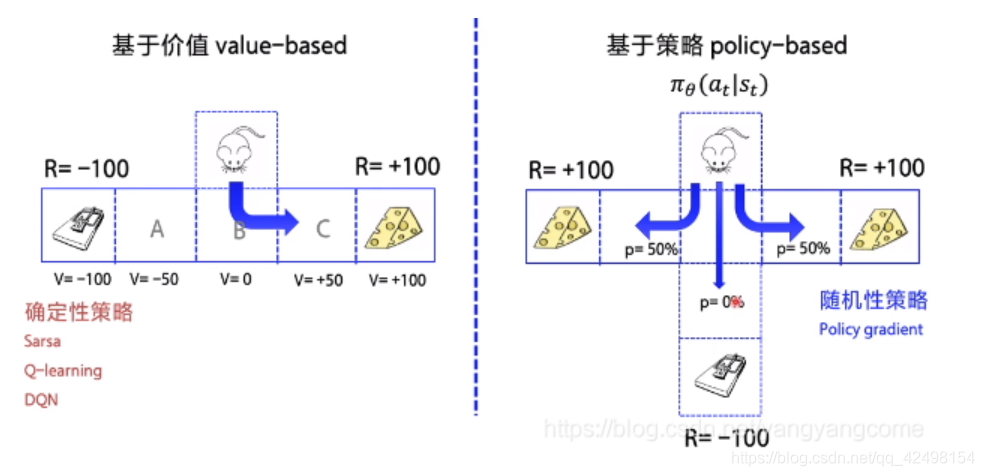
1.2.Policy Gradient好处:
2.Policy Gradient算法
2.1.environment是一个function,function吐出一个s1,actor看到游戏画面以后吐出a1,environment把a1当成他的输入再吐出s2,s2出现新的游戏画面再决定新的行为a2·····
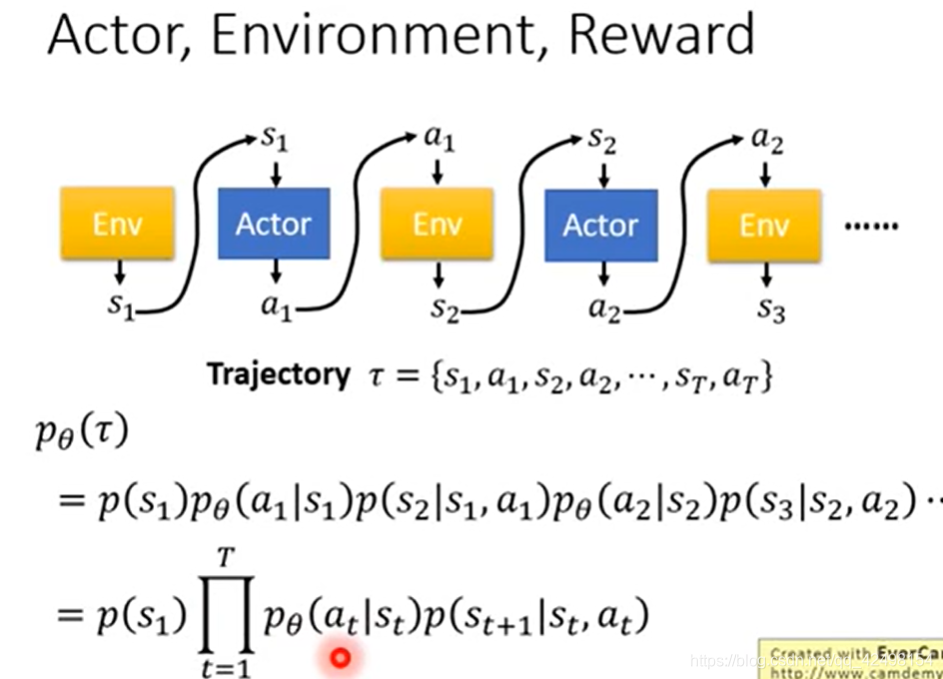
2.2.需要做的就是调整内部的参数使得奖励值的总和R最大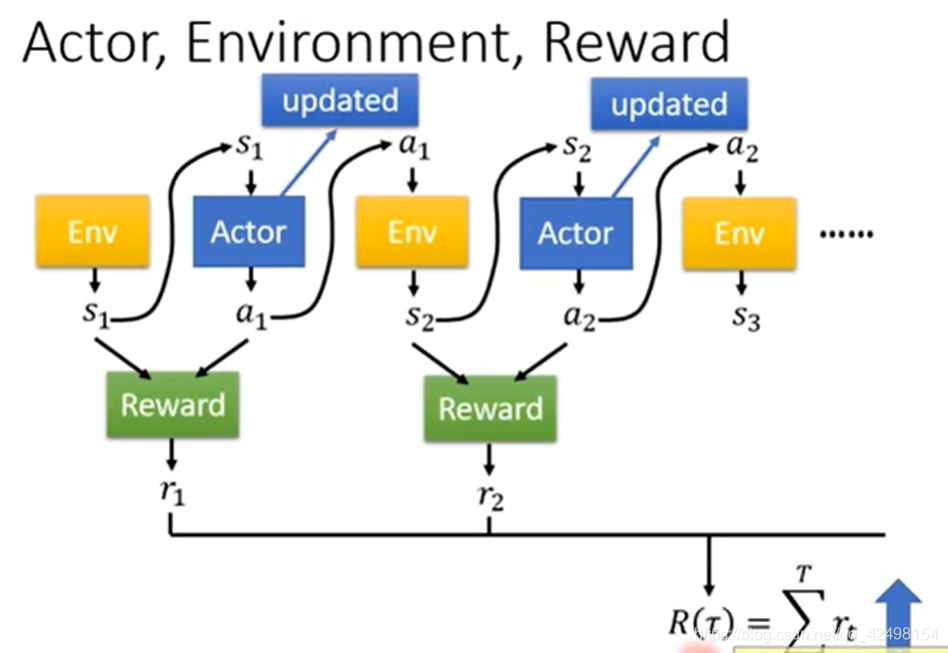
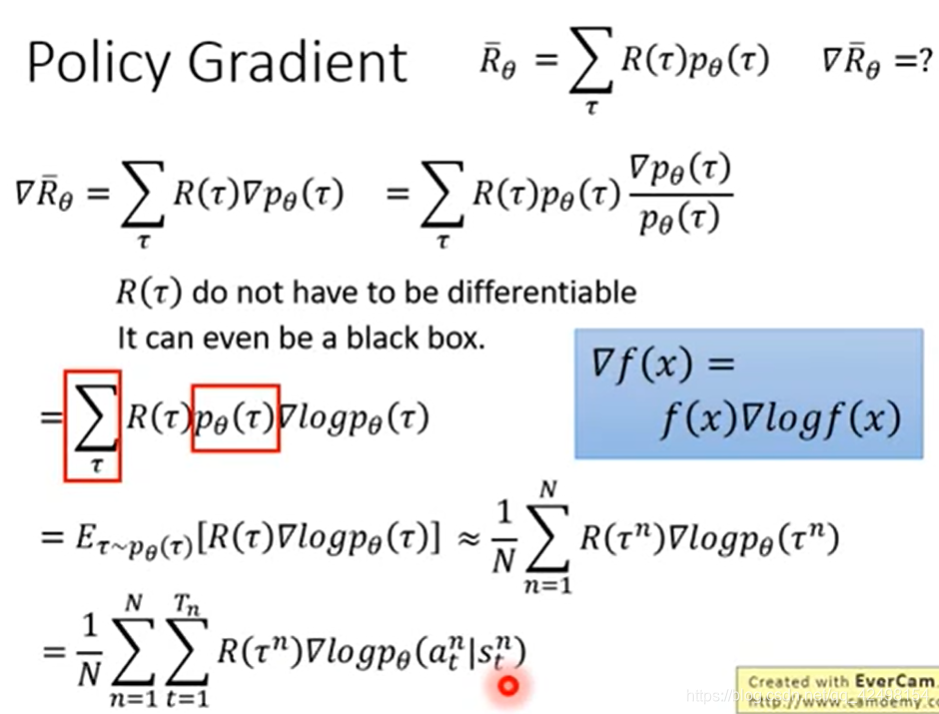
2.3.Expected Reward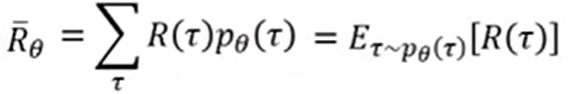
2.4.如何计算Expected Reward
3.Policy Gradient思维决策
3.1.整个过程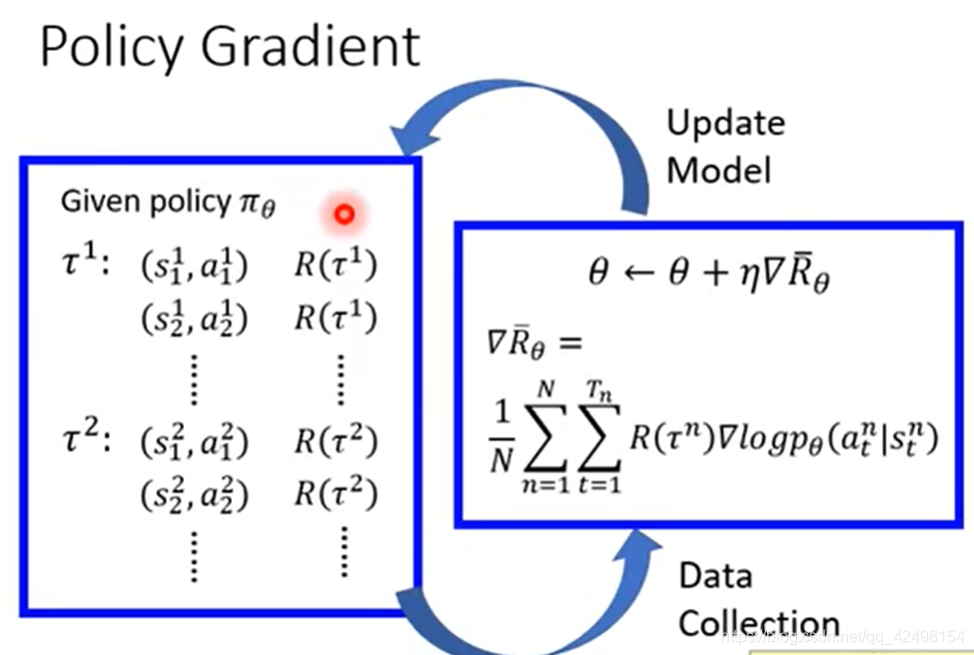
3.2.实际操作会遇到的细节
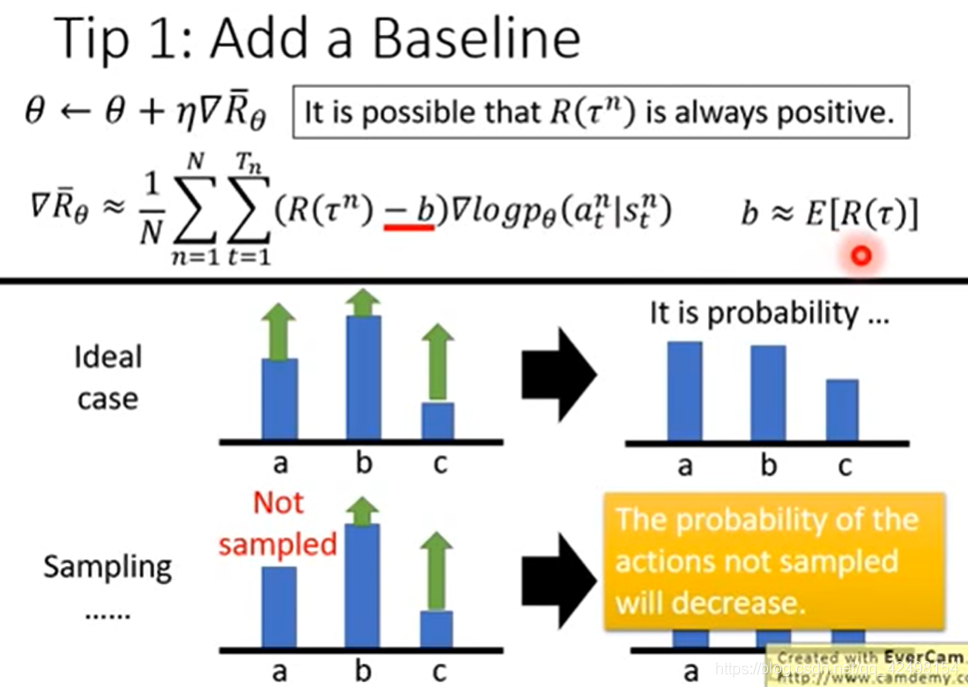
3.2.1希望reward不要总是正的,就需要设置一个基准baseline(b),这样可以降低方差,让其收敛更快,b是任意的数,但是不能依赖状态。b不会影响期望,但是会影响蒙特卡罗近似,如果选的b比较好,比较靠近Q(S,A),会让蒙特卡罗近似降低,收敛更快。
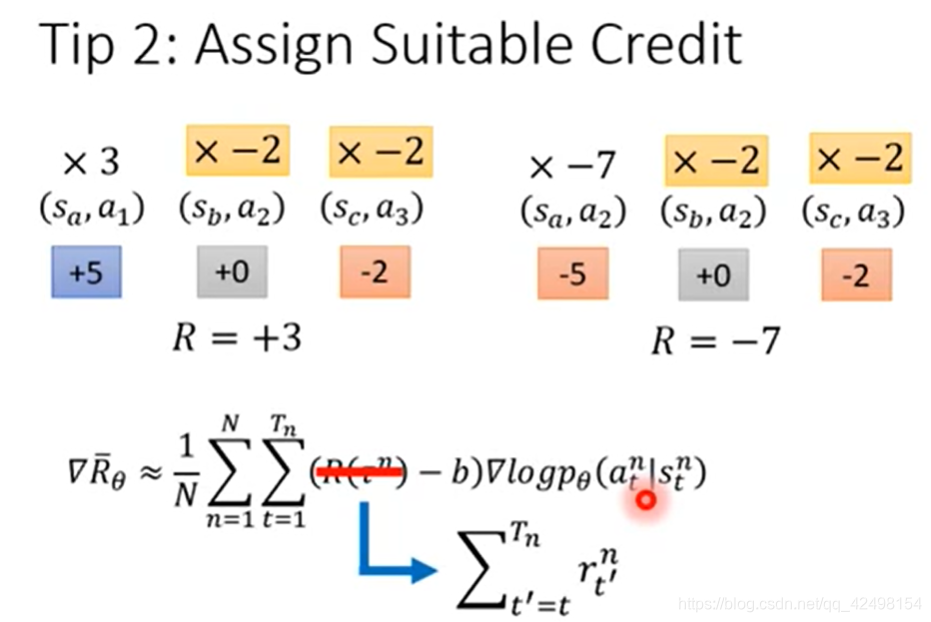
3.2.2给每一个action合适的credit,整场游戏是好的,不代表每一个action都是好的,整场游戏是坏的,不代表每一个action都是坏的。
4.policy gradient流程

vt表示是好的还是不好的,表示的是这次的分数有多高。logΠθ表示更新的方向。log的收敛性会好点。
如果vt是好的,那么参数更新幅度大一点,下一次选中的概率大一点
如果vt是坏的,那么参数更新幅度小一点,下一次选中的概率小一点

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)