强化学习基础
Reinforcement Learning1、概率论知识Random VariableRandom variable:随机变量是一个未知的量,它的值取决于一个随机事件的结果。使用大写的X表示其值。使用小写字母x来表示随机变量的观测值,小x只是一个数而已没有随机性。Probability Density Function(PDF, 概率密度函数)概率密度函数的物理意义是,随机变量在某个确定的取值点
Reinforcement Learning
1、概率论知识
Random Variable
- Random variable:随机变量是一个未知的量,它的值取决于一个随机事件的结果。使用大写的X表示其值。
- 使用小写字母x来表示随机变量的观测值,小x只是一个数而已没有随机性。
Probability Density Function(PDF, 概率密度函数)
- 概率密度函数的物理意义是,随机变量在某个确定的取值点附近的可能性
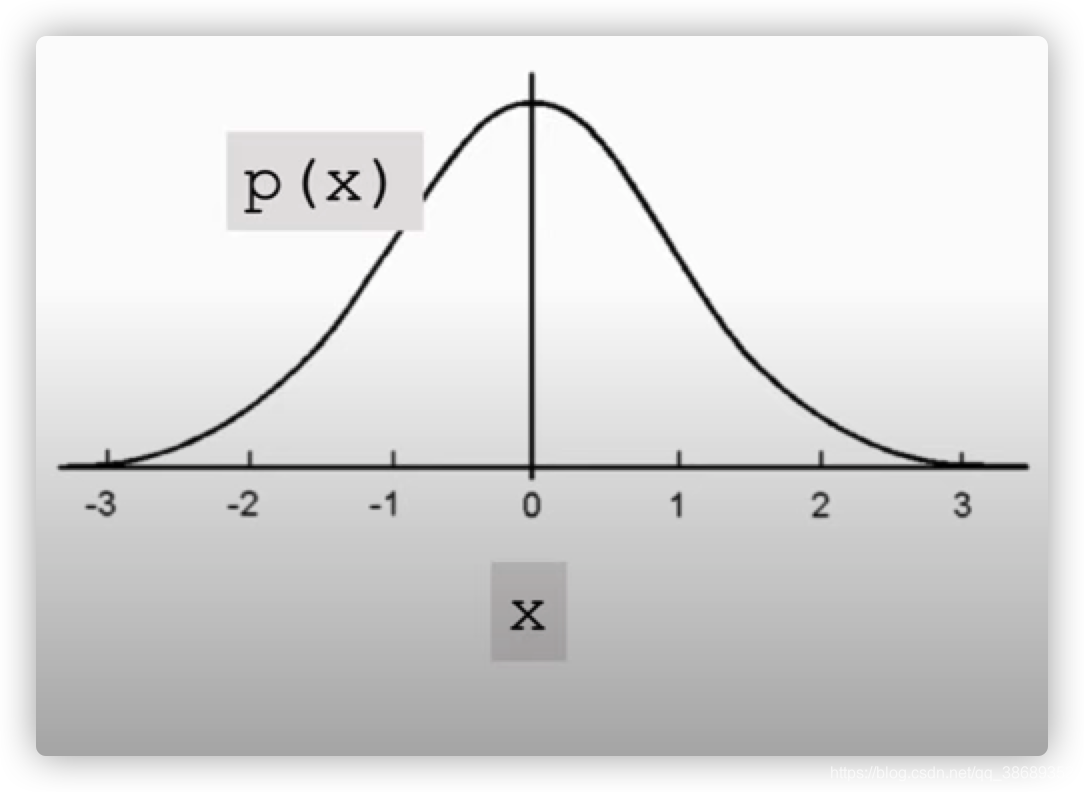
- 比如:高斯分布
- 是一个连续的分布
- PDF:p(x)=12πσ2exp(−(x−μ)22σ2)p(x)=\frac{1}{\sqrt{2 \pi \sigma^2}}exp(-\frac{(x-\mu)^2}{2\sigma ^2})p(x)=2πσ21exp(−2σ2(x−μ)2) ,这里σ\sigmaσ是标准差,μ\muμ是均值
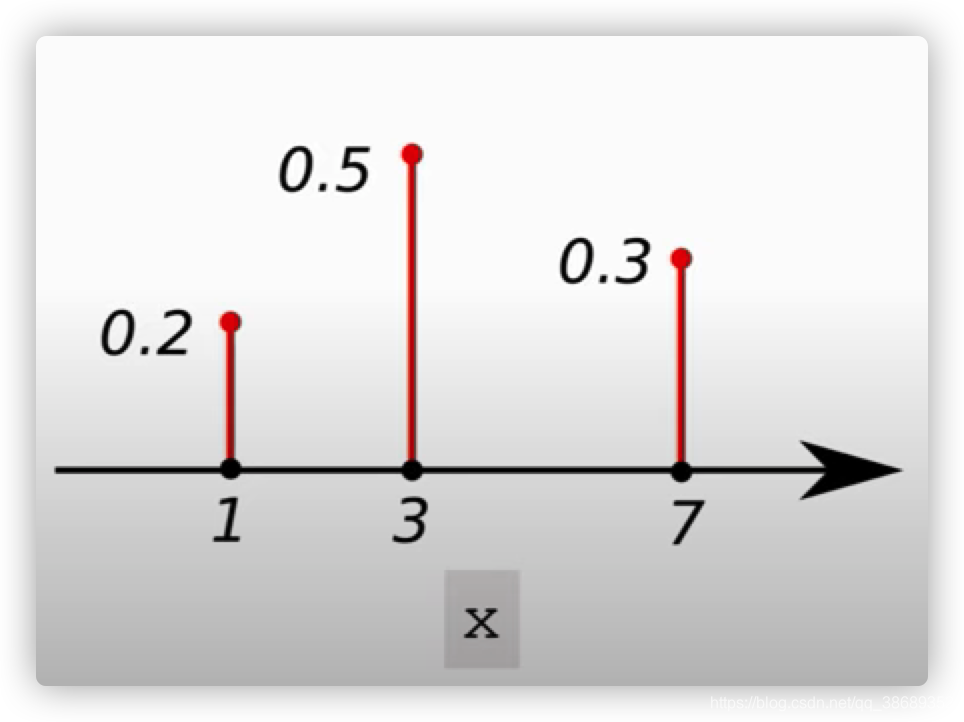
- 比如:离散概率分布
- 离散随机变量:X∈{1,3,7}X \in \{1, 3, 7\}X∈{1,3,7}
- PDF: p(1)=0.2,p(2)=0.5,p(7)=0.3p(1) = 0.2, p(2)=0.5, p(7)=0.3p(1)=0.2,p(2)=0.5,p(7)=0.3
- 概率密度函数的性质:
- 如果随机变量X的定义域为X\mathcal{X}X
- 对于连续的分布来说:∫Xp(x)dx=1\int _{\mathcal{X}}p(x)dx = 1∫Xp(x)dx=1
- 对于离散的分布来说:Σx∈Xp(x)=1\Sigma _{x\in \mathcal{X}}p(x) = 1Σx∈Xp(x)=1
Expectation(期望)
- 随机变量X的定义域是X\mathcal{X}X
- 对于连续分布,函数f(X)f(X)f(X)的期望是E[f(X)]=∫Xp(x)⋅f(x)dx\mathbb{E}[f(X)]=\int_{\mathcal{X}}p(x)\cdot f(x)dxE[f(X)]=∫Xp(x)⋅f(x)dx ,这里的p(x)p(x)p(x)是概率密度函数
- 对于离散分布,函数f(X)f(X)f(X)的期望是E[f(X)]=Σx∈Xp(x)⋅f(x)\mathbb{E}[f(X)]=\Sigma _{x\in \mathcal{X}}p(x)\cdot f(x)E[f(X)]=Σx∈Xp(x)⋅f(x)
Random Sampling(随机抽样)
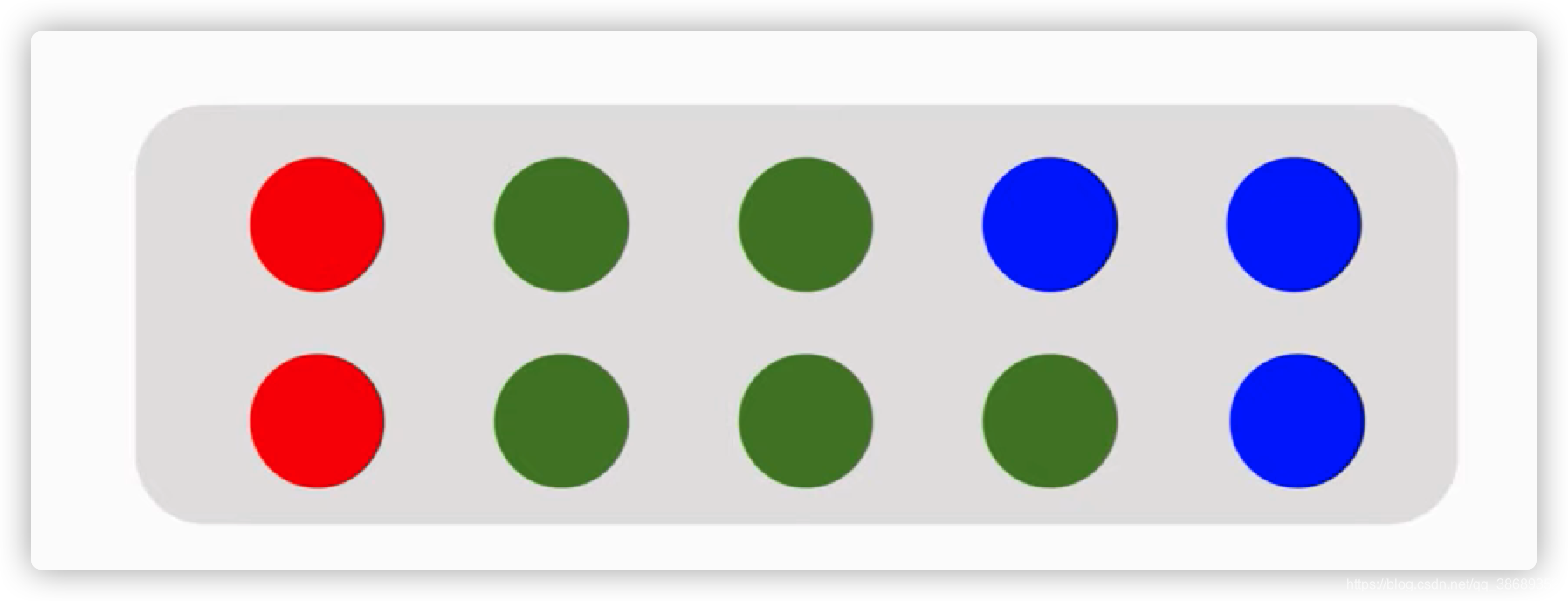
- 假设盒子里有十个球:2个红球,5个绿球,3个蓝球
- 随机抽取一个球
- 这个球是什么颜色呢?
- 这里的随机变量就是X,X有三种可能:红色、绿色、蓝色。 当我们真的拿出一个球,看到一个颜色后,我们就完成了一次随机抽样。
2、强化学习的名词
-
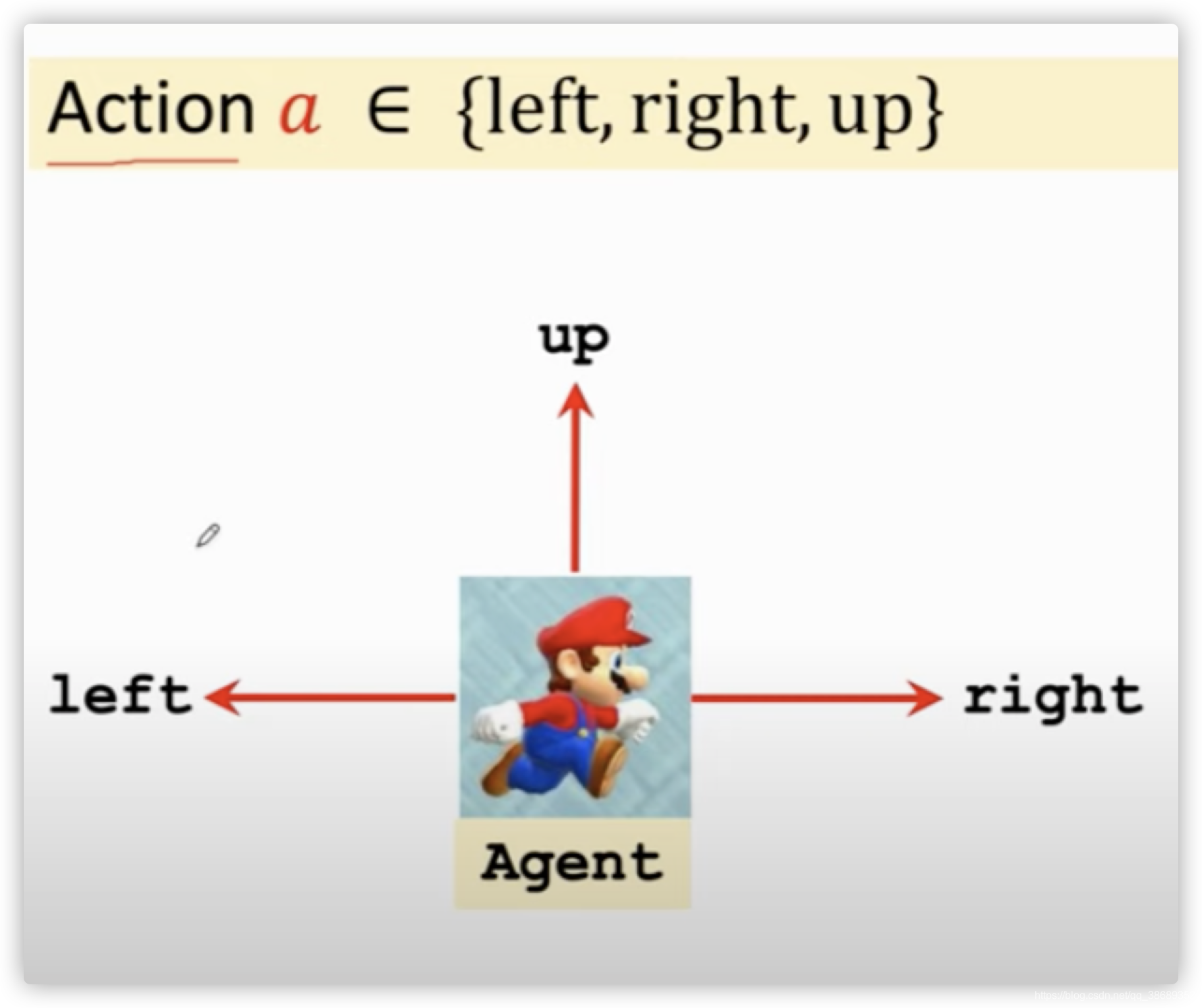
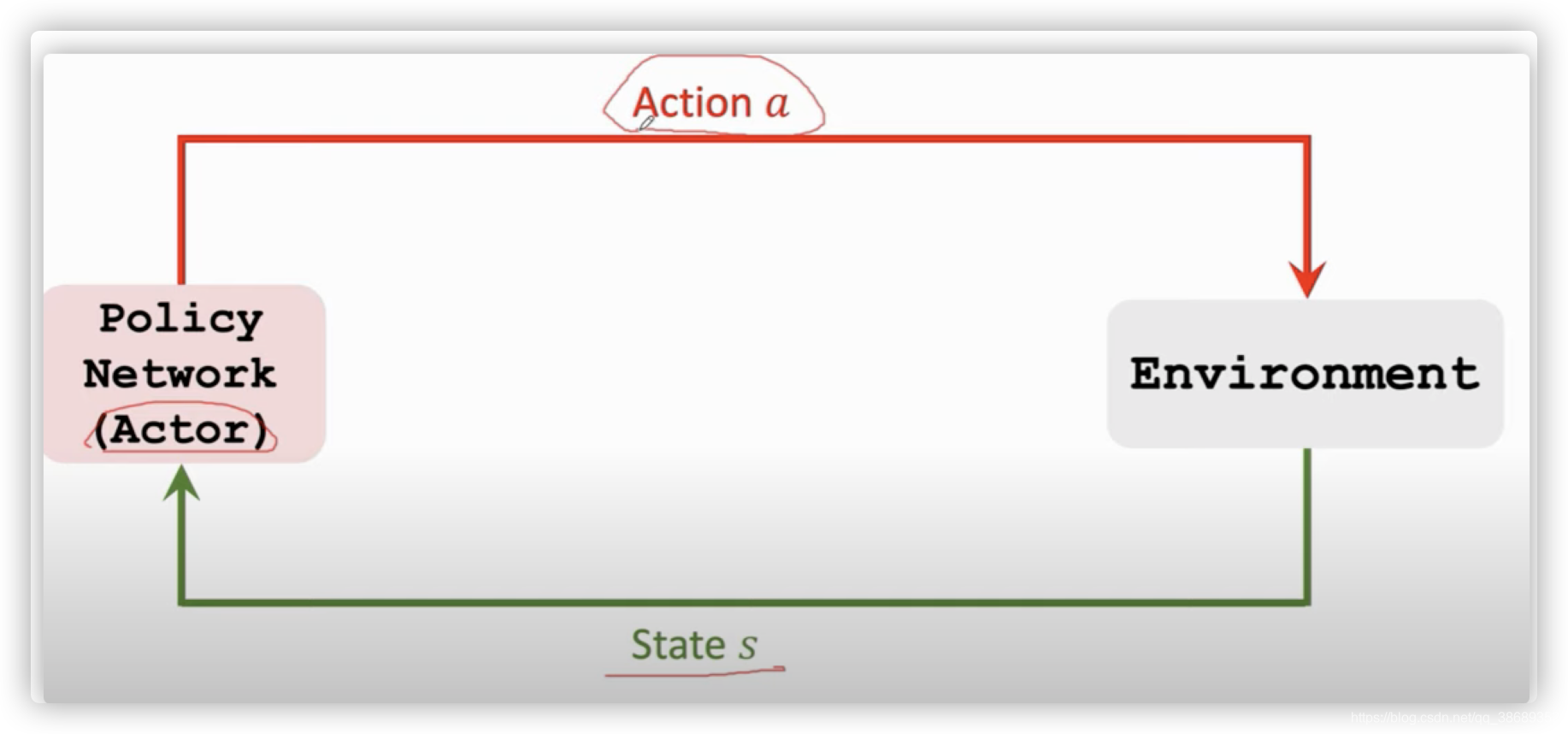
state:状态。状态的意思就是,假设我们在玩超级玛丽游戏,状态就是当前的画面。
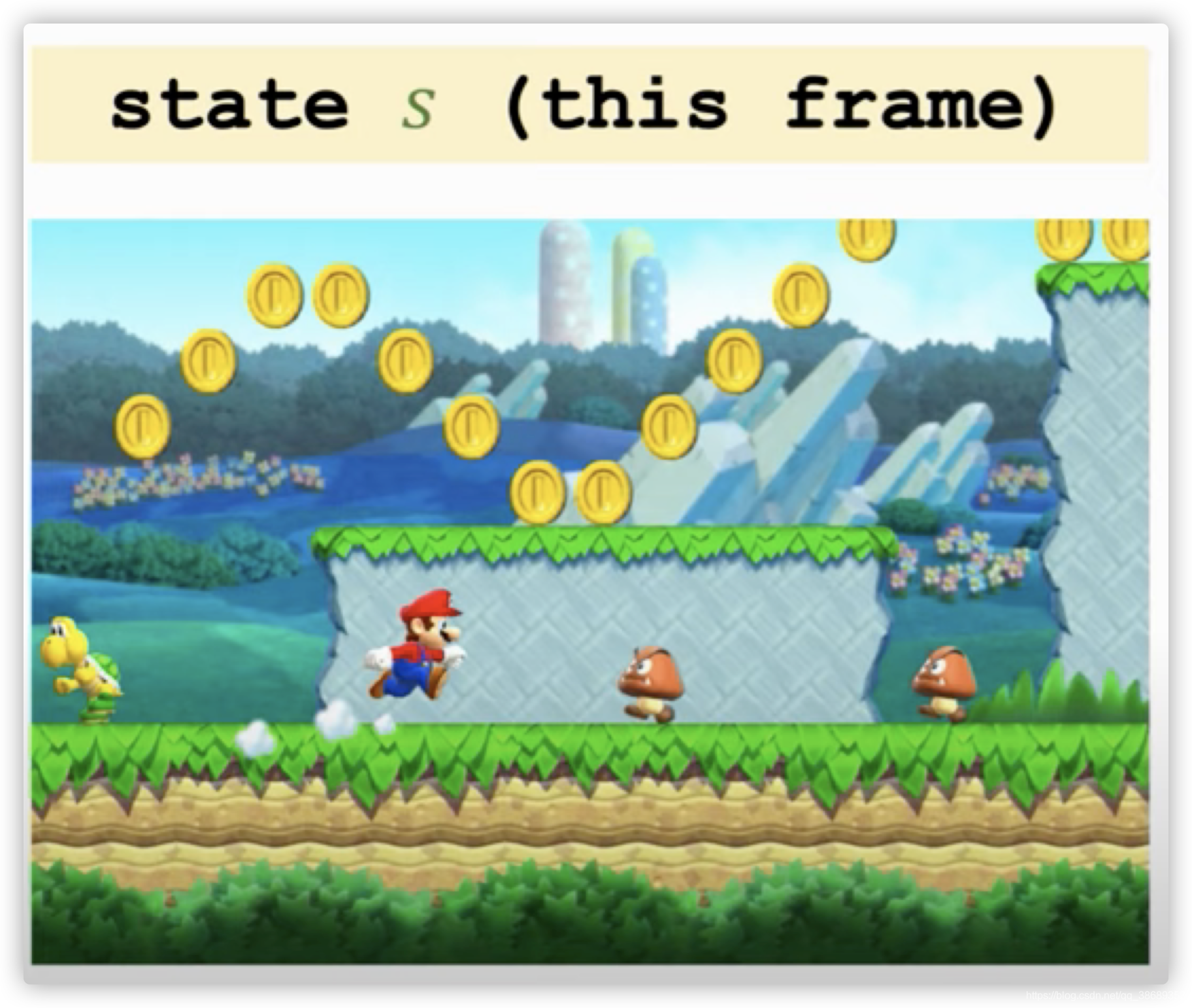
-
action:动作。当我们观测到当前的状态的时候,我们就可以操作人物,进行移动。
-
Agent:在上述例子中,马里奥就是Agent,也就是说在一个例子中动作是由谁做的谁就是Agent
-
policy:策略。记为:π\piπ 。policy的意思就是根据观测到的状态来做出决策,来控制Agent运动。
- 在数学上π\piπ函数的定义
- π:(s,a)→[0,1]\pi :(s, a) \rightarrow [0, 1]π:(s,a)→[0,1]: π(a∣s)=p(A=a∣S=s)\pi (a|s)=\mathbb{p}(A=a|S=s)π(a∣s)=p(A=a∣S=s). π\piπ就是一个概率密度函数,这里是给定状态s,做出动作a的概率密度。
- 强化学习就是在学policy函数
- 在数学上π\piπ函数的定义
-
Reward:奖励。Agent做出一个动作游戏就会给出一个奖励。这个奖励需要我们自己定义奖励。比如:马里奥吃到一个金币奖励为+1,赢得了游戏奖励就是+10000,我们应该将打赢游戏的奖励定义的大一些,这样才能更好的去打赢游戏,而不是一味的吃金币。当马里奥碰到了敌人,马里奥就死了,奖励就是-10000。如果这一步啥也没发生就是奖励为0. 强化学习的目标就是获得的奖励尽量要高。

-
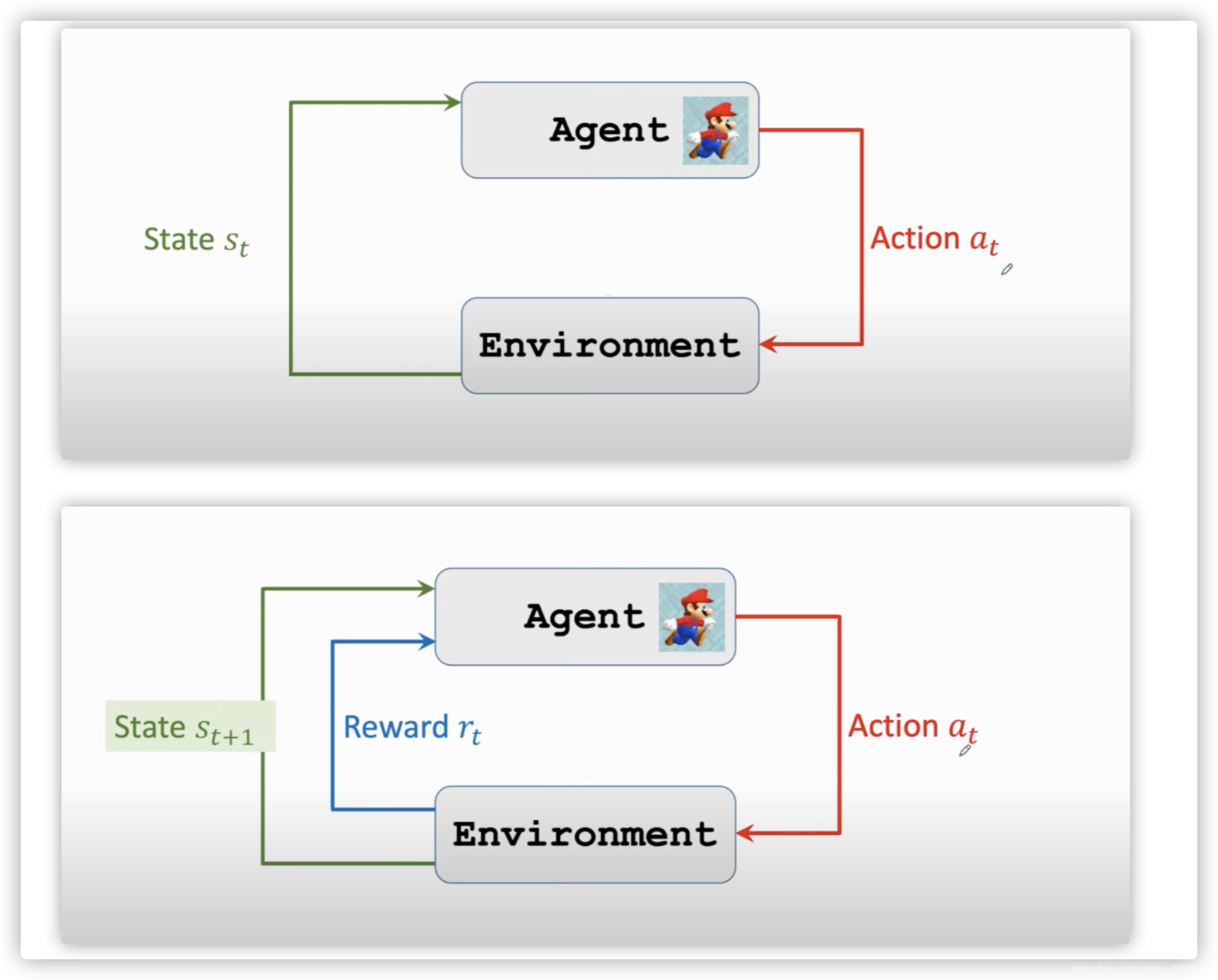
state transition:状态转移。当前状态下马里奥做一个动作游戏就会给出一个新的状态。这个过程就是状态转移,这个过程可以是确定的,也可以是随机的。通常我们认为状态转移是随机的。这里的随机性是从环境里来的。在这里环境就是游戏的程序,游戏的程序决定下一个状态是什么。
- 可以将状态转移用p函数来表示,这是一个条件概率密度函数。 意思是如果观测到当前的状态s,以及动作a,p函数输出状态变为s′s^{'}s′的概率。
- p(s′∣s,a)=P(S′=s′∣S=s,A=a)p(s^{'}|s, a)=\mathbb{P}(S^{'}=s^{'}|S=s, A=a)p(s′∣s,a)=P(S′=s′∣S=s,A=a)
- 可以将状态转移用p函数来表示,这是一个条件概率密度函数。 意思是如果观测到当前的状态s,以及动作a,p函数输出状态变为s′s^{'}s′的概率。
-
Agent environment interaction:Agent和环境之间的交互。这里环境是游戏程序,agent是马里奥,状态sts_tst是游戏告诉我们的。在超级玛丽的例子中我们可以把当前屏幕上的图片看作是状态sts_tst,agent在看到一个状态sts_tst之后要做出一个动作ata_tat,agent做出动作之后环境会更新状态,把状态变为st+1s_{t+1}st+1 同时环境给agent一个奖励。
3、Randomness in Reinforcement Learning:强化学习中的随机性
- 一个随机性的来源是agent的动作来的,因为agent是根据policy函数随机抽样来的,我们用policy函数来控制agent

- 另一个随机性的来源是状态转移,假设agent做出了向上跳的动作,环境就要生成下一个状态s′s^{'}s′ ,环境用状态转移函数p酸楚概率,然后用概率来随机抽样来得到下一个状态s′s^{'}s′。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OC5x91bQ-1628323922389)(/Users/tiger/Library/Application Support/typora-user-images/image-20210803110847320.png)]](https://i-blog.csdnimg.cn/blog_migrate/b265cc22b01ac2a42abf914e2cfbaba0.png)
4、play the game using AI
- 怎么用AI来打赢游戏呢?我们通过强化学习学出了policy函数π\piπ ,AI通过policy函数来控制Agent
- 观测到游戏当前状态s1s_1s1
- AI用policy函数来算出一个概率,然后随机抽样得到一个动作a1a_1a1
- 环境生成下一个状态s2s_2s2,并且给agent一个奖励r1r_1r1
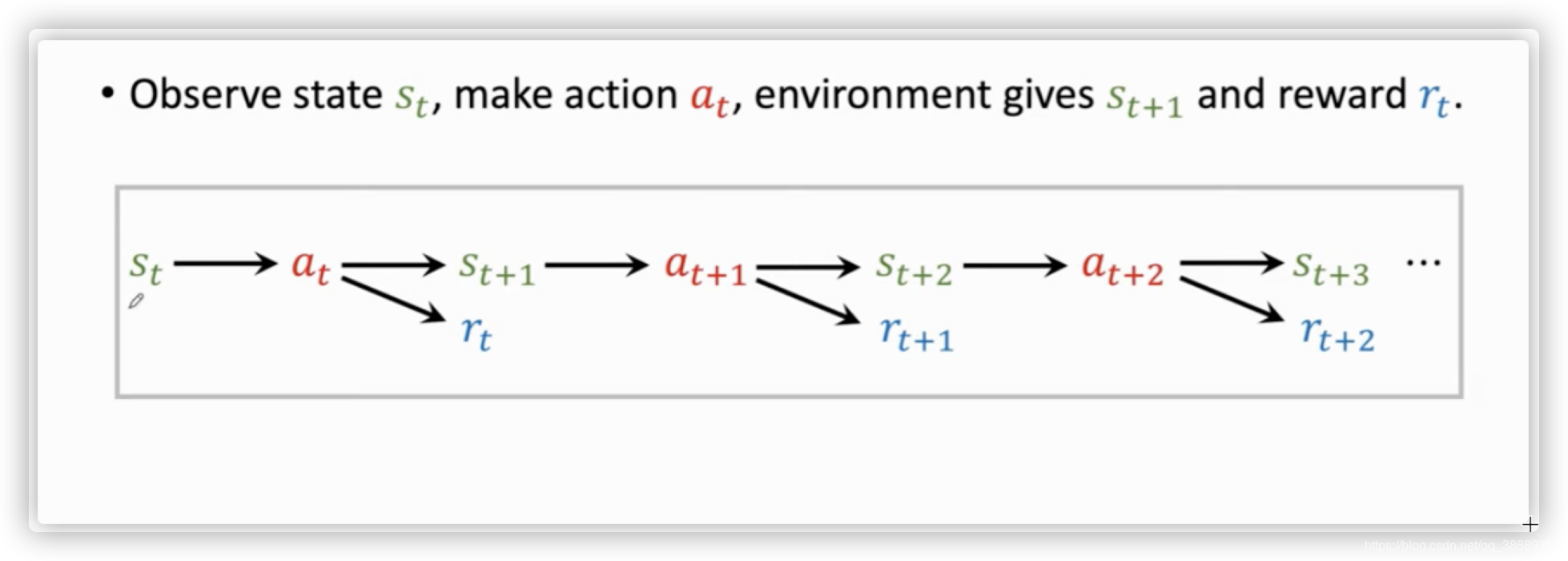
- 然后AI就会拿新的状态作为输入,一直循环上述步骤,直到打赢游戏或game over
- 这样我们就是得到一个游戏的trajectory(轨迹):s1,a1,r1,s2,a2,r2,...,sT,aT,rTs_1,a_1,r_1,s_2,a_2,r_2,...,s_T,a_T,r_Ts1,a1,r1,s2,a2,r2,...,sT,aT,rT
5、Rewards and Returns and Value Function
- Return:翻译为回报。另一个名字为cululative future reward(未来的累积奖励)
- 我们将t时刻的return记作UtU_tUt,Ut=Rt+Rt+1+Rt+2+⋯U_t = R_t+R_{t+1}+R_{t+2}+\cdotsUt=Rt+Rt+1+Rt+2+⋯。就是将从t时刻开始的奖励全都加起来
- 问题:RtR_tRt和Rt+1R_{t+1}Rt+1同样重要嘛?
- 未来奖励不如现在的奖励好,这样我们就要给未来的奖励打一个折扣。也就是说未来的奖励的权重要比现在奖励的权重低才可以
- Discounted:折扣因子。(计算未来的折扣奖励)。折扣率被记为:γ\gammaγ。它要介于0-1之间。
- 这样我们将t时刻的return记为Ut=Rt+γRt+1+γ2Rt+2+⋯U_t=R_t + \gamma R_{t+1} + \gamma ^2 R_{t+2}+\cdotsUt=Rt+γRt+1+γ2Rt+2+⋯
- Randomness in Returns:Return的随机性。假设游戏都结束了所有的奖励都观测到了,那么奖励就都是数值用小写字母表示。假设在t时刻游戏还没有结束,这些奖励还都是随机变量没有被观测到,我们就用大写字母来表示。因为Return U依赖于奖励R,所以也用大写字母表示。
- 随机性有两个来源
- 动作A
- 下一个状态
- 对于任意的的时刻i≥ti \geq ti≥t,奖励RiR_iRi取决于SiS_iSi和AiA_iAi
- 前面我们根据return的定义可知,return是未来每个时刻的奖励的加权和,每一个奖励RiR_iRi取决于SiS_iSi和AiA_iAi ,这样UtU_tUt就和未来所有的状态和动作都有关。假设我们观察到状态sts_tst,那么return UtU_tUt就取决于随机变量:At,At+1,At+2,⋯A_t,A_{t+1},A_{t+2},\cdotsAt,At+1,At+2,⋯和st+1,st+2,⋯s_{t+1},s_{t+2},\cdotsst+1,st+2,⋯
- 随机性有两个来源
- Value Functions:
- Action-Value Function A(s,a)A(s,a)A(s,a) :定义策略π\piπ的动作价值函数。Qπ(st,at)=E[Ut∣St=st,At=at]Q_{\pi }(s_t, a_t)=\mathbb{E}[U_t|S_t=s_t, A_t=a_t]Qπ(st,at)=E[Ut∣St=st,At=at] 。Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)与当前的动作ata_tat和状态sts_tst有关,还与policy函数$\pi 有关。动作价值函数的直观意义就是如果用policy函数有关。动作价值函数的直观意义就是如果用policy函数有关。动作价值函数的直观意义就是如果用policy函数\pi在在在s_t状态下,做动作状态下,做动作状态下,做动作a_t这个动作是好还是坏。这样已知Policy函数这个动作是好还是坏。这样已知Policy函数这个动作是好还是坏。这样已知Policy函数\pi,,,Q_{\pi}$就会给当前的状态下所有的动作a打分,这样我们就知道动作的好坏了。
- 上面我们知道UtU_tUt是个随机变量它依赖于未来的所有动作和状态,所以在t时刻我们并不知道UtU_tUt是什么,这时候我们可以对UtU_tUt求期望来评估当前的形势,把里面的随机性都用积分给积掉,得到的就是一个数,记为:QπQ_{\pi}Qπ。
- 这个期望怎么求呢?我们将UtU_tUt当作未来的所有状态和动作的一个函数,未来的动作a和状态s都具有随机性。动作a的概率密度函数是Policy函数$\pi ,也就是,也就是,也就是\mathbb{P}[A=a|S=s]=\pi(a|s),动作s的概率密度函数是状态转移函数p:,动作s的概率密度函数是状态转移函数p:,动作s的概率密度函数是状态转移函数p:\mathbb{P}[S{’}=s{’}|S=s, A=a]=p(s^{’}|s,a),期望就是对未来的动作a和状态s求导,把这些随机变量都用积分积掉,除了,期望就是对未来的动作a和状态s求导,把这些随机变量都用积分积掉,除了,期望就是对未来的动作a和状态s求导,把这些随机变量都用积分积掉,除了s_t和和和a_t$其余的随机变量都被积掉了。
- Optimal action-value funtion:上面我们知道动作价值函数Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)与policy函数π\piπ有关,不同的π\piπ就会有不同的动作价值函数Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at),那么我们怎么样将动作价值函数Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)当中的π\piπ去掉呢?我们可以对于Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)关于π\piπ求最大化,记为:Q∗(st,at)=maxπQπ(st,at)Q^*(s_t,a_t)=\underset{\pi }{max}Q_{\pi }(s_t, a_t)Q∗(st,at)=πmaxQπ(st,at)。意思就是我们虽然有无数种policy函数π\piπ,但是我们要用最好的那个。最好的policy函数就是让Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)最大化的π\piπ,这样我们就得到了函数Q∗Q^*Q∗,称之为optimal action-value function。Q∗(st,at)Q^*(s_t,a_t)Q∗(st,at)与policy函数π\piπ无关,因为经过之前的步骤π\piπ已经被去掉了。Q∗(st,at)Q^*(s_t,a_t)Q∗(st,at)函数的直观意义就是:可以用它对动作aaa做评价,比如当前的状态是sts_tst,Q∗(st,at)Q^*(s_t,a_t)Q∗(st,at)可以告诉我们当前的动作ata_tat好不好。这样agent就可以根据Q∗(st,at)Q^*(s_t,a_t)Q∗(st,at)这个函数来做决策了。
- State-value funtion:状态价值函数Vπ(st)V_{\pi}(s_t)Vπ(st)。Vπ=EA[Qπ(st,A)]V_{\pi}=\mathbb{E}_A[Q_{\pi}(s_t,A)]Vπ=EA[Qπ(st,A)] ,把这里的动作A作为随机变量,然后关于A求期望把A消掉,这样得到的Vπ(st)V_{\pi}(s_t)Vπ(st)只和π\piπ和s有关,Vπ(st)V_{\pi}(s_t)Vπ(st)的直观的意义:告诉我们当前的局势好不好。比如:下围棋,用Vπ(st)V_{\pi}(s_t)Vπ(st)看一下,就可以告诉我们的当前是要赢了,还是要输了,还是不分高下。
- Vπ=EA[Qπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)V_{\pi}=\mathbb{E}_A[Q_{\pi}(s_t,A)]=\Sigma _a \pi(a|s_t)\cdot Q_{\pi}(s_t,a)Vπ=EA[Qπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)。这里的期望是根据随机变量A求的,A的概率密度函数是π(at∣st)\pi(a_t|s_t)π(at∣st)。根据期望的定义可以把期望写成连加或者积分的形势,对于离散的动作action可以写为连加的形式。
- Vπ=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a)daV_{\pi}=\mathbb{E}_A[Q_{\pi}(s_t,A)]=\int \pi(a|s_t)\cdot Q_{\pi}(s_t,a)daVπ=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a)da这里是对于连续的动作action,求积分。
- 如果π\piπ是固定的,那么状态s越好,Vπ(s)V_{\pi}(s)Vπ(s)的数值越大。
- Vπ(s)V_{\pi}(s)Vπ(s)还可以平均当前的policy函数π\piπ的好坏,如果π\piπ越好那么Vπ(s)V_{\pi}(s)Vπ(s)的平均值ES[Vπ(S)]\mathbb{E}_S [V_{\pi}(S)]ES[Vπ(S)]就越大
- Action-Value Function A(s,a)A(s,a)A(s,a) :定义策略π\piπ的动作价值函数。Qπ(st,at)=E[Ut∣St=st,At=at]Q_{\pi }(s_t, a_t)=\mathbb{E}[U_t|S_t=s_t, A_t=a_t]Qπ(st,at)=E[Ut∣St=st,At=at] 。Qπ(st,at)Q_{\pi }(s_t,a_t)Qπ(st,at)与当前的动作ata_tat和状态sts_tst有关,还与policy函数$\pi 有关。动作价值函数的直观意义就是如果用policy函数有关。动作价值函数的直观意义就是如果用policy函数有关。动作价值函数的直观意义就是如果用policy函数\pi在在在s_t状态下,做动作状态下,做动作状态下,做动作a_t这个动作是好还是坏。这样已知Policy函数这个动作是好还是坏。这样已知Policy函数这个动作是好还是坏。这样已知Policy函数\pi,,,Q_{\pi}$就会给当前的状态下所有的动作a打分,这样我们就知道动作的好坏了。
6、Play games using reinforcement learning
How does AI control the agent?
- 如果我们玩超级玛丽游戏,我们的目标就是操作马里奥多吃金币,往前走,打赢每一关游戏。
- 我们写个程序让AI来控制agent。
- 一种方法是学习一个policy函数π\piπ ,这种方法在RL中称之为Policy-based learning,策略学习。这样我们就可以得到一个policy函数π\piπ,我可以用policy函数来控制agent来做动作。
- 每当我们观测到一个状态sts_tst时,我们就将这个sts_tst作为π\piπ函数的输入,π\piπ函数就会输出每个动作的概率,然后就根据这个概率来做一个随机抽样得到一个动作ata_tat,AI就通过这种方式来控制agent做动作打游戏。
- 另一种方式是学习optimal action-value functionQ∗(s,a)Q^*(s,a)Q∗(s,a),这在RL中称为Value-based learning。如果我们有了Q∗(s,a)Q^*(s,a)Q∗(s,a),agent可以根据Q∗(s,a)Q^*(s,a)Q∗(s,a)来做动作,Q∗(s,a)Q^*(s,a)Q∗(s,a)函数告诉我们如果处在状态s,做动作a是好还是坏。每观测到一个状态sts_tst,就将其作为Q∗(s,a)Q^*(s,a)Q∗(s,a)函数的输入,让Q∗(s,a)Q^*(s,a)Q∗(s,a)函数对每一个动作做一个评价,这样我们就知道每一个动作的Q值,这样我们就可以选择Q值最大的动作进行操作,因为Q值是对未来所有奖励的总和的期望。用数学公式表示为:at=argmaxaQ∗(st,a)a_t = argmax_aQ^*(s_t,a)at=argmaxaQ∗(st,a).
- 一种方法是学习一个policy函数π\piπ ,这种方法在RL中称之为Policy-based learning,策略学习。这样我们就可以得到一个policy函数π\piπ,我可以用policy函数来控制agent来做动作。
7、强化学习的流程
8、Value-Based Reinforcement Learning
Deep Q-Network(DQN)
- DQN其实就是使用一个神经网络来近似Q∗Q^*Q∗函数。
- 这里agent的目标是什么呢?
- 我们的目标就是打赢游戏,对于强化学习来说它的目标就是在游戏结束使奖励的总和最大化。
- 当我们知道Q∗(s,a)Q^*(s,a)Q∗(s,a)函数,agent应该如何做决策呢?
- 这里我们可以将Q∗(s,a)Q^*(s,a)Q∗(s,a)当作一个先知,它可以告诉我们每一个动作带来的平均回报,我们应该选择平均回报最高的动作。
- DQN想法就是用一个神经网络学习一个函数,让它近似于Q∗(s,a)Q^*(s,a)Q∗(s,a)
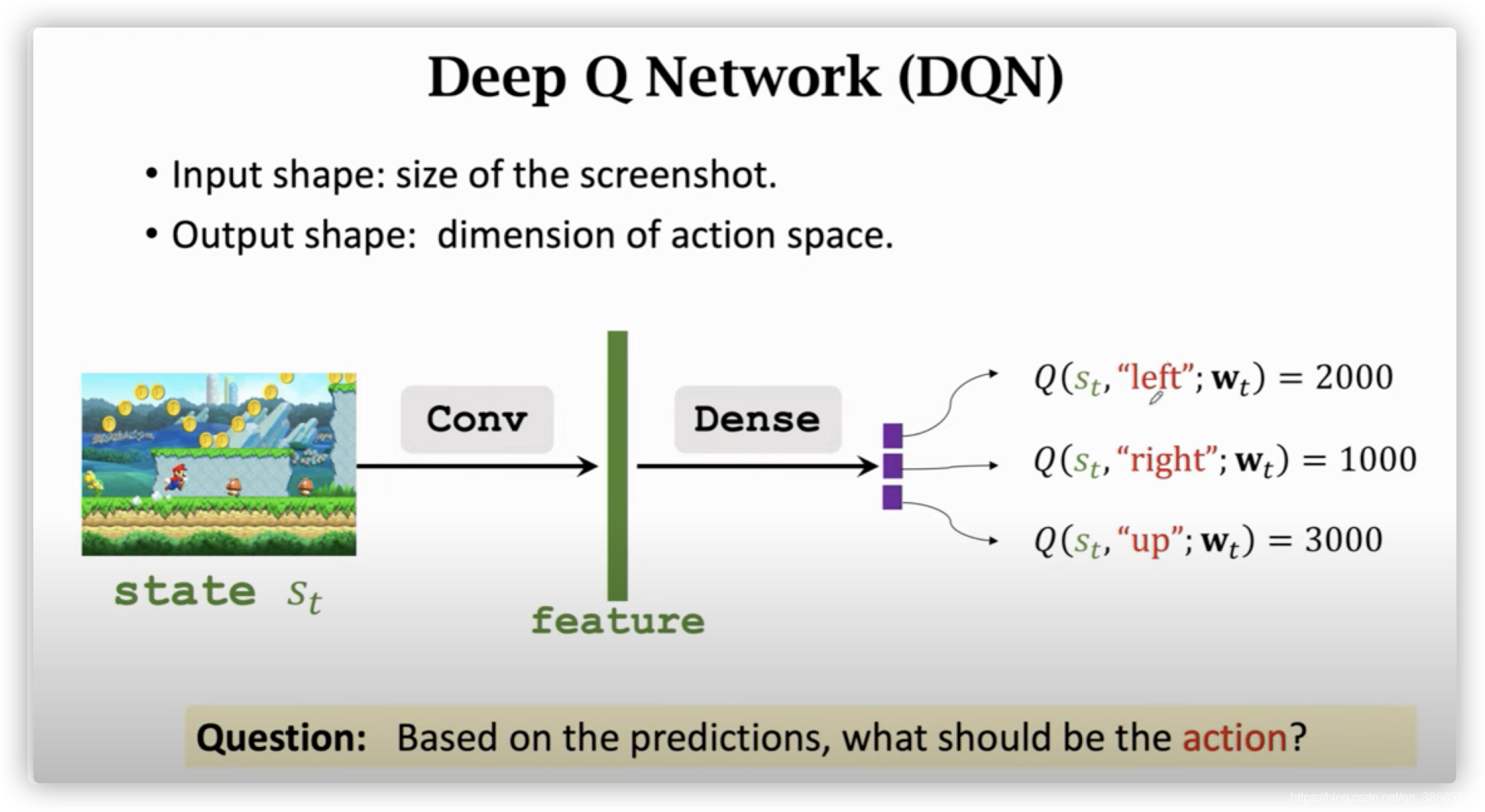
- 我们将这个神经网络记为:Q(s,a;w)Q(s,a;w)Q(s,a;w)。神经网络的参数是w,输入是s,输出是很多数值,每一个数值对所有可能的动作的打分。每一个动作对应一个分数,我们通过奖励来学习这个神经网络,这个神经网络对动作的打分就会越来越准。如果让神经网络玩很多很多次,这个神经网络就和先知一样准确了。
- 这里用一个CNN来进行举例:
- 这里的输入是一个画面的图片,然后使用卷积层将其转换为特征向量,然后用几个全连接层输出几个分数。
- Apply DQN to Play Game
- 当前观测到的状态是sts_tst,将sts_tst作为输入,使用DQN对所有的动作打分,选出分数最高的动作作为ata_tat,agent执行动作ata_tat后,环境会产生新的状态,使用状态转移函数来随机抽取一个新的状态st+1s_{t+1}st+1,同时环境还会告诉我们一个奖励rtr_trt,奖励就是强化学习中的监督信号,DQN要靠奖励来训练。有了新的状态st+1s_{t+1}st+1,将其作为输入,重复上述过程,直到游戏结束。
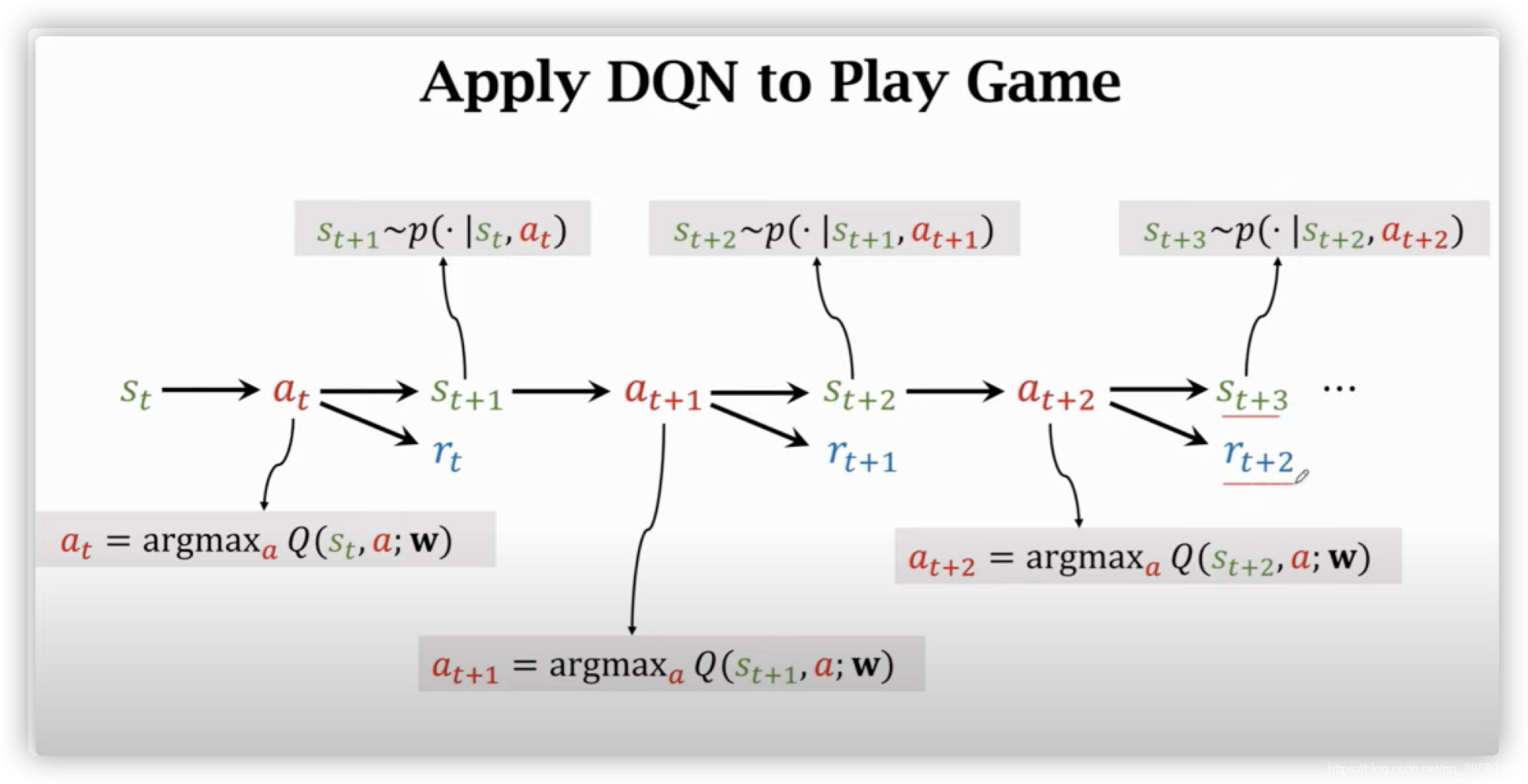
- 当前观测到的状态是sts_tst,将sts_tst作为输入,使用DQN对所有的动作打分,选出分数最高的动作作为ata_tat,agent执行动作ata_tat后,环境会产生新的状态,使用状态转移函数来随机抽取一个新的状态st+1s_{t+1}st+1,同时环境还会告诉我们一个奖励rtr_trt,奖励就是强化学习中的监督信号,DQN要靠奖励来训练。有了新的状态st+1s_{t+1}st+1,将其作为输入,重复上述过程,直到游戏结束。
Temporal Difference (TD) Learning
- 这里使用了一个例子来解释TD算法:假设开车从NYC去Atlanta,机器首先预测需要1000min,但是我们实际上只用了860min,这样我们就可以更新我们的参数w,但是如果我们的车在DC就不走了,这样我们就没有到达Atlanta,这样我们就不能得到一个真实花费的时间,怎么办呢?虽然我们没有全程真实的时间,但是我们知道从NYC到DC的真实事件,假设是300min,这样机器再给出一个DC到Atlanta的时间,假设是600min,这样我们就可以得到一个新的NYC到Atlanta的时间为900min,这个时间虽然不是真实的时间,但是它有真实的时间成分在里面,显然它比最开始机器给出的时间要准确,这样我们就可以拿模型最开始得到的时间来和这个时间来做一次参数的更新,然后得到一个新的模型。这个模型显然比最开始的模型要好。机器第一次给出的时间1000min,和我们后来得到的时间900min,有一个时间差,这个时间差就是TD error,TD算法的目标就是不断的缩小TD error。具体的流程在下面:



- TD Learning for DQN
- 上面我们可以得到一个公式

- 在强化学习中也有类似的公式:等式左边是t时刻的DQN做的估计,也就是未来奖励总和的期望。等式右边rtr_trt是真实观测到的奖励,是真实的,第二项是DQN在t+1时刻做出的估计。

-
前面我们学过折扣回报U,我们做一下如下的推导,得到一个等式:Ut=Rt+γ⋅Ut+1U_t=R_t+\gamma \cdot U_{t+1}Ut=Rt+γ⋅Ut+1。这个等式反映了相邻两个折扣回报之间的关系。
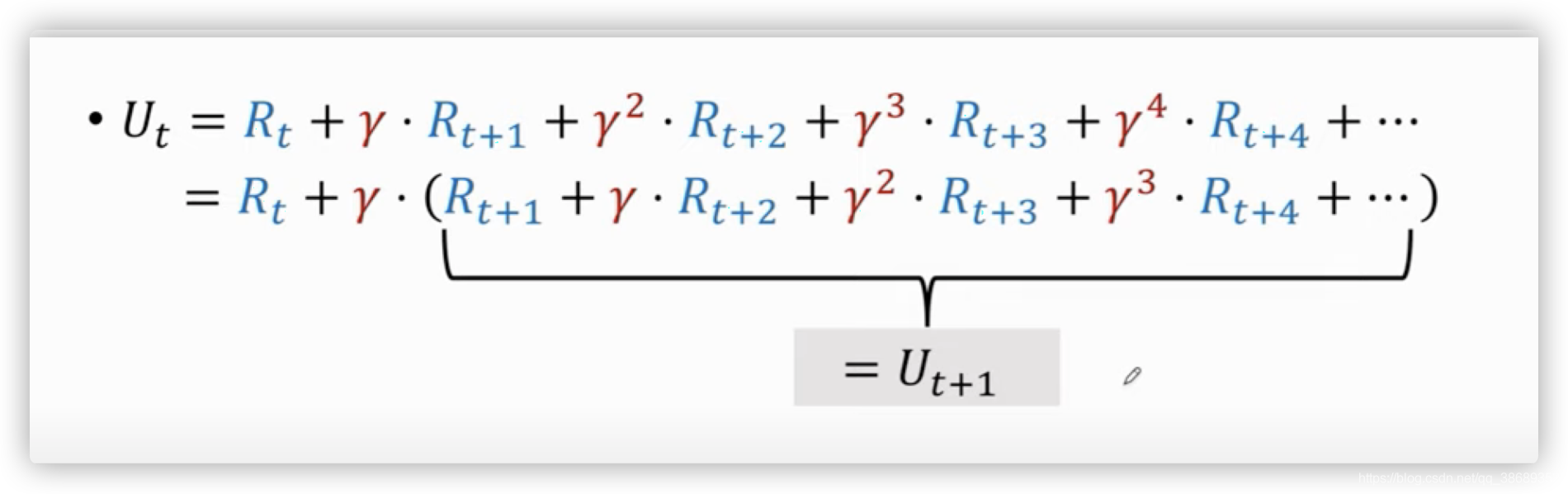
-
现在我们将TD算法用到DQN上,Q(st,at;w)Q(s_t,a_t;w)Q(st,at;w)是用E[Ut]\mathbb{E}[U_t]E[Ut]做出的估计,这就相当于我们之前的例子中,在出发前模型做的预测从NYC到Alanta的时间,在下一时刻,Q(st+1,at+1;w)Q(s_{t+1},a_{t+1};w)Q(st+1,at+1;w)是下一个时刻的估计,这就相当于之前的例子中我们到了DC,模型预测了DC到Alanta的时间。

-
这样根据前面的我可以更新我们的参数了。在t时刻模型做出了预测Q(st,at;wt)Q(s_t,a_t;w_t)Q(st,at;wt),到了t+1时刻,我们观测到了真实的奖励rtr_trt,也可以得到新的状态st+1s_{t+1}st+1,这样我们就可以用DQN算出下一个动作at+1a_{t+1}at+1,这样在t+1时刻我们就知道了rt,st+1,at+1r_t,s_{t+1},a_{t+1}rt,st+1,at+1,可以得到TD target记为yty_tyt,我们希望Q(st,at;wt)Q(s_t,a_t;w_t)Q(st,at;wt)尽量接近TD target yty_tyt,得到loss,使用梯度下降来更新参数。

-
TD算法的一次迭代如下:

Policy-Based Reinforcement Learning
- Policy Network:如果使用神经网络去近似一个policy函数,我们就将这个神经网络称为Policy Network。记为:π(a∣s;θ)\pi (a|s; \theta)π(a∣s;θ)。这里的θ\thetaθ是神经网络的参数,一开始是随机的,后面我们可以通过不断的学习来更新这个θ\thetaθ
- 下面我们使用超级玛丽举例子,这里我们输入是一个画面,然后使用一个或者几个卷积层来将这个画面转化为特征向量,然后由全连接层将画面映射为三维向量(因为这里的动作有三个),然后使用softmax函数来将每个维度变为一个概率。为什么这里要加一个softmax函数呢?是因为policy函数π\piπ是一个概率密度函数,所以π\piπ必须满足,对于所有可能的动作a,将π\piπ函数的输出加起来必须等于1。记为:Σa∈Aπ(a∣s;θ)=1\Sigma_{a\in \mathcal{A}}\pi(a|s;\theta)=1Σa∈Aπ(a∣s;θ)=1
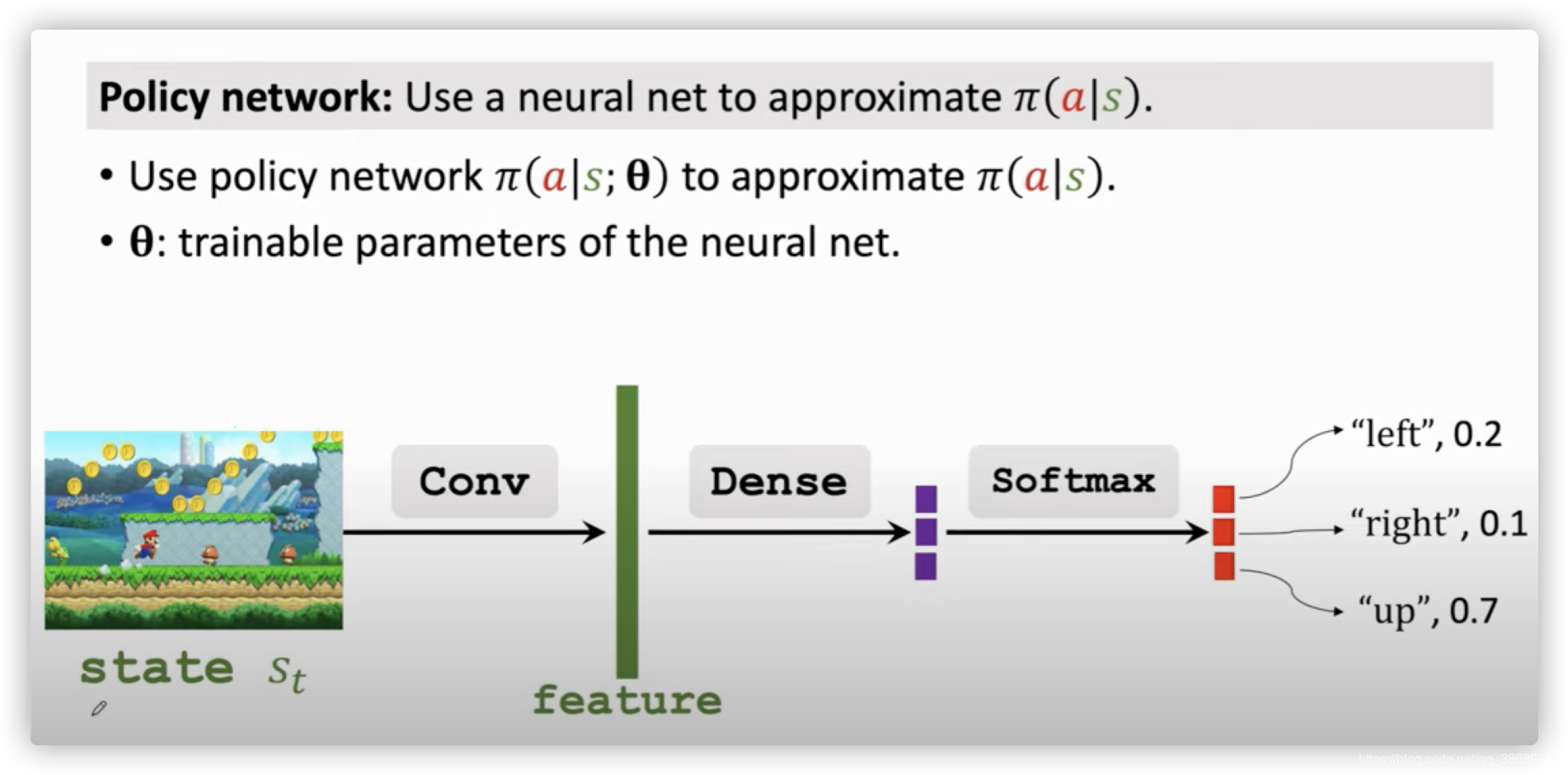

Stats-Value Function Approximation回顾
- 先回顾一下Discounted return:$U_t=R_t + \gamma R_{t+1} + \gamma ^2 R_{t+2}+\cdots 。它的定义是从t时刻开始,未来所有奖励r的加权求和,在t时刻未来的奖励r还没有观测到,所以都用大写的字母表示,他们的随机性都来自于前一时刻的状态s和动作a。动作的随机性来自于策略函数。它的定义是从t时刻开始,未来所有奖励r的加权求和,在t时刻未来的奖励r还没有观测到,所以都用大写的字母表示,他们的随机性都来自于前一时刻的状态s和动作a。动作的随机性来自于策略函数。它的定义是从t时刻开始,未来所有奖励r的加权求和,在t时刻未来的奖励r还没有观测到,所以都用大写的字母表示,他们的随机性都来自于前一时刻的状态s和动作a。动作的随机性来自于策略函数\pi$,状态的随机性来自于状态转移函数p。Discounted return的随机性来自于未来的所有的动作和状态。
- Action-value function:Qpi(st,at)=E[Ut∣St=st,At=at]Q_{pi}(s_t,a_t)=\mathbb{E}[U_t|S_t=s_t, A_t=a_t]Qpi(st,at)=E[Ut∣St=st,At=at]。是UtU_tUt的条件期望,这个期望把以后的动作a和状态s的随机性都消除了,它只依赖于当前的状态sts_tst和动作ata_tat,QπQ_{\pi}Qπ可以评价在状态sts_tst的情况下做出动作ata_tat的好坏程度。
- State-value function:Vπ(st)=EA[Aπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)V_{\pi}(s_t)=\mathbb{E}_A[A_{\pi}(s_t,A)]=\Sigma_a \pi(a|s_t)\cdot Q_{\pi}(s_t,a)Vπ(st)=EA[Aπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)。VπV_{\pi}Vπ是QπQ_{\pi}Qπ的期望,将动作A的给积掉,这里的动作A被视为随机变量,它的概率密度函数是A∼π(⋅∣st)A \sim \pi(\cdot|s_t)A∼π(⋅∣st),这样Vπ(st)V_{\pi}(s_t)Vπ(st)就只和策略函数π\piπ和当前的状态sts_tst有关了。这样当给定策略函数π\piπ,VπV_{\pi}Vπ就可以评价当前的状态的好坏。当给定状态sts_tst就可以评价当前的策略函数π\piπ的好坏了。
Policy-Based Reinforcement Learning
- 上面我们得到了状态价值函数VπV_{\pi}Vπ,下面我们就要用状态价值函数来近似VπV_{\pi}Vπ,Vπ(st)=E[Qπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)V_{\pi}(s_t)=\mathbb{E}[Q_{\pi}(s_t,A)]=\Sigma_a \pi(a|s_t)\cdot Q_{\pi}(s_t, a)Vπ(st)=E[Qπ(st,A)]=Σaπ(a∣st)⋅Qπ(st,a)
- 我们使用神经网络来近似策略函数π\piπ,这样我们就可以将VπV_{\pi}Vπ中的π\piπ替换为神经网络,这样V(st;θ)=Σaπ(a∣st;θ)⋅Qπ(st,a)V(s_t;\theta)=\Sigma_a\pi(a|s_t;\theta)\cdot Q_{\pi}(s_t,a)V(st;θ)=Σaπ(a∣st;θ)⋅Qπ(st,a)

- 通过上面转换我们可以将state-value function函数近似的写为:V(s;θ)=Σπ(a∣s;θ)⋅Qπ(s,a)V(s;\theta)=\Sigma \pi(a|s;\theta)\cdot Q_{\pi}(s,a)V(s;θ)=Σπ(a∣s;θ)⋅Qπ(s,a),这样我们就可以用V来评价策略网络的好坏,给定状态s,策略网络越好,V的值越大。这样我们就可以同过改变网络的参数θ\thetaθ来让V(s∣θ)V(s|\theta)V(s∣θ)来变大。通过这个想法我们就可以把目标函数定义为:J(θ)=ESV(S;θ)J(\theta)=\mathbb{E}_S{V(S;\theta)}J(θ)=ESV(S;θ),这里的期望是关于状态S求的,使用期望将状态S给去掉,这样一来变量就只剩下θ\thetaθ了,目标函数J(θ)J_(\theta)J(θ)就是对策略网络的评价,策略网络越好J(θ)J(\theta)J(θ)的值就越大。这样策略学习的目标就转换为了不断的改进θ\thetaθ使得目标函数越大越好。
- 那么我们怎么改进θ\thetaθ呢?使用Policy gradient ascent。
- 让agent玩游戏,每一步都观测到一个不同的状态s,这个状态s就像当于从状态s的概率分布中抽样出来的,然后将V(s;θ)V(s;\theta)V(s;θ)关于θ\thetaθ求导,然后用梯度上升来更新θ\thetaθ

- 让agent玩游戏,每一步都观测到一个不同的状态s,这个状态s就像当于从状态s的概率分布中抽样出来的,然后将V(s;θ)V(s;\theta)V(s;θ)关于θ\thetaθ求导,然后用梯度上升来更新θ\thetaθ
Policy Gradient
-
上面我们得到了V(s;θ)=Σaπ(a∣s;θ)⋅Qπ(s,a)V(s;\theta)=\Sigma_a\pi(a|s;\theta) \cdot Q_{\pi}(s,a)V(s;θ)=Σaπ(a∣s;θ)⋅Qπ(s,a),它是对state-value的近似。这里的π(a∣s;θ)\pi(a|s;\theta)π(a∣s;θ)是策略网络。
-
Policy gradient:就是V对θ\thetaθ的导数。推导过程如下。



-
这样我们就得到两种关于policy grident的等式

-
有了上面两个公式,我们就可以实际的去计算策略梯度了。
- 如果动作是离散的我们就可以用第一种公式。

- 对于动作是连续的我们就可以用第二种公式来计算。因为动作是连续的所以我们要积分。但是没办法积分,怎么办呢,我们这里就使用蒙特卡洛近似,将这个期望给近似出来。下面是蒙特卡洛近似的做法
- 根据π(⋅∣s;θ)\pi (\cdot|s;\theta)π(⋅∣s;θ)随机抽样一个动作a^\hat{a}a^
- 然后我们将期望括号里面的东西记为g(a^,θ)g(\hat{a},\theta)g(a^,θ)
- 因为a^\hat{a}a^是根据概率密度函数π\piπ随机抽出来的,g(a^,θ)g(\hat{a},\theta)g(a^,θ)是策略梯度的一个无偏估计,所以可以用它来近似策略梯度。


- 如果动作是离散的我们就可以用第一种公式。
总结策略梯度算法
-
在t时间点观测到了状态sts_tst,接下来我们用蒙特卡洛近似来计算策略梯度,将策略网络π(⋅∣st;θt)\pi(\cdot|s_t;\theta_t)π(⋅∣st;θt)作为概率梯度函数,用它随机抽样得到一个动作ata_tat,计算价值函数Qπ(st,at)Q_{\pi}(s_t,a_t)Qπ(st,at)将结果记为qtq_tqt,对 策略网络π\piπ求导,得到的结果dθ,td_{\theta,t}dθ,t是向量、矩阵或者张量,其大小和θ\thetaθ是相等的。然后近似的算策略梯度,最后更新策略网络的参数θ\thetaθ
 a
a -
上面第三步中我们并不知道状态价值函数QπQ_{\pi}Qπ,所以我们并没有办法得到qtq_tqt的值,有两种方法可以近似得到它的值
- REINFORCE:用策略网络π\piπ来控制agent运动,从一开始一直玩到游戏结束,把整个游戏的轨迹都记录下来,这样我们就可以观测到所有奖励r,我们就可以算出来return UtU_tUt,因为QπQ_{\pi}Qπ是UtU_tUt的期望,这样我们就可以用UtU_tUt的观测值utu_tut来近似QπQ_{\pi}Qπ,这样qt=utq_t=u_tqt=ut。这个算法需要玩完一局游戏,观测到所有的奖励,然后才能更新策略网络。

- 另一个方法就是使用一个神经网络来近似QπQ_{\pi}Qπ,原本我们使用一个神经网络来近似策略函数π\piπ,这样我们就有了两个神经网络,这两个神经网络一个被称为actor,一个被称为critic。就有了actor-method方法。
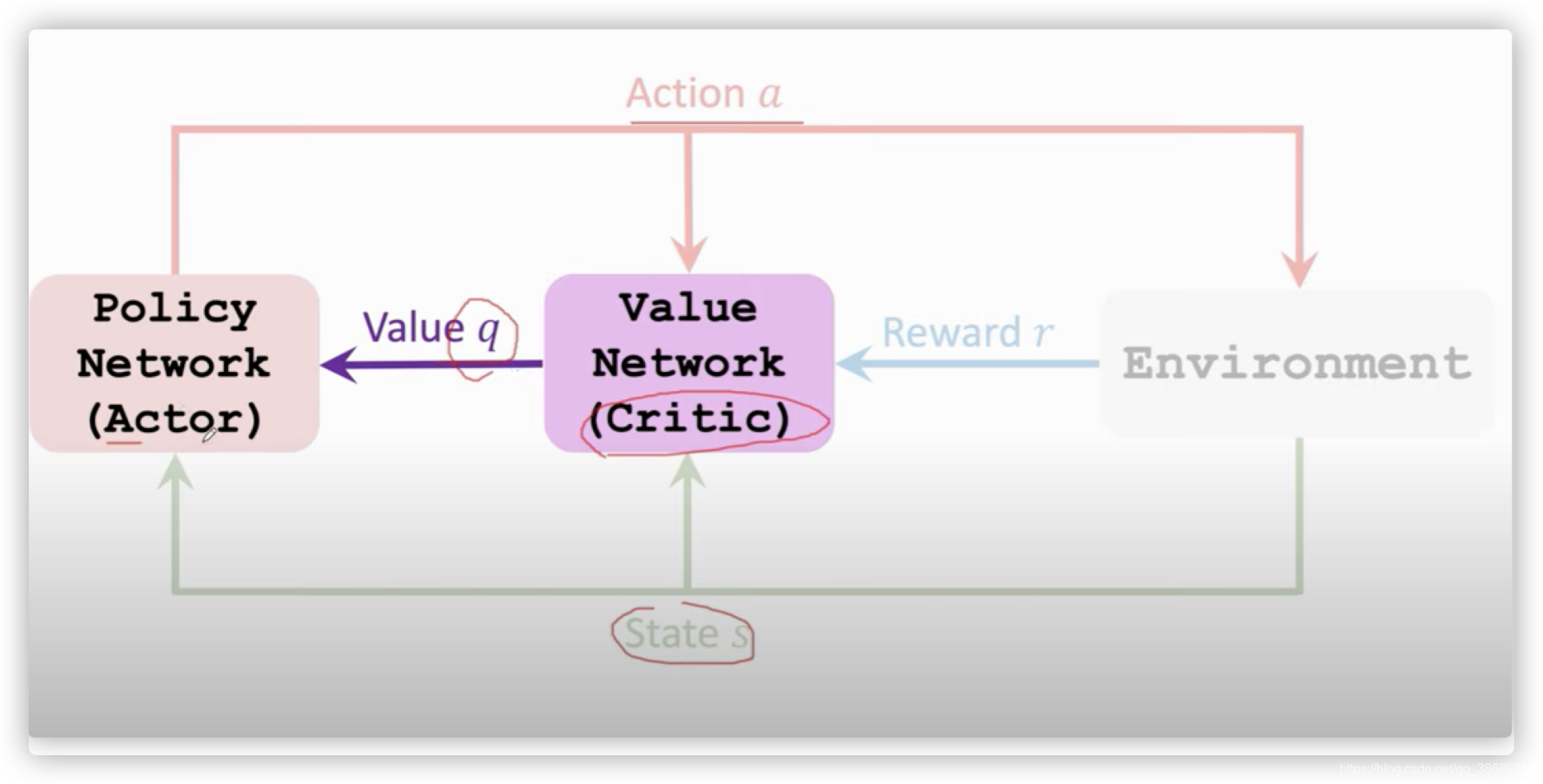
Actor-Critic Methods
回顾
- 看看怎么构造价值网络和策略网络
- State-Value Funtion Approximation
- 状态价值函数Vπ(s)V_{\pi}(s)Vπ(s)是动作价值函数Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)的期望,如果动作是离散的VπV_{\pi}Vπ可以写为:Vπ(s)=Σaπ(a∣s)⋅Qπ(s,a)V_{\pi}(s)=\Sigma_a \pi(a|s)\cdot Q_{\pi}(s,a)Vπ(s)=Σaπ(a∣s)⋅Qπ(s,a)形式。如果动作是连续的连加就要被换成定积分。π(a∣s)\pi(a|s)π(a∣s)函数是策略函数,可以用来计算动作的概率值,从而控制agent做运动。Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)是动作价值函数,可以用来评价动作的好坏程度。但是这两个函数我们都不知道,我们该怎么办呢?这里我们就可以用两个神经网络来学习,从而近似这两个函数,然后用Actor-Critic方法同时学习这两个函数。
- State-Value Funtion Approximation
Actor-Critic Methods
- Policy network(actor):
- 我们可以使用神经网络π(a∣s;θ)\pi(a|s;\theta)π(a∣s;θ)来近似π(a∣s)\pi(a|s)π(a∣s),这里的θ\thetaθ是神经网络的参数,这个神经网络被我们称为策略网络,我们使用策略网络来控制agent做运动,决策是由策略网络做的。
- Value network(critic):
- 使用一个神经网络q(s,a;w)q(s,a;w)q(s,a;w)来近似Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)。这里的w是神经网络的参数,这个神经网络被我们称为价值网络,这里的价值网络不控制agent运动,它只给动作打分,它相当于裁判。
- 举个例子:actor就相当于一个运动员,它想改进自己的技术,但是它不知道该怎么做,这就需要裁判,它给运动员的动作打分,Critic就相当于裁判,它给actor打分。这样呢运动员就知道什么样的动作分数高,什么样的动作分数低,这样运动员就会改进自己,让自己的分数越来越高。
- 通过上面的近似我们可以将VπV_{\pi}Vπ写为:Vπ(s)≈Σaπ(a∣s;θ)⋅q(s,a;w)V_{\pi}(s) \approx \Sigma_a \pi(a|s;\theta)\cdot q(s,a;w)Vπ(s)≈Σaπ(a∣s;θ)⋅q(s,a;w),这里π\piπ就是策略网络,相当于运动员,qqq是价值网络相当于裁判。
- 现在我们来搭这两个神经网络
- 首先是policy网络(Actor):π(a∣s,θ)\pi(a|s,\theta)π(a∣s,θ)
- 首先输入是当前的状态,在超级玛丽的游戏中,输入就是当前的画面
- 卷积层将画面转换为特征向量,用一个或者多个全连接层将特征向量映射到另一个向量,如果有三个动作,这个向量就是三维向量,然后使用这softmax将这个向量转化为一个和为一的特征向量,即为策略网络的输出,这个特征向量的每一个值对应着一个动作的概率。
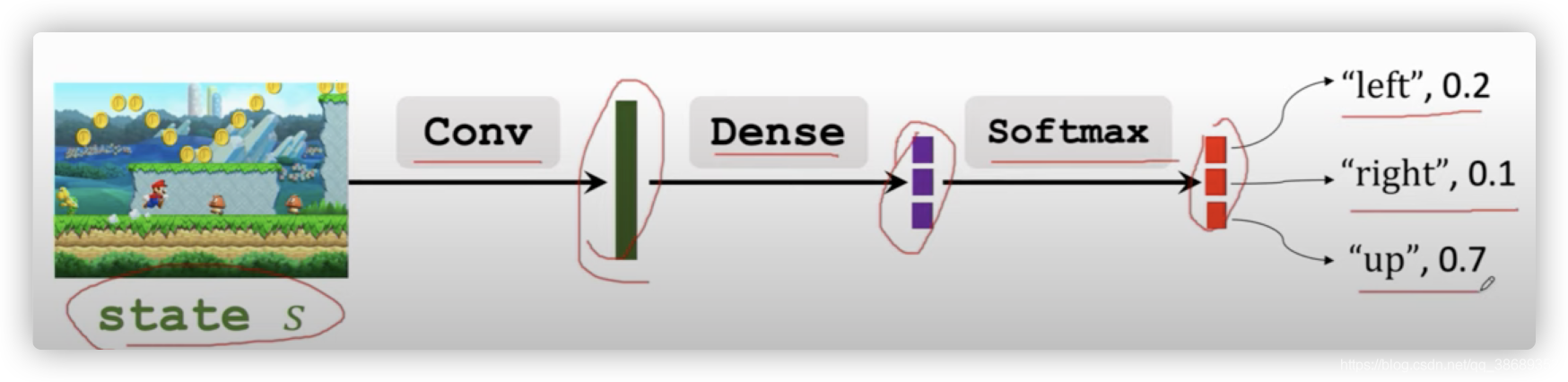
- 然后我实现价值网络q(s,a;w)q(s,a;w)q(s,a;w)
- 这里有两个输入,一个是状态s,另一个是动作a,如果动作是离散的,就可以使用one-hot coding来表示动作。
- 然后分别用卷积层和全连接层从输入中提取特征。得到两个特征向量,然后拼起来,最后用全连接层输出一个实数,这个实数就是裁判给运动员打得分数,这个分数可以表示在当前的状态s下,做出动作a的好坏,这个价值网络可以和策略网络共享卷积层的参数,也可以和策略网络相互独立,各自有各自的参数。
- 同时训练价值网络和策略网络就被称为:Actor-cricit method。可以这么理解,actor用来控制agent运动,critic来给这个动作打分。学习这两个网络的目的是让运动员的平均分越来越高。并且裁判的打分越来越精准。
- 首先是policy网络(Actor):π(a∣s,θ)\pi(a|s,\theta)π(a∣s,θ)
Train the Neural Networks
- 上面我们使用策略网络来近似策略函数,价值网络来近似动作价值函数,这样状态价值函数就可以表示为: V(s;θ,w)=Σaπ(a∣s;θ)⋅q(s,a;w)V(s;\theta ,w)=\Sigma_a \pi(a|s;\theta)\cdot q(s,a;w)V(s;θ,w)=Σaπ(a∣s;θ)⋅q(s,a;w)。
- 训练时候我们只需要更新两个网络的参数θ\thetaθ和w,但是我们更新这两个函数的目标是不同的
- 更新策略网络的参数θ\thetaθ是为了让状态价值函数V(s;θ,w)V(s;\theta,w)V(s;θ,w)的值增加,VVV函数是对策略函数π\piπ和状态s的评价,如果固定s,则V的值越大,则策略网络越好。所以我们需要更新θ\thetaθ使得V的平均值增加。学习策略网络π\piπ的时候,监督是由价值网络q提供的。
- 更新价网络的参数w是为了让q的打分更精准,从而更好的估计未来得到的奖励的总和。因为一开始参数w是随机初始化的,所以一开始裁判没有判断能力。它的打分都是瞎猜的,裁判会逐渐改进自己的水平让自己的打分越来越精准。裁判靠的是环境给的奖励来改进自己的打分的。这里可以理解为环境给的奖励就是上帝给的奖励,但是上帝一开始不会将自己的打分告诉别人,只有在游戏结束后才会公开。裁判要做的就是让它的打分接近上帝的打分。

- 训练时候我们只需要更新两个网络的参数θ\thetaθ和w,但是我们更新这两个函数的目标是不同的
- 两个神经网络一次更新的步骤
- 首先观测到状态sts_tst
- 将sts_tst作为输入,用策略网络π\piπ来计算概率分布,使用随机抽样来得到动作ata_tat
- agent执行动作ata_tat,会观测到新的状态st+1s_{t+1}st+1,并且得到奖励rtr_trt
- 有了奖励rtr_trt就可以使用TD参数来更新价值网络的参数w,。也就是让裁判变得跟准确
- 最后用policy gradient来更新策略网络的参数θ\thetaθ,更新策略网络的参数需要用到裁判对动作ata_tat的打分。

- 更新价值网络q的参数可以使用TD算法
- 首先使用价值函数给动作打分,这里分别对动作ata_tat和动作at+1a_{t+1}at+1打分,这里的动作是根据策略网络π\piπ随机抽样得到的
- 然后计算TD target记作yty_tyt。
- 然后使用预测值与TD target的差的平方的一半作为损失函数,这个损失函数鼓励预测值和TD target越接近越好。
- 做梯度下降使得损失函数越来越小,更新参数。

- 使用策略梯度算法来更新策略函数的参数θ\thetaθ
- 策略梯度就是函数VVV关于函数θ\thetaθ的导数。
- 定义:g(a,θ)∂logπ(a∣s,θ)∂θ⋅q(st,a;w)g(a,\theta)\frac{\partial log \pi(a|s,\theta)}{\partial \theta} \cdot q(s_t,a;w)g(a,θ)∂θ∂logπ(a∣s,θ)⋅q(st,a;w),这里的q是裁判的打分
- ∂V(s;θ,wt)∂θ=EA[g(A,θ)]\frac{\partial V(s;\theta,w_t)}{\partial \theta}=\mathbb{E}_A[g(A,\theta)]∂θ∂V(s;θ,wt)=EA[g(A,θ)],但是这个期望很难求出来,我们就使用一个g(A∣θ)g(A|\theta)g(A∣θ)就可以了,一个g(a∣θ)g(a|\theta)g(a∣θ)就是对期望的蒙特卡洛近似。
- 既然g函数是策略网络梯度的无偏估计,我们就可以使用g函数来代替策略梯度。具体做法为:首先根据策略网络π\piπ来随机抽样得到动作a,这个随机抽样的目的是保证样本的无偏性,有了随机梯度g,可以做一次梯度上升,更新一次θ\thetaθ,梯度是V关于θ\thetaθ的导数,梯度上升可以增加V的值。

总结Actor-Critic Method
- 这里首先策略网络也就是Actor做出根据当前环境的状态做出一个动作ata_tat,然后价值网络根据这个动作ata_tat以及当前的环境状态sts_tst,来给这个动作打分,一开始岁尾价值网络的参数是随机的,所以Critic打分并不准确。当做完一套动作之后,环境给出了一个奖励r,Critic根据环境给出的奖励r和动作at+1a_{t+1}at+1及状态st+1s_{t+1}st+1来更新自己的参数θ\thetaθ,然后得到了一个更准确的分数,Actor根据这个分数来更新自己的参数w
- 首先策略网络观测到当前的状态s,控制agent做出动作a,为了让Actor表现的越来越好,我们使用Critic来帮忙,当Actor做出动作之后 ,Critic会根据状态s和动作a来打一个分数q,Critic将q告诉Actor,这样Actor就可以改进自己了。Actor根据Critic的打分来改进自己的技术,这里的技术就指的是策略网络的参数w,它通过状态s,动作a以及q来近似算出策略梯度,然后做梯度上升来改进自己的参数。通过不断的更新参数,Actor会获得越来越高的平均分。但是更高的分数并不一定表示这个Actor变得越来越好,因为它可能只是在迎合Critic的喜好,所以我们需要让Critic不断改进它的打分能力,最开始Critic的参数是随机初始化的,它的打分就是瞎猜,所以没什么帮助,所以我们要不断改进Critic。Critic要靠奖励r来不断的提升自己的水平,奖励r就相当于上帝的判断, 裁判更具状态s和动作a来进行打分,然后通过比较相邻两次打分qtq_tqt和qt+1q_{t+1}qt+1以及r,使用TD算法来更新Critic参数,使得Critic打分更精准。
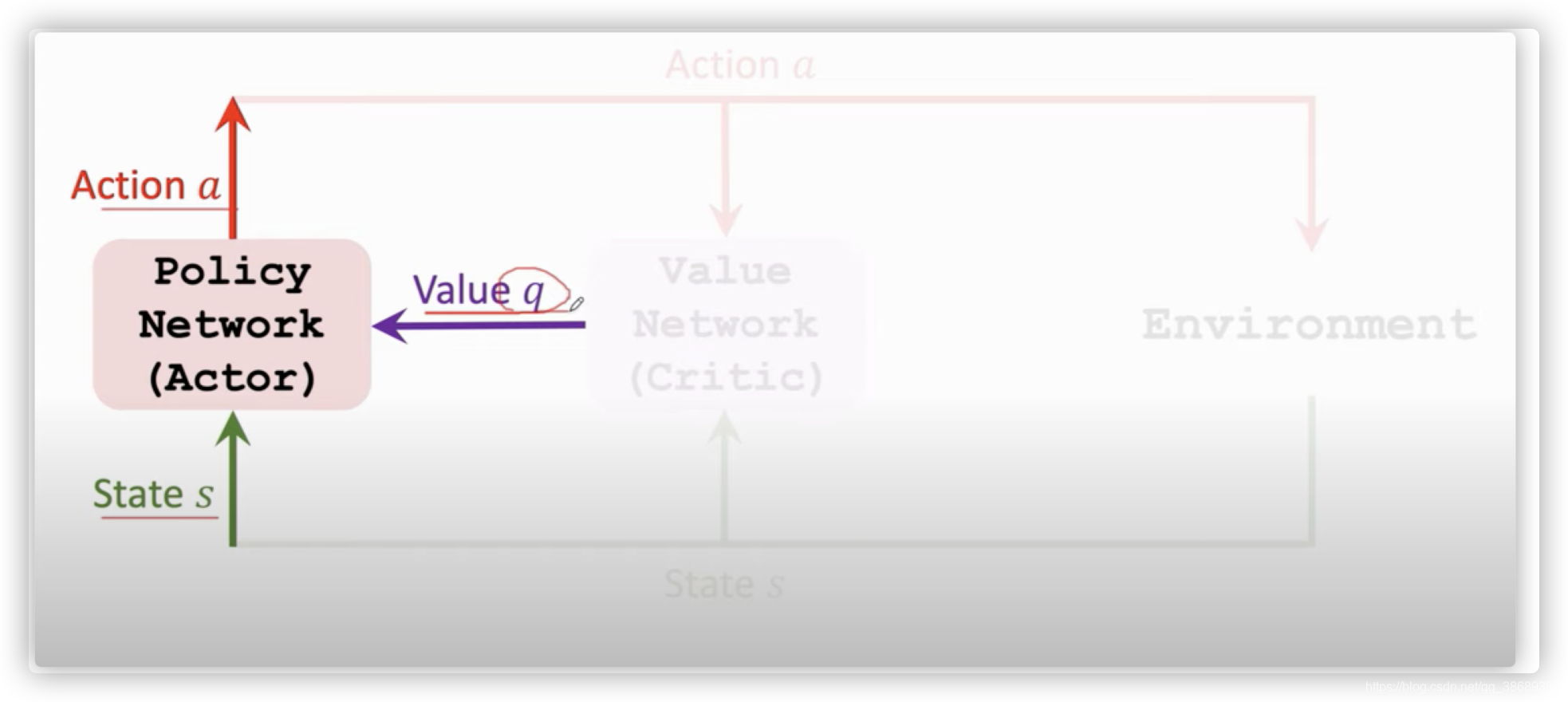
- 首先策略网络观测到当前的状态s,控制agent做出动作a,为了让Actor表现的越来越好,我们使用Critic来帮忙,当Actor做出动作之后 ,Critic会根据状态s和动作a来打一个分数q,Critic将q告诉Actor,这样Actor就可以改进自己了。Actor根据Critic的打分来改进自己的技术,这里的技术就指的是策略网络的参数w,它通过状态s,动作a以及q来近似算出策略梯度,然后做梯度上升来改进自己的参数。通过不断的更新参数,Actor会获得越来越高的平均分。但是更高的分数并不一定表示这个Actor变得越来越好,因为它可能只是在迎合Critic的喜好,所以我们需要让Critic不断改进它的打分能力,最开始Critic的参数是随机初始化的,它的打分就是瞎猜,所以没什么帮助,所以我们要不断改进Critic。Critic要靠奖励r来不断的提升自己的水平,奖励r就相当于上帝的判断, 裁判更具状态s和动作a来进行打分,然后通过比较相邻两次打分qtq_tqt和qt+1q_{t+1}qt+1以及r,使用TD算法来更新Critic参数,使得Critic打分更精准。
Summary of Algorithm
- 观测到旧的状态sts_tst,然后根据策略网络π\piπ来计算概率分布,然后根据算出的概率,来随机抽样得到ata_tat
- 让Agent执行ata_tat,,然后环境会给我们一个新的状态st+1s_{t+1}st+1和奖励rtr_trt
- 让新的状态st+1s_{t+1}st+1作为输入,让策略网络π\piπ计算出新的概率,然后随机抽样得到新的动作a~t+1\tilde{a}_{t+1}a~t+1,这个动作只是一个假象的动作,用来算一下q值,agent并不会真正的去执行这个动作。算法的每次循环中只做一次动作。
- 算两次价值网络的输出qt=q(st,at;wt)q_t=q(s_t,a_t;w_t)qt=q(st,at;wt)和qt+1=q(st+1,a~t+1;wt)q_{t+1}=q(s_{t+1},\tilde{a}_{t+1};w_t)qt+1=q(st+1,a~t+1;wt),这里a~t+1\tilde{a}_{t+1}a~t+1在用完之后就丢弃了
- 计算TD error:δt=qt−(rt+γ⋅qt+1)\delta_t=q_t-(r_t+\gamma \cdot q_{t+1})δt=qt−(rt+γ⋅qt+1)
- 对价值网络求导,然后使用TD算法来更新价值网络
- 对策略网络π\piπ求导,更新策略网络。



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)