联邦学习的主要阶段及攻击风险
联邦学习(Federated Learning)是一种分布式机器学习框架,允许各参与方在本地训练模型,仅共享模型参数更新,从而避免数据直接传输。而。
一、联邦学习的主要阶段及攻击风险
1. 数据准备阶段
- 目标:各参与方准备本地数据,通常进行数据清洗、特征工程等预处理。
- 攻击风险:
- 数据投毒攻击:恶意参与方注入污染数据(如标签错误、特征异常值),误导全局模型训练。
- 数据隐私泄露:非恶意参与方因数据预处理不当(如未脱敏),导致隐私信息间接泄露(如通过数据分布推断敏感信息)。
- 应对措施:
- 数据验证:对输入数据进行合法性校验(如统计分布检测、异常值过滤),拒绝明显异常的数据。
- 隐私保护技术:使用差分隐私对数据添加噪声,或通过同态加密确保数据在加密状态下处理。
- 数据匿名化:对数据进行去标识化(如哈希处理用户 ID),避免直接关联到个体。
2. 模型训练阶段
- 目标:各参与方基于本地数据独立训练模型,上传模型更新参数(如梯度、权重)。
- 攻击风险
- 模型投毒攻击:恶意参与方故意生成对抗性模型更新(如梯度方向误导),使全局模型在特定场景下失效
- 梯度反演攻击:攻击者通过模型梯度信息还原训练数据的特征或标签(如从图像模型梯度中恢复原始图像轮廓)。
- 拜占庭攻击:恶意节点发送任意错误的模型参数,破坏全局模型聚合的稳定性。
- 应对措施:
- 鲁棒性训练:采用联邦权重剪裁,限制异常梯度的影响;或使用中位数聚合、Krum算法等鲁棒聚合方法,过滤恶意更新。
- 隐私增强技术:
- 梯度加密:对上传的模型参数进行加密(如安全多方计算(MPC)),确保传输和聚合过程中不可见。
- 同态加密训练:允许模型在加密数据上直接训练,避免明文数据暴露。
- 参与方认证:通过区块链或数字签名技术验证参与方身份,防止伪造节点加入。
1)、联邦权重剪裁的原理
联邦学习(Federated Learning)是一种分布式机器学习框架,允许各参与方在本地训练模型,仅共享模型参数更新,从而避免数据直接传输。而联邦权重剪裁(Federated Weight Pruning) 是在联邦学习过程中对模型权重进行筛选和修剪的技术,其核心原理如下:
(1) 权重重要性评估
在联邦学习的每一轮迭代中,各客户端首先在本地训练模型,然后对本地模型的权重进行重要性评估。评估方法包括:
- 基于幅度的剪裁:认为权重绝对值较大的参数对模型贡献更大,剪裁绝对值较小的权重。
- 基于梯度的重要性:通过梯度信息判断权重对损失函数的影响,剪裁梯度较小的权重。
- 基于 Fisher 信息的评估:衡量权重对模型预测不确定性的影响,保留高Fisher信息的权重。
(2)客户端本地剪裁与稀疏化
客户端根据重要性评估结果,对本地模型权重进行剪裁,保留关键权重并将非关键权重设为0,生成稀疏模型参数。例如,设定剪裁比例(如剪裁 50% 的最小权重),仅保留关键参数参与联邦聚合。
(3) 联邦聚合中的稀疏参数处理
剪裁后的稀疏参数在联邦聚合阶段(如 FedAvg 算法)中,仅传输非零权重及其位置信息,而非完整模型参数。服务器聚合各客户端的稀疏更新时,通常采用稀疏聚合策略(如仅累加非零权重),最终生成全局模型。
(4) 动态调整与再训练
为避免剪裁导致模型性能下降,联邦权重剪裁常结合动态调整机制:
- 周期性重新评估权重重要性,避免关键权重被误删。
- 采用 “剪裁 - 微调” 循环,剪裁后在本地进行微调,恢复模型精度。
2)、中位数聚合
中位数聚合是联邦学习中应对恶意攻击和数据异质性的一种鲁棒性聚合算法,其核心思想是利用中位数的抗噪声特性替代传统联邦平均(FedAvg)的算术平均,从而过滤异常更新(如恶意客户端的攻击或异常数据的影响)。
中位数聚合的原理流程
假设联邦学习中有 N 个客户端参与训练,每轮迭代的聚合过程如下:
(1). 客户端本地训练与更新生成
各客户端 i 在本地数据集上训练模型,得到参数更新 ![]() (即全局模型到本地模型的参数差值)。
(即全局模型到本地模型的参数差值)。
(2) 参数更新的向量化与排序
- 将所有客户端的参数更新
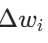 转换为一维向量(展平处理),便于统一计算。
转换为一维向量(展平处理),便于统一计算。 - 对每个参数维度 d,收集所有客户端在该维度的更新值
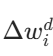 ,并按数值大小排序。
,并按数值大小排序。
(3)中位数计算与聚合
- 对每个参数维度 d,计算排序后更新值的中位数
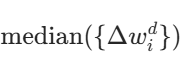 。
。 - 所有维度的中位数构成全局更新
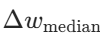 ,服务器用该更新迭代全局模型:
,服务器用该更新迭代全局模型: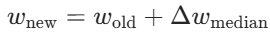
(4)核心数学逻辑
中位数聚合的抗攻击能力源于统计学特性:当存在 f 个恶意客户端时,只要恶意客户端比例 ,中位数会被良性客户端的更新 “包裹”,从而避免被恶意值污染。
- 例如:若有 10 个客户端,3 个恶意客户端上传极大或极小的更新值,剩余 7 个良性客户端的更新值构成中间群体,中位数必来自良性更新。
3. 模型聚合阶段
- 目标:中央服务器(或聚合节点)收集各参与方的模型更新,生成全局模型。
- 攻击风险:
- 聚合后门攻击:多个恶意参与方合谋,在全局模型中植入后门(如对特定输入触发错误预测),且单个节点的更新看似正常。
- 服务器侧隐私泄露:中央服务器可能恶意分析聚合后的模型参数,推断各参与方的训练数据特征(如通过模型权重反推用户偏好)。
- 流量分析攻击:攻击者通过监控模型更新的传输流量,推断参与方的数据规模、更新频率等元信息。
- 应对措施:
- 后门检测:在聚合前对每个模型更新进行 一致性检验(如与历史更新对比、跨参与方参数相似度分析),或在测试数据中注入后门触发样本,检测全局模型是否存在异常响应。
- 服务器可信执行环境(TEE):将聚合过程运行在可信硬件(如 Intel SGX)中,确保中央服务器无法篡改或窃取模型参数。
- 联邦学习框架设计:采用 去中心化聚合(如环形架构)替代单一中央服务器,降低单点攻击风险;或使用 秘密共享(Secret Sharing) 将全局模型参数拆分给多个节点保管。
4. 模型评估与更新阶段
- 目标:验证全局模型的性能,若达标则分发给各参与方更新本地模型,否则启动下一轮训练。
- 攻击风险:
- 模型窃取攻击:恶意参与方通过多次接收全局模型,反向工程推断训练数据的分布或结构(如针对文本模型的成员推断攻击)。
- 模型替换攻击:攻击者篡改分发的全局模型(如在传输过程中注入恶意参数),导致各参与方使用错误模型。
- 应对措施:
- 模型水印与版权保护:在全局模型中嵌入不可察觉的水印(如特定神经元激活模式),防止未经授权的模型复用或篡改。
- 安全传输与验证:使用加密通道(如 TLS)传输模型,并通过哈希校验确保模型完整性,防止中途被替换。
- 差分隐私模型发布:在模型评估阶段添加差分隐私噪声,模糊化模型对特定样本的响应,抵御成员推断攻击。
二、联邦学习的通用安全防护框架
-
多层级隐私保护:
- 数据层:差分隐私、同态加密、安全多方计算(MPC)。
- 模型层:梯度加密、联邦蒸馏(通过轻量化模型压缩敏感信息)。
- 系统层:可信执行环境(TEE)、区块链存证(确保参与方行为可追溯)。
-
动态攻击检测机制:
- 实时监控模型更新的统计特性(如梯度范数、参数变化趋势),设置异常阈值触发警报。
- 使用联邦学习威胁情报共享平台,汇总各参与方检测到的攻击模式,协同防御新型攻击。
-
激励与惩罚机制:
- 通过经济激励(如代币奖励)鼓励诚实参与方,同时设计惩罚措施(如扣除信用分、驱逐出网络)约束恶意行为

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)