Python聚类分析
消费群体画像LRFM_基于K-means聚类分析
开始构建LRFM模型,其中
L:客户生命周期,表示客户最后一次购买与第一次购买的时间之差,该指标可以揭示客户与品牌或超市之间的长期关系以及客户的忠诚度
R:最近一次消费 (Recency):天。表示用户最近是否活跃,时间越新鲜越好,若R时间过去太久可能用户已流失
F:消费频率 (Frequency):频率越高 说明用户忠诚度越高
M:消费金额 (Monetary):金额越大说明用户为重要用户
一般的价值模型只有RFM,关于引入L的进一步含义:'客户生命周期'越长,说明客户与商家之间的关系越持久,一般意味着客户对产品或者商家较高的满意度和信任,且存在较高的复购概率。
通过对不同生命周期客户群体的划分,更长周期的客户提供增值服务,较短周期的客户加强营销推广,能够进一步的优化营销策略,进而实现更大的商业价值。
-
数据标准化: 使用Z-score标准化消除量纲差异: $$ z = \frac{x - \mu}{\sigma} $$
二、K-means聚类流程
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 数据预处理
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df[['L', 'R', 'F', 'M']])
# 确定最佳K值(肘部法则)
wcss = []
for k in range(1, 11):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(scaled_data)
wcss.append(kmeans.inertia_)
plt.plot(range(1,11), wcss, marker='o')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()
# 选择K=4进行聚类
kmeans = KMeans(n_clusters=4, random_state=42)
clusters = kmeans.fit_predict(scaled_data)
三、群体画像分析
| 群体类型 | L特征 | R特征 | F特征 | M特征 | 营销策略 |
|---|---|---|---|---|---|
| 高价值客户 | 长 | 短 | 高 | 高 | VIP专属权益 |
| 潜力客户 | 中 | 中 | 中 | 中 | 精准促销激活 |
| 流失风险客户 | 长 | 长 | 低 | 低 | 召回活动设计 |
| 新客户 | 短 | 短 | 低 | 低 | 培育计划实施 |
四、注意事项
- 数据预处理:需处理缺失值和异常值(如$M>3\sigma$的离群点)
- 变量相关性:检查指标间相关性(如$F$与$M$的Pearson相关系数)
- 结果验证:建议结合轮廓系数评估聚类质量: $$ s = \frac{b - a}{\max(a,b)} $$ 其中$a$为样本到同簇其他点的平均距离,$b$为样本到最近其他簇的平均距离
五、可视化呈现
import seaborn as sns
# 雷达图可视化群体特征
agg_df = df.groupby('Cluster').mean().reset_index()
melt_df = pd.melt(agg_df, id_vars='Cluster')
plt.figure(figsize=(10,6))
sns.lineplot(x='variable', y='value', hue='Cluster', data=melt_df, marker='o')
plt.ylim(0,1)
plt.title('LRFM群体特征雷达图')
plt.show()
绘制客户特征雷达图
r = pd.DataFrame(best_kmeans.cluster_centers_) # 聚类中心
labels = np.array(['M', 'F', 'R', 'L'])
labels = np.concatenate((labels, [labels[0]])) # 闭合标签
# 聚类数量
N = len(r) + 1 # 聚类数量,加1以闭合雷达图
angles = np.linspace(0, 2 * np.pi, N, endpoint=False) # 均匀分布的角度
data = pd.concat([r, r.iloc[:, 0]], axis=1) # 聚类中心数据并闭合图形
angles = np.concatenate((angles, [angles[0]])) # 闭合角度
# 创建雷达图
fig = plt.figure(figsize=(8, 8)) # 增加图形尺寸
ax = fig.add_subplot(111, polar=True)
colors = ['#FF69B4', '#87CEEB', '#800080', '#32CD32', '#FFD700']
line_styles = ['-', '--', '-.', ':', '-']
# 绘制每个聚类的雷达图
for i in range(len(r)):
ax.plot(angles, data.loc[i, :], linewidth=2, linestyle=line_styles[i % len(line_styles)], label=f"客户群 {i}", color=colors[i % len(colors)]) # 添加样式和颜色
ax.fill(angles, data.loc[i, :], color=colors[i % len(colors)], alpha=0.25) # 为每个聚类区域添加填充色
ax.set_thetagrids(angles * 180 / np.pi, labels, fontsize=12) # 增加字体大小
ax.grid(True, color='gray', linestyle='-', linewidth=0.5, alpha=0.5) # 调整网格线的透明度
plt.title(u'客户特征雷达图', fontsize=16, pad=20)
plt.legend(loc='lower right', fontsize=12)
plt.show()
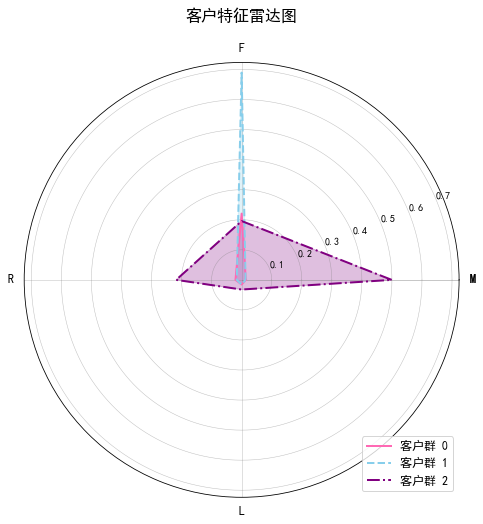
从雷达图可以看出,客户群体2的指标都很低,偏向于F指标。客户群体1偏向F指标,客户群体0偏向FM指标
因此可以根据箱线图和雷达图将消费群体划分为三个类群:
L高,R高,F低,M高 重要客户
L低,R低,F高,M低 潜在客户
L低,R低,F低,M低 一般客户
重要客户:已经有较长的消费历史,最近有光顾,表明他们对产品或服务有持续兴趣。光顾频次不高,但是消费金额很高,表明每次购买时倾向于选择高价值商品。
策略:
1.针对这类客户,可以通过忠诚度计划、VIP会员奖励等方式进一步增强他们的忠诚感,确保他们继续光顾。
2.基于他们的消费历史和高额消费,可以推荐相关的高价值产品,增加他们的购买频次。
3.为这些重要客户提供专属的优惠、折扣或客户服务(例如专属客服、生日礼包等),增加他们的满意度和粘性。
4.尽管他们的光顾频次不高,可以通过定期的邮件营销或电话跟进,提醒特定产品的新品或促销活动。
潜在客户:客户生命周期较短,最近光顾时间较久,可能代表他们已经有一段时间没有与品牌互动,虽然频繁光顾,但每次的消费金额较低,可能更多是购买低价商品。
策略:
1.通过推送促销活动、优惠券或折扣,刺激这类客户回归并进行复购。可以提供一些小额产品或折扣,以促使他们增加单次消费金额。
2.提供一些会员特权(如积分、专属折扣等),鼓励他们在未来增加购买频率并提升消费金额。
一般客户:客户生命周期较短,最近一次光顾的时间很久,可能表示他们已经离开或失去兴趣。每次消费金额也较低,整体贡献的收入不高。
策略:
1.提供试用、限时免费体验等活动,降低他们尝试新产品的门槛,从而提高其消费意愿。
2.优化网站或应用的购买流程,减少购物障碍,提升他们的购买体验,激励他们消费更多。
3.定期与这类客户保持联系,提供产品更新信息、活动通知等,以增强品牌记忆并促使他们增加购买频次。
总结:
重要客户:聚焦于增强忠诚度、提升复购率并提供个性化服务,最大化其长期价值。
潜在客户:通过优惠刺激其回归并增加消费,提升他们的终生价值。
一般客户:通过唤醒活动、优惠和个性化推荐,提高客户的活跃度和消费金额。
一、 数据读取
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from pyecharts.charts import *
from pyecharts import options as opts
import warnings
warnings.filterwarnings('ignore') #忽略警告信息
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
df = pd.read_excel('order2021kmeans.xlsx')
df.head()
| 订单顺序编号 | 订单号 | 用户名 | 商品编号 | 订单金额 | 付款金额 | 渠道编号 | 平台类型 | 下单时间 | 付款时间 | 是否退款 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8 | sys-2021-306447069 | user-104863 | PR000499 | 499.41 | 480.42 | 渠道1 | 微信公众号 | 2021-01-01 01:05:50 | 2021-01-01 01:06:17 | 否 |
| 1 | 11 | sys-2021-417411381 | user-181957 | PR000483 | 279.53 | 279.53 | 渠道1 | APP | 2021-01-01 01:36:17 | 2021-01-01 01:36:56 | 否 |
| 2 | 61 | sys-2021-313655292 | user-282453 | PR000154 | 1658.95 | 1653.91 | 渠道1 | 微信公众号 | 2021-01-01 12:01:04 | 2021-01-01 12:03:20 | 否 |
| 3 | 78 | sys-2021-311884106 | user-167776 | PR000215 | 343.25 | 337.12 | 渠道1 | APP | 2021-01-01 12:47:02 | 2021-01-01 12:47:21 | 否 |
| 4 | 81 | sys-2021-375273222 | user-138024 | PR000515 | 329.04 | 329.04 | 渠道1 | APP | 2021-01-01 12:50:23 | 2021-01-01 12:50:50 | 否 |
二、数据预处理
#查看一下数据的整体信息以及缺失值和重复值 df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 104557 entries, 0 to 104556 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 订单顺序编号 104557 non-null int64 1 订单号 104557 non-null object 2 用户名 104557 non-null object 3 商品编号 104557 non-null object 4 订单金额 104557 non-null float64 5 付款金额 104557 non-null float64 6 渠道编号 104549 non-null object 7 平台类型 104557 non-null object 8 下单时间 104557 non-null datetime64[ns] 9 付款时间 104557 non-null datetime64[ns] 10 是否退款 104557 non-null object dtypes: datetime64[ns](2), float64(2), int64(1), object(6) memory usage: 8.8+ MB
# 删除重复值 df.duplicated().sum()
0
df.columns = df.columns.str.strip()
#查看数据分布 df.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| 订单顺序编号 | 104557.0 | 52279.000000 | 30183.150385 | 1.00 | 26140.00 | 52279.00 | 78418.00 | 104557.000000 |
| 订单金额 | 104557.0 | 1049.681521 | 1054.409968 | 6.10 | 432.04 | 679.32 | 1248.28 | 28465.250000 |
| 付款金额 | 104557.0 | 1167.494225 | 2174.024855 | -12.47 | 383.66 | 641.23 | 1252.63 | 83270.053829 |
#去除退款用户数据 data = df[df['是否退款']=='否'] data.head()
| 订单顺序编号 | 订单号 | 用户名 | 商品编号 | 订单金额 | 付款金额 | 渠道编号 | 平台类型 | 下单时间 | 付款时间 | 是否退款 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8 | sys-2021-306447069 | user-104863 | PR000499 | 499.41 | 480.42 | 渠道1 | 微信公众号 | 2021-01-01 01:05:50 | 2021-01-01 01:06:17 | 否 |
| 1 | 11 | sys-2021-417411381 | user-181957 | PR000483 | 279.53 | 279.53 | 渠道1 | APP | 2021-01-01 01:36:17 | 2021-01-01 01:36:56 | 否 |
| 2 | 61 | sys-2021-313655292 | user-282453 | PR000154 | 1658.95 | 1653.91 | 渠道1 | 微信公众号 | 2021-01-01 12:01:04 | 2021-01-01 12:03:20 | 否 |
| 3 | 78 | sys-2021-311884106 | user-167776 | PR000215 | 343.25 | 337.12 | 渠道1 | APP | 2021-01-01 12:47:02 | 2021-01-01 12:47:21 | 否 |
| 4 | 81 | sys-2021-375273222 | user-138024 | PR000515 | 329.04 | 329.04 | 渠道1 | APP | 2021-01-01 12:50:23 | 2021-01-01 12:50:50 | 否 |
# 查看异常值 len(data[data['订单金额']<0])#订单金额小于0元则为异常值
0
# 查看异常值 len(data[data['付款金额']<0])#付款金额小于0元则为异常值
5
#付款金额存在负值的情况,处理办法是将其转化为正值 data['付款金额'] = data['付款金额'].abs() len(data[data['付款金额']<0])
0
三、数据可视化分析
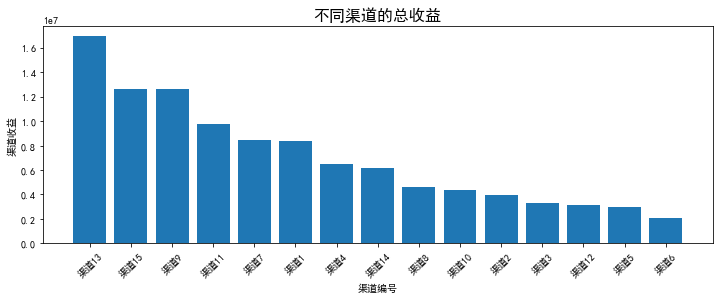
查看按渠道划分的收益
#统计不同渠道付款总额,并降序,转换成DF数据
channel_revenue=data.groupby('渠道编号')['付款金额'].sum().sort_values(ascending=False).reset_index()
#channel_revenue
#绘制柱状图
plt.figure(figsize=(12,4))
plt.title("不同渠道的总收益",fontsize=16)
plt.bar(channel_revenue['渠道编号'],channel_revenue['付款金额'])
plt.xlabel("渠道编号")
plt.ylabel("渠道收益")
plt.xticks(rotation=45)
plt.tight_layout()#自动调整子图布局
plt.show()
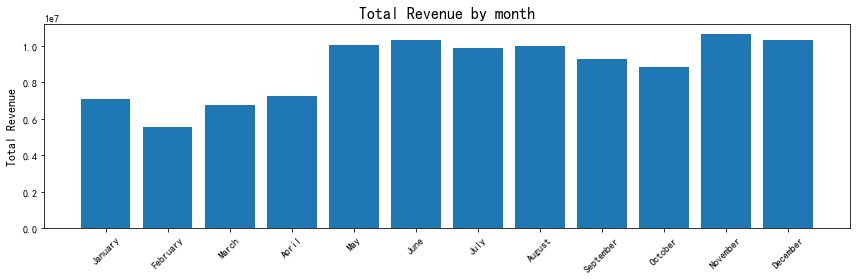
查看按月份划分的收益
#数据准备
data['付款月份'] = data['付款时间'].dt.month #提取月份
#data['付款月份'] = [i.month for i in data['付款时间']]
data['付款月份名称'] = data['付款时间'].dt.month_name() #提取月份名称
#按月份统计总收益
month_revenue = data.groupby(['付款月份', '付款月份名称'])['付款金额'].sum().reset_index()
#绘制柱状图
plt.figure(figsize=(12, 4))
plt.title("Total Revenue by month", fontsize=16)
plt.bar(month_revenue["付款月份名称"],month_revenue["付款金额"])
plt.ylabel("Total Revenue", fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.yticks(fontsize=10)
plt.tight_layout()
plt.show()
查看按每天小时划分的收益
#数据准备
data['付款小时'] =data['付款时间'].dt.hour #获取时间
data['付款天数'] = data['付款时间'].dt.day #获取天数
data['付款天数名称'] = data['付款时间'].dt.day_name()#获取时间名字
hourly_sales =data.groupby(['付款天数名称','付款小时'])['付款金额'].sum().reset_index()
hourly_sales = hourly_sales.rename(columns={'付款金额': 'TotalValue'})
hourly_sales
| 付款天数名称 | 付款小时 | TotalValue | |
|---|---|---|---|
| 0 | Friday | 0 | 3.208984e+05 |
| 1 | Friday | 1 | 1.104411e+05 |
| 2 | Friday | 2 | 9.343783e+04 |
| 3 | Friday | 3 | 1.139179e+04 |
| 4 | Friday | 4 | 5.626410e+03 |
| ... | ... | ... | ... |
| 163 | Wednesday | 19 | 1.769271e+06 |
| 164 | Wednesday | 20 | 2.354979e+06 |
| 165 | Wednesday | 21 | 1.699454e+06 |
| 166 | Wednesday | 22 | 1.063404e+06 |
| 167 | Wednesday | 23 | 5.837316e+05 |
168 rows × 3 columns
# 创建一个空列表来存储所有切分后的DataFrame
split_dfs = []
# 计算需要切分的组数
num_groups = len(hourly_sales) // 24
for i in range(num_groups):
# 每次迭代选取24行
start_index = i * 24
end_index = start_index + 24
split_df = hourly_sales.iloc[start_index:end_index]
split_dfs.append(split_df)
#查看第一个切分后的DataFrame
print(split_dfs[0])
付款天数名称 付款小时 TotalValue 0 Friday 0 3.208984e+05 1 Friday 1 1.104411e+05 2 Friday 2 9.343783e+04 3 Friday 3 1.139179e+04 4 Friday 4 5.626410e+03 5 Friday 5 5.533420e+03 6 Friday 6 1.560106e+04 7 Friday 7 6.796755e+04 8 Friday 8 1.060996e+05 9 Friday 9 2.194146e+05 10 Friday 10 3.375344e+05 11 Friday 11 6.278208e+05 12 Friday 12 1.014062e+06 13 Friday 13 1.410802e+06 14 Friday 14 1.232234e+06 15 Friday 15 7.496987e+05 16 Friday 16 7.528851e+05 17 Friday 17 8.270167e+05 18 Friday 18 1.153808e+06 19 Friday 19 2.028809e+06 20 Friday 20 2.508399e+06 21 Friday 21 1.794541e+06 22 Friday 22 1.083644e+06 23 Friday 23 5.885448e+05
# 创建折线图并绘制
name=hourly_sales['付款天数名称'].unique()
line=(
Line()
.add_xaxis(split_dfs[0]['付款小时'].astype(str).tolist()) # X轴为每个点的索引
.set_global_opts(
title_opts={"text":"每日每小时收益总额"},
legend_opts=opts.LegendOpts( #图例配置
is_show=True, # 是否显示图例
orient='vertical',#垂直显示
pos_top='5%', # 图例位置,例如顶部5%
pos_right='5%' # 图例位置,例如右侧5%
)
)
)
for i in range(num_groups):
line.add_yaxis(name[i],split_dfs[i]['TotalValue'].tolist(),label_opts=opts.LabelOpts(is_show=False))
line.render_notebook()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)