【强化学习】DQN算法
但是在每次训练Q网络中,时序差分估算的Qtd值和Qw值同步更新,这会让Q网络不稳定。因此,DQN维护两个网络,一个网络用于计算Qw值,一个网络用于计算Qtd值。Qw网络每次训练值更新w参数不会更新Qtd值,每N次训练后都会从另一个网络(目标网络)复制Qtd值;,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来
1. Q-learning算法局限性
Q-learning算法根据时序差分来推导下一轮的Q值,这是基于状态和动作都是离散的、有限的;当状态和动作是连续的,Q-learning方法不可用。
2. DQN算法思路
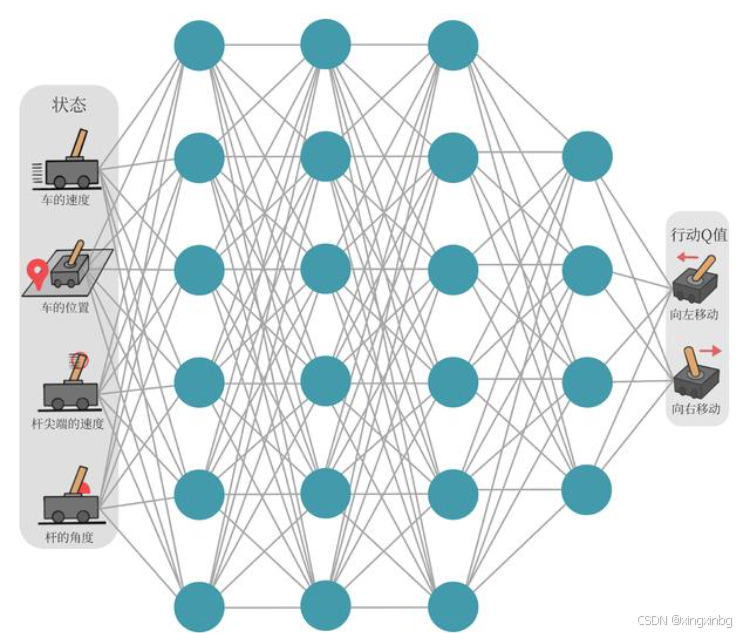
使用神经网络来拟合Q值,即给神经网络输入动作、状态对,神经网络输出Q值,从而构建拟合函数![]() ,其中是神经网络的参数,我们管这个网络叫Q网络。将Q网络融合到Q-learning的新算法叫深度Q网络(DQN)
,其中是神经网络的参数,我们管这个网络叫Q网络。将Q网络融合到Q-learning的新算法叫深度Q网络(DQN)
3. 损失函数
Q网络将时序差分更新的Q值当做真实值,通过均方误差构建损失函数
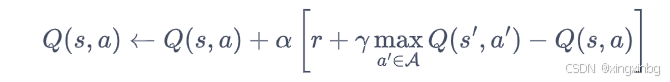
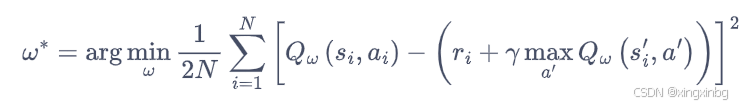
4. DQN算法细节
(1)经验回放
DQN维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。其每次交互产生一条序列后不用于直接更新Q网络参数,而是放到经验缓冲区中。
Q网络的训练是随机从缓冲区抽到若干条序列后进行训练。这样做是因为,两条相邻的序列往往具有相关性,经验回放有利于打破样本之间的相关性,让其满足独立同分布假设(神经网络需要样本是独立同分布的)
(2)目标网络
观察DQN的损失函数,其目标是让Qw值接近于时序差分的估值。但是在每次训练Q网络中,时序差分估算的Qtd值和Qw值同步更新,这会让Q网络不稳定。因此,DQN维护两个网络,一个网络用于计算Qw值,一个网络用于计算Qtd值。 Qw网络每次训练值更新w参数不会更新Qtd值,每N次训练后都会从另一个网络(目标网络)复制Qtd值;目标网络每次训练只更新Qtd值不更新w参数,每N次训练从另一个网络复制w参数。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)