答疑:监督学习和无监督学习
·
聊到监督学习和无监督学习,很多同学是存在误区的:
今天就简单聊聊,
-
监督学习
- 输入数据被标记,包括特征值和目标值
- 函数的输出可以是一个连续的值(称为回归)或是输出是有限个离散值(称作分类)
- 常见的监督学习算法:回归分析和统计分类。最典型的算法是 KNN 和 SVM
-
无监督学习
- 输入数据是由输入特征值组成,没有目标值
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知;
- 需要根据样本间的相似性对样本集进行类别划分
- 输入数据没被标记,即无法预测样本标签。非监督学习,是要让机器自己学习怎样做某事。
常见的是聚类分析,聚类的规则,是并不知道具体分类的规则,需要靠算法进行判断数据之间的相似性,也就是,探索和挖掘数据中潜在的差异和联系。
- 数据分析中,常见的聚类方法是 K-Mcans。应用过程是:
1、先确定分组数 k
2、随机选择 k 个值作为数据中心
3、计算其他数值与数据中心的距离,根据距离,完成第一次分组
4、重新选择新的数据中心,在第 3 步中选择两个数据中心
5、再次计算出其他数据与新数据中心的距离,根据距离,再次分组
重复第 4 步,直到数据中心不再变化了。完成分类
实际工作中,python excel FineBI中都有聚类功能。设置好分组数,迭代次数、距离计算公式。
- 半监督学习
- 训练集同时包含有标记样本数据和未标记样本数据
- 监督学习训练方式:
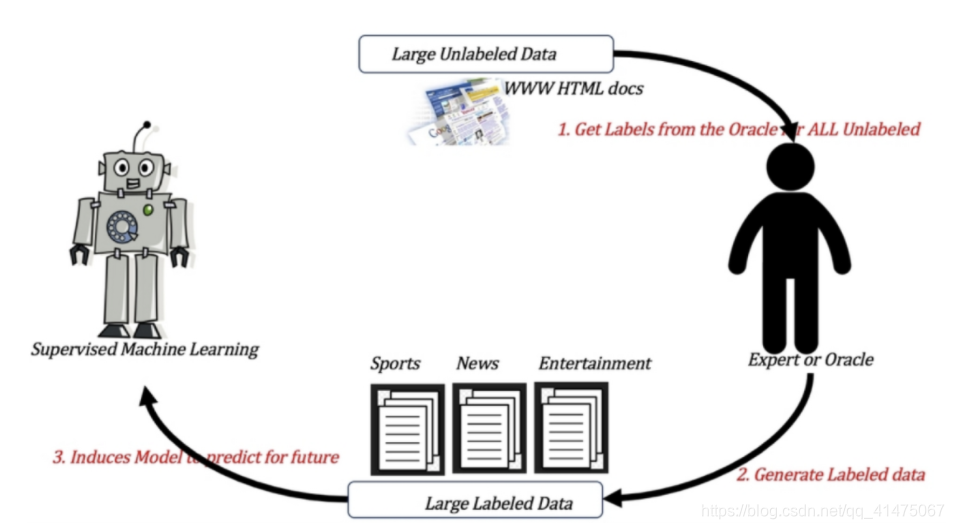
- 半监督学习的训练方式:
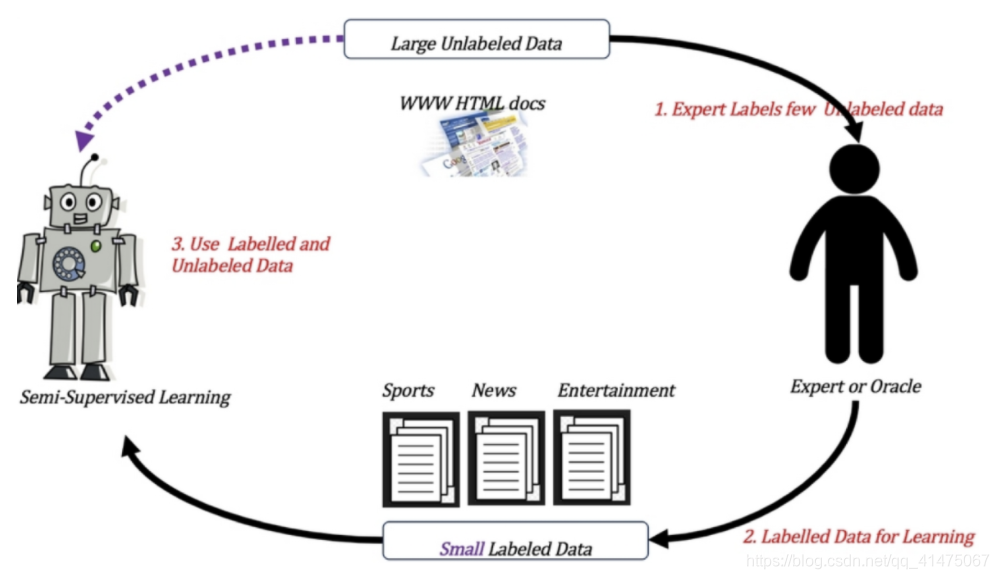
总结: - 区分监督学习和无监督学习,就看数据是否有标签即可,即:是否有目标值
- 区分监督学习和半监督学习,就看训练集数据是否同时包含标记样本数据和未标记样本数据

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)