matlab数据统计和分析
平均值(或均值,数学期望):xˉ=1n∑i=1nxi\bar{x}=\frac{1}{n}\sum_{i=1}^n{x_i}xˉ=n1i=1∑nxi式中,x表示统计中的样本。中位数:将数据由小到大排序后居于中间位置的那个数值平均值中位数标准差是各个数据与均值偏离程度的度量,其定义为:s=[1n−1∑i=1n(Xi−Xˉ)2]s=\sqrt{\left[ \frac{1}{n-1}\sum_{
matlab数据统计和分析
常用统计量
1.表示位置的统计量——平均值和中位数
平均值(或均值,数学期望):
x ˉ = 1 n ∑ i = 1 n x i \bar{x}=\frac{1}{n}\sum_{i=1}^n{x_i} xˉ=n1i=1∑nxi
式中,x表示统计中的样本。
中位数:将数据由小到大排序后居于中间位置的那个数值
- mean(a,dim)——默认是求每一列的平均值,dim=1给出每一列的平均值,dim=2表示给出每一行的平均值,
- median(a,dim),默认是求每一列的中位数,dim=1给出每一列的中位数,dim=2表示给出每一行的中位数,
A=[1:5;2:6;3:7]
b=mean(A,1)%求每一列的平均值
c=mean(A,2)%求每一行的平均值
d=median(A,1)
e=median(A,2)
平均值
中位数
2.表示变异程度的统计量——标准差、方差和极差
标准差是各个数据与均值偏离程度的度量,其定义为:
s = [ 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 ] s=\sqrt{\left[ \frac{1}{n-1}\sum_{i=1}^n{\left( X_i-\bar{X} \right) ^2} \right]} s=[n−11i=1∑n(Xi−Xˉ)2]
其中X表示统计中的样本
方差:标准差的平方
极差:样本中最大值与最小值之差
matlab求解方差和标准差的函数分别是var(x)和std(x)
A=[1:5;2:6;3:7]
var(A)%返回每一列的方差,自由度为(n-1)
var(A,1)%自由度为n
std(A)%求每一列的标准差

3. 表示分布形状统计量——偏度和峰度
偏度:
g 1 = 1 s 3 ∑ i = 1 n ( X i − X ˉ ) 3 g_1=\frac{1}{s^3}\sum_{i=1}^n{\left( X_i-\bar{X} \right) ^3} g1=s31i=1∑n(Xi−Xˉ)3
偏度反映分布的对称性,可以看出偏度可正可负,如果偏度大于0那么就是右偏态,否则是左偏态
峰度:
g 2 = 1 s 4 ∑ i = 1 n ( X i − X ˉ ) 4 g_2=\frac{1}{s^4}\sum_{i=1}^n{\left( X_i-\bar{X} \right) ^4} g2=s41i=1∑n(Xi−Xˉ)4
峰度是分布形状的另外一种度量,正态分布的峰度为3,若 g 2 g_2 g2比3大很多,可近似说明不是正态分布
在matlab中,可以使用jbtest函数进行Jarque-Bera检验,测试数据对正态分布的偏离程度
若输出h=1,则可说明在0.05的显著性水平下不是正态分布
data=[10,11,12,13,14,15,16,78,19,20,20,20,20,20, 11,12,13,14, 15,12,12,12,12,12,12,11,13]
[H,P]=jbtest(data)%输出h值和p值

即不服从正态分布
随即数的生成
1.二项分布随机数
- binord(N,P,m,n)——n,p是二项分布的两个参数,m,n是生成矩阵的行和列
某射击手进行设计比赛,假设每枪射击命中率,每轮射击 10 次,共进行 10 万轮。 用直方图表示这 10 万轮每轮命中成绩的可能情况。 \text{某射击手进行设计比赛,假设每枪射击命中率,每轮射击}10\text{次,共进行}10\text{万轮。} \\ \text{用直方图表示这}10\text{万轮每轮命中成绩的可能情况。} 某射击手进行设计比赛,假设每枪射击命中率,每轮射击10次,共进行10万轮。用直方图表示这10万轮每轮命中成绩的可能情况。
x=binornd(10,0.45,100000,1);
hist(x,11)
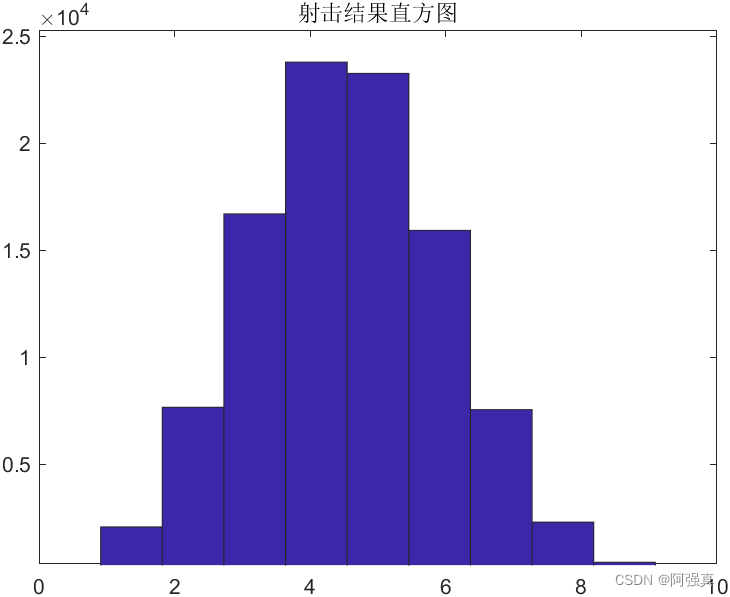
由此可知,该射击员最有可能命中4环
2.泊松分布随机数
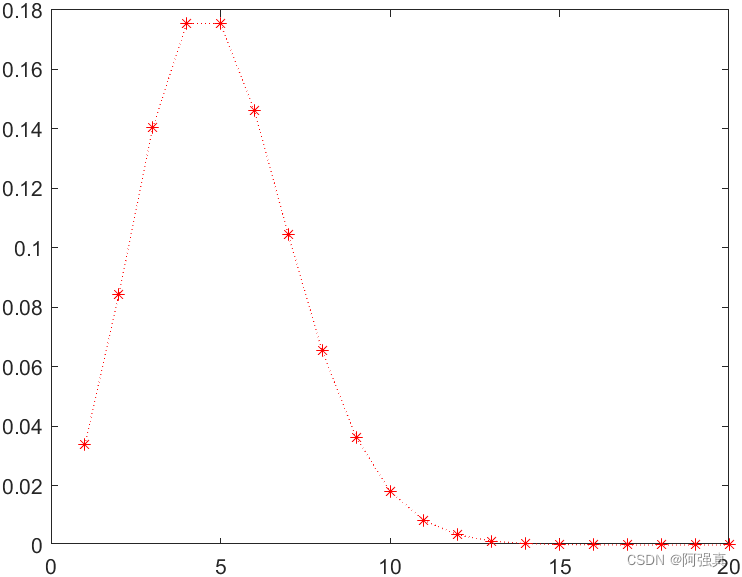
泊松分布表达式为:
f ( x ∣ β ) = λ x x ! e − λ , x = 0 , 1 , . . . , ∞ f\left( x|\beta \right) =\frac{\lambda ^x}{x!}e^{-\lambda},x=0,1,...,\infty f(x∣β)=x!λxe−λ,x=0,1,...,∞
x=1:20
y=poisspdf(x,5)%产生20个随机数
plot(x,y,":r*")%画概率密度函数图
3.均匀分布随机数
*unifrnd(A,B)以A为上限,B为下限生成均匀分布随机数
unifrnd(10,20)

4.正态分布随机数
*使用normrnd(mu,sigma)函数可以生成正态分布随机数,其中mu是均值,sigma是标准差
normrnd(3,2,3,3)

假设检验
1.方差已知时均值的假设检验
在给定方差的条件下,可以使用ztest函数来检验单样本数据是否服从给定均值的正态分布。
ztest(x,m,sigma,alpha,tail),tail=0是双侧,等于-1和1是单侧
某工厂随机选取的8只零部件的装配时间如下:
12.1478 , 11.3194 , 18.1945 ,19.3617 , 15.7478 , 17.3202 , 19.1669 ,19.5776
假设装配时间的总体服从正态分布,标准差为3.24,请检测装配时间的均值与15有无明显差异
m=[ 12.1478 , 11.3194 , 18.1945 ,19.3617 , 15.7478 , 17.3202 , 19.1669 ,19.5776]
ztest(m,14,3.24,0.05,0)

输出结果为1,即可以得出在0.05的显著性水平下,装配时间的均值不等于15
2.方差已知时均值的假设检验
*ttest(x,m,alpha,tail)
假设某种电子元件的寿命X服从正态分布,且均值和方差未知。现在获取10只元件的寿命如下:
10.1,10.2,10.11,10.33,10.44,10.55,10.66,10.12,10.31,10.15
请判断平均寿命与10是否有显著差异
m=[10.1,10.2,10.11,10.33,10.44,10.55,10.66,10.12,10.31,10.15]
ttest(m,10)

同样拒绝原假设,即有显著差异

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)