多元高斯分布异常检测代码_智能运维常见时序数据异常点检测技术
概述通常时序数据的异常值主要分为三类:异常值 Outlier给定输入时间序列 ,异常值是时间戳值对,其中观测值 ,与该时间序列的期望值(即 )不同。波动点 Change Point给定输入时间序列 x,波动点是指在某个时间 t,其状态(行为)在这个时间序列上表现出与 t 前后的值不同 。异常时间序列( Anomalous Time-series )给定一组时间序列,异常时间序列是在上与大多...

概述
通常时序数据的异常值主要分为三类:
- 异常值 Outlier
给定输入时间序列,异常值是时间戳值对
,其中观测值
,与该时间序列的期望值(即
)不同。
- 波动点 Change Point
给定输入时间序列 x,波动点是指在某个时间 t,其状态(行为)在这个时间序列上表现出
与 t 前后的值不同 。 - 异常时间序列( Anomalous Time-series )
给定一组时间序列,异常时间序列
是在
上与大多数时间序列值不一致的部分
时序数据常用特征
时序数据常见特征
用于建模实验的常见指标,衡量模型好坏
异常检测方法
主要分为三大类:
- 基于统计模型
基于统计模型的异常点检测技术将所有数据构建成一个数据模型,其认为异常点是那些与模型不能完美拟合的对象。 - 基于邻近度
通常可以在对象之间定义邻近性度量。异常对象是那些远离大部分其他对象的对象。 - 基于密度的技术
对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量时。当一个点的局部密度显著低于它的大部分近邻时,可能会被看作是异常的。
基于统计模型的异常点检测
基于数据,构建一个概率分布模型,得出模 型的概率密度函数。通常,异常点的概率是很低的。
基于正态分布的一元异常点检测
假设数据集由一个正态分布产生,该分布用
多元正态分布的异常点检测
对于多元高斯分布检测,我们希望使用类似于一元高斯分布的方法。 例如,如果点关于估计的数据具有低概率,那么就把它们分类为异常点。
实际上马氏距离也是统计算法,点到基础分布的Mahalanobis距离与点的概率直接相关
综上所述,两种基于统计模型的异常点检测方法,需要建立在标准的统计学技术(如分布 参数的估计)之上。这类方法对于低维数据效果可能较好,但是对于高维数据,数据分布非常 复杂,基于统计模型的检测效果会比较差。
基于邻近度的异常点检测
马氏距离
对于一个多维数据集
其中,
容易证明: 点到基础分布的Mahalanobis距离与点的概率直接相关,等于点的概率密度的对数加上一个常数。因此,可以对Mahalanobis距离进行排序,距离大的,就可以认为是异常点。
KNN
KNN 算法是基于邻近度的算法, 不需要对数据集进行统计模型的拟合,可以直接用距离来识别异常点。但是,这种基于距离的算法也有其明显的缺点:①时间复杂度为
基于密度的异常点检测
从基于密度的观点来说,异常点是低密度区域中的对象。
定义密度的方法有以下三种。
逆距离
一个对象的密度为该对象周围k个最近邻的平均距离的倒数。
其中,
半径 d 内的个数
即一个对象周围的密度等于该对象指定半径 d 内对象的个数。d是人为选择的,那么这个d的选择就很重要了。
相对密度
即用点 x 的密度与它最近邻 y 的平均密度之比作为相对密度。
其中,
独立森林 Isolation Forest
首先,要理解独立森林,就必须了解什么是独立树,下文简称 iTree 。 iTree 是一种随机二 叉树,每个节点要么有两个子节点(称为左子树和右子树),要么没有子节点(称为叶子节点)。 给定数据集D,这里 D 的所有属性都是连续型变量, iTree 的构成如下:
- 随机选择一个属性 A。
- 随机选择该属性的一个值 value 。
- 根据 A对每条记录进行分类,把 A 小于 value 的记录放在左子树上,把大于或等于 value 的记录放在右子树上。
- 递归构造左子树和右子树,直到满足条件:①传入的数据集只有一条或多条一样的记录;②树的高度达到了高度阔值。
iTree 构造完成后,接下来对数据进行预测。预测的过程就是把测试记录从 iTree 根结点开始搜索,确定测试记录落在哪个叶子节点上。 iTree 能检测异常的假设是:异常点一般都是非常稀有的,在 iTree 中很快会被分到叶子节点上。也就是说,在 iTree 中,异常值一般表现为叶子 节点到根节点的路径 h(x)很短。因此,可以用 h(x)来判断一条记录是否属于异常值。
再定义一个关于h(x)的异常指数,
其中, n 为样本的大小, h(x)为记录 x 在 iTree 上的高度,
实现中还有注意的点:
- 随机树是不稳定的,但是把多棵 iTree 结合起来,形成 iForest 就变得强大了
- 构建iForest 的方法与构建随机森林的方法类似,都是随机采样一部分数据集来构造每一棵树,保证不同树之间的差异。 但不同的是,我们需要限制采样样本的大小。采样前正常值和异常值有重叠,采样后可以有效区分正常值和异常值。
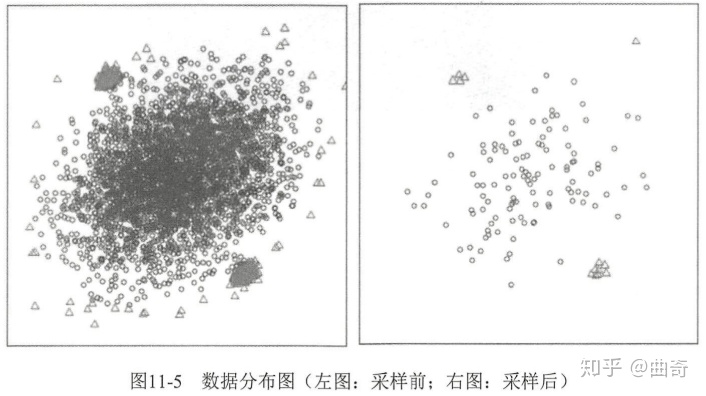
- 需要限制 iTree 的最大高度,因为异常值记录比较少,其路径长度也比较小。树太深了增加无意义的计算消耗。
综上所述,独立森林本质上是一种非监督算法,不需要先验的类标签。在处理高维数据时,不是把所有的属性都用上,而是通过峰度系数(峰度小,长尾太长了,比较难判断异常;峰度大,则大部分数据集中,方便判断)挑选一些有价值的属性,然后再进行 iForest 的构造,算法效果会更好。
颜色越深代表异常值得分越高, 颜色越浅代表异常值得分越低。可以看出,模型预测效果不错,颜色分布规律与 test 和 outlier 数据集完全吻合。

业界实践
常见的开源的异常监测系统
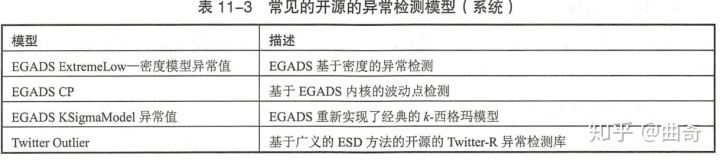

EGADS
EGADS是 Yahoo 公司开发的一个灵活的、准确的、可扩展的异常检测综合系统。 EGADS 框架与异常检测基准数据一起开源 (https://github.corn/yahoo/egads)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)