经济数学基础小抄_【计量经济学笔记】基础数学知识
目录:
二次型
随机变量的数字特征(矩、期望、方差、偏度、峰度、协方差)
迭代期望定律(条件分布、迭代期望定律)
常见连续型统计分布(正态分布、卡方分布、t分布、F分布)
统计推断--参数估计(原理、优劣评估--系统性偏差&抽样偏差)
二次型
二次型是一个二次齐次多项式函数,计量经济学中二次型是用于计量距离的,即一个向量与某个向量的距离,中间的二次型矩阵其实是赋权重的。
关于二次型矩阵A有几点:
1.二次型矩阵A是一个对称矩阵。
2.二次型>0,称A为正定矩阵;二次型<0,A为负定矩阵;二次型≥0,A为半正定矩阵;二次型≤0,A为半负定矩阵;二次型不确定符号,A为不定矩阵。
3.如果A是正定矩阵,那么它可以通过线性变换转换为一个,主对角线元素全正的,对角矩阵。对角线元素正好是它的特征值。

计量中常用的二次型矩阵是随机向量X的协方差矩阵的逆矩阵。
以Var(X)的逆为权重,将X到0向量的距离标准化(避免受到X度量单位的影响)。可以在一维向量角度下理解,其实就是x离远点有几个标准差的距离。

随机变量的数字特征
这里是讲期望、方差等指标。期望就是一个变量取值的加权平均,权重是某个取值的概率。
先来讲一个概念:矩(moment)。
矩就是,任何一个变量的函数的,期望。
原点矩就是(X-0)的期望,n阶原点矩就是(X-0)的n次方的期望,这里的函数就是(X-0)。
中心距是(X-E(X))的期望,中心就是X的均值,也就是X的期望,n阶中心距就是(X-E(X))的n次方的期望,这里的函数是(X-E(X))。
求这些矩,就是求一个期望,就是一个加权平均,对这些函数的取值的加权平均,那这些函数的取值的概率,其实就是X的概率,也就是f(x)(这里讲的连续型变量)。
接下来看常用的一些数字特征
原点矩里,一阶原点矩就是变量的期望。
中心距里,一阶中心距是0,二阶中心距是方差(反映变量分布的波动程度),三阶中心距是偏度(反映变量分布的对称程度),四阶中心距是峰度(反映变量分布的最高处有多“尖”以及尾部有多“厚”)。
偏度和峰度的值会受到变量度量单位的影响,可以用他们的标准差来标准化,也就是除以其标准差。
对于两个变量的相关性的判断,用到的是协方差。协方差也受到度量单位影响,所以其标准化其实就是,除以两个变量的标准差的乘积。
对于协方差的解释:如果当X的取值大于它的期望时,Y也倾向于大于Y的期望,那么二者是正相关的,反之则是负相关的。如果协方差为0,那么就是一个变量的取值不会受到另一个变量的影响,二者是“线性不相关”的。

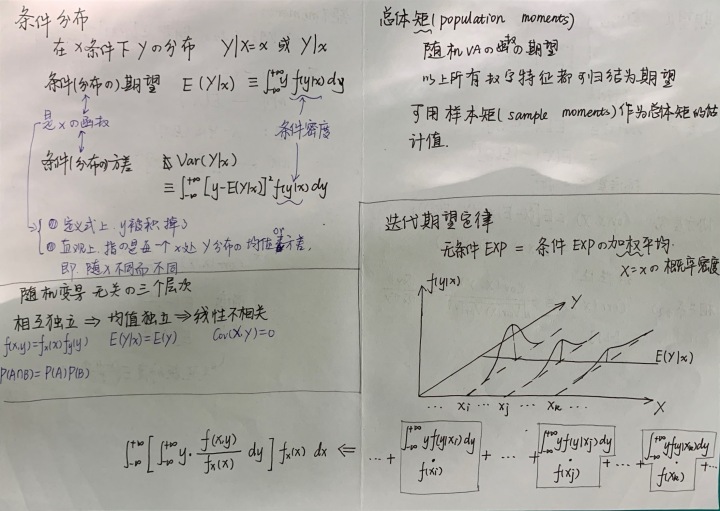
迭代期望定律
条件分布
我们说的X的分布,就是X的有什么样的取值、取值概率如何。
条件分布是在某条件下的一个变量的分布。也就是理解为,当X=x时,Y有什么样的取值、取值概率如何。
条件(分布的)期望就是在一个确定的X的取值x下,Y的取值的整体倾向,这其实是一个确定的值,而这个值因为X的取值x的不同而不同,也就是,Y的条件期望是x的函数。
迭代期望定律
Y的无条件期望=Y的条件期望的加权平均。
权重是X=x的概率密度。
常用连续型统计分布
正态分布,卡方分布,t分布,F分布。
正态分布的平方是自由度为1的卡方分布,t分布的平方是自由度为(1,k)的F分布。

统计推断--参数估计--点估计
统计推断是计量的主要方法。因为总体往往很大,如果要求得总体的特征,做一个完整的数据统计是不现实的,所以用样本的数据统计来推断总体。(联系前面,就可以用样本的矩来估计总体的矩)
- 这里讲的是统计推断的参数估计。
原理:从总体中抽取容量为n的样本数据,以此设计一个函数来估计总体中的参数。
这个设计出来的函数叫做估计量,它是一个函数,只有当样本的具体数据给定了,求出来的才是一个数值,叫做估计值。
- 那么既然原则上讲,任何函数形式都可以作为估计量,那就要进行优劣评估,选出最合适的估计量。
首先,估计量要没有系统性偏差。
也就是,估计量的取值的倾向要跟总体待估计的那个参数一样。这个“取值倾向”其实就是期望。当估计量的期望=总体参数时,这个估计量就叫做“无偏估计量”,否则就是“有偏估计量”。
其次,抽样误差要尽可能小。
也就是,估计量的整体倾向跟总体参数一样的,可能有很多,但是他们的波动程度不一样,有的集中有的分散,那么如果选中了分散的那个估计量,也是不利于对总体参数作出靠谱的估计的。
系统性偏差考虑的是,估计量的总体倾向跟实际参数的差距,那抽样误差考虑的就是,这个估计量本身跟实际参数的差距。
要选择这个估计量本身跟实际参数差距最小的估计量。
这个差距是有正有负的,所以取个平方来处理,然后选择让这个平方倾向于最小的估计量,也就是这个平方的均值最小。这个平方叫做误差平方(squared error),这个均值叫做均方误差(mean squared error,MSE)。
可以证明,MSE=Var+Bias(均方误差=方差+系统性偏差),所以选择最小的抽样误差,跟最初的分析是一致的,在系统性偏差和方差中权衡,亦即在整体倾向和分布的分散程度间权衡。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)