编译原理---属性文法与语义分析
编译原理---属性文法与语义分析
第三和第四的顺序应该反过来会更好,因为是根据ppt的顺序做的,写完第三部分才发现顺序有问题
文章目录
一、概述
1.1 程序设计语言的语义
(1)静态语义:是指在编译阶段能检查的语义。它是对程序约束的描述,可以分为类型规则和作用域/可见性规则两大类。
(2)动态语义:是只有在目标码的运行阶段才能检查的语义。
1.2 编译程序的语义处理工作
静态语义检查 /生成某种中间代码 /解释执行动态语义
1.3 语义处理方法
目前在实际应用中比较流行的语义处理的方法主要是属性文法和语法制导翻译方法,应用最广的是属性文法。属性是描述语义的有效方法,由此发展而来的属性文法被认为是上下文无关文法的扩充。
1.4 属性文法的基本思想
将语言结构的语义以属性(attribute)的形式赋予代表此结构的文法符号,而属性的计算以语义规则(semantic rules)的形式赋予由文法符号组成的产生式。在进行语法分析推导或归约的同时通过语义规则实现对属性的计算,以达到对语义的处理。
文法符号就是第四章文法中的终结符和非终结符(VT、VN)
文法符号组成的产生式就是第四章文法中的产生式所以,属性文法是上下文无关文法的扩充(增加了语义)

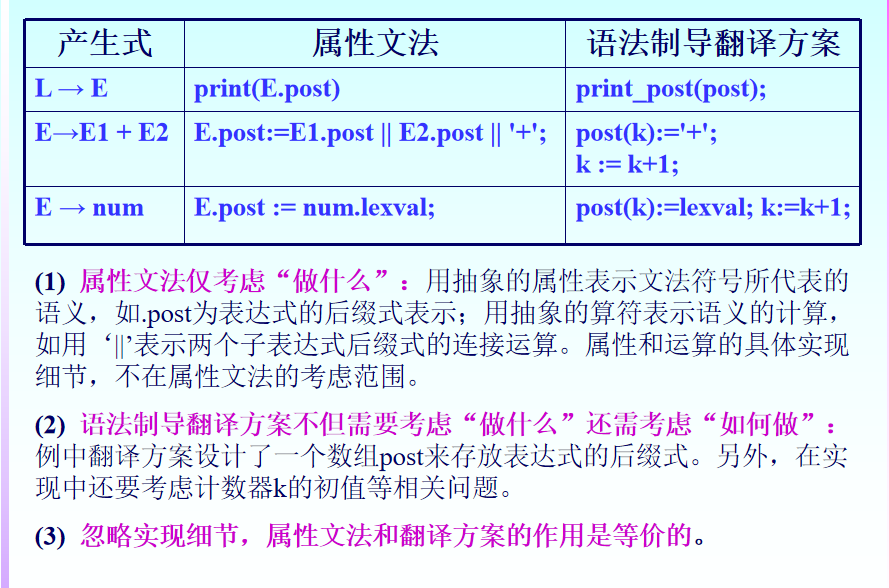
二、属性文法
2.1 定义
属性文法是一个三元组:A=(G, V, F)
1)G: 是一个
上下文无关文法
2)V: 有穷的属性集,每个属性与文法的一个终结符或非终结符相连,这些属性代表与文法符号相关的语义信息,如它的类型、值、代码序列、符号表内容等等. 属性与变量一样,可以进行计算和传递。属性加工的过程即是语义处理的过程。
3)F: 关于属性的属性断言或一组属性的计算规则(称为语义规则) . 如产生式A—>α有一组形式为
b := f (c1, c2, …, ck )的语义规则,其中f 是函数,b和c1, c2, …, ck 是该产生式文法符号的属性。
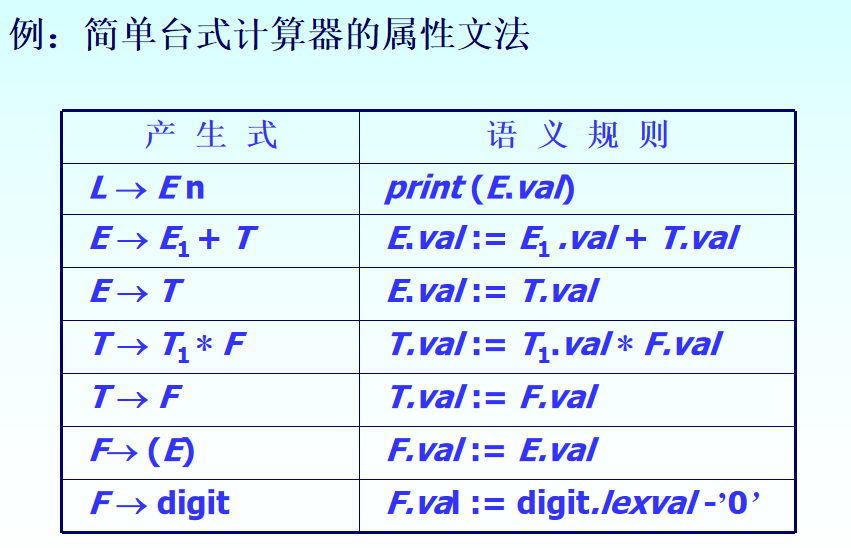
1)X.TYPE 表示该文法符号的类型;X.VAL 表示该文法符号的值;X.length 表示长度;X.val = digit 就是给该文法符号赋值;print(X)打印/输出
2)type、val、length与文法符号相连,说明其是属性,在V集合中
3)如果自底向上去看表中的语义规则,可以看出相当于一段程序代码的执行:给予F初始值,经过计算和传递,最终得到E的值进行打印/输出
2.2 习题练习

1)首先,我们要理解文法是如何实现由开始符号S产生一个二进制数的:L.L可替换S,产生的是具有小数的二进制数;L则对应是只有整数部分的二进制数;接下来要确定L的值:LB可替换L,即确定一位,并向左移动一位,产生的是多位二进制数;L则是只确定二进制数中的一位;B非终结符可由0/1替换,用于决定每一位取0/1
2)我们要对产生式做一个处理,使得产生式右边都只有一个句型:S—>L1.L2、S—>L、L—>L1B、L—>B、B—>1、B—>0(因为整数部分和小数部分不相同,所以L.L中要对两个L进行区分)
3)对第二步中得到的产生式加上属性,制定语义规则,即可得到属性文法:

写出产生式和语义规则就相当于是属性语法了,因为已经体现了三元组中的所有内容
题目举例中的S.val = 5.625 是一个十进制数,说明在print(S.val)之前就要把二进制数转换为十进制数;这也是为什么要记录L的长度(length),以及在L->L1B中要乘2(当L为10,对应十进制为2;当后面多接一个1,L为101,对应十进制为5)
三、符号表
符号表记录源程序中各种名字的属性和特征。每当扫描器识别出一个名字,编译程序就查符号表,看它是否在其中。如果不在,则填入(名字),其它信息以后陆续填入。
符号表中的信息在编译不同阶段都要用到:
1)语义分析中,用于语义检查
2)中间代码生成中,用于生成中间代码
3) 目标代码生成阶段,用于地址分配
符号表的内容:
(1)名字
符号表中的内容可以包括:标识符(常量名、类型名、变量名、域名、函数名、过程名、标号)、特殊符号(如算符)等。其中标识符是最多的一类。为了处理方便,符号表可以按上述分类划分为几张子表,如变量名表、过程名表等。
(2)属性
跟名字有关的信息。如类型、地址、作用域等
3.1 名字的作用域
名字起作用的范围被称为名字的作用域
定义在并列的两个范围内的名字其作用域互不相干,但是定义在嵌套的两个范围内的名字,其作用域的问题就需要制定规则来限定,该规则称为名字的作用域规则


3.2 符号表的分类(根据标识符的类型)及条目结构
3.2.1 按常量标识符进行分类(常量名表)
条目结构为:
(1)TypePtr指的是
数据类型标记;因为常量/变量只是一个标识符,其表示的数据也会有类型,可分为基本类型(如实数),自定义类型(如数组)
(2)Kind指的是标识符的类别,常量标识符为 consKind,类型标识符为 typeKind,变量标识符为 varKind
(3)Value指的是该常量的值
3.2.2 按类型标识符进行分类(类型名表)

Forward指的是处理前向声明,标记该类型是否是 “先声明、后定义” 的不完整类型,解决循环依赖问题
什么是先声明,后定义:
VAR a:vector 这是声明
TYPE vector = ARRAY[1…10] 这是定义
3.2.3 按变量标识符进行分类(变量名表)

(1)Access指的是访问方式,dir表示直接访问,indir表示间接访问(如指针、引用)
(2)Level指的是变量所在的作用域层数,用于静态作用域分析
(3)Off指的是变量在当前作用域的偏移地址(因为当前作用域有多个变量,即处在该作用域的表项有多个,其相对第一个表项地址的距离就是相对偏移)
3.2.4 例子剖析

1)找出题目代码中所提到的所有名字:pai、vector、x、y、r、s
2)pai使用的是const定义,说明是一个常量——>采用常量名表的格式

3)vector使用的是typedef/type定义,说明是一个类型——>采用类型名表的格式

4)x、y直接使用var定义,说明是变量——>采用变量名表的格式

题目中应该是少说了当前层次为L
1)x是当前作用域的第一个变量,所以偏移地址为0
2)y是当前作用域的第二个变量,并且有x,y: real,说明x和y都是实数,大小为8字节,所以y的偏移地址为8
5)r,s: vector说明r和s既是变量,其数据类型为上面所定义的vector数组,所以大小都为40字节(因为数组有10项,每一项为整数占4个字节),那么s与r的地址之差就是40

下图对偏移情况做一个详细描述: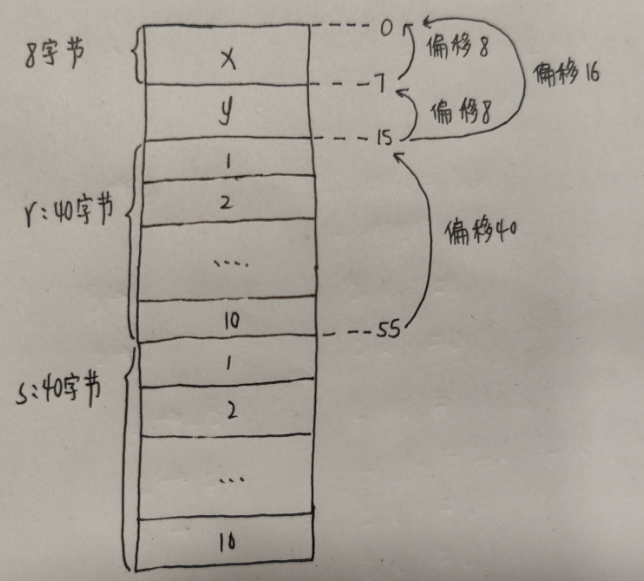
思考:为什么TypePtr这一部分,有的是realPtr,有的是aPtr?
如果数据是实数,那么就是realPtr;如果数据是整数,就是intPtr;如果数据是自定义的类型,如数组,就可以自定义,既可以是aPtr,也可以是bPtr
3.2.5 习题训练


3.3 符号表的分类(根据数据结构)
3.3.1 线性表


3.3.2 二叉表

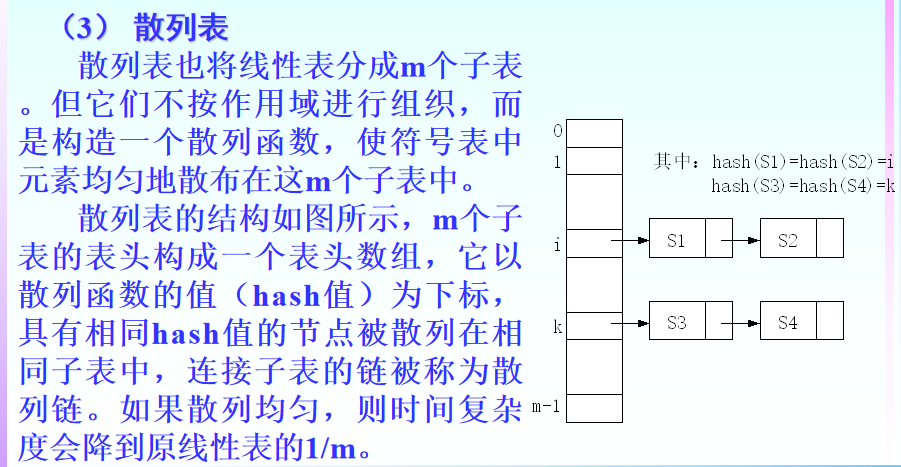
3.3.3 散列表
四、程序各部分的语义分析
一个程序首先是类型定义,然后是变量声明,最后是程序体部分。下面分别讲应如何对它们进行语义分析。
4.1 类型定义和变量声明的语义分析
一个变量应该分两部分完成:类型的定义和变量的声明。类型定义为编译器提供存储空间大小的信息,而变量声明为变量分配存储空间,编译器根据类型确定变量的存储空间。
4.1.1 类型定义
(1)三种类型:

integer(整数)可以占4个字节,real(实数)可以占8个字节,char(字符)可以占1个字节
数组的定义:
(2)类型的等价性
1、按名等价:
如果类型是一个名字,则两个类型等价当且仅当其名字相同;如果是结构类型形式,则任意两者都不能等价
怎么理解:
1)a: array [1…10] of integer和b: array [1…10] of integer类型的结构是一样的,但是名字不一样,所以a和b不等价
2) var a:tp; b:tp; 这是使用一个类型去声明变量,即使a和b名字不同,但是共享tp同一个名字,所以a和b等价
2、按结构等价:
则需比较结构中所有子成分的结构,为此需要一个判定两个类型是否等价的专门程序。
(2)类型的相容性
类型相容性的问题主要有以下几种:
(1)运算分量类型的相容性
(2)赋值语句左右类型的相容性
(3)值参和实参类型的相容性
等价性是相容性的一个特例
4.1.2 变量声明

程序体的语义分析




魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)