依据imu姿态角计算z轴倾角_[姿态估计] DenseFusion详解
今天分享一篇关于6D姿态估计任务的paper:《DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion》来源于CVPR2019,作者李飞飞等人。DenseFusion的主要思路:1. RGB数据和点云数据是位于不同特征空间中的异构数据,因此DenseFusion使用了一个异构网络去分别处理这两种数据,同时保留了这两种数据本身

今天分享一篇关于6D姿态估计任务的paper:
《DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion》
来源于CVPR2019,作者李飞飞等人。
DenseFusion的主要思路:
1. RGB数据和点云数据是位于不同特征空间中的异构数据,因此DenseFusion使用了一个异构网络去分别处理这两种数据,同时保留了这两种数据本身的结构。
2. 设计了一种稠密(dense)的像素级融合方式,将RGB数据的特征和点云的特征以一种更合适的方式进行了整合。
3. 设计了一种可微分、可迭代的refine模块,可以代替传统方式中的离线后处理方法(如ICP),由于其具有可微分性,因此,该模块可与整体网络联合训练优化,提供端到端的workflow,提高模型运行的实时性。
这里的姿态估计是基于相机坐标系下的。描述姿态估计的目标变量为[R|t]。其中,R表示旋转,用旋转向量来描述(欧拉角有周期性和方向锁的问题,四元数有单位向量的约束,旋转矩阵冗余度太高且有各个基需要是单位正交的约束);t表示平移,用平移向量来描述。R和t均采用无约束的向量进行描述,于是也均可以通过网络的学习来得到。因为R和t共有六个自由度,因此姿态估计又称为6D姿态估计。
注:旋转向量的方向代表旋转轴,模长代表旋转角的大小,旋转方向为逆时针。
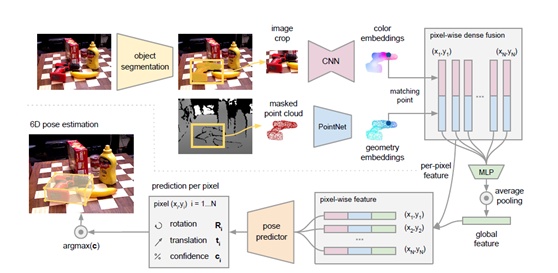
DenseFusion的整体网络架构可以分成两个stage:
第一个stage:
对RGB图像进行语义分割,并将各个mask所对应的点云、以及通过其bbox裁剪出来的RGB图像(RGB crop)提取出来,送入第二个stage。
第二个stage:
使用一个全卷积网络,将RGB crop中的每个像素点映射到颜色特征空间;
使用一个基于PointNet的网络,将mask对应的点云中的每个点映射到几何特征空间;
基于一个无监督的置信度分数,将颜色特征空间和几何特征空间中的特征点融合,并输出一个6D姿态估计;
利用一种迭代式refine方法,以循环学习的方式,训练整个神经网络,同时迭代地优化估计姿态的结果。
其中的一些细节:
- 网络中的语义分割模块使用了encoder-decoder结构,得到channel数为“类别数+1”的输出。1代表背景。
2. 在进行像素级分类的时候,采用的encoding方式为one-hot encoding。因此输出的对应各个channel的seg map,都是binary的mask。
3. 将mask对应的像素点映射到点云上的点有两种方法:
(1) 若是有序点云,则点云点的index可通过RGB像素点在图像按行flatten的单行像素点中的index来得到:
点云点index = 图片cols * 像素点row_index + 像素点col_index
然后根据点云点的index,可以索引到点云点的x,y,z值。
(2) 若是无序点云,则点云点的x,y,z值,可以通过相机内参来获得:
点云点的坐标值为相机坐标系中的坐标值,而RGB像素点的坐标值为图像坐标系中的坐标值。两者之间的转换可由相机的内参矩阵来完成。
4. 本文的一个观点:
虽然在RGBD数据中,RGB数据与Depth数据有着相仿的格式(r,g,b和x,y,z),但是两者本身的属性拥有不同的内在关联结构,其代表的信息位于不同的特征空间中。所以不适应以相同的方式统一进行处理(如将Depth当做RGB的额外channel信息,两者一起提取特征之类)。
DenseFusion的创新点,也就是其名字的来历,是它改变了传统的RGB-D特征的融合方式。
对于一个目标区域,传统的特征融合的方式是直接从dense color and depth feature中提取出一个全局特征。
该方式会受到目标遮掩(occlusion)、语义分割结果不准确的影响,从而导致提取到的全局特征还包括了非目标物体的特征,以及来自背景的特征,使融合后的特征准确度下降,利用该特征进行姿态估计的性能也发生退化。
而DenseFusion又是怎么做的呢?
1. 使用稠密的像素级融合:即对于每个RGB像素点的color feature,与跟它对应的点云点(利用相机内参计算对应点)的depth feature,进行channel上的拼接,得到一组fused feature。
2. 将这组fused feature的一个副本,送进mlp中进行信息整合,并利用一个average pooling获得global feature。(average pooling是为了解决点云的无序性问题,它是一个对称函数,输出的数值不取决于输入变量的顺序)
3. 将global feature在channel上拼接到各个fused feature的后面。得到一组具有上下文信息的fused feature。由于其是像素级的,因此也称为dense fused feature。
得到了dense fused feature,即是得到了进行姿态估计的输入。一个fused feature会对应一个predicted pose,所以最终的输出是一组predicted pose。DenseFusion使用一种自监督的方式选择其中最优的predicted pose,即对于每个predicted pose都对应输出一个confidence score作为判断依据。网络模型对于pose的预测和confidence score的计算的学习,是通过对损失函数的设计来在训练优化中实现的。
下面有请每个predicted pose的“私人”损失函数:
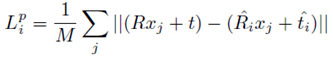
简单来说,就是最小化3D模型上的采样点在groundtruth pose下的坐标与在predicted pose下的坐标之间的欧氏距离的均值。
其中,M为在3D模型上的随机采样点的点数。对于由不同的fused feature预测出的不同pose,都有一个如上的损失函数。
一个需要注意的地方:
上述的损失函数,使用的对象为形状非对称的物体。若对象为形状对称的物体,则存在有多个不同的pose可作为解,满足该最优化问题。对于比如球型的物体,甚至存在有无限个pose可作为该最优化问题的解。
因此,对于形状对称的物体,上述的损失函数(或者说用于学习的目标函数),将变得模棱两可。这不利于网络的训练。
于是,在DenseFusion中,对于形状对称的物体,使用了另一个损失函数:
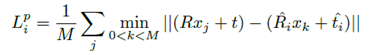
简单来说,就是对于每个在predicted pose下的3D模型采样点,都去寻找它在groundtruth pose下的3D模型采样点中的最近点,并计算这对采样点之间的距离,最后,对这些距离的均值求最小值。
这个损失函数在优化的过程中,会逐渐使得groundtruth pose和predicted pose的model的各个对应的点都贴合在一起,最终只能收敛出一个最优值。它避免了以对称的分布去贴合物体的形状就可以成为优化目标的可行解的情况,而是需要逐点贴合才可以成为优化目标的可行解。
该损失函数在本质上有点类似ICP(但算法步骤相反),在逐次的优化(迭代)过程中,不断调整[R|t],使得各对最近点之间的距离都在逐渐减小。慢慢地从可能的错误的一对多或多对一的各对最近点对,解耦并逼近正确的一对一的各对最近点对(因为其距离之和的最小值在理论上可以取到0,而其他情况基本上都不可能取到0,除非数据的取值和分布的巧合性)。
一个补充声明:以上的损失函数,不管是针对对称形状的物体,还是针对非对称形状的物体,都是pixel-wise的。
由于一个predicted pose对应一个confidence score,因此confidence score也是pixel-wise的。同时,confidence score与predicted pose之间又存在一个平衡关系,即:每个predicted pose所对应的confidence score,其实是考虑了所有的predicted pose之后得出的。
在DenseFusion中,将各个predicted pose 的confidence score作为其自身误差函数的权重,并加上一个对该confidence score的regularization term,在所有的predicted pose上求均值,作为总误差函数,从而让网络模型学习到这种平衡关系。
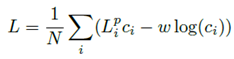
其中N为在dense fused feature中的采样数,P为fused feature的个数,w为一个超参数,用于控制上述的平衡关系。
一个误差函数,其实也可以看作是一个惩罚函数。对于上述的总误差函数而言,虽然低confidence score会导致其对应的predicted pose的误差函数值在总误差函数值中的贡献变小,但是confidence score的regularization term会给予这种低confidence score较高的惩罚。在网络模型进行预测任务时,confidence score最高的一个predicted pose将会被输出,作为最终的估计姿态。
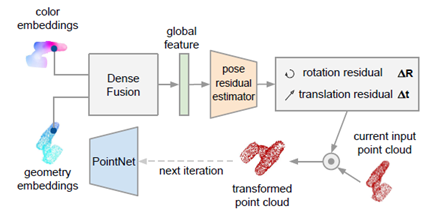
到了这一步,主体网络预测出来的pose依然只是一个coarse result。因此,老一套pipeline管上,即refinement,将输出的predicted pose进行微调,得到更精确的estimated pose。这是DenseFusion在结构上的又一个创新点,一个即可以jointly train,又可以online refine的模块。该模块的workflow具体如下:
1. 通过DenseFusion的主体模块(姿态估计网络)预测出物体的一个pose
2. 将该pose作用于物体的点云上,得到一个pose初始化后的点云
3. 将该完成pose初始化的点云作为本次迭代的输入,通过PointNet,更新原本物体点云的几何特征,并与无需更新的颜色特征进行稠密特征融合,得到dense fused feature
4. 将所有的fused feature利用MLP提取出global feature,并把该global feature送进pose residual estimator中,计算出R和t的residual。这个pose residual estimator本质上也是一个MLP(由4个全连接层组成)
5. 将上一步得到的R和t的residual应用于作为本次迭代输入的点云上,得到的完成pose微调的点云即为本次迭代的输出
6. 将本次迭代输出的点云,作为下一次迭代的输入,如此往复
7. 当达到迭代条件时,迭代终止(一般使用的迭代条件有迭代次数、相邻迭代的R和t的residual的大小等)
对于refine模块的一点额外说明/tips:
- 利用DenseFusion的主体模块预测出的pose为以上的迭代过程中物体的初始化pose,此后利用refine模块预测出的pose residual是叠加在其上的微调量。
- 由于初始化pose的质量会严重影响最终的姿态估计结果,因此,在联合训练优化DenseFusion的主体模块和refine模块的时候,要首先单独地将主体模块给训练至收敛,以保证其提供的初始化pose中不包含过多的噪声,进而使后续的微调失去意义。
码字不易,如果您觉得本文对您有所帮助,请不吝点个赞吧 ^_^

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)