浅析扩散模型与图像生成【应用篇】(十二)——DiffI2I
12. DiffI2I: Efficient Diffusion Model for Image-to-Image Translation
该文提出一种基于扩散模型的图像到图像的转换算法(DiffI2I),可用于图像修复、超分辨率提升、图像去模糊、语义分割等任务。作者指出一般的扩散模型,虽然在图像生成任务中表现很好,但是在图像转换任务表现不佳,因为许多图像转换任务都包含一个约束条件,要求生成结果要能与GroundTruth保持一致,而图像生成任务中并没有此类要求。为此,作者提出一个图像转换先验信息表征(I2I Prior Representation, IPR)的概念,用于引导一个动态的I2IFormer模型(DI2Iformer)来完成图像转换。此外,由于很多扩散模型是直接对图像进行扩散和去噪的,这就导致模型的维度很大,计算量很高,这也导致很多扩散模型不能处理高分辨率的图像,且生成速度很慢。作者采用类似LDM的思想,不对图像直接进行扩散和生成,而是对压缩过的特征信息IPR进行扩散和生成,这就极大的提升了图像转换的效率。在多个任务中的转换效果和效率与其他算法的对比如下图所示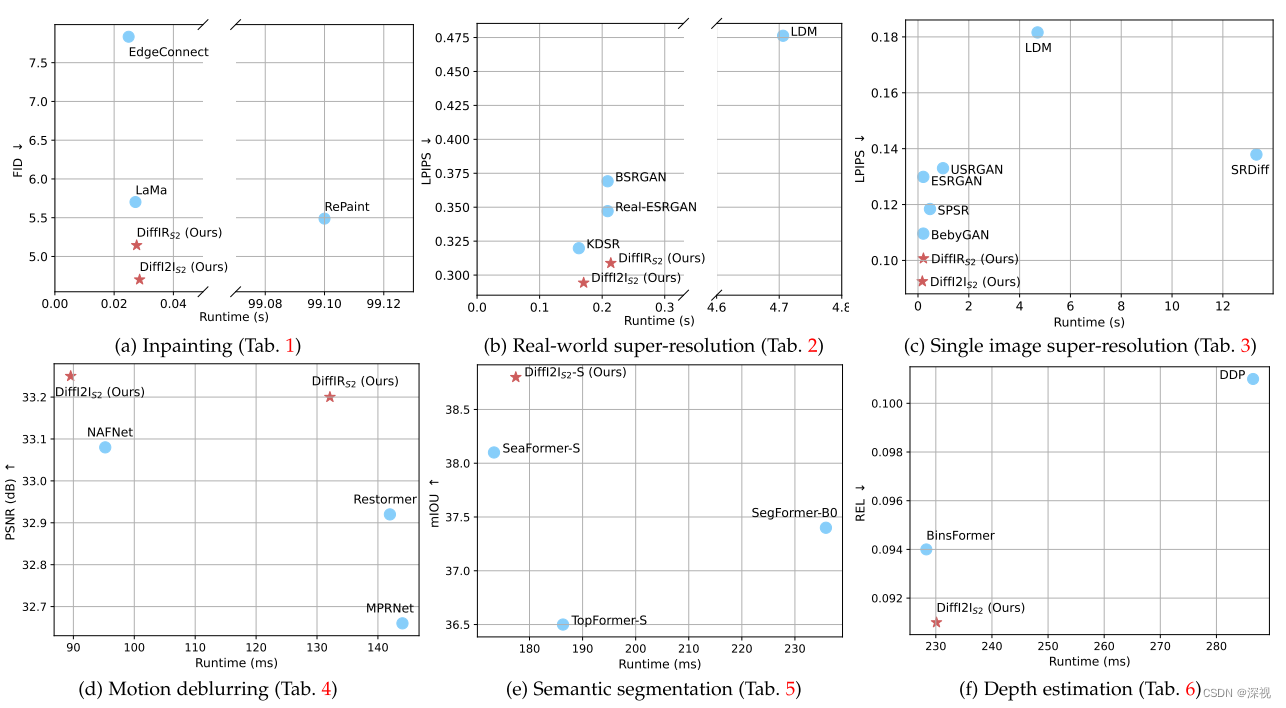
那么作者是怎么实现这样一个又好又快的方法的呢?在DiffI2I中包含三个关键的部分:1. 紧凑的图像转换先验提取网络(CPEN)用于根据输入图像和GT生成对应的IPR;2.动态图像转换Former(DI2Iformer)在IPR的引导下根据输入图像生成输出图像;3. 扩散和去噪网络,用于根据输入的IPR ZZZ生成估计的Z^\hat{Z}Z^。整个算法的流程如下图所示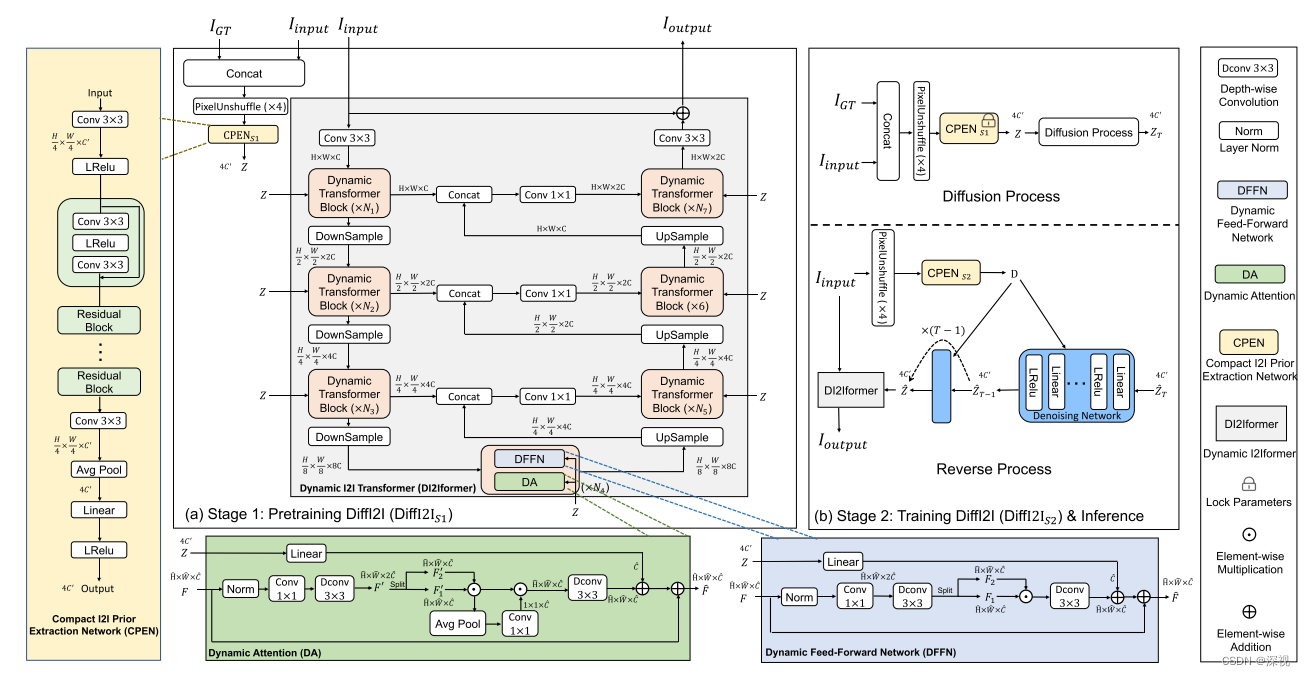
整个DiffI2I的训练过程分成两个阶段,第一阶段是对CPEN和DI2Iformer进行预训练,第二阶段是对去噪模型以及DI2Iformer进行联合训练。首先看第一阶段,将输入图像和对应的GT级联起来,经过PixelUnshuffle算子进行下采样后,输入到CPEN网络中提取IPR 。CPEN网络结构如图中黄色方框内所示,主要由卷积层、残差块、平均池化层、线性层和激活层等结构组成,输出的是一个经过紧凑的带有先验信息的特征图 ZZZ。然后,在 ZZZ的引导下,DI2Iformer根据输入图像IinputI_{input}Iinput输出目标图像IoutputI_{output}Ioutput。DI2Iformer是一个由多个动态Transformer块组成的UNet结构网络,如图中灰色的方框中所示。每个动态Transformer块由动态注意力模块(DA)和动态前向传播网络(DFFN)构成,DA和DFFN模块的结构分别如图中绿色和蓝色方框内所示。对于DA而言,输入特征FFF经过规则化层,1∗11*11∗1卷积和3∗33*33∗3的深度维度卷积得到F′F'F′F′=WdWcNorm(F)\mathbf{F}^{\prime}=W_{d} W_{c} \operatorname{Norm}(\mathbf{F})F′=WdWcNorm(F)然后经过一个SimpleGate (SG)激活操作得到FSG′F'_{SG}FSG′ FSG′=SG(F1′,F2′)=F1′⊙F2′\mathbf{F}_{S G}^{\prime}=\mathrm{SG}\left(\mathbf{F}_{1}^{\prime}, \mathbf{F}_{2}^{\prime}\right)=\mathbf{F}_{1}^{\prime} \odot \mathbf{F}_{2}^{\prime}FSG′=SG(F1′,F2′)=F1′⊙F2′采用通道注意力机制对FSG′F'_{SG}FSG′的各个通道进行加权求和得到FCA′F'_{CA}FCA′ FCA′=FSG′⊙ϕ(FSG′)\mathbf{F}_{C A}^{\prime}=\mathbf{F}_{S G}^{\prime} \odot \phi\left(\mathbf{F}_{S G}^{\prime}\right)FCA′=FSG′⊙ϕ(FSG′)其中ϕ\phiϕ表示全局平均池化操作,最后FCA′F'_{CA}FCA′再次经过3∗33*33∗3的深度维度卷积,并与经过线性映射层的先验信息ZZZ和最初输入的特征FFF求和,得到DA模块的输出F^\hat{F}F^ F^=WdFCA′+WlZ+F\hat{\mathbf{F}}=W_{d} \mathbf{F}_{C A}^{\prime}+W_{l} \mathbf{Z}+\mathbf{F}F^=WdFCA′+WlZ+FDFFN模块的结构与DA模块非常类似,只是缺少计算全局平均池化和进行通道注意力加权的部分,计算方式如下F^=Wd2SG(Wd1WcNorm(F))+WlZ+F\hat{\mathbf{F}}=W_{d}^{2} \mathrm{SG}\left(W_{d}^{1} W_{c} \operatorname{Norm}(\mathbf{F})\right)+W_{l} \mathbf{Z}+\mathbf{F}F^=Wd2SG(Wd1WcNorm(F))+WlZ+F关于DA模块和DFFN模块的输出是怎么进行融合的,原文中我没看到,但是图中可以看出来动态Transformer块的输入和输出维度不变,那么大概率是做了一个相加的操作。经过多个级联的动态Transformer块处理后,输出第一阶段的生成结果IoutputI_{output}Ioutput,用于计算损失,对CPEN和DI2Iforme进行预训练。
完成预训练后,我们进入第二阶段对去噪模型以及DI2Iformer进行联合训练。首先,在扩散阶段输入图像和GT级联起来,并经过PixelUnshuffle算子进行下采样后,使用预训练得到的CPEN模块进行处理得到IPR ZZZ,然后经过一系列的扩散过程得到噪声ZTZ_{T}ZT,接着以ZTZ_{T}ZT作为起点进行反向去噪,去噪网络ϵθ(Concat(Z^t,t,D))\epsilon_{\theta}\left(\operatorname{Concat}\left(\hat{\mathbf{Z}}_{t}, t, \mathbf{D}\right)\right)ϵθ(Concat(Z^t,t,D))包含三个输入,Z^t\hat{\mathbf{Z}}_{t}Z^t是前一时刻ttt的输出结果,初始时刻Z^T=ZT\hat{\mathbf{Z}}_{T}=\mathbf{Z}_{T}Z^T=ZT,ttt表示前一时刻,D\mathbf{D}D表示IPR。要注意的是,这里的IPR也就是D\mathbf{D}D是用一个全新的CPEN模型仅对输入图像进行处理得到的,如下D=CPENS2( PixelUnshuffle (Iinput ))\mathbf{D}=\mathrm{CPEN}_{\mathrm{S} 2}\left(\text { PixelUnshuffle }\left(I_{\text {input }}\right)\right)D=CPENS2( PixelUnshuffle (Iinput ))最后,经过生成过程得到的Z^\hat{\mathbf{Z}}Z^将于输入图像IinputI_{input}Iinput一起输入到DI2Iformer中得到输出结果。CPENS2\mathrm{CPEN}_{\mathrm{S} 2}CPENS2,去噪模型ϵθ\epsilon_{\theta}ϵθ和DI2Iformer一起进行训练,损失函数如下Ldiff =14C′∑i=14C′∣Z^(i)−Z(i)∣,Lall =Ltask +Ldiff \mathcal{L}_{\text {diff }}=\frac{1}{4 C^{\prime}} \sum_{i=1}^{4 C^{\prime}}|\hat{\mathbf{Z}}(i)-\mathbf{Z}(i)|, \mathcal{L}_{\text {all }}=\mathcal{L}_{\text {task }}+\mathcal{L}_{\text {diff }}Ldiff =4C′1i=1∑4C′∣Z^(i)−Z(i)∣,Lall =Ltask +Ldiff 其中Ltask \mathcal{L}_{\text {task }}Ltask 与具体任务有关,比如去噪任务就是用GT和输出结果之间的L1距离,语义分割任务就用交叉熵损失。
在预测时,输入图像经过CPENS2\mathrm{CPEN}_{\mathrm{S} 2}CPENS2处理得到 D\mathbf{D}D,然后与采样得到的高斯噪声Z^T\hat{\mathbf{Z}}_{T}Z^T一起经过反向去噪过程得到IPR Z^\hat{\mathbf{Z}}Z^,将其与输入图像一起输入到DI2Iformer模块中得到预测结果。训练和预测过程如下

由于扩散和生成阶段是对紧凑的先验信息IPR进行处理的,因此扩散和生成阶段计算复杂度较小,只需要迭代4次(T=4T=4T=4)就可以生成较好的结果。在图像修复任务中与其他方法的结果对比如下
运动去模糊任务
超分辨率提升任务

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 35
35 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)