熵,决策树和特征选择
·
1. 信息熵
信息量
信息量度量一个事件/一个随机变量具体值发生所带来的信息多少。
- 一些性质
- 信息量大于等于0。
- 事件发生的概率与信息量成反比。
- 相互独立事件 A, B 同时发生的信息量等于各自发生时的信息量之和。
- 公式
H ( x ) = − l o g 2 ( x ) H(x) = -log_2(x) H(x)=−log2(x)
信息熵(entropy)
信息熵度量所有可能事件/随机变量信息量的期望。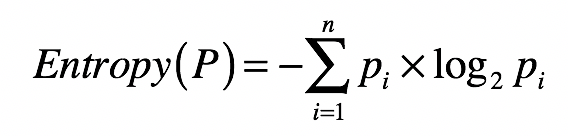
n 表示集合中分组数量。pi 表示第 i 个分组的元素在集合中出现的概率。
信息增益(Information gain)
条件熵是指某一条件下的信息熵。信息增益表示某一条件下信息不确定性减少的程度。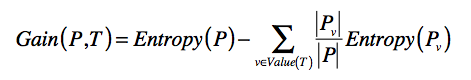
T 表示选择的特征。Entropy(Pv) 表示 T=v 时的熵。
2. 决策树
2.1 建树/训练
- 根据样本分类计算集合的熵值,加权平均后得到整个数据集的熵值。
- 计算每个特征的信息增益,选择区分能力最强的特征,并对每个集合进行更细的划分。
- 重复上述步骤,直到没有更多特征或所有样本都已被分好类。
2.2 算法
1) 概览
| 算法名 | 特征选择标准 | 特点 |
|---|---|---|
| ID3 | 信息增益 | 取值过多时,容易导致机器学习中的过拟合 |
| C4.5 | 信息增益率 | 克服因取值过多导致的过拟合 |
| CART | 基尼指数 | 采用二叉树,每次把数据切成两份(而非根据特征值切分) |
2) 信息增益率 & C4.5算法
子集数量越多,分裂信息值越大。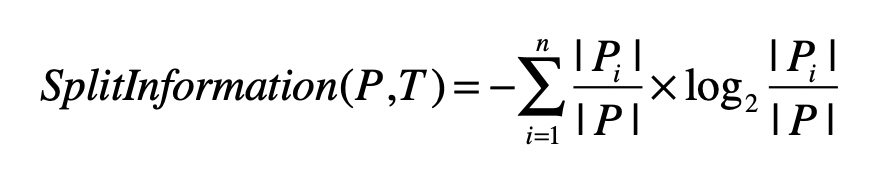
训练集 P 通过特征 T 划分为 n 个子集合。|Pi| 表示 T=i 时子集合中样本的数量。|P|表示训练集 P 中样本的数量。
信息增益率引入分裂信息项来惩罚取值较多的特征。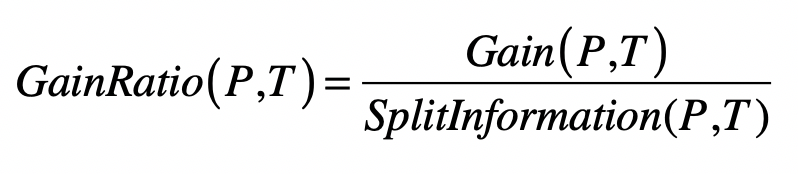
3) 基尼指数 & CART算法
基尼指数是熵模型的近似。由于没有对数运算,基尼指数的计算开销较小。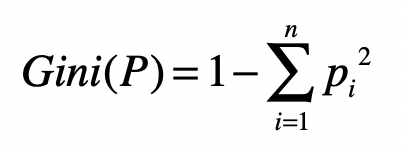
n 表示集合 P 包含的组别数。Pi 表示样本分到某一组别的概率。
整个数据集的基尼系数计算公式如下。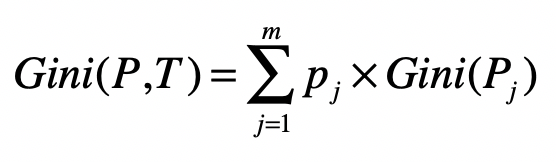
2.3 优化
- 剪枝
- 随机森林
- … …
3. 特征选择
特征是可用于模型拟合的各种数据。
4. 参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)