【强化学习】策略梯度算法
基于策略的方法则是存在一个显式的目标策略(使该策略下的动作价值函数期望最大),通过神经网络从每次和环境交互的数据中不断逼近该策略,即神经网络是对策略进行建模,输入是状态,输出是动作的概率分布。Q-learning、DQN都是基于动作价值函数的更新来推导最优策略的,即每次更新并不存在一个显示的策略,这个策略是随着Q值的更新而更新的,这是基于价值的方法。
·
1. 基于策略的算法
Q-learning、DQN都是基于动作价值函数的更新来推导最优策略的,即每次更新并不存在一个显示的策略,这个策略是随着Q值的更新而更新的,这是基于价值的方法。
基于策略的方法则是存在一个显式的目标策略(使该策略下的动作价值函数期望最大),通过神经网络从每次和环境交互的数据中不断逼近该策略,即神经网络是对策略进行建模,输入是状态,输出是动作的概率分布。
2. 策略梯度算法
目标函数定义为:
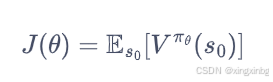
每次数据训练后,使用梯度上升的方法更新:
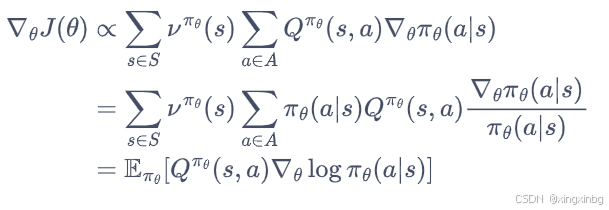
其中Q值使用蒙特卡洛方法得到:
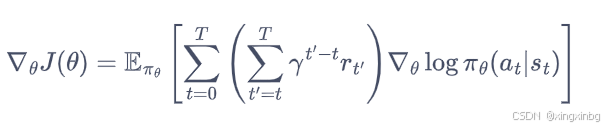

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)