AgilePilot:基于 DRL 的无人机代理,通过利用对象检测在动态环境中进行实时运动规划
抽象
动态环境中的自主无人机导航仍然是一项关键挑战,尤其是在处理不可预测的场景时,包括目标位置快速变化的快速移动物体。虽然传统的规划器和经典的优化方法已被广泛用于解决这一动态问题,但它们经常面临实时、不可预测的变化,最终导致适应性和实时决策方面的次优性能。在这项工作中,我们提出了一种新颖的运动规划器 AgilePilot,它基于深度强化学习 (DRL),在动态条件下进行训练,并结合实时计算机视觉 (CV) 在飞行过程中进行物体检测。从训练到部署的框架弥合了 Sim2Real 的差距,利用复杂的奖励结构,根据环境条件促进安全性和敏捷性。该系统可以快速适应不断变化的环境,同时实现3.0m/s 在现实世界场景中。相比之下,我们的方法优于基于人工势场 (APF) 的运动规划器等经典算法3倍,通过在展示时使用速度预测来改变动态目标的性能和跟踪精度90%75 次实验的成功率。这项工作强调了 DRL 在应对实时动态导航挑战、提供智能安全性和敏捷性方面的有效性。
关键词:无人机导航、动态环境、运动规划、深度强化学习、安全性和敏捷性、计算机视觉、机器人技术。
我介绍
近年来,自主无人机导航引起了人们的极大兴趣,尤其是在动态环境的背景下。传统的运动规划方法,如非线性模型预测控制 (NMPC) 和基于图形的搜索算法,已经在结构化和受控环境中证明了效率,但缺乏实时适应快速变化条件的能力。因此,DRL 已成为一种可行的替代方案,它提供快速决策和适应性,从而提高自主导航。在最近的工作中,Song 等人。[1]已经探索了使用 DRL 方法在近时间内生成近乎最优的轨迹,能够适应动态轨道配置,同时实现高达 60 公里/小时的惊人速度。另一项研究[2]作者 Kaufmann 等人利用模型预测控制 (MPC) 在赛道中快速导航,其中卷积网络和扩展卡尔曼滤波器 (EKF) 预测最近门的姿态以及不确定性。此外,另一项突破性研究[3]介绍了一个 SWIFT 系统,该系统通过使用近端策略优化 (PPO) 算法来训练一个为四旋翼生成低级控制命令的模型,从而在无人机比赛中与人类无人机飞行员竞争。尽管这些研究为无人机开发了敏捷系统,但它们缺乏实时有效避开障碍物和适应高度动态变化环境的能力。此外,当环境变得高度不可预测时,它们平衡安全性和敏捷性的能力也受到限制。
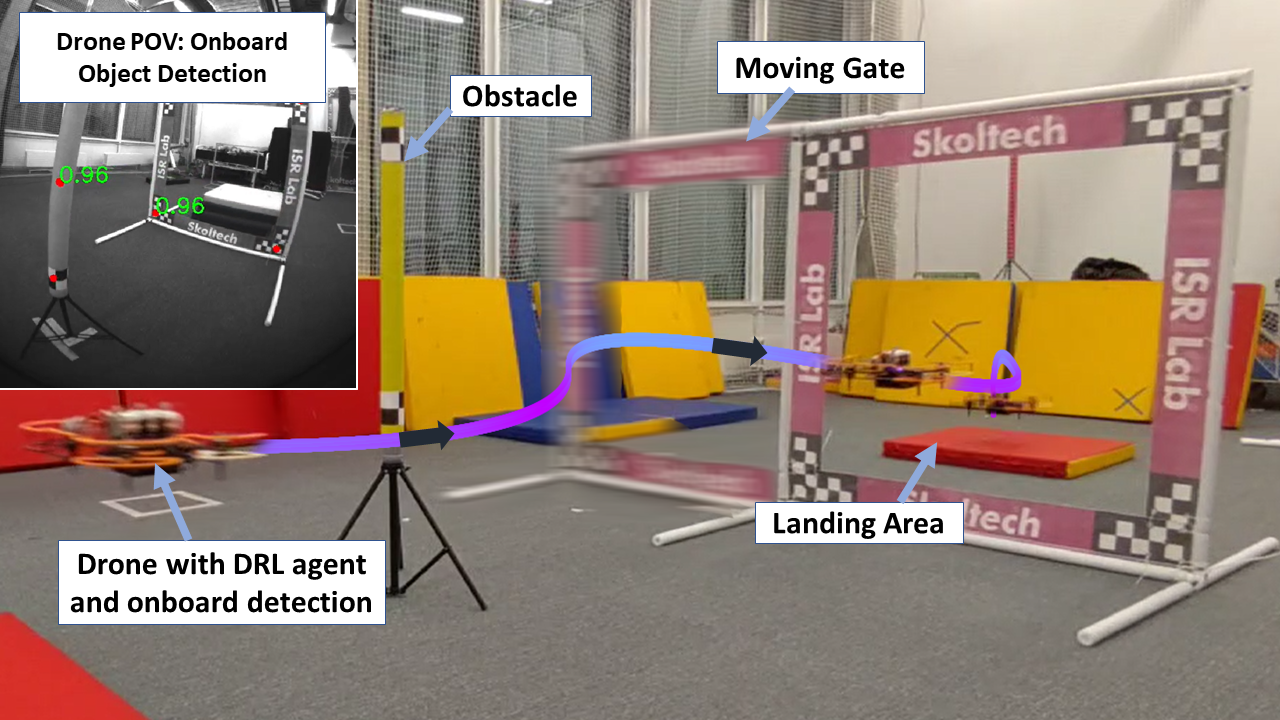
图 1:AgilePilot 技术执行基于深度强化学习的运动规划,以避免障碍物和导航穿过移动的门和目标位置,使用机载计算机视觉系统实时检测物体
这项研究引入了一种新颖的运动规划器 AgilePilot,它利用 DRL 来预测无人机在移动物体的动态环境中导航的速度。速度预测具有态势感知能力,在较简单的地形中最高可达 3.0 m/s,而在涉及障碍物和移动物体的复杂场景中会减慢速度。所提出的方法涉及一个独特的框架,用于在定制的仿真环境中训练模型,以达到 Sim2Real 传输所需的精度水平。训练使用 Actor Critic 神经网络架构进行,并使用独特的奖励结构,并在剧集中进行有效随机化,使训练模型的应用通用且易于实施。为了跟踪可移动物体,该系统应用基于 YOLO 的物体检测,并使用 IPPE PnP 和 EKF 进行状态估计,以实现稳健的姿态估计。
本研究中使用的方法通过根据地形的复杂性有效地调整速度矢量,同时考虑到物体运动的不确定性,彻底改变了无人机在动态环境中的运动规划。用于在未知环境中训练和测试训练模型的管道确保了技术的广泛适用性。
第二相关作品
由于无人机导航在动态环境中的复杂性非常复杂,许多研究一直在尝试使用机器学习或经典方法来解决算法的普遍适用性。例如,在研究中[4],该政策是在高度不确定性的情况下学习的,并在嘈杂的真实环境中进行了测试。结果表明无人机导航在现实中是有效的,但该方法仅适用于 2D 空间,未在动态条件下进行测试。
在研究中[5],DRL 用于避免由图像和多个标量组成的移动和静止障碍物与联合神经网络 (JNN)。Liu 等人,在研究中[6]使用集成了 Visibility Path Search 的运动规划框架来生成无碰撞的路径,并使用 RL 来生成低级运动命令。此外,还引入了基于 CPU 的 DRL 用于 UAV 到 UAV 跟踪[7].该模型使用 PPO 进行训练,并显示出相当大的效果。另一位基于 PPO 的学习性 RL 代理正在研究中[8]在赛车环境中用作路径规划器,并利用传统的比例-积分-微分 (PID) 控制器来控制运动。此外,Song 等人的研究[9]通过将视觉与 DRL 相结合,在照顾看不见的环境的同时,生成平滑的无碰撞轨迹。虽然上述这些研究表明了运动生成和避障的良好能力,但它们主要仅在具有挑战性较低的场景中进行了仿真环境测试。
此外,在学习中[10]高效的路径规划器是为杂乱的环境设计的,通过根据时空联合优化调整时间分配,融入了一定程度的动态可行性。此外,学习[11]通过使用多阶段训练方法并在真实的空地无人系统上测试代理,引入了一种基于搜索的方法。在[12],利用双 Deep-Q 网络 (DDQP) 对密集城市环境中的随机障碍物进行 DRL 训练,同时增强算法的训练稳定性。此外,学习[13]通过利用地图参数化和低成本规划来提高避障时的安全导航,同时结果在实际实验中得到验证。彼得等人。研究中的 Al[14]使用双延迟深度确定性 (TD3) 策略梯度算法和现实生活实验的训练模型表明,在下洗和风湍流存在的情况下,无人机对动态移动平台的着陆性能非常出色。使用 PPO 的这些工作扩展也已成功应用于多代理[15].然而,这些方法纯粹专注于路径规划,而不考虑障碍物,并且仅在小型无人机上进行了测试,因此总体上限制了中型无人机的高速潜力。最后,另一项研究[16]推出了 OmniRace,这是一个基于无人机速度纵的控制界面,适用于各种尺寸的无人机。然而,它的运动规划完全依赖于人工输入,这限制了导航的准确性和自主性。
为了解决上述差距,本研究提出了一种新颖的基于 DRL 的运动规划框架,由于其无模型学习代理的性质,该框架可以为任何尺寸的无人机生成基于速度的轨迹。与以前依赖静态环境的研究不同,我们的方法是为动态场景设计的,确保对快速变化的环境具有强大的适应性。使用的训练环境是 Gym PyBullet[17]并经过精心定制和调整,以融入现实世界的复杂性,实现从仿真到现实的无缝过渡。此外,该框架还考虑了动态变化的障碍,使无人机能够实时做出智能决策,同时根据需要平衡敏捷性和安全性。
第三方法论
本节介绍用于开发 AgilePilot 管道的方法。Gym PyBullet 用于 PPO 训练中的模拟和物理学,模型部署在模拟和真实环境中。我们系统的整体管道如图 1 所示。2.
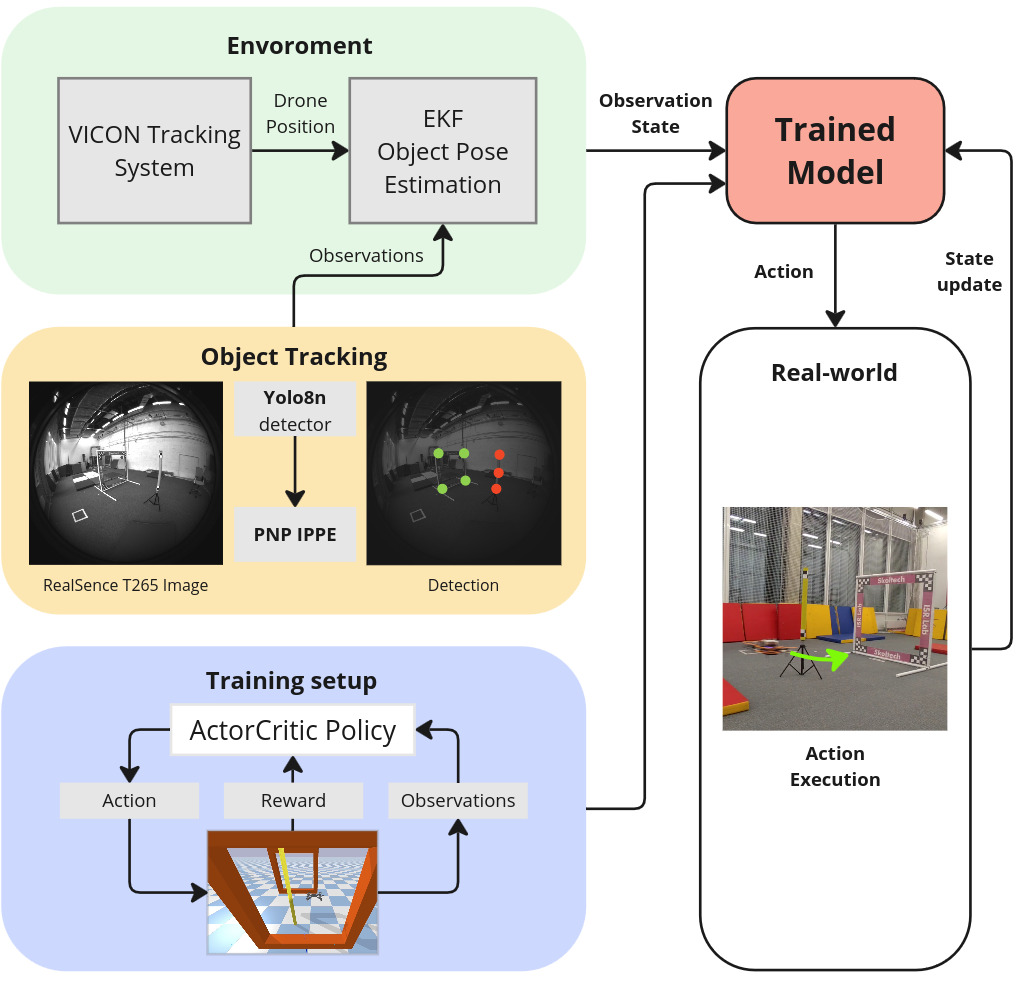
图 2:AgilePilot 由一个用于环境中的代理和动态对象的位置估计模块以及一个将状态观察映射到控制命令的控制策略组成。该策略使用 ActorCritic 网络在定制的模拟环境中使用 PPO 算法进行训练。位置估计系统使用 VICON 跟踪系统提供无人机的状态,而使用 YOLO 神经网络进行对象检测,以进行门角检测和障碍物关键点提取。使用 IPPE PnP 处理关键点以估计局部位置,然后将其映射到全局坐标系中的 3D 姿势。
III-A 系列仿真环境
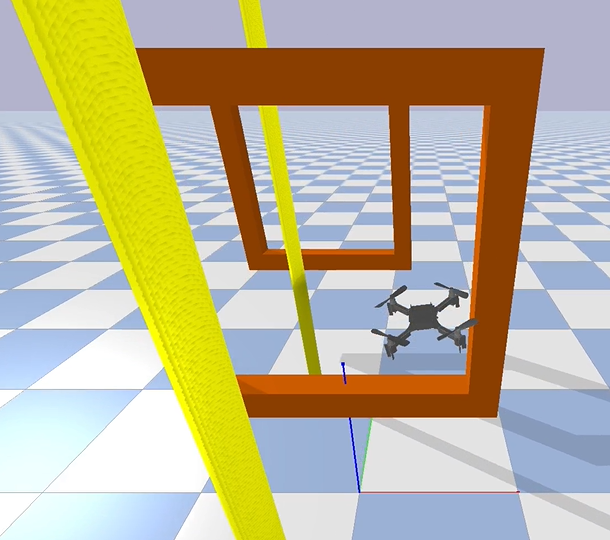
图 3:具有自定义对象的 Gym PyBullet 模拟环境。
模拟设置是使用 Gym 环境和 PyBullet 物理引擎开发的,允许使用逼真的空气动力学和精确的四轴飞行器数学建模来模拟无人机。我们在仿真中集成了定制的中型无人机和定制的 PID 控制器。惯性和控制器参数被调整到真实环境中的实际响应水平。此外,还构建了自定义对象,例如门和障碍物,如仿真图 1 所示。3.
在每个步骤中,物体的运动都由从均匀概率分布中得出的随机速度控制。
| Δ𝐩∼𝒰(−v麦克斯,v麦克斯) |
哪里Δ𝐩=[Δx,Δy]表示x和ydirections 和𝒰(−v麦克斯,v麦克斯)表示范围内均匀分布−v麦克斯自v麦克斯.
最后,PID 控制器允许无人机达到±3m/s 输入xy和±2在z方向,而旋转角度的范围可以从−π自π弧度,通过使用精确的电机动力学模型将所需命令映射到电机 RPM,然后映射到所需的力和扭矩。
III-B 型深度强化学习
III-B1 号神经网络架构
我们的神经网络遵循一个 Actor-Critic 共享架构 Fig.4. 输入层由以下观察值组成:
| 𝐨^t=[𝐱雄蜂,θ雄蜂,𝐯雄蜂,ω雄蜂,𝐝目标,Δ𝐫OBS] |
哪里𝐱雄蜂表示无人机的位置,由其坐标组成,θ雄蜂表示无人机的方向,𝐯雄蜂是无人机的线速度,而ω雄蜂表示无人机的角速度。目标的状态由𝐝目标,其中包括目标的 3D 位置、大小和方向。最后Δ𝐫OBS表示障碍物的相对位置以及障碍物的大小。

图 4:神经网络架构代表我们系统的输入层、隐藏层和输出层。
actor 的输出层表示作空间,它由以下四个值组成:
| 一个^t+1=[vx,vy,vz,v麦克斯] |
其中无人机所需的速度分量由vx,vy和vz和v麦克斯表示无人机可以达到的最大速度。
神经网络设计有 ReLU 激活函数,并使用具有以下结构的全连接 (FC) 层:
| ReLU 系列(FC512型×2)→ReLU 系列(FC256型)→ReLU 系列(FC128型) |
输出层本质上是一个四维速度矢量,由低级 PID 控制器控制。速度矢量可通过一些比例因子进行调整,以便在实际无人机控制系统中实现。此外,通过从动作空间投影 xy 速度矢量来间接确定所需的偏航角。
III-B2 号奖励结构
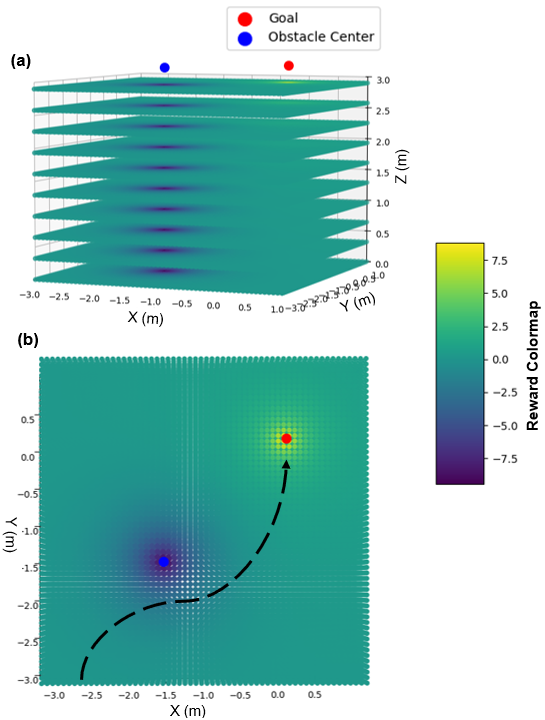
图 5:颜色图在定义区域内存在障碍物和目标的情况下可视化无人机位置的奖励值,即 (a) 显示 3D 空间中的奖励结构,其中障碍物被视为无限高度,(b) 显示 XY 平面中的俯视图,以及无人机避开障碍物并到达目标的预测路径。
无人机的奖励结构旨在激励有效的目标穿越,同时避开障碍物 Fig.5.
代理根据其与目标的距离获得奖励。当无人机靠近目标时,奖励会大幅增加,从而在 3D 空间中实现稳定的目标位置跟踪。
| R接近=1d目标+cp, |
哪里d目标是无人机位置与目标之间的欧几里得距离,cp是避免极高奖励值的常数。
此外,代理会因靠近障碍物而受到惩罚,其中障碍物被建模为无限高度的对象。惩罚基于与障碍物的相对距离及其大小,使用指数函数:
| R障碍=−co⋅exp (英文)(−d障碍r安全), |
哪里d障碍等于‖Δ𝐫OBSxyz‖,co是罚度缩放常数,而r安全是障碍物周围的安全区域。
最后,如果无人机与具有较大常数的物体相撞,则适用处罚,cpen一个l或者如果无人机的速度在安全区域内非常高,以促进安全导航行为。
| R碰撞={−cpen一个lif 碰撞0还 |
| R速度={−cv⋅‖𝐯‖2如果d障碍<r安全0还 |
哪里‖𝐯‖是速度矢量的欧几里得范数,cv是速度惩罚常数。
最后,总奖励Rtot一个l计算公式为:
| Rtot一个l=R接近+R障碍+R碰撞+R速度 |
III-B3 号训练
无人机在以下范围内随机化:
- •
x,y∈[−4.0,4.0](在xy-plane)
- •
z∈[0.3,4.0](在z-轴)
- •
θ雄蜂在[−π2,π2].
障碍物位置根据两个组成部分随机化:纵向偏移和横向偏移。
纵向偏移量是沿着连接无人机和目标的线计算的,而横向偏移量是垂直于这条线。让L→是从无人机到目标的向量:
| L→=𝐝目标xyz− 𝐱雄蜂 |
纵向偏移d长由下式给出:
| O→长=d长⋅L→ |
横向偏移量计算为L→使用单位向量Z→:
| L→纬度=L→×Z→‖L→×Z→‖ |
然后,通过将纵向和横向偏移量与无人机在剧集中的初始位置相结合来确定障碍物的位置。 这z- 障碍物的坐标在一个范围内随机化,通常在z∈[0,2].
表 I:DRL 的训练参数
| 参数 | 价值 |
|---|---|
| 算法 | PPO (邻近策略优化) |
| 总步数 | 25,000,000 |
| 环境数量 | 8 |
| 批量大小 | 256 |
| 步数 | 2048 |
| 熵系数 | 0.01 |
| 折扣系数 | 0.99 |
| 剪辑范围 | 0.2 |
| 激活函数 | ReLU 系列 |
此外,表 I 总结了训练中强化学习算法中使用的关键参数。用于训练的优化算法是 Adam,它是强化学习中广泛使用的优化器。学习率设置为1×10−4.
特征提取器(策略网络)处理观察结果,并为动作预测提供必要的特征。对于 PPO,策略体系结构基于 ActorCriticPolicy,它将 actor (策略) 和 critic (值函数) 集成到单个神经网络中。输出层根据已处理的输入提供作分布。
训练后,通过在环境中运行模型并计算多个事件中奖励的平均值和标准差来评估模型的性能。无花果。6 和图 .7 分别显示了具有不同超参数集的几个训练模型的平均奖励和平均剧集长度。表 中列出的 Hyperparmeter 的模型 2。我被选中进行实验是因为它具有更好的收敛性、最高的奖励和最小的剧集长度,表明该策略已经学习得很好。
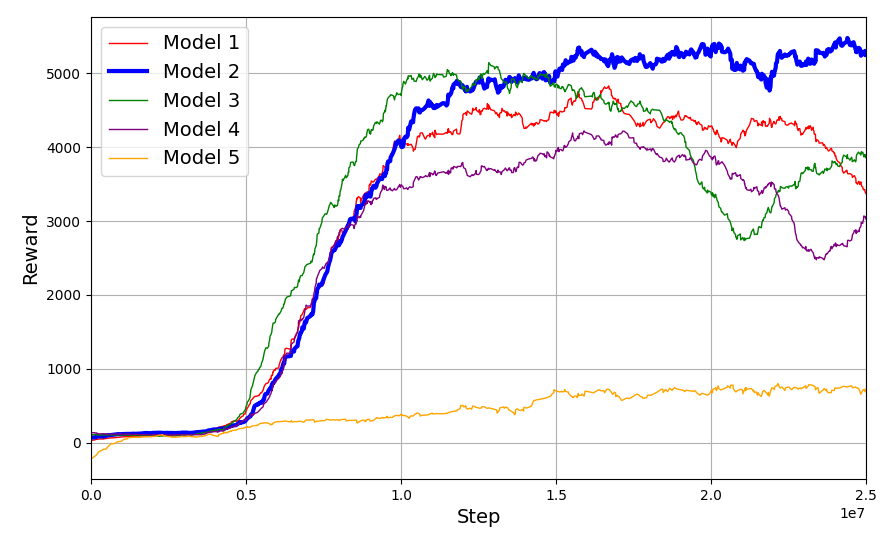
图 6:具有不同参数的 5 个训练模型的平均奖励表明,奖励在收敛前随时间增加。
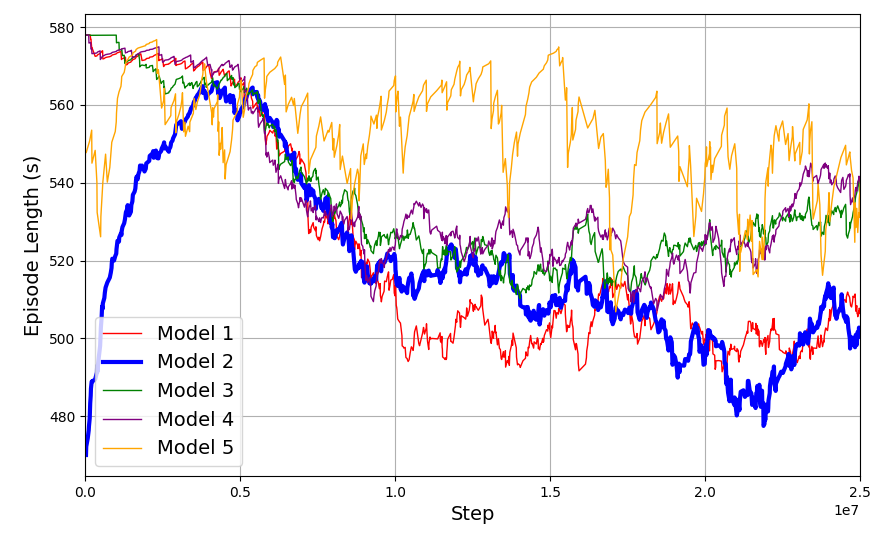
图 7:具有不同参数的 5 个训练模型的平均剧集长度随时间呈下降趋势,这表明模型正在收敛到最佳学习策略
III-C 系列计算机视觉系统
III-C1 号对象检测
对象检测系统以 30 fps 的帧速率接收来自广角英特尔实感 T265 摄像头的图像,并输出门和障碍物相对于摄像头的空间位置的估计值。相机捕获一帧,然后由 YOLOv8n Pose 神经检测器处理。探测器识别了定义尺寸为 1.5 x 1.5 m 的门平面的四个关键点,以及长度为 1.0 m、直径为 0.1 m 的圆柱形障碍物的三个关键点。为了训练检测模型,我们收集了一个自定义数据集,其中包含 2475 个带注释的赛车门实例和 3015 个障碍物实例。使用专门的增强技术从原始数据集生成了 4,471 张图像。最终数据集以 80:20 的比例分为训练集和验证集。YOLO 模型经过 500 个 epoch 的训练,批量大小为 32,图像分辨率为 424x400 像素。应用了数据增强,包括概率为 0.5 的水平翻转、高达 10 度的随机旋转以及使用以下参数在 HSV 空间中进行颜色调整:色调 0.015、饱和度 0.2 和值 0.2。该模型的推理时间为 40 ms,展示了系统的实时处理能力。
III-C2位置估计
基于无穷小平面的姿态 (IPPE) 方法有助于估计赛车门和障碍物相对于无人机摄像头的空间位置和方向。这是使用对象角点的 2D 坐标、对象本地坐标系内这些角的 3D 坐标以及相机固有参数来实现的。该方法允许精确确定物体在空间中的姿态和方向。EKF 用于过滤多个物体的噪声位置测量,通过根据观测的空间接近度关联观测来实现精确跟踪。门的状态向量表示为𝐱=[xyzψ]T和圆柱形障碍物𝐱=[xy]T表示对象的位置和方向,其中:x,y,z是位置坐标,而ψ是偏转角(方向)。工作检测和姿态估计系统的结果如图 2 所示。8.

图 8:在帧上检测到的关键点的结果以及 RVIZ 中物体估计姿势的可视化。
四比较分析
在本分析中,我们将基于 DRL 的运动规划器的性能与著名的人工势场 (APF) 运动规划器的性能进行了比较,因为它在无人机的动态环境中的有效性[18] [19].为了进行这种比较,我们进行了 5 个模拟案例来评估不同的动态条件。每种情况的一般配置包括无人机必须通过的两个障碍物和一个门才能到达目标位置。
IV-A 型模拟案例
这 5 个模拟案例如下:
- •
案例 1:以 0.3 m/s 的速度移动门,并设置障碍物以利用 APF 局部最小值。
- •
案例 2:仅以 0.3 m/s 的速度移动闸门
- •
案例 3:以 0.3 m/s 的速度移动闸门,目标高度不同。
- •
案例 4:移动门和障碍物均以 0.3 m/s 的速度移动,目标高度不同。
- •
案例 5:浇口仅以 0.6 m/s 的速度移动。
每个案例都执行 15 次,具有不同的初始无人机和对象位置,以记录每当无人机与环境中的物体碰撞时存在故障的故障次数。
IV-B 型性能指标
性能指标如下:
- •
成功率:成功率使用以下公式计算:
成功率=1−失败次数15 - •
跟踪精度:跟踪移动门和目标位置的精度。
- •
完成实验的时间:在每种情况下,无人机完成完整任务所用的总时间。
表 II:DRL 药物与 APF 的成功率比较
| 箱 | DRL 代理 | APF |
|---|---|---|
| 1 | 100% | 0% |
| 2 | 100% | 80% |
| 3 | 90% | 60% |
| 4 | 80% | 40% |
| 5 | 80% | 20% |
表 II 显示平均值90%与 APF 运动规划器相比,DRL 代理总共 75 次实验的成功率,其中 APF 在案例 1 中完全无法通过局部最小值情况导航,并且在案例 4 和案例 5 中难以完成其高度动态移动环境的任务。
表 III:DRL 代理与 APF 的性能指标显示平均误差 (ME)、标准差 (SD) 和到达成功航班的目标点所花费的时间 (TT)
| 案例 (DRL) | 跟踪 ME (cm) | 跟踪 SD (cm) | TT (秒) |
|---|---|---|---|
| 1 | 4.80 | 0.2 | 5.00 |
| 2 | 4.30 | 0.3 | 4.50 |
| 3 | 5.50 | 0.3 | 4.20 |
| 4 | 5.50 | 0.3 | 6.40 |
| 5 | 5.60 | 0.2 | 5.20 |
| 案例 (APF) | 跟踪 ME (cm) | 跟踪 SD (cm) | TT (秒) |
|---|---|---|---|
| 1 | 那 | 那 | 那 |
| 2 | 15.6 | 1.0 | 14.7 |
| 3 | 14.2 | 0.5 | 14.8 |
| 4 | 13.4 | 1.1 | 15.5 |
| 5 | 16.0 | 1.2 | 14.0 |
此外,表 III 显示了两种方法之间的关键性能参数。DRL 代理能够通过速度预测执行高精度门控和目标跟踪,即比 APF 规划器好约 3.0 倍。此外,完成所有案例所需的时间平均为 5.0 秒,这比动态环境中的 APF 规划快约 3.0 倍。

图 9:在情况 3 比较中,无人机的轨迹与无人机的速度颜色图,其中 (a) 显示使用 DRL 代理的轨迹,(b) 通过 APF 规划显示轨迹
从案例的其中一个视觉表示中,高精度和高速导航也从图 1 中明显可见。9 中可以看出,无人机相当平稳和智能地通过移动门,其速度超过 2.5 m/s。相反,APF 规划器难以适应移动闸门场景,并将其速度保持在 1.0 m/s 以下。
V实验评价
V-A实验装置

图 10:我们系统的实验布局,其中 ArduPilot 无人机配备了英特尔 NUC 机载计算机和实感摄像头,在避开障碍物并到达目标点(红色区域)的同时,通过大门中心进行动态导航。
无花果。图10说明了我们实验装置的总体布局。这架无人机重 1.80 公斤,配备了高性能 Intel NUC 机载计算机,以及用于实时物体检测的 RealSense T265 摄像头。机载计算机与 SpeedyBee 飞控通信,该飞控负责通过 ArduPilot 固件发送和接收命令。对于环境布局,使用障碍物、门和着陆垫,其中对象由绳索以 0.4-0.7 m/s 的速度动态手动移动,以验证仿真结果向真实世界条件的传输。
飞行测试在静态和动态条件下进行。设计了三个测试用例来评估 DRL 代理的性能,特别关注其在不同条件下的速度预测及其对不断变化的环境的适应性。这三种情况如下:
- •
案例 1:缓慢向左移动的门,有障碍物和目标。
- •
案例 2:带有障碍物和目标的快速右移动门。
- •
案例 3:静态环境。
V-B结果
V-B1 号对象位置估计
飞行实验期间门和障碍物姿态估计的误差测量结果如图 1 所示。11. 对于位置估计,障碍物的平均位置误差为 0.19 m,门的平均位置误差为 0.22 m。位置估计的标准差为障碍物 0.06 m,门 0.13 m。在方向方面,门的平均方向误差为 0.3 弧度,标准差为 0.07 弧度,表明方向估计具有合理的精度。障碍物的位置均方根误差 (RMSE) 为 0.076 m,门为 0.37 m。此外,观察到 X 坐标位置变化的延迟(图 D)。11 b.),从实际姿势开始更改到预测的 X 坐标姿势开始响应,范围最长为 100 毫秒。
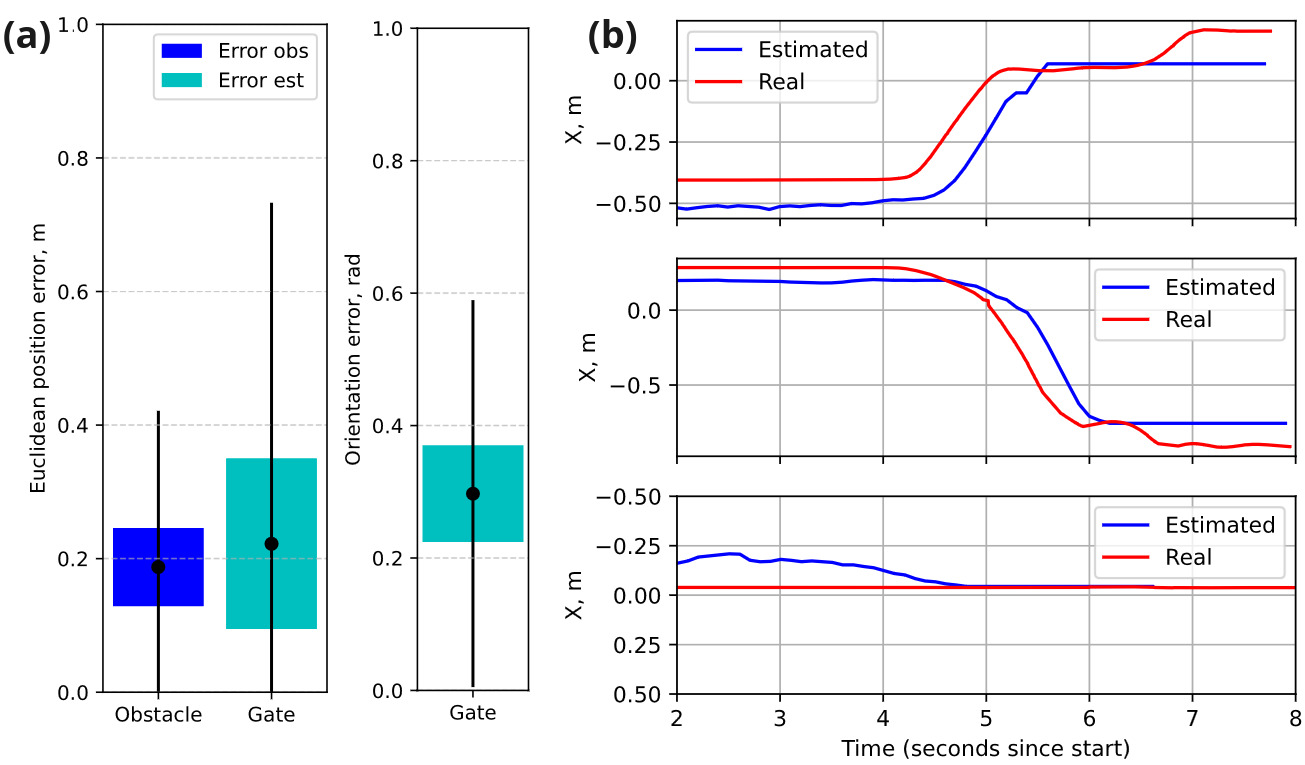
图 11:(a) 门检测的欧几里得位置和方向误差。 (b) 情况 1、2 和 3 中移动门的 X 坐标位置的估计。红线表示坐标的真实 X,而蓝线表示预测值。
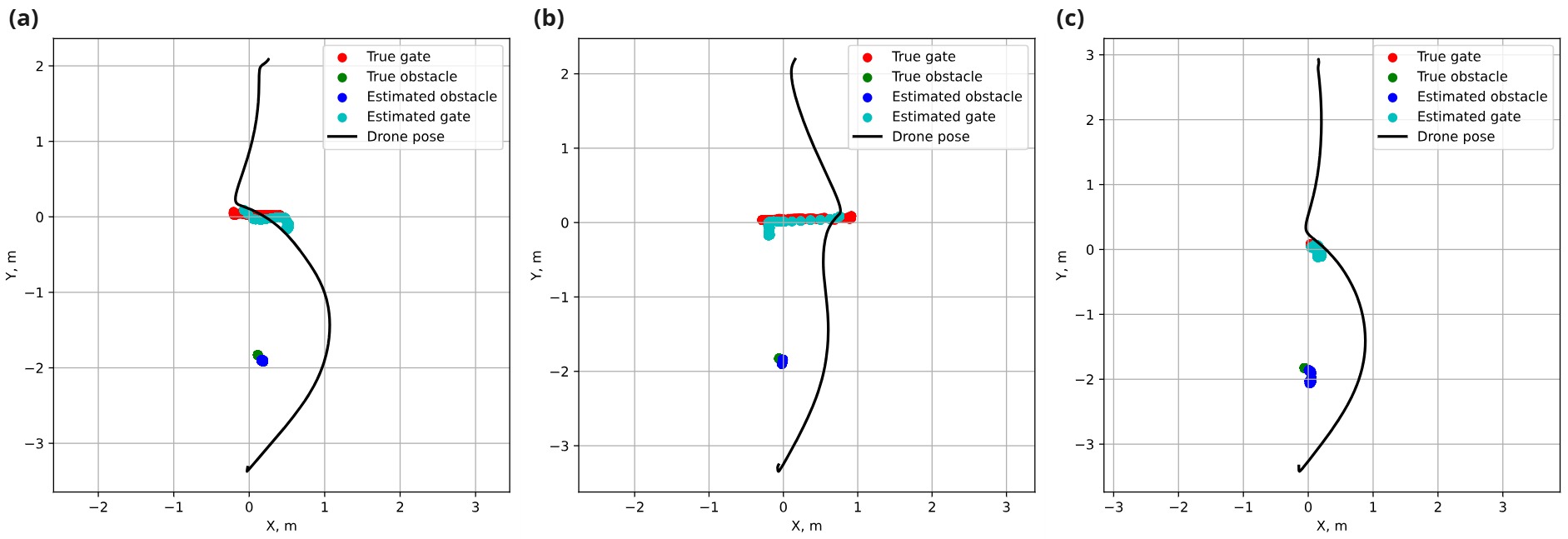
图 12:实验的俯视图(XY 平面)图,其中 (a) 显示无人机的轨迹和案例 1 中检测到的物体的 CV 姿势,(b) 显示相同,但现在包括案例 2 中检测到的快速移动门的姿态,以及 (c) 在案例 3 中显示无人机的轨迹和静态环境的物体检测
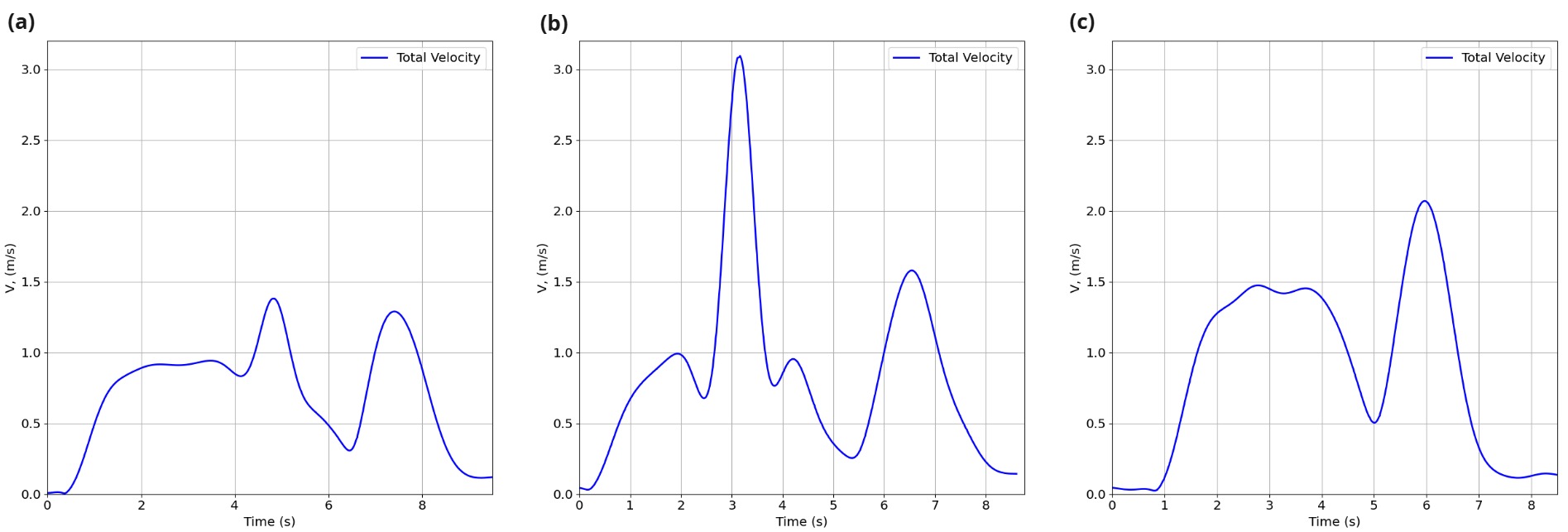
图 13:每种情况的总速度,其中 (a) 显示情况 1,(b) 显示情况 2,(c) 表示情况 3。所有速度都显示在无人机起飞后和着陆程序之前。每种情况下的第一个最大值表示无人机在到达门时的移动,第二个峰值突出显示无人机向最终目标点的移动。
V-B2 号DRL 代理的动作预测
图 1 中的位置和速度图12 和图 .13 总结说,在案例 1 中,大门以稳定的速度移动,使无人机能够在没有任何突然运动变化的情况下导航。代理意识到环境中包含移动物体,逐渐将其速度提高到最大 1.5 m/s,同时平稳地避开障碍物。这种平滑的速度曲线表明,代理有效地预见了门的运动,设法在没有遇到任何重大困难的情况下进行导航。
在案例 2 中,当无人机接近大门时,大门的移动速度要快得多,呈现出更加动态的场景。为了进行调整,无人机将其速度提高到 3.0 m/s,以响应门的快速移动。这种快速调整还证明了闸门检测系统能够准确跟踪快速移动的闸门。这种行为特别强调了智能体在动态条件下速度管理的稳健性。
在案例 3 中,在环境保持静止的情况下,无人机的速度预测在整个飞行过程中是平滑和一致的。环境没有突然的变化,这让无人机能够保持稳定的步伐。在安全通过大门和障碍物后,无人机提高了速度,因为没有进一步的碰撞风险,从而实现了更高效、更稳定的导航路径。
六结论和未来的工作
总之,我们介绍了 AgilePilot,这是一种基于 DRL 的新型运动规划器,它通过利用实时对象检测在动态环境中实现智能导航。DRL 框架在动态仿真环境中进行了训练,促进了稳健的自适应学习过程,从而有效地弥合了仿真与现实的差距。在模拟动态环境中,将我们的 Motion Planner 的性能与基于 APF 的 Motion Planner 进行了比较。总之,AgilePilot 通过完成任务优于传统方法3倍快,而且3在动态目标跟踪方面比 APF planner 更准确。总体而言,我们训练有素的代理的平均成功率为90%总共进行了 75 个实验。
在现实世界中,通过将经过训练的 DRL 代理部署到利用实时对象检测的硬件上,在不同的环境和动态条件下测试了三种条件。无人机展示了安全导航,同时避开障碍物并稳定通过动态门。然而,当环境受到高速变化的影响时,例如快速移动的大门,无人机表现出非凡的敏捷性和适应性,将其速度调整到 3 m/s 以满足环境的动态需求。障碍物的 RMSE 为 0.076 m,移动门的 RMSE 为 0.37 m,对门和障碍物的实时检测是准确的。观察到的延迟是由图像采集、神经网络处理以及位置和姿态过滤的转换所花费的时间得出的。但是,这种延迟不会对性能产生显著影响,并且无人机在实验中表现良好。这些结果验证了 AgilePilot 在真实条件下的有效性,证明了它能够使用训练有素的代理的实时速度预测来驾驭动态和不可预测的环境。
将来,可以探索更复杂的场景,包括引入不可预测的障碍和具有多个代理的环境。此外,进一步的研究可以集中在完全自主的系统上,该系统不仅利用 CV 进行物体检测,还用于精确的无人机定位,无需外部定位系统。这将提高态势感知能力,并扩大自主无人机系统的可部署场景范围。
引用
- [1]↑Y. Song、M. Steinweg、E. Kaufmann 和 D. Scaramuzza,“具有深度强化学习的自主无人机赛车”,2021 年 IEEE/RSJ 智能机器人与系统 (IROS) 国际会议,2021 年,第 1205-1212 页。
- [2]↑E. Kaufmann、M. Gehrig、P. Foehn、R. Ranftl、A. Dosovitskiy、V. Koltun 和 D. Scaramuzza,“美女与野兽:无人机赛车的最佳方法与学习相结合”,2019 年 5 月,第 690-696 页。
- [3]↑E. Kaufmann、L. Bauersfeld、A. Loquercio、M. Müller、V. Koltun 和 D. Scaramuzza,“使用深度强化学习的冠军级无人机比赛”,《自然》,第 620 卷,第 7976 期,第 982-987 页,2023 年 8 月。[在线]。可用: Champion-level drone racing using deep reinforcement learning | Nature
- [4]↑B. Joshi、D. Kapur 和 H. Kandath,“测量不确定性下无人机基于模拟到真实的深度强化学习避障”,2024 年第 10 届自动化、机器人和应用国际会议 (ICARA),2024 年,第 278-284 页。
- [5]↑E. Çetin、C. Barrado、G. Muñoz、M. Macias 和 E. Pastor,“通过深度强化学习进行无人机导航和避障”,2019 年 IEEE/AIAA 第 38 届数字航空电子系统会议 (DASC),2019 年,第 1-7 页。
- [6]↑Z. Liu, W. Gao, Y. Sun, and P. Dong, “基于搜索到控制强化学习的密集环境中四旋翼局部规划框架”,2025 年。[在线]。可用: arXiv:2408.00275
- [7]↑Z. Tan 和 M. Karaköse,“使用基于近端策略优化的分布式深度强化学习,使用无人机进行无人机跟踪的新方法”,SoftwareX,第 23 卷,第 101497 页,2023 年。[在线]。可用: https://www.sciencedirect.com/science/article/pii/S2352711023001930
- [8]↑U. Ates,“自主无人机深度强化学习的长期规划”,2020 年智能系统和应用创新会议 (ASYU),2020 年,第 1-6 页。
- [9]↑S. Song、K. Saunders、Y. Yue 和 J. Liu,“通过深度强化学习避免平滑轨迹碰撞”,2022 年第 21 届 IEEE 机器学习与应用国际会议 (ICMLA),2022 年,第 914-919 页。
- [10]↑X. 周, X. 温, Z. Wang, Y. Gao, H. Li, Q. Wang, T. Yang, H. Lu, Y. Cao, C. Xu, 和 F. Gao, “野外的微型飞行机器人群”,科学机器人学,第 7 卷,第 66 期,第 eabm5954 页,2022 年。[在线]。可用: https://www.science.org/doi/abs/10.1126/scirobotics.abm5954
- [11]↑X. Chen, Y. Qi, Y. Yin, Y. Chen, L. Liu, and H. Chen, “用于空地无人系统导航的多阶段深度强化学习和基于搜索的优化”,《应用科学》,第13卷,第4期,2023年。[在线]。可用: A Multi-Stage Deep Reinforcement Learning with Search-Based Optimization for Air–Ground Unmanned System Navigation
- [12]↑Y. Zhu, Y. Tan, Y. Chen, L. Chen, and K. Y. Lee, “在密集城市环境中基于随机障碍物训练和DRL线性软更新的无人机路径规划”,《能源》,第17卷,第11期,2024年。[在线]。可用: UAV Path Planning Based on Random Obstacle Training and Linear Soft Update of DRL in Dense Urban Environment
- [13]↑Y. Yang, Z. Hou, H. Chen, and P. Lu, “基于DRL的路径规划器及其在带有激光雷达的真实四旋翼中的应用”,《智能与机器人系统杂志》,第107卷,第3期,第38页,2023年3月。[在线]。可用: DRL-based Path Planner and its Application in Real Quadrotor with LIDAR | Journal of Intelligent & Robotic Systems
- [14]↑R. Peter、L. Ratnabala、D. Aschu、A. Fedoseev 和 D. Tsetserukou,“Lander.ai:在存在空气动力学干扰的情况下,基于 DRL 的自主无人机降落在移动的 3D 表面上”,2024 年无人机系统国际会议 (ICUAS),2024 年,第 295-300 页。
- [15]↑D. Aschu、R. Peter、S. Karaf、A. Fedoseev 和 D. Tsetserukou,“Marlander:使用多智能体深度强化学习的无人机集群本地路径规划”,2024 年 IEEE 系统、人和控制论国际会议 (SMC),2024 年,第 2943-2948 页。
- [16]↑V. Serpiva、A. Fedoseev、S. Karaf、A. A. Abdulkarim 和 D. Tsetserukou,“Omnirace:用于赛车无人机直观指导的 6d 手部姿势估计”,2024 年 IEEE/RSJ 智能机器人与系统 (IROS) 国际会议,2024 年,第 2508-2513 页。
- [17]↑J. Panerati、H. Zheng、S. 周、J. Xu、A. Prorok 和 A. P. Schoellig,“学习飞行——使用 pybullet 物理学进行多智能体四轴飞行器控制的强化学习的健身房环境”,载于 2021 年 IEEE/RSJ 智能机器人与系统 (IROS) 国际会议论文集,2021 年,第 7512-7519 页。
- [18]↑J. Amiryan 和 M. Jamzad,“使用先验路径的人工势场自适应运动规划”,2015 年第 3 届 RSI 机器人与机电一体化国际会议 (ICROM),2015 年,第 731-736 页。
- [19]↑H. Jayaweera 和 S. Hanoun,“用于跟踪地面移动目标的动态人工势场 (d-apf) 无人机路径规划技术”,IEEE Access,第 8 卷,第 192 760-192 776 页,2020 年 1 月。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)