js 画树状图 如何确定各个点的位置_聚类分析:如何优雅地分类
点击下方领取大碗宽面指南:▼【导入】“五一”旅游和聚类分析【理论】那什么是聚类分析呢?【实例】中国科创城市的聚类分析五一到了,小张和小红打算去旅游。但他们还没决定去哪里...为了让问题更简单,我们假设:作为又穷又宅的学生党,小张选择目的地的依据是人流量和价格于是,小红给小张一张表格,列出了5个她想去的地方,以及对应的人流量和价格。作为上过计量经济学的普通学生,小张先是画了个散点图观察一下...
点击下方
领取大碗宽面指南:
▼
-
【导入】“五一”旅游和聚类分析
-
【理论】那什么是聚类分析呢?
-
【实例】中国科创城市的聚类分析

五一到了,
小张和小红打算去旅游。
但他们还没决定去哪里...

为了让问题更简单,我们假设:
作为又穷又宅的学生党,
小张选择目的地的依据是
人流量
和
价格
于是,
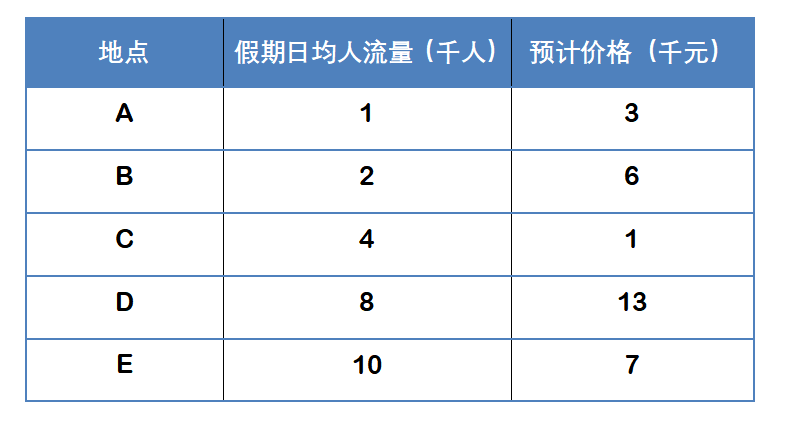
小红给小张一张表格,
列出了5个她想去的地方,
以及对应的人流量和价格。
作为上过计量经济学的普通学生,
小张先是画了个散点图观察一下:
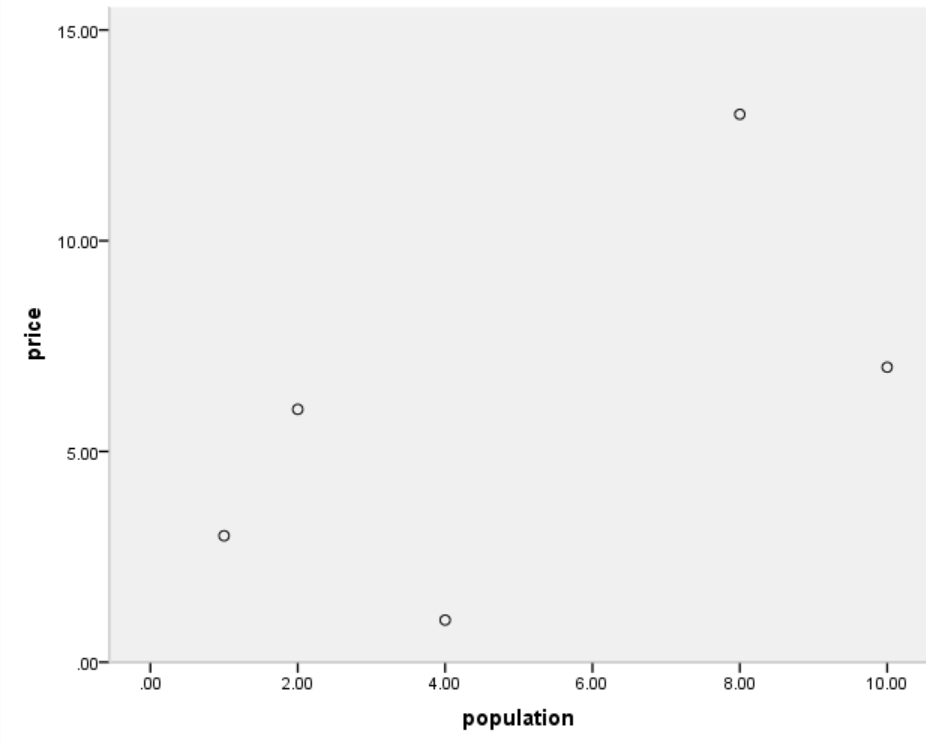
直觉告诉他,
这5个地方实际上可以简化成更简单的几类,
比如:
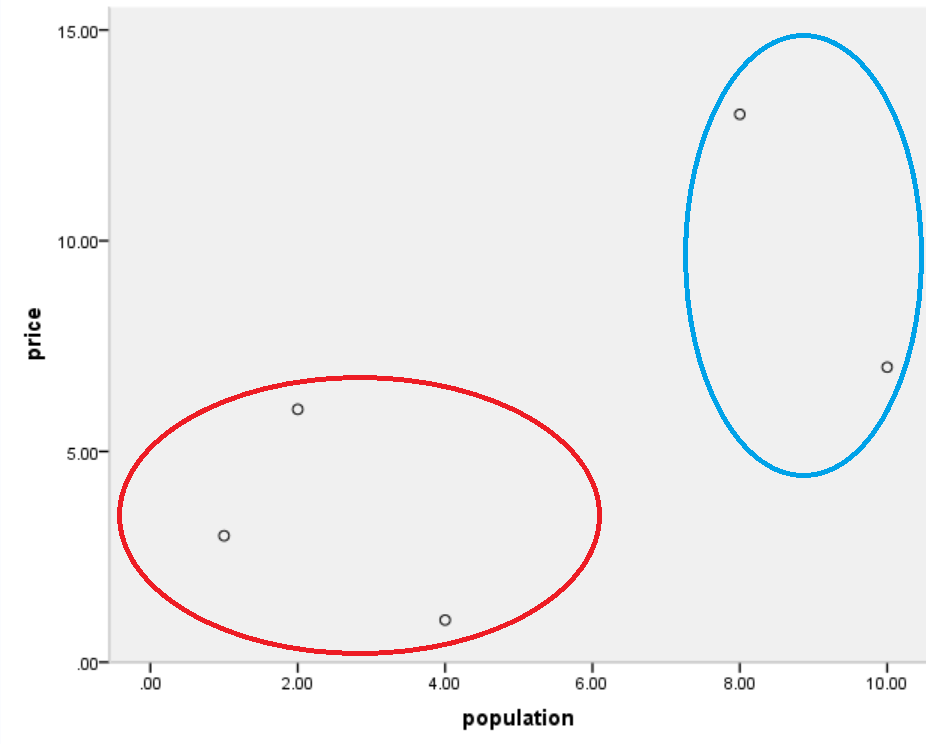
但是直觉需要更好的验证支持!
为了运营自己在小红面前的学霸人设,
小张应该怎么办呢?
他的好基友小周提醒他:
“你知道聚类分析吗?”


聚 类 分 析
在分类问题中,“类”指的是相似的元素构成的集合。
分类问题指的是如何将观测对象指定到某一个类。
可分为两种类型:
1. 【判别分析】
知道类的数目与特征,要决定将一个观测对象分入哪一个类的问题。
2. 【聚类分析】
不知道类的数目以及特征,探究分类数目与分类方法的问题。
对于聚类分析,我们更深入地将其划分为几个不同的问题类型,并介绍特定的一种分析方法。
太长不看版:
讨论对象为Q型系统聚类法,
变量均为定量变量。
在聚类分析中,我们常常会有一些样本,并且有这些样本关于若干个变量各自的观测值。
自然地,我们既可以对样本进行分类,也可以对变量进行分类;前者被称为Q型聚类分析问题,后者被称为R型聚类分析问题。
为了帮(jian)助(hua)小(wen)张(ti),我们在此仅讨论Q型聚类分析方法。

聚类分析依据聚类的方法又可以分为许多种:系统聚类法、动态聚类法、图论聚类法……
其中,系统聚类法的想法是让每个样本初始自成一类,每次将最相近的两类合并并且更新类与类之间的“距离”,直到剩余的类数满足条件为止。
为了帮助小张,我们在本文中仅讨论系统聚类方法。
对于变量,我们同样地将其分为定量变量与定性变量。由于定性变量通常仅仅表示性质上的差异,其数值大小没有意义,需要特殊处理。由此,我们在本文中讨论所涉及的变量均指定量变量。

下面介绍距离
定义方式、分类过程和分类指标
涉及一定量的公式。
只对【实例】感兴趣的同学
可以活动手指快速下滑。
我们的数据以矩阵形式进行表示:
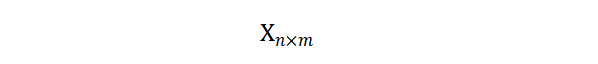
其中第 i 行代表的是第 i 个样本,第 j 列代表的是第 j 个变量的值。容易看到共有 n 个样本,m 个变量.
注意到 m 个变量可能具有不同量纲,以计量中提到的方法,我们很自然地对于矩阵的每一列进行标准化变换以消除量纲差异。
接下来的一个问题是:不同样本之间的“距离”如何定义?
第 i 个样本即为矩阵 X 的第 i 行所对应的行向量 Xi,第 j 个样本即为矩阵 X 的第 j 行所对应的行向量,我们设两个样本之间的距离为 dij。
对于数学上的距离定义,其需要满足三个性质:正定性、对称性、三角不等式。
在这里为了方便起见,我们取最熟悉的欧式距离
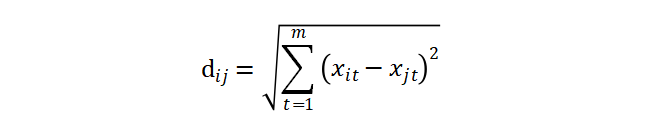
作为两个向量之间的距离的度量。
最后一个我们关心的问题是:不同的类之间的距离如何定义?
假设对于两个类,其中样本个数分别为 Gp,Gq,类间距离为 np,nq。
在此,我们介绍两种最常用的定义方式。
第一种类间距离定义为最短距离法(single linkage),即将类之间的距离定义为两个类中相距最近的元素之间的距离:
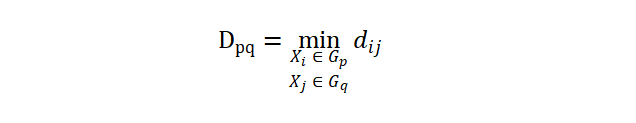
则当我们将两个类 Gp,Gq 合并为一个新类 Gr 并且按最短距离法计算其与一个其它类 Gk 之间的距离时,我们自然地有
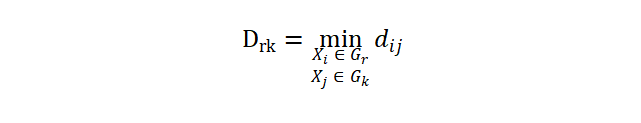
由于 Gr 由 Gp,Gq 经过合并得到,
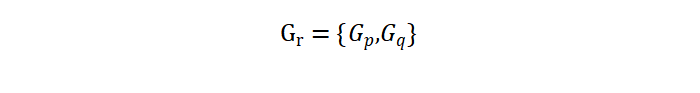
则有
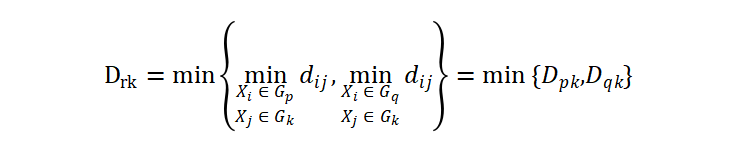
为更新类间距离时我们将用到的递推公式。
第二种类间距离的定义是类平均法(average linkage)。类平均法从两类中各取出一个样本,将其两两之间距离的平方平均数作为类间距离。
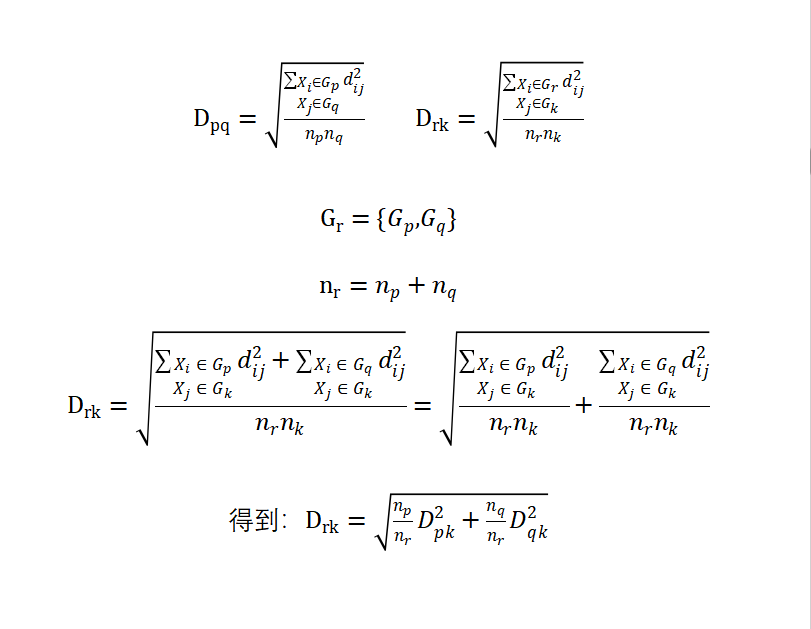
由于篇幅限制,在此不做赘述。欢迎大家找小周讨论。

由此,我们可以完整地给出系统聚类法的步骤:
1. 对每一列进行需要的数据变换(此处进行标准化变换).
2. 将每个样本单独地看成一个类。
3. 计算所有类两两之间的距离。
4. 合并类间距离最小的两个类作为新类,类的总个数减少 1。
5.更新所有类两两之间的距离矩阵,并跳至 4,直到类的个数为1后停止。
6. 根据谱系聚类图以及各种指标决定分类的个数以及类中成员。

接下来的一个问题是:
我们如何确定究竟要分为多少个类呢?
这里着重介绍指标 R^2,与OLS中的 R^2 有着异曲同工之妙。




实 例
在SPSS中,系统聚类分析输出的结果往往是一张树状图(dendrogram),其中横轴上是我们要进行分类的项目,垂直线表示将不同类分为同一类,水平线对应的刻度则是它们被分为同一类时的距离。
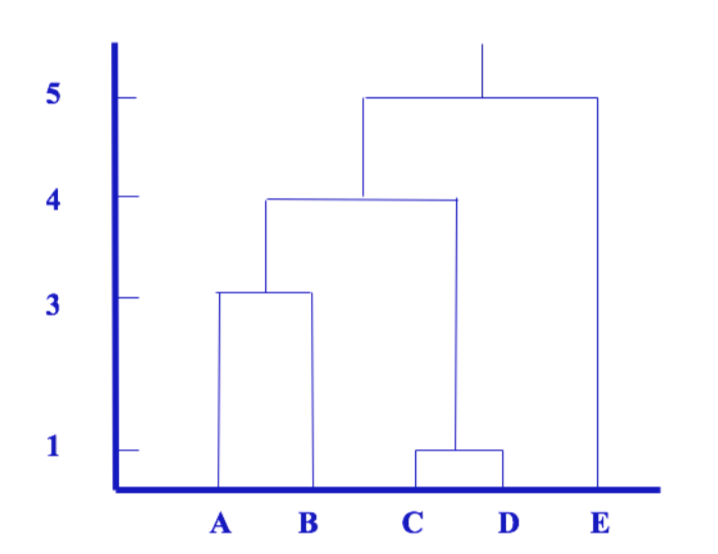
示例图
在这里,我们想要对各省市规模以上工业企业的科技创新情况进行总体考察。(数据来源:国家统计局)
首先,采用了规模以上工业企业研究与试验发展(R&D)项目数、新产品项目数、专利申请数以及有效发明专利累积数四项作为指标进行分类,其中前三项选用了2015-2017年数量的平均值,第四项则直接选用了2017年的数量,结果如下图。
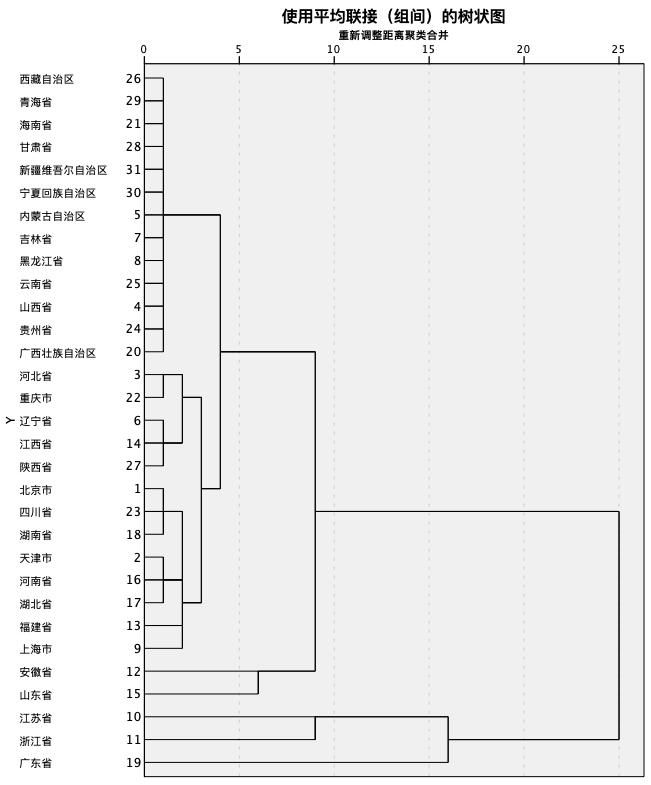
四项创新指标系统聚类树状图
从中可以看出,安徽、山东、江苏、浙江、广东五省的创新指标明显区别(高于)于其余26个省市。
当然,创新项目指标与对应经费投入理应存在一定的联系。
因而,我们将R&D经费投入与R&D项目数(r = 0.936,p < .001)、新产品开发经费与新产品项目数(r = 0.947,p < .001)分别进行相关分析都得到了显著的结果。
但是,当利用R&D经费投入与新产品开发经费作为指标进行分类(下图)时,我们看到,山东、江苏、浙江、广东四省的经费支出确实高于其余各省。
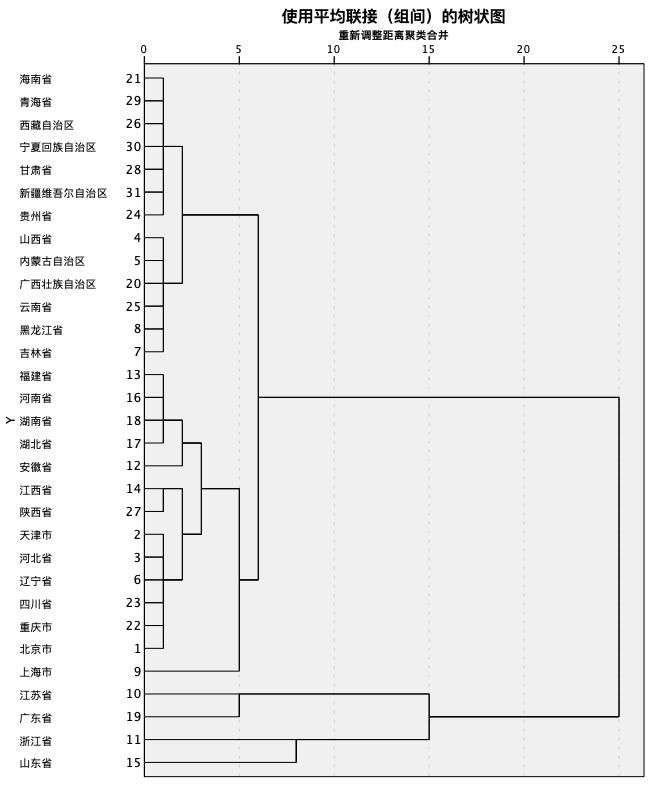
经费投入系统聚类树状图
这很可能就是他们能够拥有更高创新产出的原因,然而安徽省却不在他们之中了。也就是说,安徽省用较为平均的投入,却获得了超常的创新产出,这是真实的吗?
于是,我们带着这个问题又眼盘了下原始数据,发现安徽省仅在专利申请数这一指标上处于领先的位置,如果去除这一指标再进行分类,那么一切都显得顺理成章了。
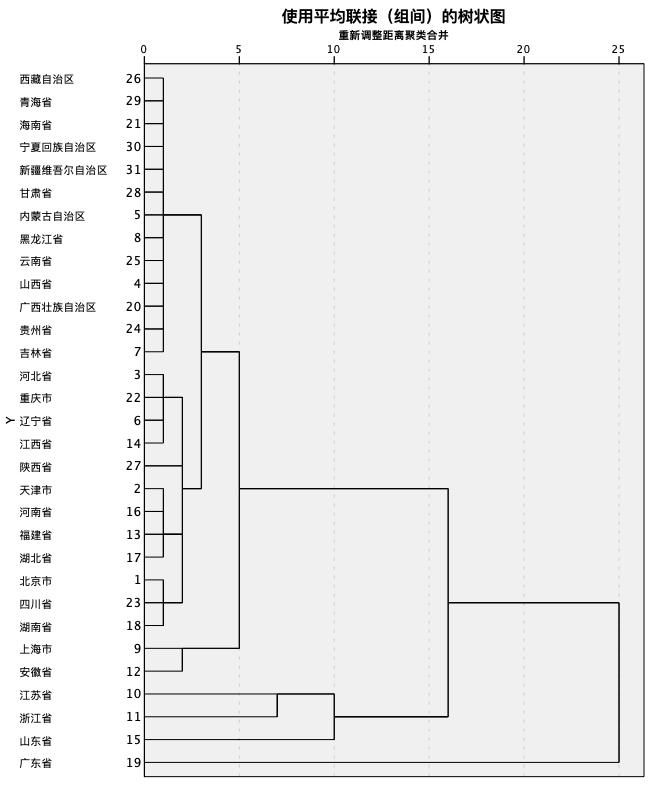
三项创新指标系统聚类树状图
以上,简而言之,聚类分析帮助我们对数据有一个从个体到整体的、更好的了解,方便我们继续发现问题并产生假设。
参 考 文 献
[1] 高惠璇. 应用多元统计分析[M]. 北京大学出版社, 2005.
理论阐述:周昊晟
实例分析:张锡超
推送制作:芦 旖

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)