Q-learning的强化学习2*2案例C语言实现
————————————————————————————————————————————————
版权声明:本文为CSDN博主「小然_ran」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_23144435/article/details/80368635
Q-Learning是强化学习算法核心思想
Q-Learning是强化学习算法中value-based的算法,Q即为Q(s,a),就是在某一个时刻的state状态下,采取动作a能够获得收益的期望,环境会根据agent的动作反馈相应的reward奖赏,所以算法的主要思想就是将state和action构建成一张Q_table表来存储Q值,然后根据Q值来选取能够获得最大收益的动作。
Q-learning的主要优势就是使用了时间差分法(融合了蒙特卡洛和动态规划)能够进行off-policy的学习,使用贝尔曼方程可以对马尔科夫过程求解最优策略。
*
算法的基本流程:*
1、初始化Q-table矩阵
2、选择起始state
3、选择当前state(s)下的一个可能action(a)
4、换移到下一个state(s’)
5、重复第3步
6、使用Bellman Equation,更新Q-table
7、将下一个state作为当前state
8、如此迭代三十年,直到大厦崩塌…
。。。。。。
比如,从state-1开始,可能的action有D, R, N。然后我们选择了D,到了state-3,这个state踩中了陷阱,所以-10。
在state-3又有三种可能的action:U, R, N。 又因为此时Q-table还没有经过更新,所以当然就是0。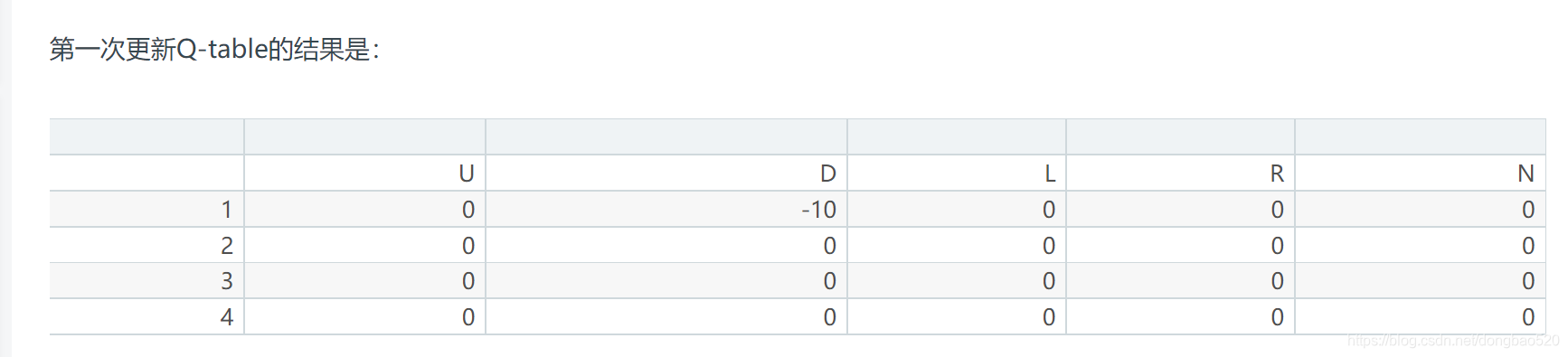
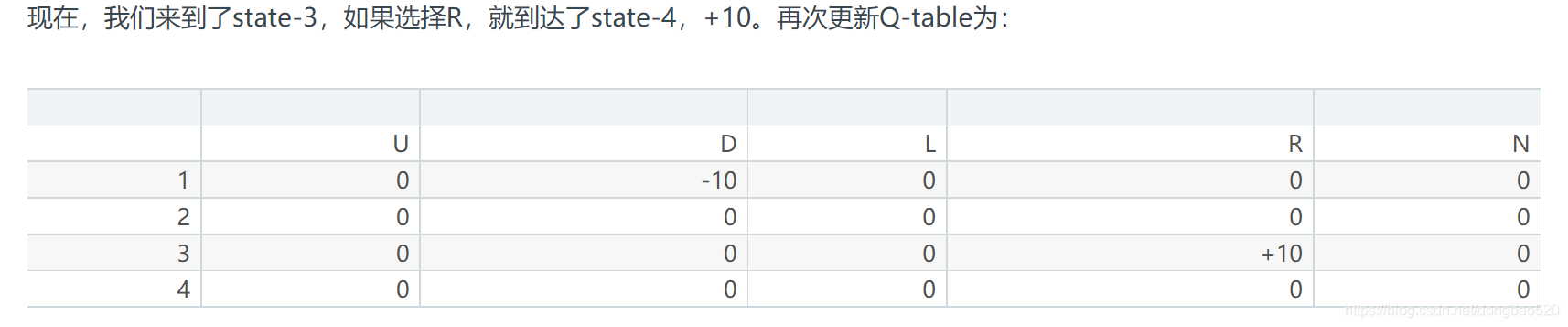
参考案例源码:
#include <stdio.h>
#include<time.h>
#include<stdlib.h>
const double lr = 0.7;
int reward[4][5] = { { 0,-10,0,-1,-1 },{ 0,10,-1,0,-1 },{ -1,0,0,10,-1 },{ -1,0,-10,0,10 } };
double q_matrix[4][5] = { { 0,0,0,0,0 },{ 0,0,0,0,0 },{ 0,0,0,0,0 },{ 0,0,0,0,0 } };
int transition_matrix[4][5] = { { -1,2,-1,1,1 },{ -1,3,0,-1,2 },{ 0,-1,-1,3,3 },{ 1,-1,2,-1,4 } };
int valid_actions[4][3] = { { 1,3,4 },{ 1,2,4 },{ 0,3,4 },{ 0,2,4 } };
int choice(int arr[])
{
srand(time(NULL));
int seed = rand() % 3;
int i = 0;
return arr[seed];
}
double max(double arr[])
{
int i;
double max = -10000.0;
for (i = 0; i < 3; i++)
{
if (max < arr[i])
{
max = arr[i];
}
}
return max;
}
int main()
{
int i = 0;
for (i = 0; i < 1000; i++)
{
int start_state = 0;
int current_state = start_state;
while (current_state != 3)
{
int action = choice(valid_actions[current_state]);
int next_state = transition_matrix[current_state][action];
int future[3] = { 0 };
double future_rewards[3] = { 0 };
int action_nxt;
int action_next_next;
for (action_nxt = 0; action_nxt < 3; action_nxt++)
{
future[action_nxt] = valid_actions[next_state][action_nxt];
}
for (action_next_next = 0; action_next_next < 3; action_next_next++)
{
future_rewards[action_next_next] = q_matrix[next_state][action_nxt];
}
double q_state = reward[current_state][action] + lr * max(future_rewards);
q_matrix[current_state][action] = q_state;
current_state = next_state;
}
}
int q_i, q_j;
for (q_i = 0; q_i < 4; q_i++)
{
for (q_j = 0; q_j < 5; q_j++)
{
printf("%f.2", q_matrix[q_i][q_j]);
}
printf("\n");
}
system("pause");
return 0;
}
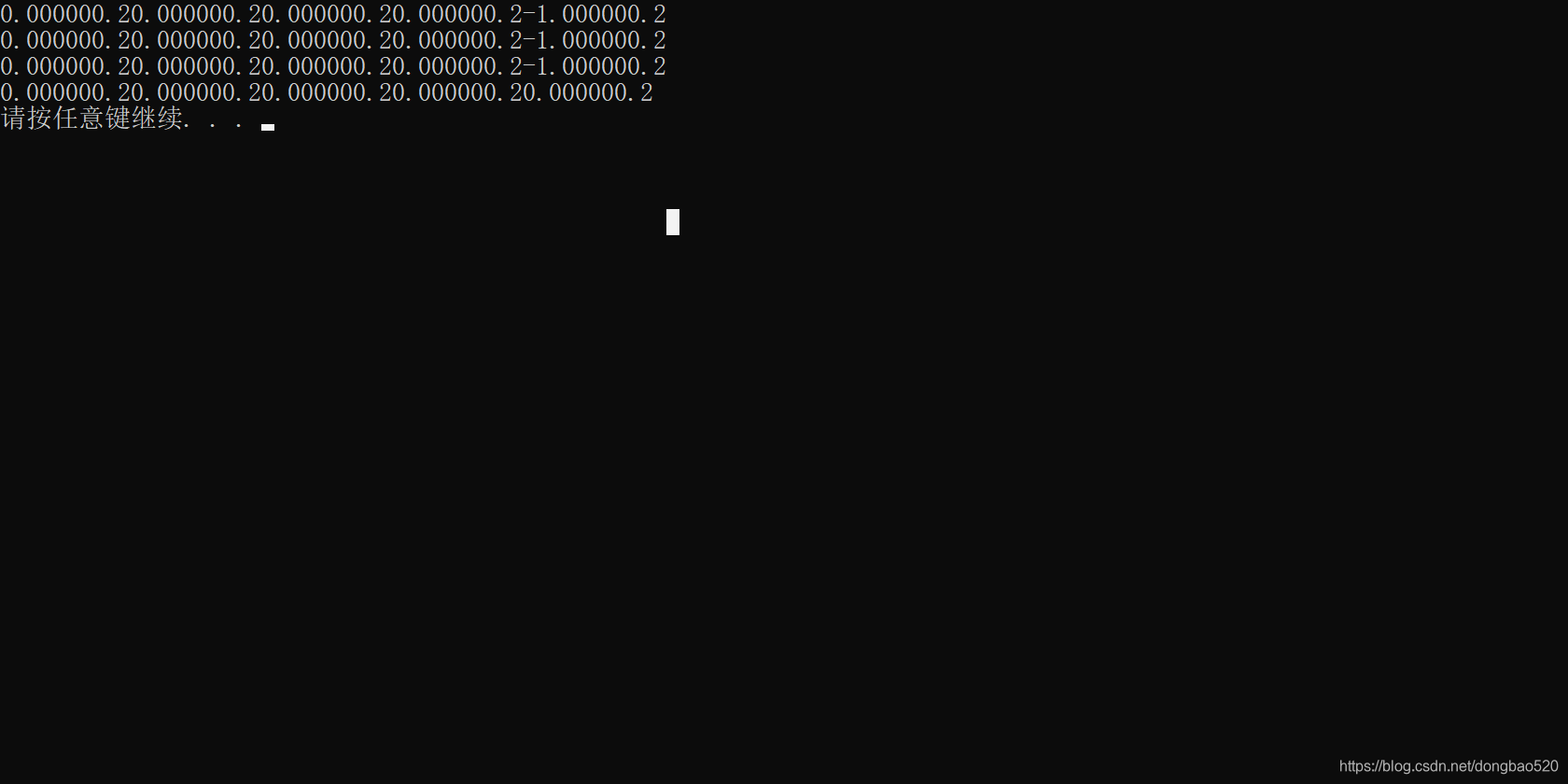
效果如下图:
0.000000.20.000000.20.000000.2-1.000000.2-1.000000.2
0.000000.20.000000.2-1.700000.20.000000.2-1.000000.2
0.000000.20.000000.20.000000.20.000000.2-1.000000.2
0.000000.20.000000.20.000000.20.000000.20.000000.2
请按任意键继续. . .

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)