kmeans设置中心_聚类分析:kmeans 算法簇个数的确定
·
kmeans算法是无监督聚类学习中最常见、最常用的算法之一,其基本原理如下:
1、随机初始化k个聚类中心点,并计算数据中每个点到k个点的距离;
2、将每个数据点分到距离聚类中心点最近的聚类中心中;
3、针对每个类别重新计算聚类中心;
4、重复上面的2、3步骤中,直到达到预先设置的停止条件(迭代次数、最小误差变化等)。
kmeans算法其实挺简单,但是聚类个数k应该如何的选择?目前常用有肘部法则和轮廓系数法等。肘部法则通过寻找损失值下降平稳的拐点来确定k值,而轮廓系统则是通过寻找轮廓系数的最大值来进行计算:
肘部法则SSE(误差平方和):
轮廓系数:
通过Python模拟数据,应用kmeans,分别通过肘部法则和轮廓系数选择相应的k值
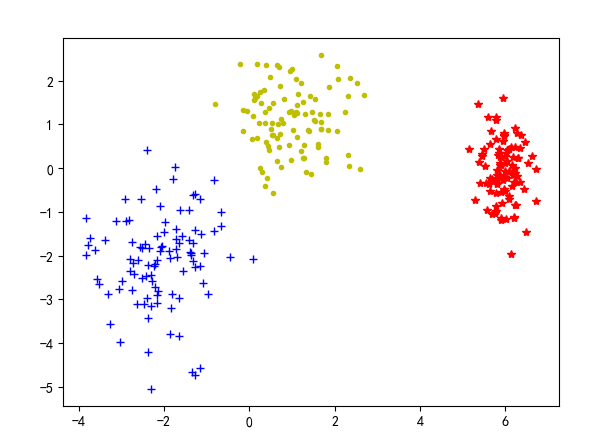
import 随机产生的数据如下图所示:
应用肘部法则来选择相应的k值
#应用肘部法则确定 kmeans方法中的k
k值与sse的走势关系如下图所示:
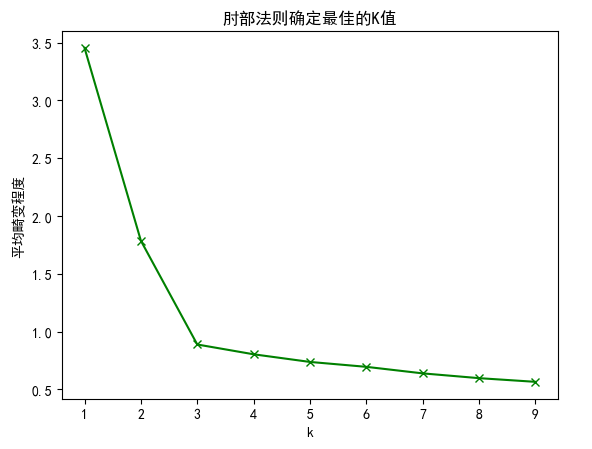
从图中可以明显的看出k在3之后减小的幅度变缓,这说明当k=3之后,如果在增加聚类的类别效果提高不是十分明显,由此可以确认此批数据的k应该取3.
应用轮廓系数确定k
from 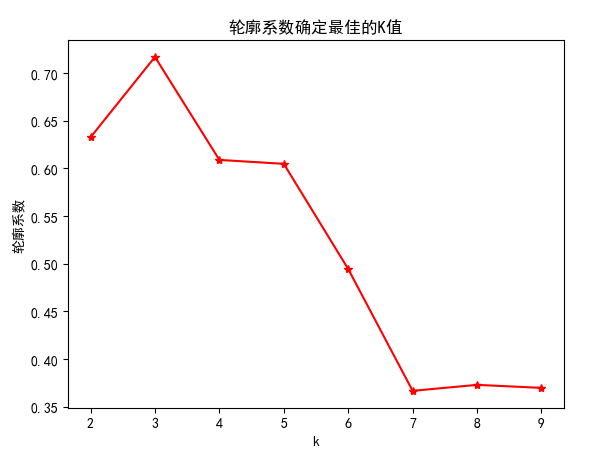
由上图可以看出当k=3值轮廓系数达到最大值,此时的聚类效果最好,因此k应该选择3。
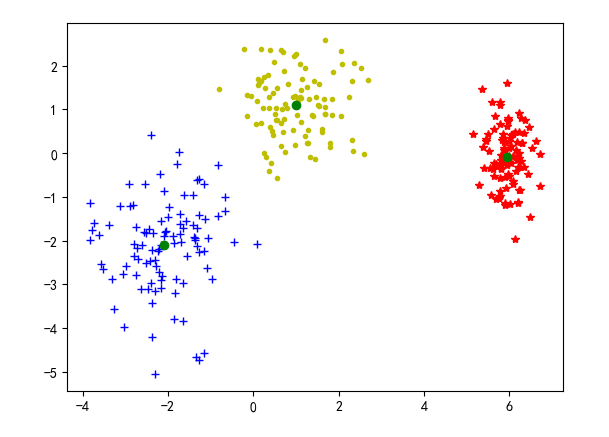
可以看一下当k=3时聚类中心与样本点的分布情况,选取的聚类中心还是挺准确的。因为是模拟产生的数据,所有聚类效果异常的好,但是在实际的应用中一般不会有这么好的聚类效果 的。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)